







发布于: Jun 16, 2022
步骤如下:
- 将未标注的数据集上传到 S3 上
- 在 Sagemaker GroundTruth 中创建一个私有的 Labeling workforce
- 创建一个 GroundTruth Labeling job
- 使用 GroundTruth 平台来标注图片
- 分析结果
1.1.1 下载未标注的数据集:
在这一步中,我们将未标注的数据集下载到本地,然后 upload 到刚刚创建的存储桶中作为 SageMaker GroundTruth 的数据输入。这个数据集中包含 388 个文件,其中包含 6 大分类(Brachiosaurus, Dilophosaurus, Spinosaurus, Stegosaurus, Triceratops and Unknown)。
数据集下载地址:
将未标注的数据集上传到S3上:
在 ap-northeast-1 区域中创建一个 S3 存储桶并给存储桶唯一的命名.(比如,ground-truth-labelling-job-initials-20200112)
- 将 download 的数据集上传到刚刚创建的桶中。(因为下面的步骤我们需要做人工标注,所以建议将 6 大类的乐高恐龙分别选取 2-3 张作为需要标注的数据集即可)
- 在设置权限这一步保持默认即可,然后完成设置。
1.1.2 在 GroundTruth 中创建一个私有的 Labeling workforce:
这一步骤中我们将通过 Sagemaker GroundTruth 创建一个图像分类任务在 ap-northeast-1。
- 打开 Amazon Web Services 控制台 > Amazon SageMaker > 标签工作人员(Labeling workforces)
- 选择私有(Private)的标签然后创建私有团队(Create private team)
- 给私有标注的工作组命名
- 填写一个有效的邮箱地址
- …
- 创建私有团队
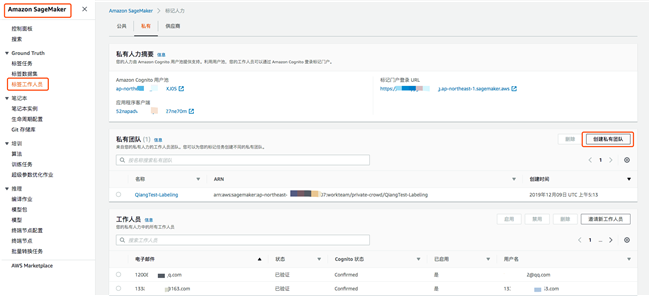
