发布于: Aug 26, 2022
基于 Amazon 的 i3.8xlarge 实例来搭建一个 ZFS 文件系统,并实践生产环境下 EDA 任务的常见管理运维操作
下面会基于Amazon 的 i3.8xlarge 实例来搭建一个 ZFS 文件系统,并实践生产环境下 EDA 任务的常见管理运维操作。包括搭建一个 ZFS 文件系统,配置读写缓存从而提高 IOPS,实现在线扩容以及快照的备份与恢复等操作。
在搭建 ZFS 文件之前,首先需要通过 Amazon Web Services 控制台启动一个 EC2 实例,本文中使用的操作系统为 Ubuntu Server 16.04,实例类型为 i3.8xlarge(具有 4 块 1.7 TiB SSD 来作为读写缓存),并使用 1TB 的 GP2 类型的 EBS 卷 。具体的启动实例过程在这里不展开描述,可以参照 Amazon EC2 文档。
创建 ZFS 文件系统的过程比较简单。通过以下步骤及命令即可安装一个 ZFS 文件系统以及存储池。
$sudo apt-get update -y #安装文件系统 $sudo apt-get -y install zfs #列出当前设备 $sudo lsblk #在指定存储卷上创建存储池 $sudo zpool create -f edastore /dev/xvdb #挂载存储池 $sudo zfs set mountpoint=/edastore edastore #查看文件池状态 $sudo zpool status
在一些场景下,为了避免用户在存储池中过多的存储一些不必要的文件,造成存储空间的过快增长,并在实际上造成存储空间的浪费,可以根据前期的项目规划和目录规划,针对目录层级或者用户层级设置相应的 Quota,在写入的数据超过 Quota 定义的大小尺寸后,不能再继续写入数据。 Quota 设置命令如下:
#创建文件系统 $sudo zfs create edastore/tools #设置目录 quota: $sudo zfs set quota=1G edastore/tools #设置用户quota $sudo zfs set userquota@ubuntu=2GB edastore/tools #验证quota设置,通过dd命令写入数据进行测试 $sudo dd if=/dev/zero of=/edastore/tools/sun.txt bs=2G count=1

针对 EDA 的 Library 库,在大量并发任务的情况下,会有非常高的读性能的要求。可以结合 ZFS 文件系统的读写缓存以及 I3 实例的 NVMe 本地实例存储,提高并发读的性能。实际操作如下:
#查看当前磁盘,会看到有四块 NVMe 设备/dev/nvme0n1,/dev/nvme1n1,#/dev/nvme2n1,/dev/nvme3n1 $sudo lsblk #插入缓存盘 $sudo zpool add -f edastore cache /dev/nvme0n1 /dev/nvme1n1 #增加log缓存 $sudo zpool add edastore log mirror nvme2n1 nvme3n1 #检查当前状态 $sudo zpool status edastore
检查 ZFS pool 的状态我们可以看到,当前缓存已经插入成功。
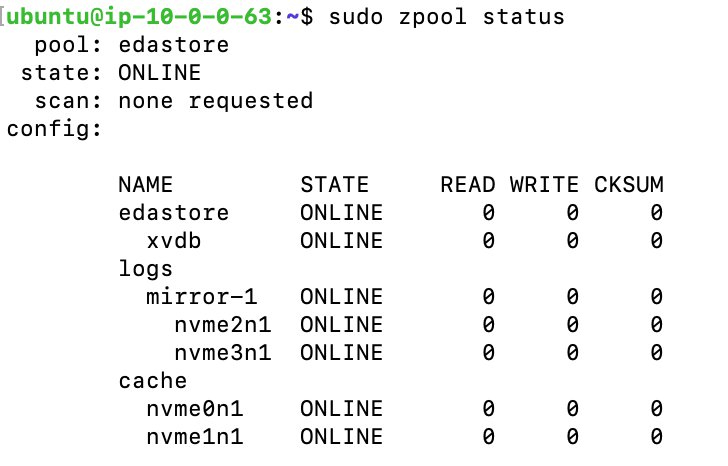
可以通过下面的操作分别对于加缓存和不加缓存的两种情况进行测试,验证缓存对 ZFS IOPS 和吞吐的提升情况。
#安装 fio sudo apt-get install -y fio #创建文件系统 $sudo zfs create edastore/projectA #测试随机写 $sudo fio --directory=/edastore/projectA --direct=0 --rw=randwrite --refill_buffers --norandommap --randrepeat=0 --ioengine=libaio --bs=4k --size=2G --iodepth=32 --numjobs=20 --runtime=300 --group_reporting --name=4k_mixed #测试随机只读 $sudo fio --directory=/edastore/projectA --direct=0 --rw=randread --refill_buffers --norandommap --randrepeat=0 --ioengine=libaio --bs=4k --size=2G --iodepth=32 --numjobs=20 --runtime=300 --group_reporting --name=4k_mixed #检查缓存 的 读写状态 $sudo zpool iostat -v 5
