发布于: Aug 16, 2022
为观察 Amazon Web Services Batch 如何创建集群以搭起云计算与高性能计算间的桥梁,本实验利用 Batch 搭建一个简单抓取脚本运行的 Demo,原理如下图流程所示。Batch 执行的任务是以 Docker 容器方式运行的,容器镜像基于 Amazon ECS 服务来管理。实验中生成的简单镜像里包含一个辅助程序,负责从 S3 存储中下载名为 myjob.sh 的自定义任务脚本(同时也支持 zip 文件),由 Batch 负责启动 EC2 实例来装载容器具体执行。实验中的任务脚本会输出打印一些演示信息,在 CloudWatch 的 Log 日志记录中可以查看验证任务脚本的这些输出信息。当然您也可以根据需求自己改写或丰富 myjob.sh 的脚步执行内容。
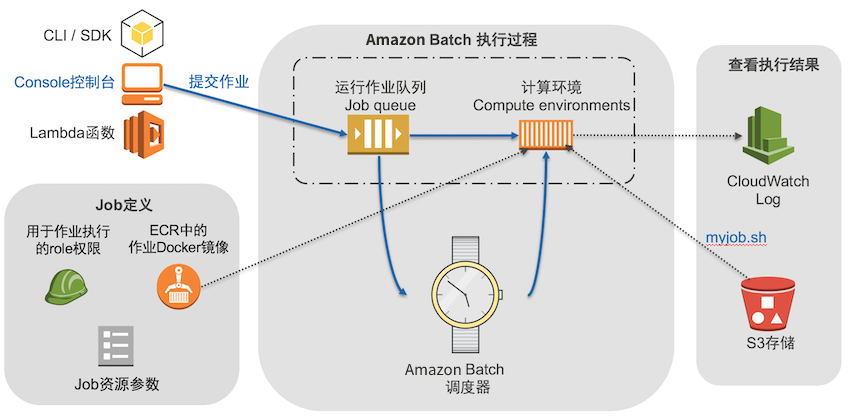
整个实验的步骤一览:
- 步骤1 准备处理任务的 Docker 镜像。
- 步骤2 Docker 镜像传入 ECR 存储库。
- 步骤3 上传批作业脚本至 S3 存储并配置相应 IAM 权限。
- 步骤4 Batch 服务的作业配置。
- 步骤5 提交 Batch 任务并查看执行状态。
整个动手实验时间约需 45 分钟,实验所需资源的花费 <5 元(如果有免费体验套餐花费可以更低)。动手前请确认满足前提条件(操作步骤详见参考链接):
- 具有一个 Amazon Web Services 中国区域帐号(或 Global 帐号)。
- 新建了足够权限的 IAM User 并记录了访问密钥(AK)和秘密密钥(SK)。
- 掌握 Amazon EC2 启动、SSH 登录 EC2、创建 S3 存储桶的基本操作。
本实验需要启动一个 EC2 实例来制作 Docker 镜像。在中国区域实验时选择宁夏区域,启动 EC2 环境时选取 Amazon Linux 2 类型的 AMI,如下图所示。实例类型选择 t2.micro。

EC2 就绪后通过 SSH 方式登录:
ssh -i yourkey.pem ec2-user@your-ec2-public-ip
配置 CLI 的权限,根据命令提示输入 AK 和 SK 密钥值,默认:
aws configure
执行一次更新并安装 docker 服务:
sudo yum update -y sudo yum install docker
启动 Docker 服务:
sudo service docker start
下载实验包的 github 源码:
wget https://github.com/awslabs/aws-batch-helpers/archive/master.zip unzip master.zip
解压进入路径后查看 Dockerfile 文件:
vim aws-batch-helpers-master/fetch-and-run/Dockerfile
文件内容如下所示,其中 FORM 语句是拉取最新的 amazonlinux 版本,ADD 语句把 fetch_and_run.sh 脚本拷贝至 /usr/local/bin 路径下,ENTRYPOINT 语句指定容器运行的入口是调用 /usr/local/bin/fetch_and_run.sh 脚本。
FROM amazonlinux:latest RUN yum -y install unzip aws-cli ADD fetch_and_run.sh /usr/local/bin/fetch_and_run.sh WORKDIR /tmp USER nobody ENTRYPOINT ["/usr/local/bin/fetch_and_run.sh"]
在中国区实验时修改一下 fetch_and_run.sh 脚本内容(Global 区域跳过此步)
vim aws-batch-helpers-master/fetch-and-run/fetch_and_run.sh
将 fetch_and_run_script() 函数的第一句改成如下并保存退出编辑:
aws s3 cp "${BATCH_FILE_S3_URL}" - > "${TMPFILE}" --endpoint "https://s3.cn-northwest-1.amazonaws.com.cn" || error_exit "Failed to download S3 script."
