发布于: Aug 26, 2022
通过语音交互技术与机器进行对话可以在很多场景下提高效率,也是当下人工智能领域内研究的热点之一。语音识别技术的应用场景可以划分为以车载语音助手为例的车载场景、以智能家居设备的家庭场景等。要实现人与机器间的语音交互,需要首先让机器能够识别声音内容,但通用的语音识别服务无法完全满足不同场景下的需求,因此客户需要根据自己的需求训练模型。
本文会为大家展示如何使用 Amazon SageMaker (以下简称 SageMaker) 服务训练自己的语音识别模型,我们选择了一个开源的语音识别项目 WeNet 作为示例。
SageMaker 是一项完全托管的机器学习服务,涵盖了数据标记、数据处理、模型训练、超参调优、模型部署及持续模型监控等基本流程;也提供自动打标签,自动机器学习,监控模型训练等高阶功能。其通过全托管的机器学习基础设施和对主流框架的支持,可以降低客户机器学习的整体拥有成本。
WeNet 是一个面向工业级产品的开源端到端语音识别解决方案,同时支持流式及非流式识别,并能高效运行于云端及嵌入式端。模型在训练的过程中,需要用到大量的计算资源,我们可以借助 SageMaker 非常方便的启动包含多台完全托管的训练实例集群,加速训练过程。
在开始训练模型之前,我们需要做一些准备工作,包括准备 FSx 文件系统以存放训练过程中的数据、创建 SageMaker Notebook 作为实验环境、在笔记本中挂载 FSx 文件系统、准备实验代码,以及准备数据处理及模型训练的运行环境 (Docker 镜像) 并把镜像推送到 Amazon ECR (Elastic Container Registry) 中。
本文中的实验内容均使用 us-east-1 区域中的服务完成,您可以自行使用其他区域。
创建 FSx for Lustre 存储
以往,在 SageMaker 中训练模型一般使用 Amazon Simple Storage Service (以下简称 S3) 作为存储,现在,SageMaker 做模型训练时已经支持多种数据源,比如 Amazon FSx for Lustre 和 Amazon Elastic File System (EFS) 。SageMaker 通过直接读取存储在 EFS 或者 FSx for Luster 上的数据来加快训练模型时数据加载进度。
FSx for Lustre 支持从 S3 中导入数据,以及将数据导出到 S3,如果您的数据已经存放在 S3 中,FSx for Lustre 以透明方式将对象显示为文件。同一个 FSx 文件系统还可用于多个 SageMaker 训练任务,省去多次重复下载训练数据集的时间。
这里,我们会选择使用 FSx for Lustre 作为主要的数据存储。接下来,我们会创建一个 FSx for Lustre 存储。
创建基于 S3 的 FSx for Lustre
在“网络和安全性”处设置 VPC,子网组和安全组,并确认安全组入站规则是否允许了端口 998 的流量。
在 “数据存储库导入/导出” 处选择 “从 S3 导入数据及将数据导出到 S3” 并指定 S3 训练数据所在的存储桶和路径。
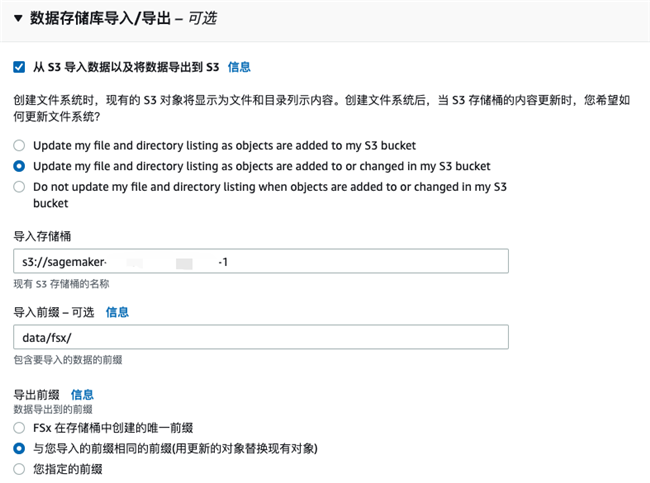
创建完成后,点击“挂载”按钮就会弹出挂载此文件系统的步骤,稍后我们会在 SageMaker Notebook 中使用到。

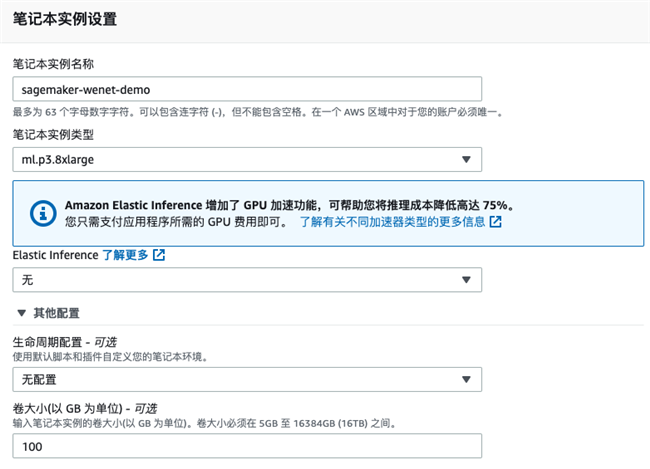
创建 SageMaker Notebook
选择笔记本实例类型,这里我们选择一台 ml.p3.8xlarge 的机器,其包含 4 张 Tesla V100 GPU 卡。您可以选择其他 GPU 机器,如果您不需要 GPU 卡,也可以选择 CPU 机器。