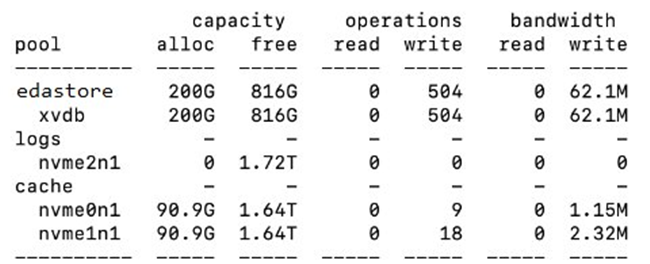
需要注意的是,添加高速缓存设备之后,这些设备中将逐渐填充来自主内存的内容。填充设备可能需要一个小时以上的时间,具体取决于高速缓存设备的大小。因此在通过 fio 写入数据以后,测试缓存的读性能需要等到数据填充到缓存盘以后。通过下图我们可以看到,目标卷中的数据为 200G,而 NVMe 的 cache 中已经缓存了超过 90% 的数据。
下面通过 fio 分别测试 20 个线程和 100 个线程并发随机读写的场景,测试结果如下所示,可以看到无论是 IOPS 还是吞吐量,在 20 个并发的情况下,有 NVMe 缓存的性能差不多是无 NVMe 缓存性能的 12 倍,而在 100 个并发的情况下,有 NVMe 缓存的性能差不多是无 NVMe 缓存性能的 7 倍。因此通过 Amazon I3 实例的本地 NVMe 实例存储可以显著提高 ZFS 文件系统的 IOPS 和吞吐量。
|
线程数 |
IOPS |
吞吐量 |
无 NVMe 缓存 |
20 |
168K |
675MB/s |
有 NVMe 缓存 |
20 |
2144K |
8377.2MB/s |
无 NVMe 缓存 |
100 |
174K |
696MB/s |
有 NVMe 缓存 |
100 |
1209K |
4724.2MB/s |
需要说明的是,本测试场景是在 ZFS 文件系统本机进行的 fio 压测, ZFS 文件系统不支持参数 direct=1 直接写磁盘的测试,因此数据反应的不是磁盘本身的性能。另外多次执行测试结果数据有一定的波动,这里取的是数次执行结果的平均值。
在企业的真实业务中,Library 是多任务多项目共享的,因此随着时间的推移, Library 文件的规模也在不断增长。企业在初始规划时,从成本的角度设计了一个较小的满足当前需求的存储容量。那么随着存储规模的增长,存储如何扩容,并且是在线扩容,不要对运行中的任务造成任何影响,就是企业最直接的一个需求。
ZFS 文件系统的存储池特性很好的支持了这样的用户需求。通过增加一块新的 EBS 卷到存储池中,可以实现:1) 工具端的访问路径不需要做任何修改;2) 运行中的任务没有任何影响; 3) 数据会在新增的盘上自动平衡,从而提升并发读写的效率。具体扩容步骤如下:
- 在 Amazon EC2 服务里,选择卷服务, 创建一块 EBS 卷, 容量可以自定义, 单卷最大不超过 16T,可以根据实际情况而定;
- 将新创建的卷挂载到这台 Amazon I3 服务器机器上;
- 执行 lsblk 命令查看新加卷的设备号;
- 执行添加和升级命令。
#检查新加设备号
$lsblk
#执行添加命令,其中edastore为pool名称:
$sudo zpool add edastore /dev/{deviceno}
$执行升级命令:
$sudo zpool upgrade edastore
#检查 pool 状态
$sudo zpool status edastore
由于 ZFS 存储池可以使用多块 EBS 卷,数据分布在所有的 EBS 卷上,通过利用 ZFS 文件系统的存储快照功能,创建快照,并与开源项目 Z3 结合,从而实现将 ZFS 本地快照上传到 Amazon S3,以及从 Amazon S3 快照恢复存储池的功能。
Z3 备份与恢复的基本原理是围绕 zfs send 和 zfs receive 的管道来实现的。Z3 backup 命令,首先是执行 zfs 的 snapshot 命令创建本地快照,然后执行 z3 send 以及结合 Amazon S3 multi-part 上传接口,将快照文件上传到 Amazon S3 存储桶。Z3 restore 命令,首先通过 Amazon S3 的接口下载 snapshot 文件到本地,执行 ZFS 命令将文件恢复为 ZFS 本地快照,再执行 zfs receive 恢复快照到 zfs 文件系统。具体可以参考 ZFS 的文档以及开源 Z3 项目。