把 ec2-user 加到 docker 组里(免得后续每次 docker 命令前都要加 sudo):
sudo usermod -a -G docker ec2-user
执行完退出 SSH。
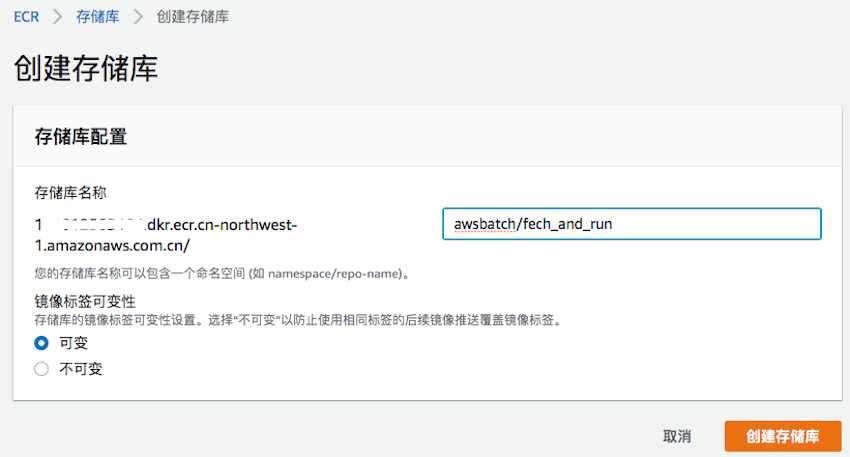
进入 ECR 控制台选择“Repositories”页,点击“创建存储库”,填写名称为“awsbatch/fetch_and_run”后点击创建,如下图所示。
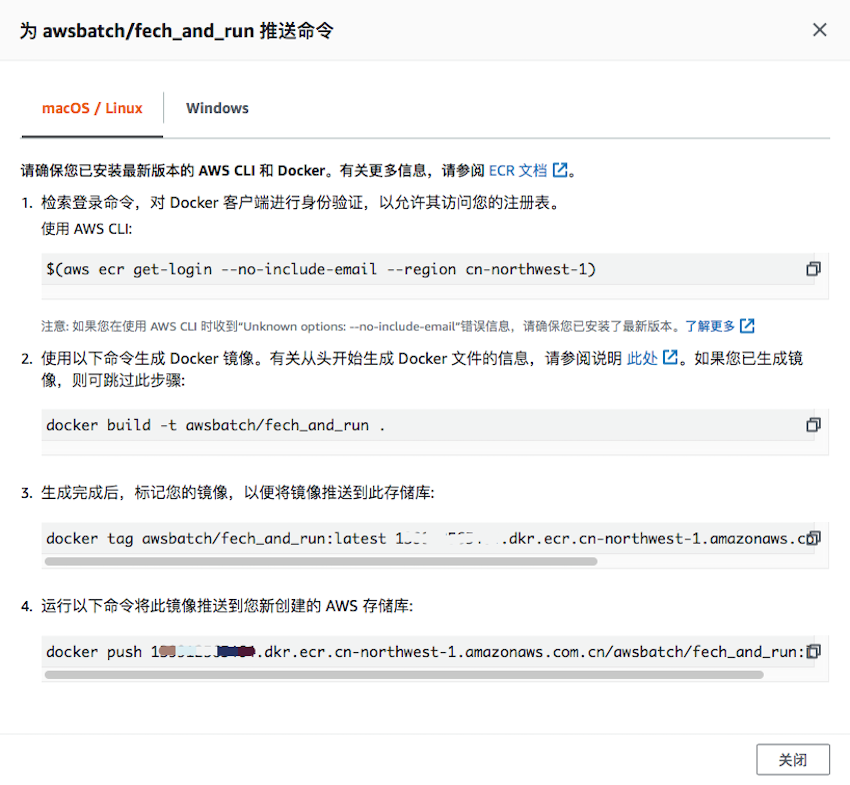
创建完成后,在“存储库”列表中选中“awsbatch/fetch_and_run”这一栏,点击右上角“查看推送命令”按钮,即出现如下界面,里面详细列出了推送至 ECR 的步骤。
重新 SSH 登录到 EC2 上并进入 fetch-and-run 路径
ssh -i yourkey.pem ec2-user@your-ec2-public-ip cd aws-batch-helpers-master/fetch-and-run
逐个执行上述“查看推送命令”图中的四条命令:
$(aws ecr get-login --no-include-email --region cn-northwest-1)
编译 docker 镜像文件(命令行最后的“.”点号不要忘输入)
docker build -t awsbatch/fetch_and_run .
正常编译完成的输出信息如下:
Sending build context to Docker daemon 373.8 kB Step 1/6 : FROM amazonlinux:latest latest: Pulling from library/amazonlinux c9141092a50d: Pull complete Digest: sha256:2010c88ac1****… Status: Downloaded newer image for amazonlinux:latest ---> 8ae6f52035b5 