创建私有团队
- 当创建成功后,我们的邮箱会收到来自于 no-reply@verificationemail.com 发来的验证邮件,这个邮件包含了我们创建 workforce 的用户名和临时密码。
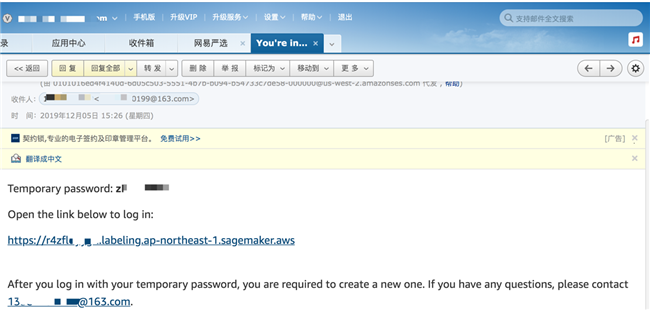
创建 workforce
- 使用 log in 的连接和临时密码登陆到标注控制台进行标注。
- 此时会要求我们更改临时密码。
- 因为我们还没有分配给 worker(我们自己)标注任务,此时标注任务是空的,下一步我们将分配给自己标注乐高恐龙的标注任务。
1.1.3 创建一个 GroundTruth Labeling job:
这一步骤就是我们创建一个标注的任务,然后分配给 workforce。
- 打开 Amazon Web Services 控制台 > Amazon SageMaker > 标记任务(Labeling jobs)
- Step 1:指定任务详细信息中:
—定义任务名称(记住任务名称,我们在notebook中的代码会用到)
—创建清单文件(manifest),输入 S3 训练数据集的路径,注意要以/结尾。For e.g. : s3:///<prefix/foldername>/
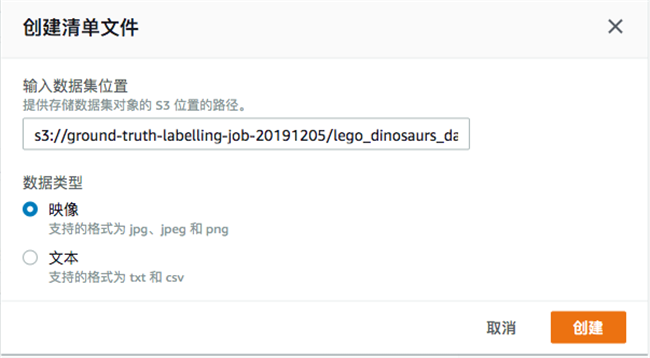
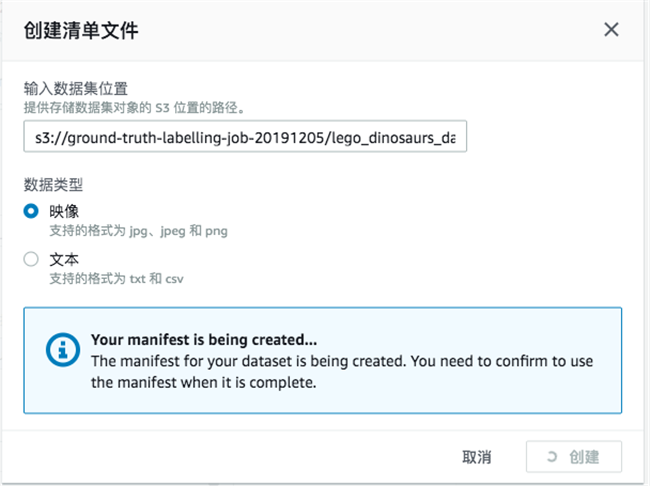
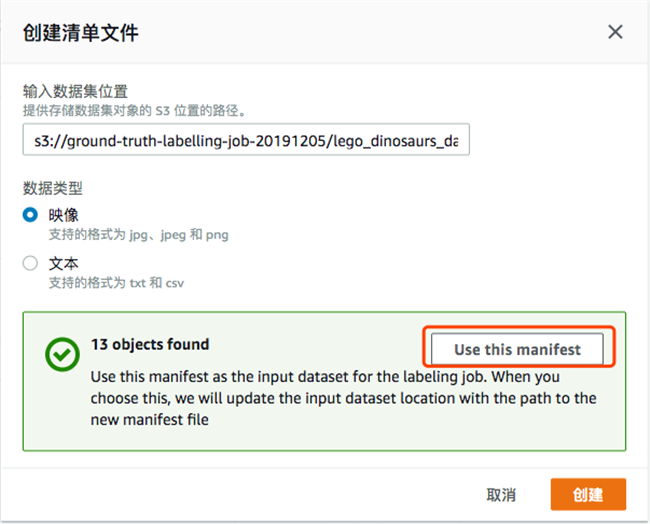
创建 manifest
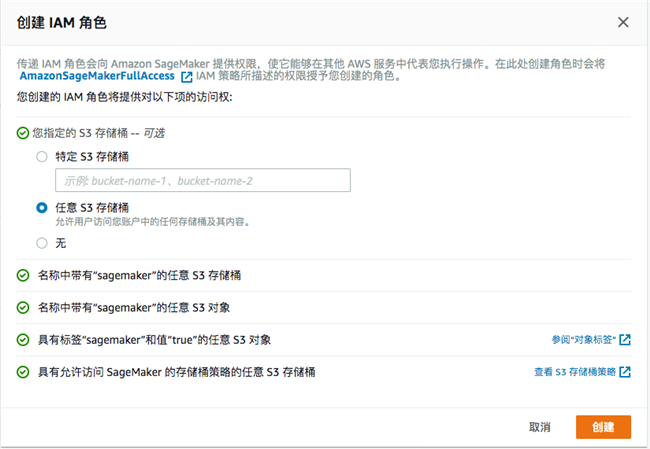
- IAM 角色,在测试环境中我们可以允许它访问所有的 S3 bucket,当然我们可以指定它可以访问特定 S3 bucket。
任务类型,我们选择图像分类。
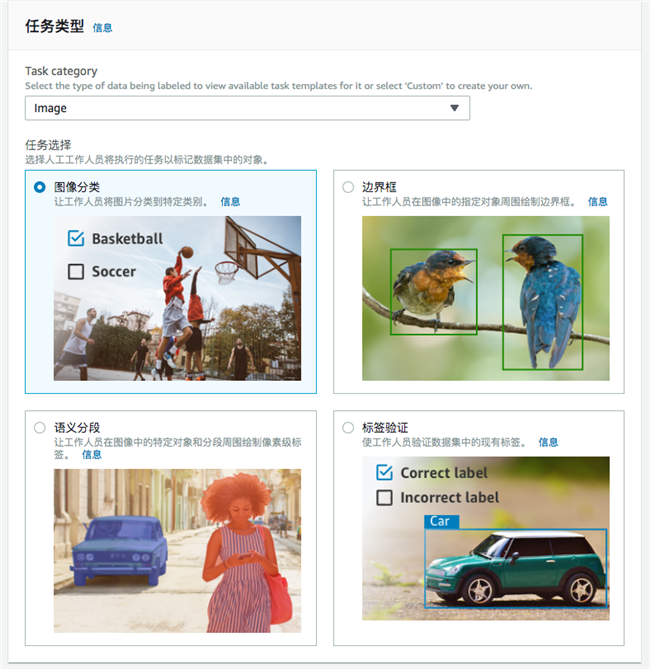
任务类型
- Step2: 选择工作人员并配置工具