此外,您可以自行决定笔记本实例的卷大小,如本实例选择了 100GB 的存储。您可以在后续调整此存储的大小。
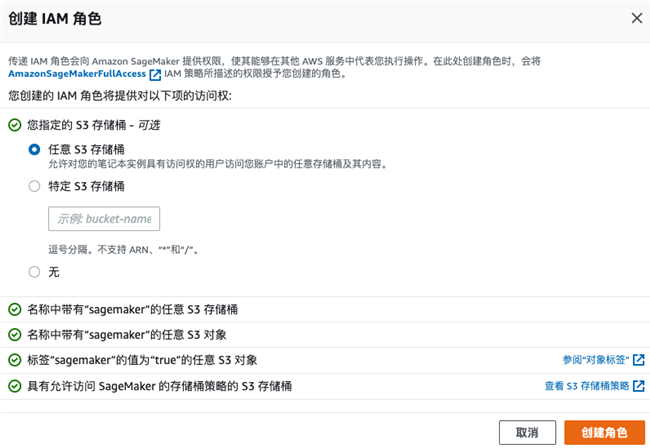
选择新建 IAM 角色,包含所需的权限,如下图:
网络部分,选择 FSx 所在 VPC 以及公有子网即可,安全组需要允许 SageMaker 访问 FSx。
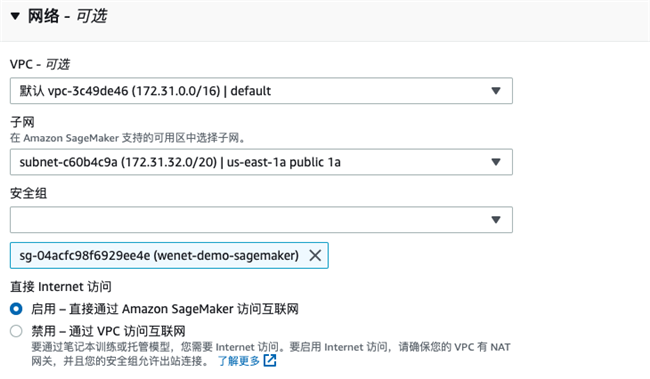
在笔记本中挂载 FSx 存储
在笔记本控制台页面,点击“打开 JupyterLab”。
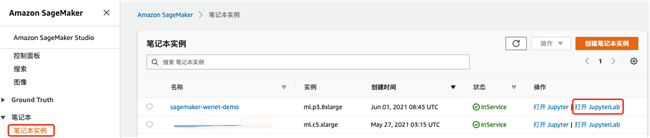
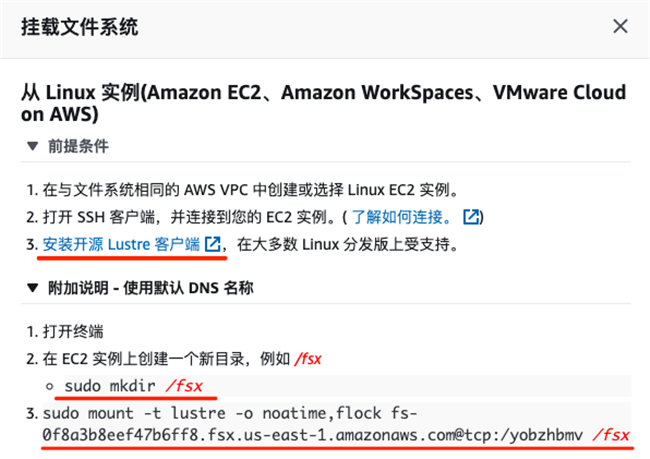
在 Launcher 页面,点击“Terminal”以创建一个新的命令行终端。根据“创建基于 S3 的 FSx”章节中提示的步骤,在命令终端中安装 Lustre 客户端,并执行挂载命令。
此外,您还可以配置笔记本生命周期策略,在创建或者启动 Notebook 实例的时候,实现笔记本自动挂载 FSx 文件系统。
下载 WeNet 源代码
在上一步中的命令行终端,执行如下命令,将完成代码下载。
sudo chown ec2-user.ec2-user /fsx ln -s /fsx /home/ec2-user/SageMaker/fsx cd ~/SageMaker/fsx git clone -b sagemaker https://github.com/chen188/wenet
这里,我们建议您将试验相关文件都放置在 ~/SageMaker 目录下,该目录下的数据在 Notebook 实例关机之后依然可以单独存在。
您可以打开 Notebook 文件 /fsx/wenet/examples/aishell/s0/SM-WeNet.ipynb,后续的命令您都可以在此笔记本中找到。
准备 Docker 镜像
在 SageMaker 中,很多任务都是基于 Docker 镜像实现,如数据预处理、模型训练及模型托管等。采用 Docker 镜像可以极大程度保证环境的一致性,并且降低环境预置的运维成本。
接下来,我们会需要构建自己的 Docker 镜像,来实现数据格式转换、模型训练。Amazon Web Service 已经提供了一些通用的 Deep Learning Container (DLC) 环境。但是其中尚未包含 TorchAudio 包,此时,我们可以选择基于开源版本构建运行环境。
该镜像基于 Ubuntu 来构建,并安装 pytorch 1.8.1、torchaudio 及其他相关依赖。文件 /fsx/wenet/Dockerfile:
FROM ubuntu:latest
ENV DEBIAN_FRONTEND=noninteractive
ENV PATH /opt/conda/bin:$PATH
RUN apt-get update --fix-missing && \
apt-get install -y gcc net-tools && \
apt-get install -y --no-install-recommends wget bzip2 ca-certificates libglib2.0-0 libxext6 libsm6 libxrender1 git mercurial subversion && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