Step 2/6 : RUN yum -y install unzip aws-cli ---> Running in e49cba995ea6 Loaded plugins: ovl, priorities Resolving Dependencies --> Running transaction check ---> Package aws-cli.noarch 0:1.11.29-1.45.amzn1 will be installed << removed for brevity >> Complete!
输入以下命令验证下镜像信息:
docker images
可查看到本地镜像库的列表信息如下图所示:

继续输入以下命令给镜像添加标签:
docker tag awsbatch/fetch_and_run:latest 112233445566.dkr.ecr.cn-northwest-1.amazonaws.com/awsbatch/fetch_and_run:latest
执行 docker 镜像推送命令:
docker push 112233445566.dkr.ecr.cn-northwest-1.amazonaws.com/awsbatch/fetch_and_run:latest
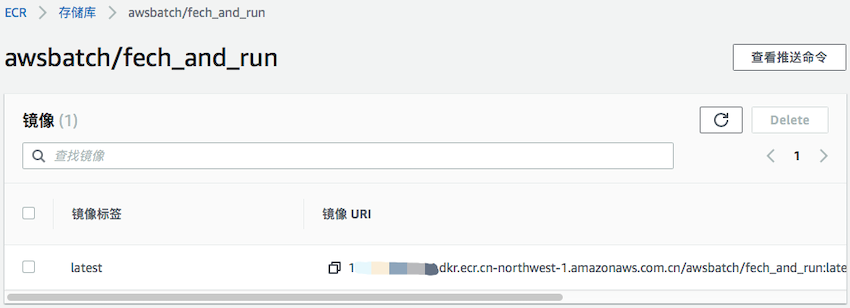
待提示信息中 pushed 完成后可在 ECR 存储库中查看到镜像的信息,拷贝记录下该 URI 名称。
拷贝以下代码存入本地文件命名为 myjob.sh。
#!/bin/bash date echo "Args: $@" env echo "This is my simple test job!." echo "jobId: $AWS_BATCH_JOB_ID" echo "jobQueue: $AWS_BATCH_JQ_NAME" echo "computeEnvironment: $AWS_BATCH_CE_NAME" sleep $1 date echo "bye bye!!"
