发布于: Oct 30, 2022
要修改实例,大家需要完成以下操作步骤:
- 确定修改策略以及各实例的修改顺序。
- 将您的实例类修改为适当的 Graviton2 实例。
您所选择的实例类修改策略,具体取决于您的实际配置——例如采用多可用区或读取副本。
对于采用多可用区设置的 Amazon RDS,所有实例修改均在辅助实例上完成,而后执行故障转移。接下来,在新的辅助(即原主)实例上重复修改步骤。这种方法带来的停机时间仅限于故障转移周期。故障转移周期通常为 60 到 120 秒。在实例类修改期间,单可用区实例将不可用。
对于采用一个或多个 Aurora 副本的 Aurora,在我们修改写入实例时,将有一套 Aurora 副本被升级为主实例;接下来在这个新的 Aurora 副本(原写入实例)上继续修改。临时中断一般在 120 秒以内。为了最大程度降低停机时间与风险,您可以首先在 Aurora 副本上修改实例,验证其是否按您的预期方式运行,而后通过故障转移迁移至现有 Graviton2 读取实例。在您的 Aurora 集群中,大家可以按照与具体用例相匹配的任意顺序将各实例修改为 Graviton2。
您还可以将 Graviton2 R6g 与 Intel R5 实例混合使用并匹配在同一集群当中,作为您的主实例或者读取副本,借此根据工作负载的需求尽可能提高实例资源性价比。
实例类的变更,意味着该实例将被重新定位至另一硬件主机之上,原有缓冲区也将不复存在。因此,当所修改的实例上的数据库重新启动时,缓冲区将处于冷启动状态,所以初始查询可能需要更长的时间。
作为一项常规最佳实践,我们可以在修改之前保存手动快照以保证能够轻松回滚。对于在单可用区设置内的 Amazon RDS,保存快照的过程(持续几秒到几分钟)内所有 I/O 将被挂起,具体视数据量大小而定。在多可用区配置下,快照保存期间不会导致 I/O 挂起。对于 Aurora,保存快照不会影响性能或导致数据库服务中断。
最好能根据您的日程安排,在 Amazon RDS 维护时段之内规划这项变更。这里指的是每周维护时段,即专门用于应用系统变更的时间窗口。您可以将维护窗口视为良好的调整机会,抓紧在此期间调整控制机制、进行软件修复。
对于本文中的用例,我们首先将一个 Aurora 读取实例迁移至 Graviton2,而后进行验证以确保其正常工作。我们将读取实例类修改为 Graviton2,而后故障转移至这个新的 Graviton2 读取实例并将其提升为写入实例。故障转移过程一般只需要几秒即可完成。
我们首先登录至 Amazon RDS 控制台。按照计划,我们首先在读取副本上修改实例类。
- 在 Amazon RDS 控制台的导航窗格中,选择 Databases。