选择“私有(Private)”>“私有团队(Private teams)在下拉框中我们已经在 1.2 创建过的”>“取消自动标记”>“其他配置中工作人员数量为 1”>“图像分类标记工具中添加 6 个标签:Brachiosaurus, Dilophosaurus, Spinosaurus, Stegosaurus, Triceratops and Unknown”
- 返回标注作业的页面查看 jobs 的状态,此时我们的邮箱会有 no-reply@verificationemail.com 发来的邮件,内容是分配给我 1 个 jobs 需要完成。
1.1.4 用GroundTruth平台来标注图片:
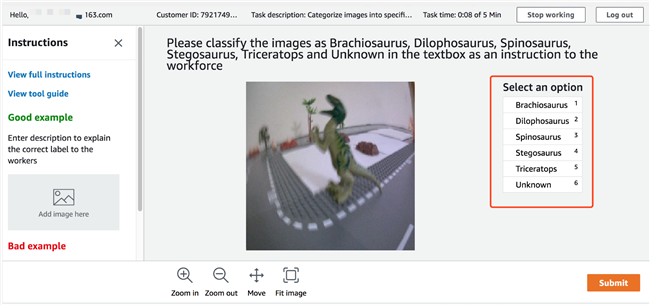
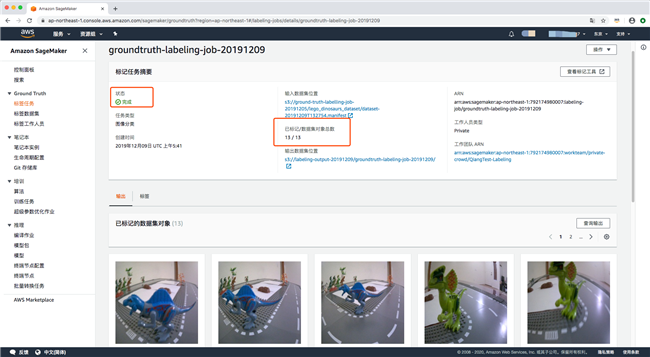
1.1.5 结果验证:
我们可以用 sublime text 打开在 output中 的 /manifests/output.manifest 文件,它是一个 json 文件包含一些被标记图片的 metadata .比如:

Manifests 格式
https://ml-jetson-greengrass.s3.cn-north-1.amazonaws.com.cn/sagemaker_image_classification-Copy1.ipynb
1.2.1 下载代码 ipynb 并导入到 SageMaker notebook 中:
这一步我们主要的目的就是通过 Amazon SageMaker notebook 编写训练模型的代码,通过代码来调用云计算的资源,比如机器学习类型的 instance。它将执行数据训练,并将训练和优化好的模型以 Amazon SageMaker Neo 导出。下一步将 Amazon SageMaker Neo 模型部署到 Jetson Nano 的设备上。如果不想对模型进行训练的话可以到参考链接处下载训练好的模型。
这个 notebook 主要是展示端到端机器学习的工作流程
- 使用 Sagemaker GroundTruth 创建的标签数据集。然后将数据集分为训练和验证。