输入以下命令上传脚本至已事先创建好的 S3 存储桶。
aws s3 cp myjob.sh s3://testbucket/myjob.sh
由于镜像 fetch_and_run 作为 Batch 作业执行过程中要访问 S3 下载任务脚本,所以需要给 Batch 中的容器配置一个能读取 S3 存储桶的 IAM 权限角色。打开 IAM 控制台,分别点击角色->创建角色。受信任实体选“Amazon Web Services 产品”,并在服务中选择“Elastic Container Service”:
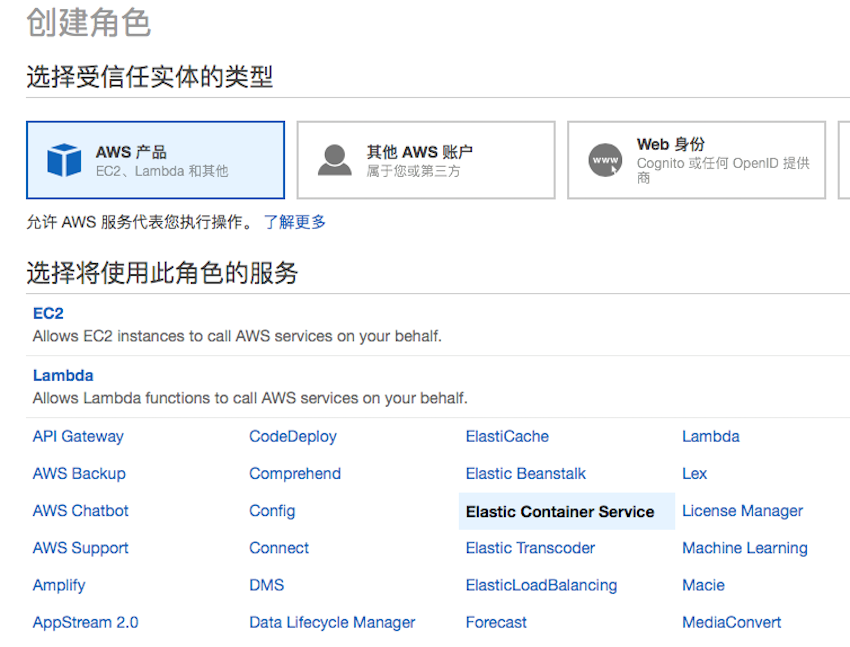
然后在随之出现的使用案例列表里,选择“Elastic Container Service Task”一项,点击下一步权限。
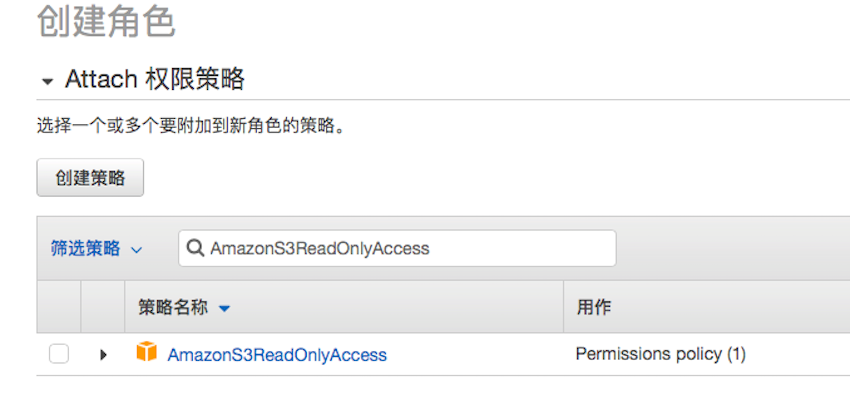
在 Attach 权限策略页中的搜索栏中输入 AmazonS3ReadOnlyAccess 搜索并选取该权限策略,点击下一步标签填写(可选)标签内容,再点击下一步审核,在角色名称中填入 batchJobRole 后,点击创建角色按钮。
