







发布于: Oct 30, 2022
如何通过 Amazon A2I 将表格数据引入人工审核工作流,首先我们要明确训练与部署阶段中的关键步骤:
- 导入必要的库并加载数据集。
- 将数据集划分为训练数据集与测试数据集,而后训练 ML 模型。在本文中,我们将使用 Amazon SageMaker 中内置的 XGBoost 算法训练模型,以得出二元预测结果。
- 创建一个端点,用以生成关于测试数据的推理示例。
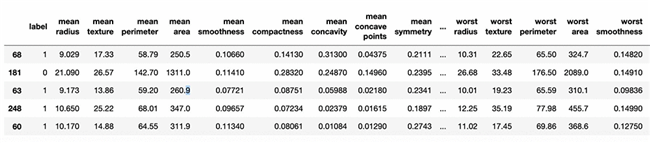
我们可以使用 scikit-learn 中的内置实用程序导入数据、导入数据集、生成训练与测试数据集,并最终完成模型训练以及预测结果生成。Scikit-learn 还提供另外一款实用程序,可根据固定比率(在大部分数据科学应用中通常为 80:20)以及随机状态将数据集划分为训练集与测试集,借此确保结果的可重现性。数据集详情,参见以下截屏中的表格。
要完成模型训练,我们需要使用内置的 XGBoost 算法,这是一种用于监督学习的高效、可扩展梯度提升树算法。关于更多详细信息,请参阅 XGBoost 工作原理。
按照 notebook 中的步骤完成模型训练。在模型训练完成后,Amazon SageMaker 会接手模型终端节点的部署与托管,如 notebook 中所示。Amazon SageMaker 将为您训练后的构型构建 HTTPS 终端节点,并根据需求自动扩展以在推理时提供流量。完成模型部署后,您即可生成预测结果。请参阅随附 notebook 中的以下源码:
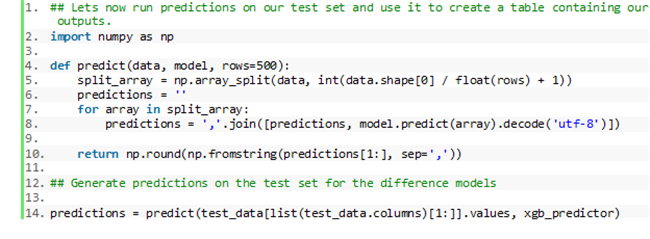
这单元格的输出为一系列预测结果:1或0分别代表恶性或良性。
现在,我们可以将模型输出合并至人工工作流当中。
随附的 Jupyter notebook 中包含以下操作步骤:
- 创建一个工作任务(worker task)模板,用于创建工作 UI。此工作 UI 将显示您的输入数据,例如文档或图像,以及对审核人员的指导性说明。此外,其中还提供供工作人员完成任务的交互式工具。关于更多详细信息,请参阅创建工作 UI。