- 选择读取实例(在本文中,我们使用 auroralab-pgsql-node-3) 而后选择 Modify。
- 在 DB instance class size 部分,选择 Memory Optimized 类。
- 选择您的实例类;在本文中,我们选择 db.r6g.large(其中的「g」代表 Graviton2)。
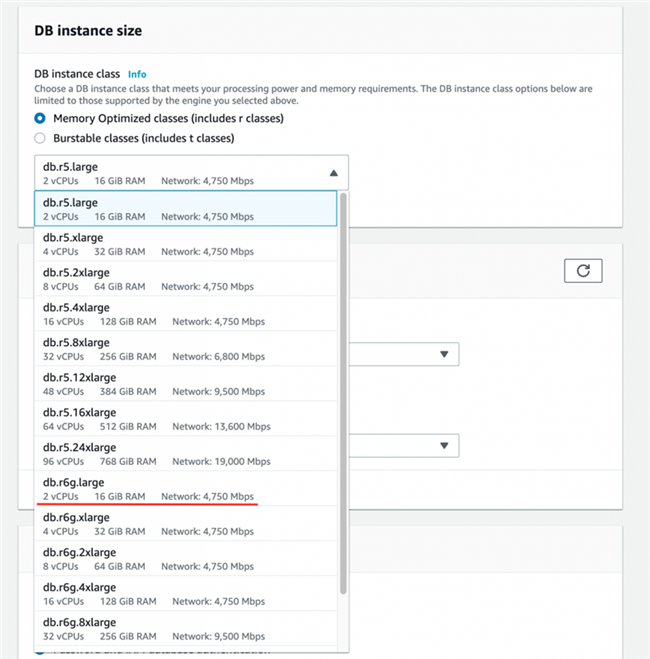
- 选择 Continue。
- 在摘要页面上,查看变更内容。
- 要立即应用变更,请选择 Apply immediately。如果您不立即应用变更,则变更内容将在您所设定的首选维护时段内进行。在某些情况下,选择立即应用可能会导致服务中断。
- 选择 Modify DB instance。
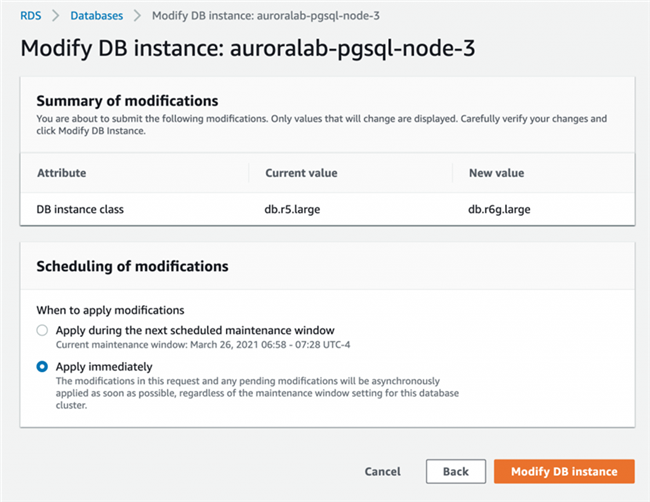
○ 以下截屏所示,为当前正在修改的实例。
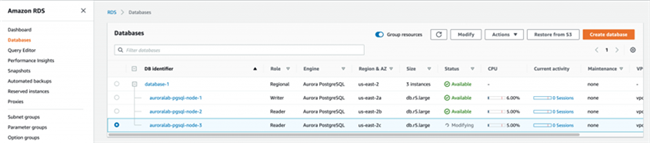
○ 对于本文中的用例,读取副本实例的修改时间耗费了几分钟。在修改此实例时,系统将打开写入实例及另一读取实例以处理应用请求。数据集的大小或数据库的加密状态等图中并未显示的因素,会影响到修改实例类所需要的时间。
○ 以下截屏所示,为位于 db.r5.large(x86)实例上的一个写入加一个读取副本,另一读取副本位于 db.r6g.large(Graviton2)实例上。
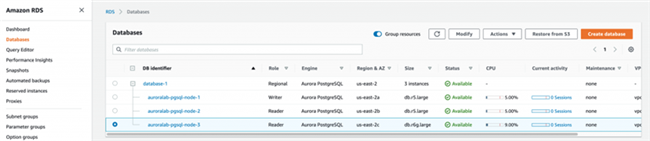
○ 现在,我们将写入副本故障转移至新的 db.r6g.large 读取副本。每个读取副本都对应一项优先级。在执行故障转移时,Amazon RDS 会首先提升优先级最高(层级数值最小)的读取副本。如果两个或更多副本拥有相同的优先级,则 Amazon RDS 将优先提升与原有主实例大小相同的副本。在进行故障转移之前,我们需要保证 db.r6g.large 读取副本的故障转移在优先级上高于其他读取副本。默认情况下,它们都位于第 1 级,因此我们需要选择 auroralab-pgsql-node-2 读取副本并将其配置变更为第 2 层。
- 选择 auroralab-pgsql-node-2 实例,之后选择 Modify。
- 在 Failover priority 部分,选择 tier-2。
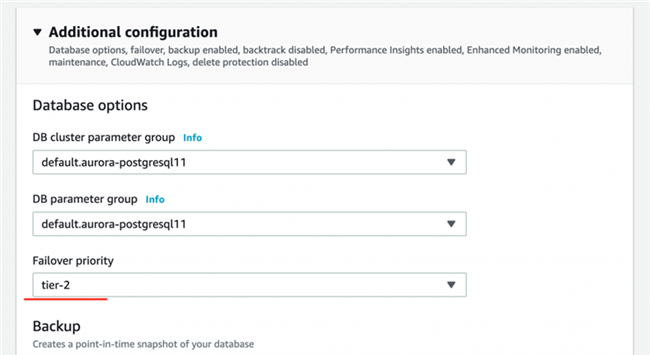
- 选择 Continue。
- 选择 Modify DB instance。