Batch 的作业配置依次包括:计算环境(Compute Environment)配置,作业队列(JobQueue)配置,作业定义(Job Definition)的配置。
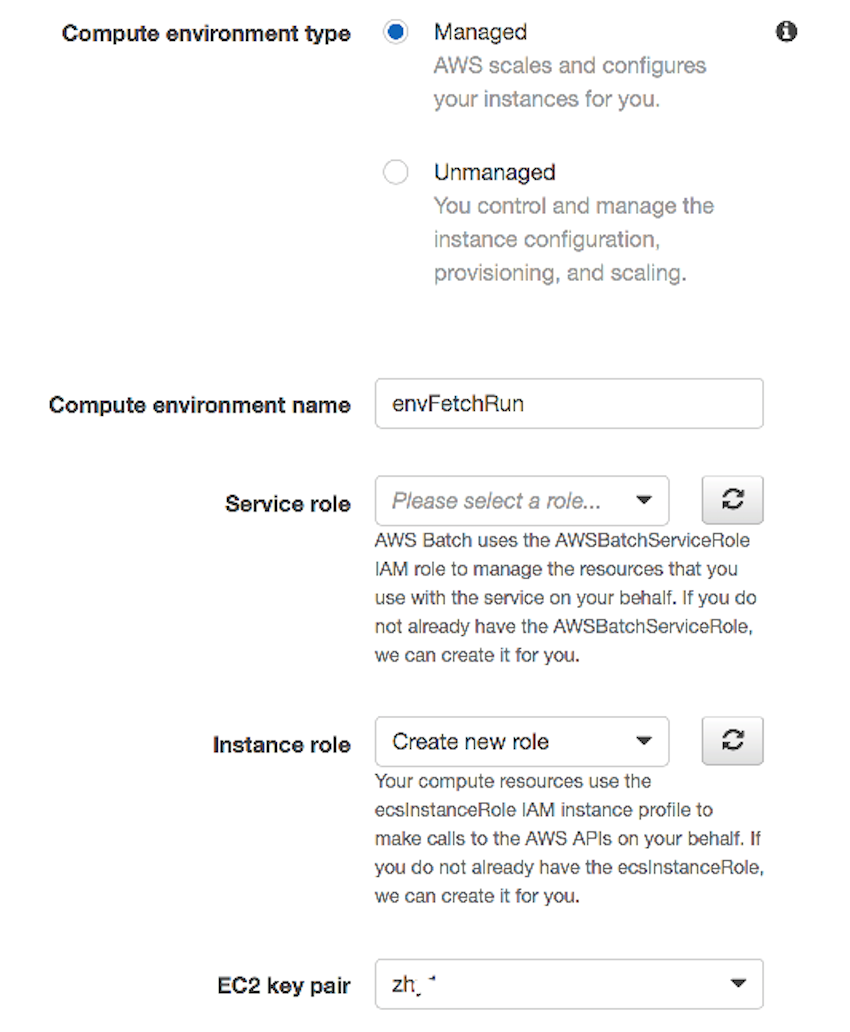
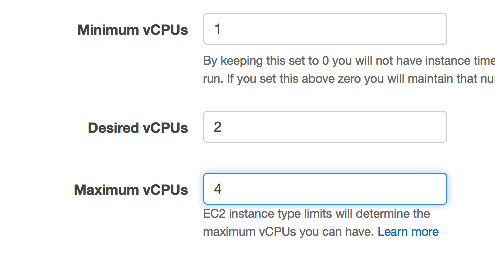
计算环境配置是在 Batch 控制台中选择 Compute Environment 页点击创建。其中计算环境参数组的配置如下图,环境类型选择托管,将由 Batch 来负责管理实例的选择和调度。计算资源参数组可指定需要的实例类型,其中最小 vCPU 数填 1,所需 vCPU 填 2,最大 vCPU 填 4,选择已有 EC2 密钥对,其他保持默认并点击创建。
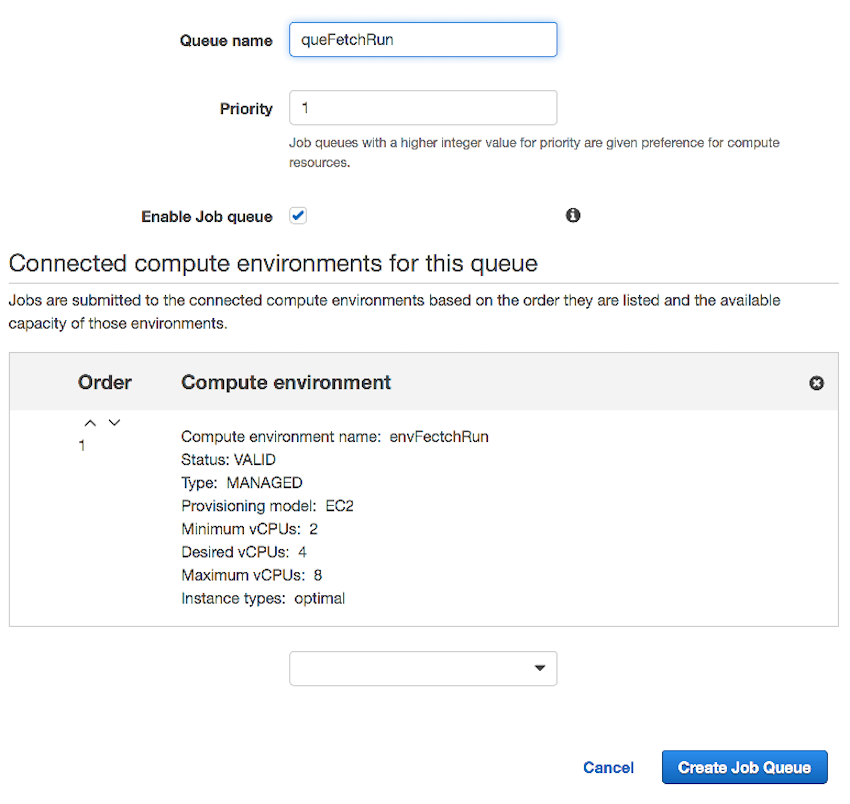
