发布于: Aug 12, 2022
3.使用 Atlas 查看 Hive 表的数据沿袭
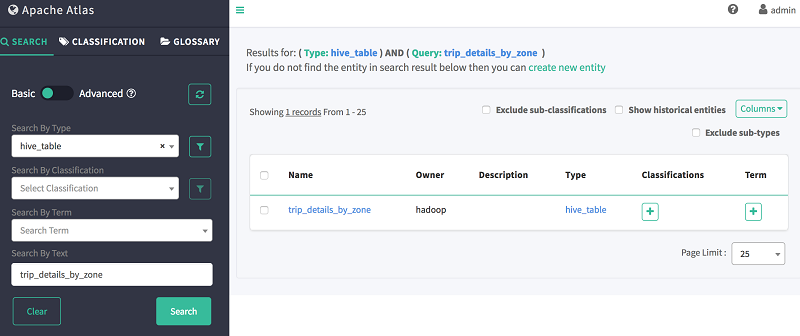
要查看所创建的表的数据沿袭,可以使用 Atlas Web 搜索。例如,要查看先前创建的交叉表 trip_details_by_zone 的数据沿袭,请输入以下信息:
- 按类型搜索:hive_table
- 按文本搜索:trip_details_by_zone
前文所述查询的输出应如下所示:
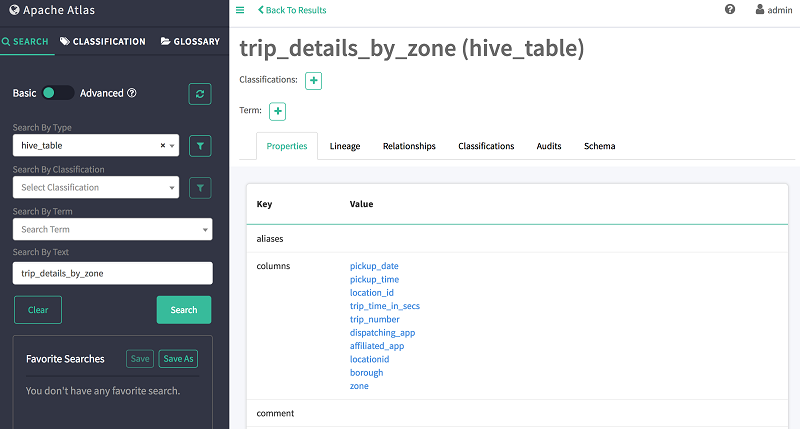
现在,选择表名称 trip_details_by_zone 来查看该表的详细信息,如下所示。
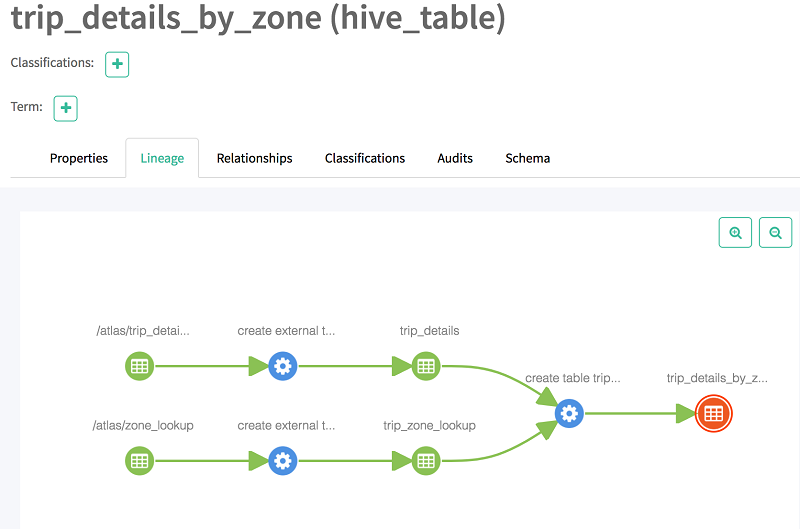
现在,当您选择沿袭时,您应该会看到该表的沿袭。如下所示,沿袭提供有关其基表的信息,并且显示两个表的交叉表。
4.为元数据管理创建分类
Atlas 可以帮助您对元数据进行分类,以满足组织特定的数据治理要求。接下来,我们创建一个示例分类。
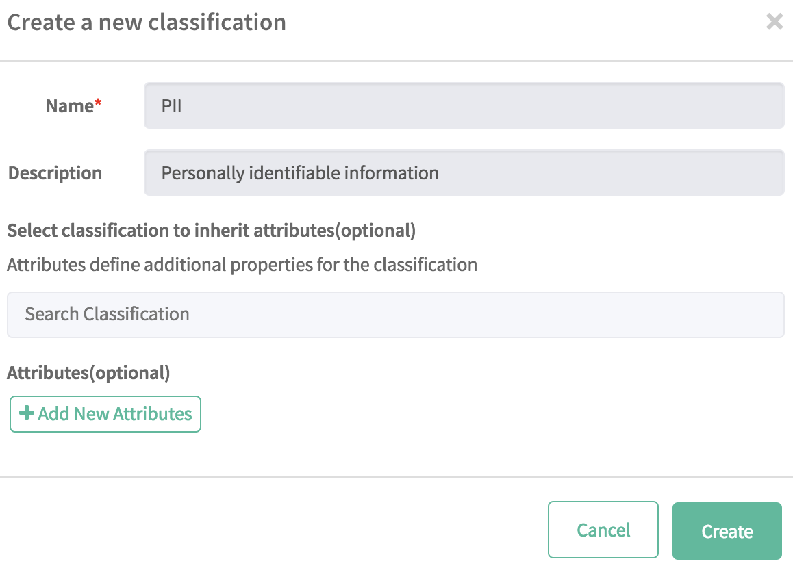
要创建分类,请执行以下步骤
- 从左侧窗格中选择“分类”,然后选择“+”
- 在名称字段中键入 PII,在描述中键入个人身份信息
- 选择创建。
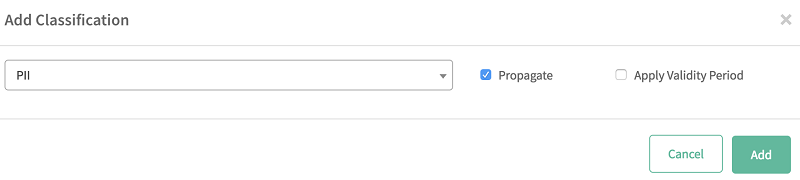
接下来,将该表分类为 PII:
- 返回到左侧窗格中的搜索选项卡。