- 创建一个人工审查工作流,也被称为流程定义。我们使用流程定义来配置人工团队,并提供关于如何完成人工审查任务的指导信息。大家可以使用单一流定义创建多个人工循环。关于更多详细信息,请参阅创建流定义。
- 创建一个人工循环,用于启动人工审查工作流并发送数据以供人工检查。在本文中,我们使用自定义任务类型并通过 Amazon A2I Runtime API 启动人工循环。在自定义应用程序中调用
StartHumanLoop,即可将任务发送给人工审核人员。
下面,我们将详细讨论如何在工作任务 UI 当中添加表格数据。
Amazon A2I 使用 Liquid 实现模板自动化。Liquid 是一种开源内联标记语言,可在大括号内包含文本,并通过指令创建过滤器与控制流。
在本文中,我们要求审核人员查看测试数据的特征,以判断模型输出结果是否准确。现在我们开始编写模板。此模板由两部分组成:包含测试数据集特征的静态表,以及包含允许用户修改的预测结果的动态表。
这里使用以下模板: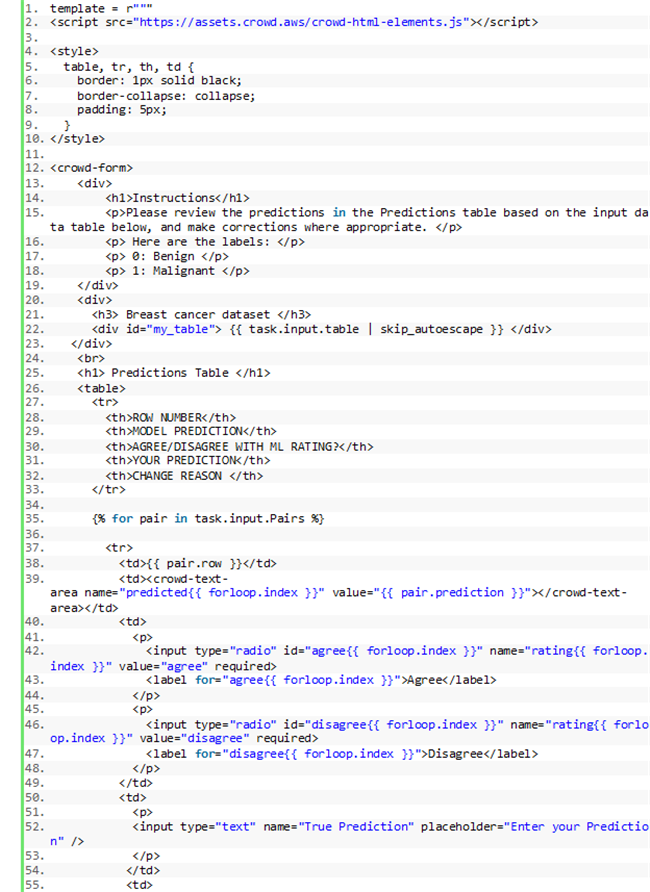
其中的task.input.table字段允许大家将静态表提取至工作任务 UI 当中。而skip_autoescape过滤器则负责将 pandas 表呈现为 HTML 形式。关于更多详细信息,请参阅创建自定义工作模板。
其中的task.input.Pairs字段用于在工作任务 UI 中动态生成表。由于此表中包含您的预测结果并需要配合人工输入,因此大家可以在其中同时包含单选按钮与文本字段,以帮助工作人员对模型的预测结果做出同意/不同意标记、在必要时更改模型预测结果,并提出更改的潜在原因。另外,这样的设计思路还可以限制我们在 ML 模型中的使用的特征类型,借此满足某些严格要求避免偏见因素的监管要求,充分遵守法规与合规性条款。
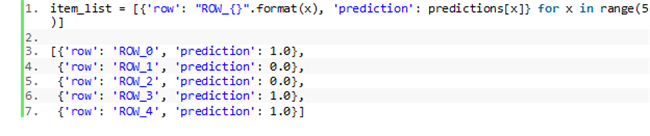