作业队列的配置是在 Batch 控制台中选择 Job Queue 页点击创建。指定队列名称 queFetchRun,Priority 优先级填 1,下方计算环境选择列表里选择刚创建的计算环境配置名称 envFetchRun,选取后会显示其摘要信息,如下图所示。
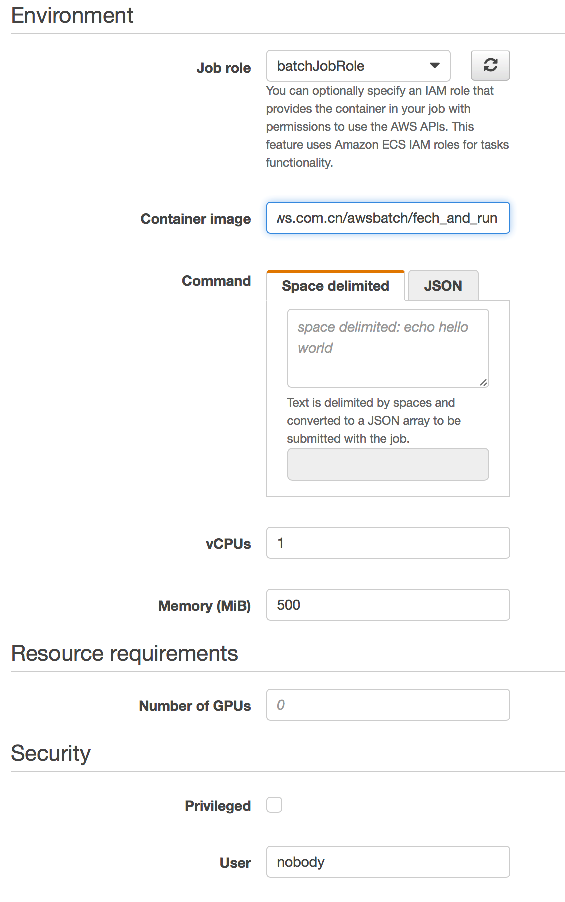
作业定义配置是在 Batch 控制台中选择 Job Definition 页点击创建。输入 Job 名称,例如 defFetchRun。Job role 里选取刚创建的 IAM 角色 batchJobRole。Environment 中的 Container image 一栏填入之前创建的 Dock 镜像的 URI 名称,例如 112233445566.dkr.ecr.cn-northwest-1.amazonaws.com/awsbatch/fetch_and_run。此处 Command 一栏保持为空, vCPU 填 1,Memory 填 500,Security 中的 User 栏填 nobody。全部填写完成后点击创建作业定义。
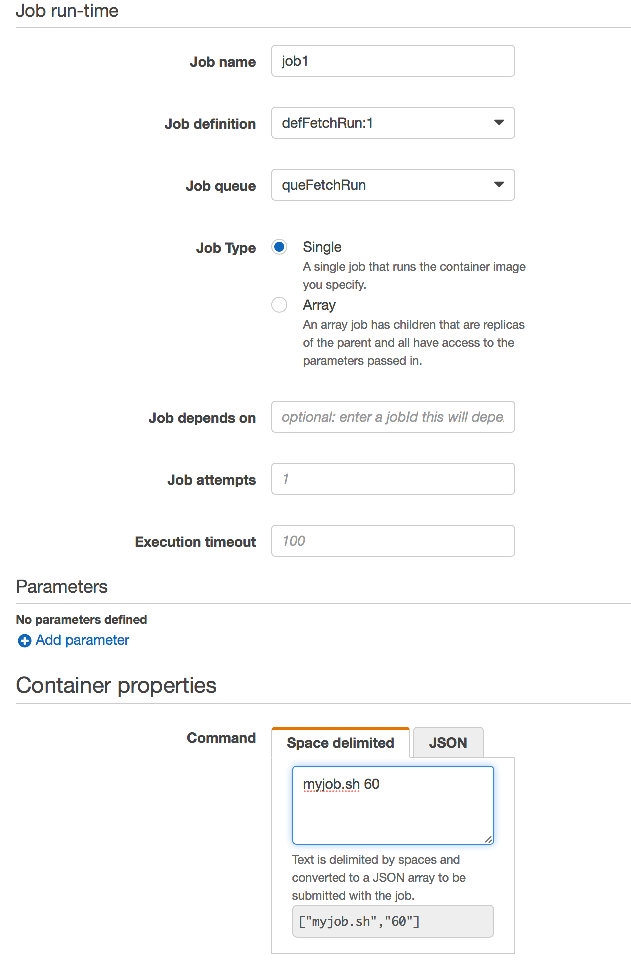