- 在按文本搜索字段中,键入:trip_zone_lookup
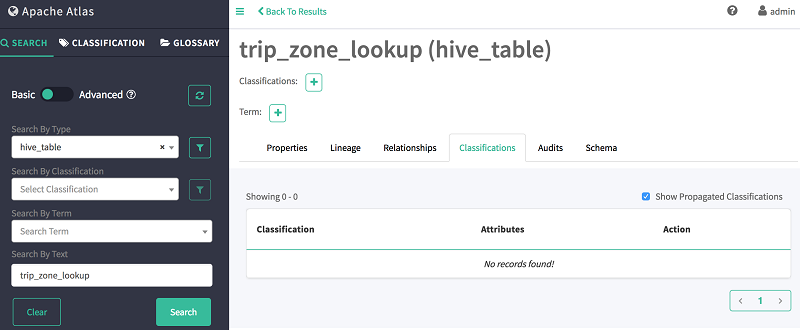
3. 选择选项卡,然后选择加号图标 (+)。
4. 从列表中选择您创建好的分类 (PII)。
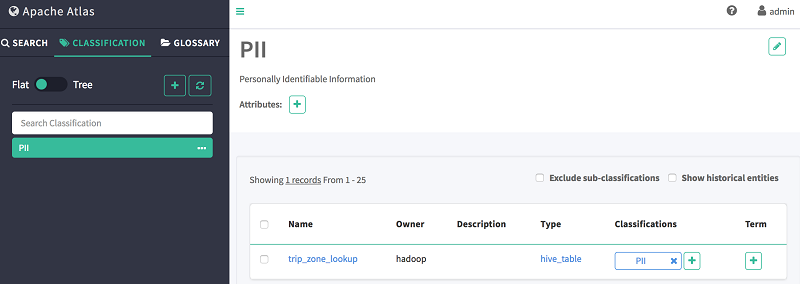
- 选择分类选项卡。
- 选择您先前创建的 PII 分类。
- 查看显示在主窗格上的属于该分类的所有实体。
6.使用 Atlas 领域专用语言 (DSL) 发现元数据
接下来,您可以使用 Atlas 的领域专用语言(DSL,一种类似于 SQL 的查询语言)在 Atlas 中搜索实体。该语言构造简单,可帮助用户浏览 Atlas 数据存储库。其语法模拟了关系数据库领域中广为流行的 SQL。
要使用 DSL 搜索表,请执行以下操作:
1. 选择搜索。
2. 选择高级搜索。
3. 在按类型搜索中,选择 hive_table。
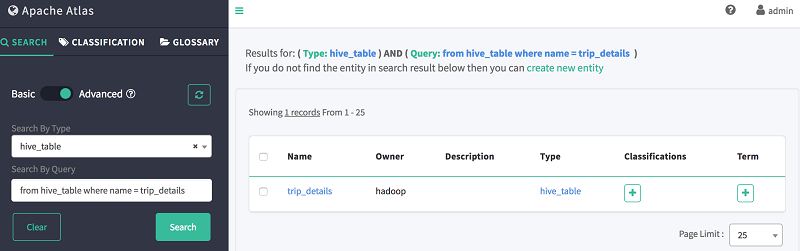
4. 在按查询搜索中,使用如下 DSL 代码段搜索 trip_details:from hive_table where name = trip_details
如下所示,Atlas 会显示表格的 Schema、数据沿袭和分类信息。
接下来,使用 DSL 搜索一列:
1. 选择搜索。
2. 选择高级搜索。
3. 在按类型搜索中,选择 hive_column。