wget --quiet https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh -O ~/anaconda.sh && \
/bin/bash ~/anaconda.sh -b -p /opt/conda && \
rm ~/anaconda.sh && \
ln -s /opt/conda/etc/profile.d/conda.sh /etc/profile.d/conda.sh && \
echo ". /opt/conda/etc/profile.d/conda.sh" >> ~/.bashrc && \
echo "conda activate base" >> ~/.bashrc && \
find /opt/conda/ -follow -type f -name '*.a' -delete && \
find /opt/conda/ -follow -type f -name '*.js.map' -delete && \
/opt/conda/bin/conda clean -afy
COPY ./requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt && \
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html && \
pip install sagemaker-training && \
rm /tmp/requirements.txt
您可以注意到,我们额外安装了 sagemaker-training 包,来提供镜像对 SageMaker 训练功能的支持。
构建镜像并推送到 ECR
ECR 是 Amazon 完全托管的容器注册表服务,我们可以将构建好的镜像推送到 ECR,后续 SageMaker 在训练或者托管模型的时候,会从这里下载对应的镜像。
import boto3
account_id = boto3.client('sts').get_caller_identity().get('Account')
region = boto3.Session().region_name
ecr_repository = 'sagemaker-wenet'
# 登录ECR服务
!aws ecr get-login-password --region {region} | docker login --username AWS --password-stdin {account_id}.dkr.ecr.{region}.amazonaws.com
# 训练镜像
training_docker_file_path = '/fsx/wenet'
!cat $training_docker_file_path/Dockerfile
tag = ':training-pip-pt181-py38'
training_repository_uri = '{}.dkr.ecr.{}.amazonaws.com/{}'.format(account_id, region, ecr_repository + tag)
print('training_repository_uri: ', training_repository_uri)
!cd $training_docker_file_path && docker build -t "$ecr_repository$tag" .
!docker tag {ecr_repository + tag} $training_repository_uri
!docker push $training_repository_uri
相关文章