最后一步就是提交任务了。在 Batch 控制台选择 Jobs 页面点击“提交任务”按钮。Job name 栏输入指定的 Job 名称,Job definition 中选择前一步设置好的作业定义 defFetchRun:1(冒号后是版本号),Job queue 一栏选取前一步设好的作业队列名称 queFetchRun。Command 命令里面输入“myjob.sh 60”,设置好的信息如下图所示。
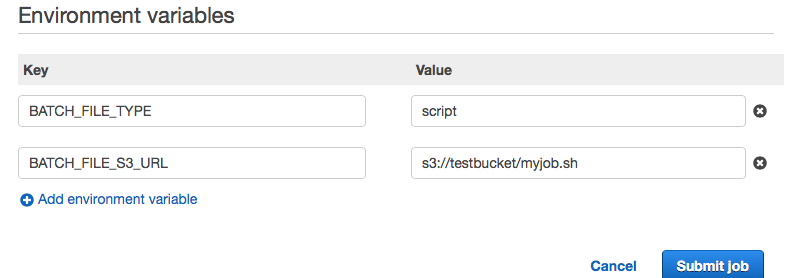
在环境变量一栏中添加环境变量的键值对:
- Key=BATCH_FILE_TYPE, Value=script
- Key=BATCH_FILE_S3_URL, Value=s3://testbucket/myjob.sh
最后点击提交任务。
任务提交后在 Batch 控制台可以查看其最新状态,任务会经历 submitted、pending、runnable、starting、running 各个状态。