在 Action 菜单上选择写入实例 auroralab-pgsql-node-1,之后选择 Failover。
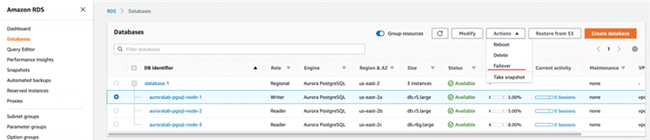
如果使用集群端点(推荐)而非数据库端点进行连接,并采用连接重试逻辑,则可以将应用程序的服务中断周期缩短至最低程度。在故障转移期间,Amazon Web Services 会修改集群端点 DNS 以指向新创建或新提升的数据库实例。变更完成之后,您将获得一个运行在 Graviton2 之上的写入实例。
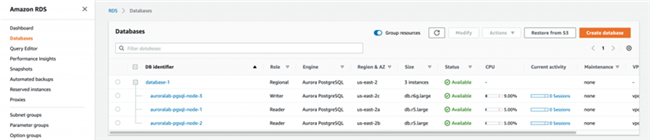
为了尽可能减少服务中断并增强应用程序弹性,您还可以使用 Amazon RDS 代理。要进一步缩短故障转移周期,您也可以在应用程序层级上配置主动 TCP keepalive 与 JDBC 连接设置或者 PGConn 类。关于更多细节信息,请参阅 Amazon Aurora PostgreSQL 最佳实践。
现在,您可以验证应用程序是否能够与基于 Graviton2 的 RDS 或 Aurora 数据库协同工作。如果启用了 Performance Insights,则可以使用 Performance Insights 仪表板实现数据库负载可视化,并根据等待时长、SQL 语句、主机或用户对负载进行筛选。
经过一段时间的测试(可能需要几天时间,具体视您的需求而定),您可以将其余读取实例变更为 Graviton2,并删除变更之前保存的快照。
在完成任意变更之后,如果发现新变更无法起到预期的效果,您必须设有后备策略——这一点非常重要。从宏观层面来看,大家拥有以下几种选择:
- 如果您的集群中存在一个 x86 读取实例,则可通过调整故障转移优先级故障转移至集群内的另一 x86 实例。
- 您还可以按照本文之前提到的类似过程,将实例类型变更回 x86 实例类型。
- 如果问题仍然存在,则可以使用变更之前保存的快照进行还原。关于使用 Amazon RDS 或 Aurora 时的其他注意事项,请分别参阅从数据库快照还原与从数据库集群快照还原。
回滚过程本身属于单独的主题,受篇幅所限,本文不再讨论更多具体细节。
本文分步向大家介绍如何将 Aurora PostgreSQL 实例修改为 Graviton2,并强调了关于停机时间控制方面的重要注意事项。您可以按照类似的步骤将 RDS 实例修改为 Graviton2。如果您的数据库版本未能达到 Graviton2 迁移所要求的最低版本,本文还简要介绍了数据库升级过程。
作为最佳实践,您应始终在较低环境中测试各项变更,包括您可能需要的数据库扩展,同时保证测试环境在配置与规模方面与生产环境高度相似。
相关文章







