我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用基于 C6i 英特尔的 Amazon EC2 实例加速亚马逊 SageMaker 的推断
这是与英特尔的安东尼·万斯共同撰写的客座文章。
客户一直在寻找在不增加每笔交易成本和不牺牲结果准确性的情况下提高机器学习 (ML) 推理工作负载的性能和响应时间的方法。在 运行
量化是一种通过使用 8 位整数 (INT8) 等低精度数据类型而不是通常的 32 位浮点 (FP32) 来表示权重和激活次数来降低运行推理的计算和内存成本的技术。在下例图中,我们显示了基于 BERT 的模型在 C6i 中的 INT8 推理性能。
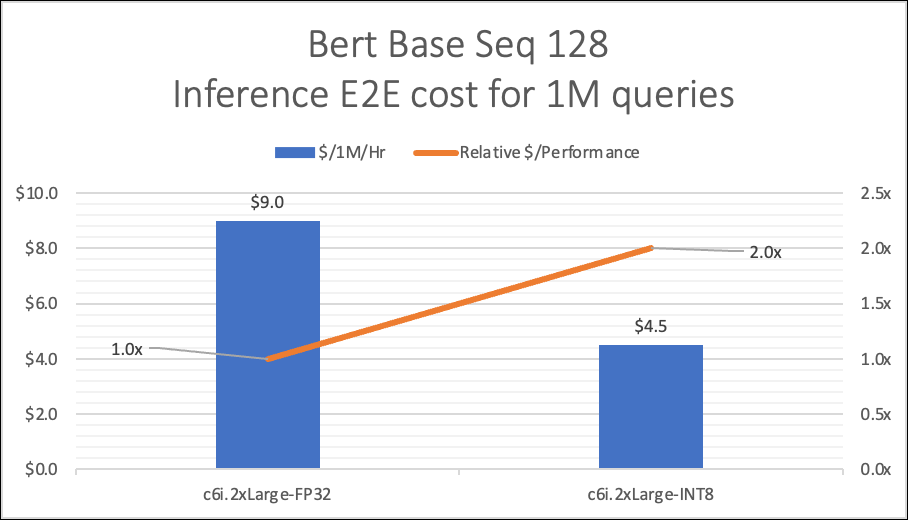
BERT-Base 使用 Squad v1.1 进行了微调,其中 PyTorch (v1.11) 是与英特尔® PyTorch 扩展模块一起使用的机器学习框架。使用批量大小为 1 进行比较。更高的批量大小将为每100万个推断提供不同的成本。
在这篇文章中,我们将向您展示如何使用您
技术概述
在深度学习的背景下,迄今为止用于研究和部署的主要数值格式是 32 位浮点数或 FP32。但是,降低带宽的需求和深度学习模型的计算要求推动了对使用低精度数值格式的研究。已经证明,权重和激活值可以使用 8 位整数(或 INT8)来表示,而不会显著降低精度。
EC2 C6i 实例提供了许多新功能,可提高 AI 和 ML 工作负载的性能。C6i 实例在 FP32 和 INT8 模型部署中提供了性能优势。通过 AVX-512 改进支持 FP32 推理,AVX-512 VNNI 指令支持 INT8 推理。
C6i 现已在 SageMaker 端点上线,开发人员应该预计,与 FP32 推理相比,它的 INT8 推理性价比提高了两倍以上,与 C5 实例 FP32 推断相比,性能提升了多达四倍。有关详细信息和基准测试数据,请参阅附录。
在边缘部署深度学习以进行实时推理是许多应用领域的关键。它在网络带宽、网络延迟和功耗方面显著降低了与云通信的成本。但是,边缘设备的内存、计算资源和功率有限。这意味着必须针对嵌入式部署对深度学习网络进行优化。对于 TensorFlow 和 PyTorch 等机器学习框架,INT8 量化已成为进行此类优化的一种流行方法。SageMaker 为您提供自带容器 (BYOC) 方法和集成工具,以便您可以运行量化。
有关更多信息,请参阅
解决方案概述
实施该解决方案的步骤如下:
- 预置 EC2 C6i 实例以量化并创建 ML 模型。
- 使用提供的 Python 脚本进行量化。
- 创建 Docker 镜像,使用 BYOC 方法在 SageMaker 中部署模型。
-
使用 A
mazon Simple Storage Servic e (Amazon S3) 存储桶复制模型和代码以供访问 SageMaker。 -
使用
亚马逊弹性容器注册表 (亚马逊 ECR) 托管 Docker 镜像。 -
使用
亚马逊云科技 命令行接口 (亚马逊云科技 CLI) 在 SageMaker 中创建推理终端节点。 - 运行提供的 Python 测试脚本,调用 INT8 和 FP32 版本的 SageMaker 端点。