任务执行完成后会在 succeeded 一页下,如下图所示:
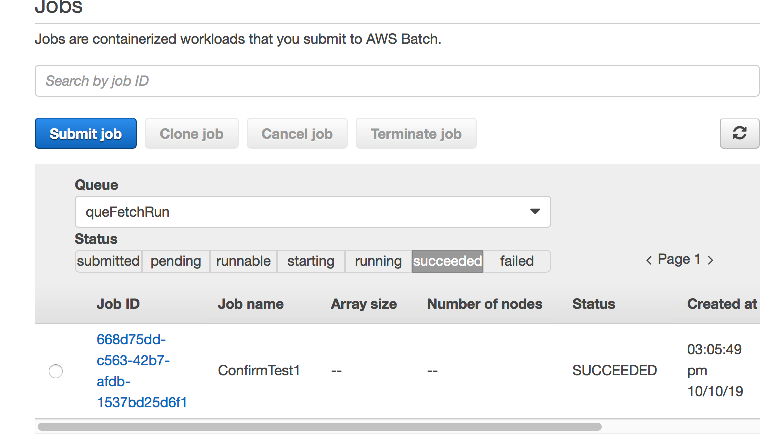
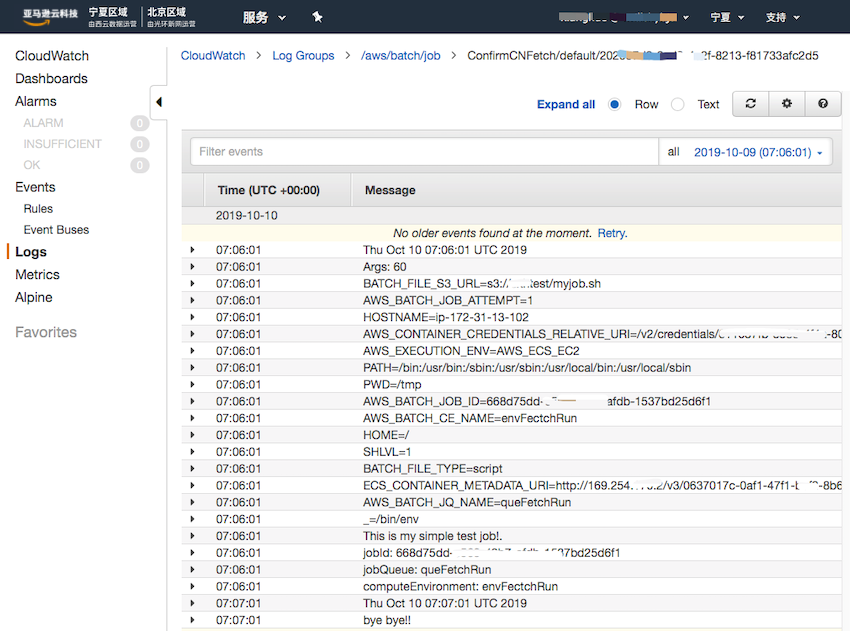
点击作业 ID 链接的详情页面中可点击“CloudWatch日志”的链接查看详细日志信息,其中就可以看到 myjob.sh 中 echo 输出的信息内容。如下图所示。
(可选步骤)如果需要批量提交更多数量的作业任务,可在提交任务参数页面中的 Job Type 中选择 Array 类型并填入一个测试数量值,同样可在 CloudWatch 中查看批量任务执行的情况,并在 EC2 的资源列表里可以看对应的实例扩展情况。
动手实验完成后记得回收释放相应资源,释放的资源包括:
- 禁用并删除 Batch 服务中的作业队列和计算环境中的配置资源。
- 终止制作 Docker 镜像所用的 EC2 实例。
- 删除 ECR 存储库中的 Image 镜像。
- S3 中的任务脚本删除。
- CloudWatch 中的对应日志记录删除。
相关文章