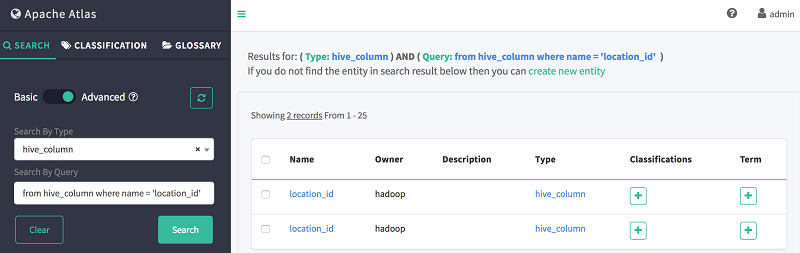
4. 在按查询搜索中,使用如下 DSL 代码段搜索 column location_id:
from hive_column where name = 'location_id'
如下所示,Atlas 会显示先前创建的两个表中都存在 location_id 列:
您还可以使用 DSL 对表进行计数:
1. 选择搜索。
2. 选择高级搜索。
3. 在按类型搜索中,选择 hive_table。
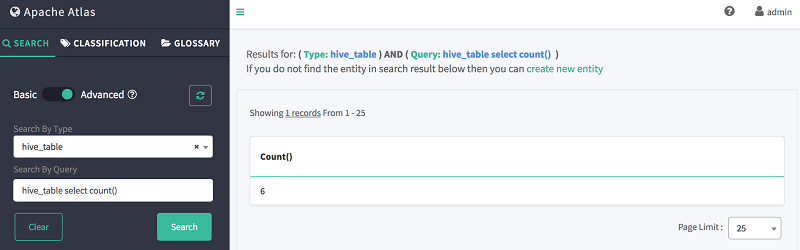
4. 在按查询搜索中,使用如下 DSL 命令搜索表存储:
hive_table select count()
如下所示,Atlas 会显示表的总数。
最后一步是清理环境。为了避免产生不必要的费用,请在完成实验后删除 Amazon EMR 集群。
如果使用的是 CloudFormation,最简单的方法是删除先前创建 CloudFormation 堆栈。默认情况下,集群在创建时会启用终止保护机制。要删除集群,您首先需要关闭终止保护,这可以通过 Amazon EMR 控制台来完成。
小结
在这篇博文中,我们概述了使用 Amazon Web Services CLI 或 CloudFormation,安装和配置带有 Apache Atlas 的 Amazon EMR 集群所需的步骤。我们还探讨了如何将数据导入 Atlas,以及如何使用 Atlas 控制台执行查询、查看数据构件的沿袭。