此推理部署设置使用来自 Hugging Face 变形金刚存储库(csarron/bert-base-uncased-squad-v1)中的 Bert-Base 模型。
先决条件
以下是创建部署设置的先决条件:
- 安装了 亚马逊云科技 CLI 的 Linux 外壳终端
- 有权创建 EC2 实例的 亚马逊云科技 账户(C6i 实例类型)
- SageMaker 有权部署 SageMaker 模型、端点配置、端点
-
用于配置 IAM 角色@@
和策略的 亚马逊云科技 身份和访问管理 (IAM) 权限 - 访问亚马逊 ECR
- SageMaker 有权创建带有启动端点说明的笔记本
在 SageMaker 上生成和部署量化的 INT8 模型
打开 EC2 实例来创建您的量化模型,并将模型工件推送到 Amazon S3。对于端点部署,使用 PyTorch 和英特尔® PyTorch 扩展程序创建自定义容器,以部署优化的 INT8 模型。容器被推送到亚马逊 ECR 中,并创建了一个基于 C6i 的端点来服务 FP32 和 INT8 模型。
下图说明了高级流程。
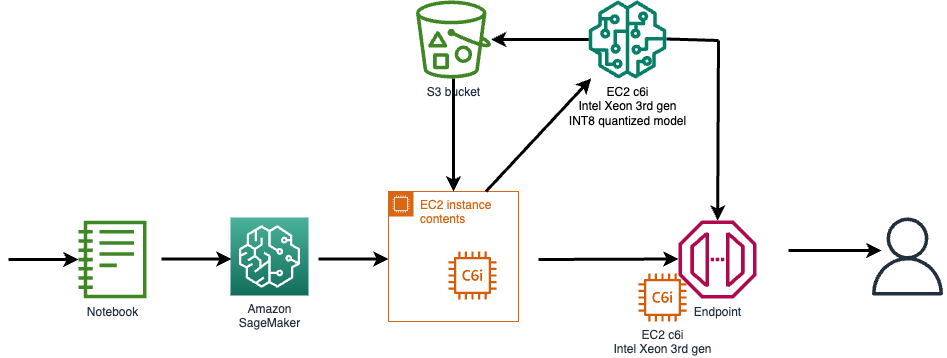
要访问代码和文档,请参阅
示例用例
斯坦福问答数据集(SquaD)是一个阅读理解数据集,由众人对一组维基百科文章提出的问题组成,其中每个问题的答案都是相应阅读段落中的一段文字或 跨度 ,否则问题可能无法回答。
以下示例是使用 BERT 基础模型的问答算法。给定文档作为输入,模型将根据输入文档中的学习和上下文回答简单的问题。
以下是示例输入文档:
亚马逊雨林(葡萄牙语:Floresta Amazonnica 或 Amazonia;西班牙语:Selva Amazonica、Amazonía 或通常是亚马逊;法语:Forét amazonienne;荷兰语:Amazoneregenwoud),在英语中也被称为亚马逊或亚马逊丛林,是一种潮湿的阔叶森林,覆盖了南美亚马逊盆地的大部分地区。该盆地占地7,000,000平方千米(2700,000平方英里),其中550万平方千米(210万平方英里)被雨林覆盖。
对于 “哪个名字也被用来用英语描述亚马逊雨林?”我们得到答案:
对于 “盆地覆盖了多少平方千米的热带雨林?”我们得到答案:
在 PyTorch 中量化模型
本节简要概述了使用 PyTorch 和英特尔扩展的模型量化步骤。
这些代码片段源自 SageMaker 示例。
让我们详细介绍 quantize.py 文件中 ipex_Quantize 函数的更改。
- 导入 PyTorch 的英特尔扩展以帮助量化和优化,并导入 torch 用于数组操作:
- 对 100 次迭代应用模型校准。在这种情况下,您正在使用 SquaD 数据集校准模型:
- 准备示例输入:
- 使用以下配置将模型转换为 INT8 模型:
- 运行两次向前传递迭代以启用融合:
- 最后一步,保存 TorchScript 模型:
清理
有关清理创建的 亚马逊云科技 资源 的步骤,请参阅
结论