基于 Z3 的备份与恢复步骤如下:
快照备份
- 通过 Amazon Web Services 控制台或者 CLI 创建快照 S3 存储桶: eda-snapshot
- 登录 ZFS 文件服务器,安装 ZFS 备份工具 Z3
- 安装 Z3 并设置配置文件
#如果没有 python-pip 工具,执行安装 $sudo apt install -y python-pip $export LC_ALL=en_US.UTF-8 #pip 安装 Z3 $sudo pip install z3 #安装其他依赖 $sudo apt-get install pv $sudo apt-get install pigz # 更新配置文件 $sudo mkdir /etc/z3_backup $sudo vi /etc/z3_backup/z3.conf
参考配置文件如下:
##sample configuration file [main] #Amazon S3的endpoint。在开源的配置文件中没有说明,在中国区一定要配置#这个参数 HOST = s3.cn-northwest-1.amazonaws.com.cn #Amazon S3存储桶名称 BUCKET= eda-snapshot #AWS的Access Key和Secret Key S3_KEY_ID= ***** S3_SECRET= ***** #上传Amazon S3并发线程数 CONCURRENCY=64 #上传失败重试次数 MAX_RETRIES=3 #Amazon S3快照对象前缀 S3_PREFIX= project #文件系统可以配置多个,也可以直接配置存储池的名称 FILESYSTEM=edastore/projectA # only backup snapshots with this prefix SNAPSHOT_PREFIX=
- 创建快照
#创建快照 $sudo zfs snapshot edastore/projectA@projectA.snap01 #检查快照是否创建成功 $sudo zfs list -t snapshot
- 执行 Z3 backup 命令,快照将会被上传到配置文件中指定的 S3 存储桶
#Z3 backup $sudo z3 backup --full --snapshot projectA.snap01
- 验证 Amazon S3 存储桶的快照文件
##执行 S3 list 命令 $aws s3 ls s3://eda-snapshot/edastore/ --region cn-northwest-1
快照恢复
如果 ZFS 文件系统损坏,比如对于 project 目录或者 home 目录来说,通常会因为研发工程师在文件系统上的误操作要求恢复出指定时间前的文件,那么通过 Z3 恢复一个指定时间的快照,就可以实现单个文件或者整个文件系统的恢复。具体恢复步骤如下:
- 如果原文件系统损坏,需要重新启动一个新的原有配置的 Amazon EC2,并按照上述步骤安装 ZFS,插入缓存盘,安装 Z3,并设置好 Z3 的配置文件
- 创建同名的存储池以及文件系统
- 执行 Z3 恢复命令
#执行 z3恢复命令 $sudo z3 restore projectA.snap01 --force ##检查 zfs 文件: zfs status $sudo zpool status $cd /edastore/projectA ##检查是否所有文件都正确恢复 $ls -la
- 执行 Job,验证恢复的文件的正确性。可以根据实际业务场景,比如执行典型的 Job,来验证恢复的文件的完整性和正确性;
基于 Amazon I3 实例以及 ZFS 文件系统搭建的大容量高性能的存储系统已经应用到多个 EDA 的案例中,通过本方案,帮助用户实现了一个可弹性扩展的、安全的、低成本的、高性能的共享文件存储系统。对于那些需要大规模并发访问共享文件存储系统的其他场景例如 HPC 场景,本方案也是一个可以选择的共享存储设计方案。
相关文章