- 使用 Sagemaker 容器训练模型
- 使用 Sagemaker Neo 优化模型
创建 Amazon SageMaker 笔记本
1.2.2 部分代码解析:
- 在 OUTPUT_MANIFEST 要输入Sagemaker GroundTruth的output 路径,前面的步骤已经验证过 output 的 manifest 的 json 格式。
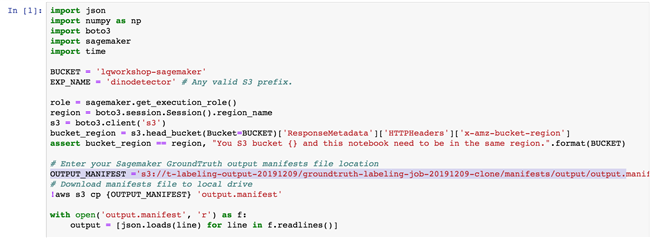
代码解析-1
- 在创建 Sagemaker 训练任务的时候,请根据自己数据集训练的个数来调整超参数(hyperparamerter)和训练 instance 的类型(InstanceType)如下:

代码解析-2
- 在 InputDataConfig 替换 AttributeNames 为自己定义的 name,比如:
“AttributeNames”: [“source-ref”,”groundtruth-labeling-job-20191209-clone”]
- 启动训练作业,我们可以在 Sagemaker notebook 中查看到结果,也可以返回到 Sagemaker 控制台的训练任务中看到训练的状态。训练的时间长短取决于训练实例类型、数据集大小、超参数的定义。
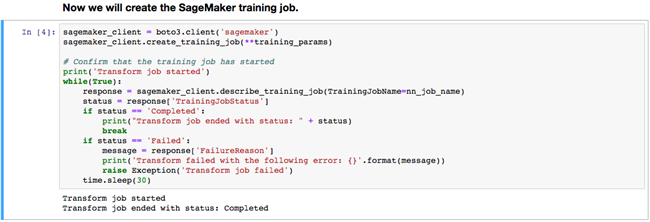
Sagemaker notebook 的训练状态
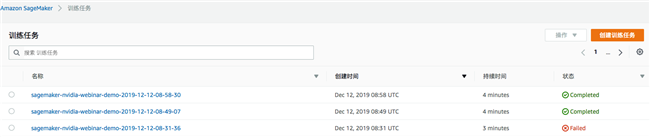
Sagemaker console 的训练状态
- 通过使用 Sagemaker Neo 来优化压缩模型给终端 Jetson Nano 使用,导出的模型路径我们要记录一下,在下一步骤部署 GreenGrass 的时候会用到。
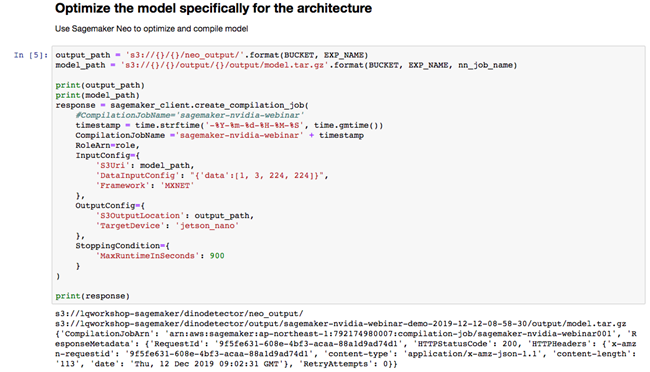
模型导出
实验小结:
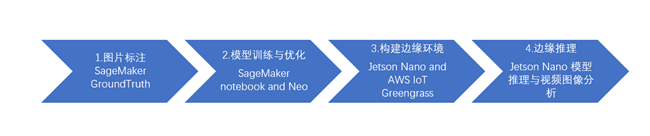
Amazon Web Services EI Demo 流程图
相关文章