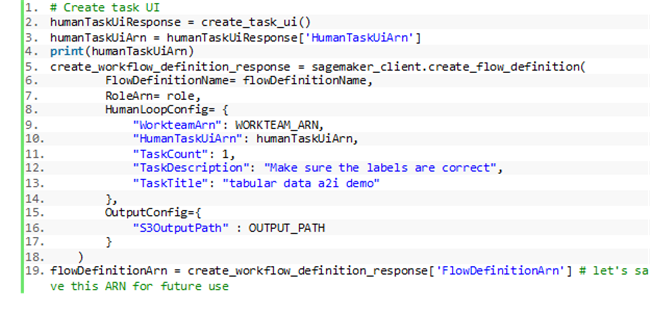
现在我们可以创建工作任务模板与人工审核工作流了。具体请参见以下代码片段:
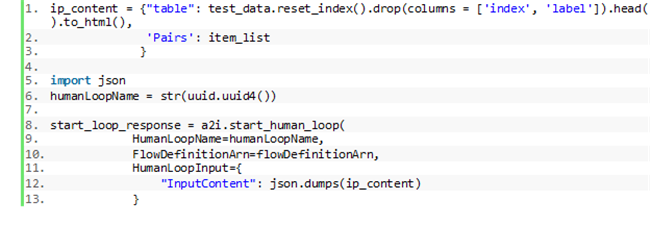
使用以下代码片段以启动人工循环:
在本文使用专项团队处理人工审核工作,因此工作人员可以在打开团队创建时接收到的链接,借此获取可视化 UI。
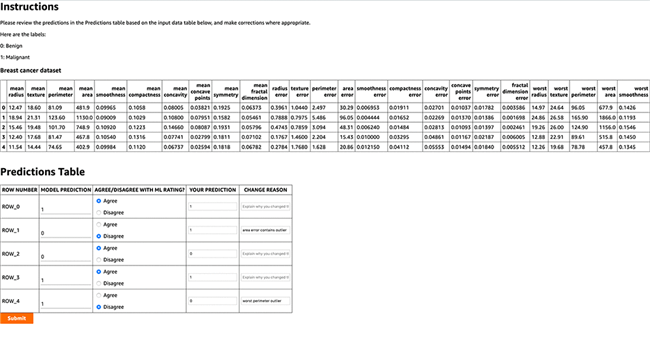
以下截屏所示,为我们使用的工作 UI。
在提交审核之后,相关结果将被写入至我们通过人工审核工作流指定的 Amazon S3 内输出位置。以下内容,为此位置上以 JSON 文件格式输出的结果。
- 人工审核回应
- 指向
StartHumanLoopAPI 的输入内容 - 关联的元数据
大家可以使用此信息来跟踪 ML 输出结果,并将其与人工审核输出关联起来:
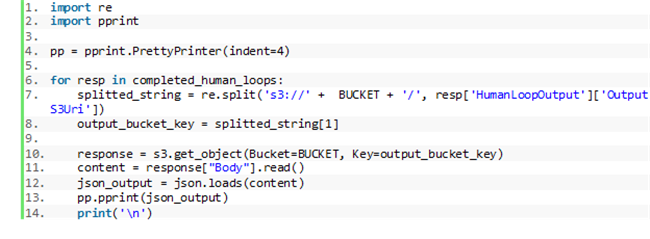
其中‘humanAnswers’ 键负责提供人工审核员对于各项更改的说明信息。详见以下代码片段:
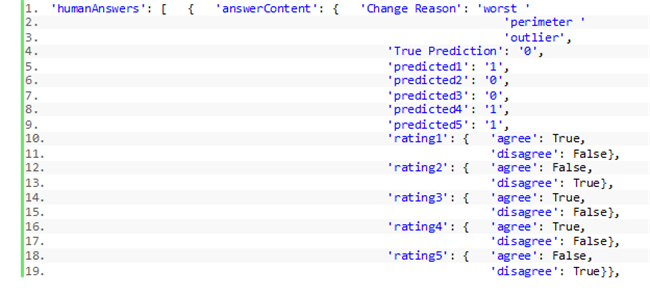
到这里,我们可以解析此 JSON 文档以提取相关输出结果,也可以在训练数据集中使用人工审核者提供的输出以重新训练模型,随时间推移不断改善模型推理性能。
为了避免产生不必要的后续成本,请在不再使用时删除相关资源,例如 Amazon SageMaker 终端节点、notebook 实例以及模型工件。
本文展示了两个用例,分别通过 Amazon A2I 将表格数据引入人工审核工作流中,且分别对应不可变静态表与动态表。当然,本文对于 Amazon A2I 功能的表述只能算是冰山一角。目前 Amazon A2I 已经在 12 个 Amazon Web Services 区域内正式上线,关于更多详细信息,请参阅区域表。
相关文章