使用 INT8 量化,SageMaker 端点中的新 EC2 C6i 实例可以将推理部署速度提高多达 2.5 倍。使用英特尔 PyTorch 扩展中的一些 API,可以在 PyTorch 中量化模型。建议在 C6i 实例中量化模型,以便在端点部署中保持模型的准确性。SageMaker 示例
我们鼓励您使用 EC2 C6i 实例类型使用 INT8 量化创建新模型或迁移现有模型,亲眼看看性能的提升。
通知和免责声明
本文档未授予任何知识产权的许可(明示或暗示、禁止反言或其他方式),唯一的例外是本文档中包含的代码受
附录
支持 INT8 部署的 SageMaker 中的新 亚马逊云科技 实例
下表列出了支持和不支持
| Instance Name | Xeon Gen Codename | INT8 Enabled? | DL Boost Enabled? |
| ml.c5. xlarge – ml.c5.9xlarge | Skylake/1 st | Yes | No |
| ml.c5.18xlarge | Skylake/1 st | Yes | No |
| ml.c6i.1x – 32xlarge | Ice Lake/3 rd | Yes | Yes |
总而言之,启用 INT8 支持 INT8 数据类型和计算;启用 DL Boost 支持深度学习增强。
基准数据
下表比较了 c5 和 c6 实例的成本和相对性能。
延迟和吞吐量是通过发送到 Sage 制造商端点的 10,000 次推理查询来衡量的。
| E2E Latency of Inference Endpoint and Cost analysis | ||||||
| P50(ms) | P90(ms) | Queries/Sec | $/1M Queries | Relative $/Performance | ||
| C5.2xLarge-FP32 | 76.6 | 125.3 | 11.5 | $10.2 | 1.0x | |
| c6i.2xLarge-FP32 | 70 | 110.8 | 13 | $9.0 | 1.1x | |
| c6i.2xLarge-INT8 | 35.7 | 48.9 | 25.56 | $4.5 | 2.3x | |
预计INT8模型将提供2-4倍的实际性能改进,大多数模型的精度损失不到1%。上表涵盖了开销延迟(NW 和演示应用程序)
基于 BERT 的模型的精度
下表汇总了采用 SquaD v1.1 数据集的 INT8 模型的准确性。
| Metric | FP32 | INT8 |
| Exact Match | 85.8751 | 85.5061 |
| F1 | 92.0807 | 91.8728 |
英特尔的 PyTorch 扩展程序
英特尔® PyTorch* 扩展程序(GitHub 上的一个开源项目)通过优化对 PyTorch 进行了扩展,以进一步提升英特尔硬件的性能。大多数优化最终将包含在现有 PyTorch 版本中,扩展的目的是在英特尔硬件上为 PyTorch 提供最新的功能和优化。示例包括 AVX-512 矢量神经网络指令 (AVX512 VNNI) 和英特尔® 高级矩阵扩展 (英特尔® AMX)。
下图说明了 PyTorch 架构的英特尔扩展。
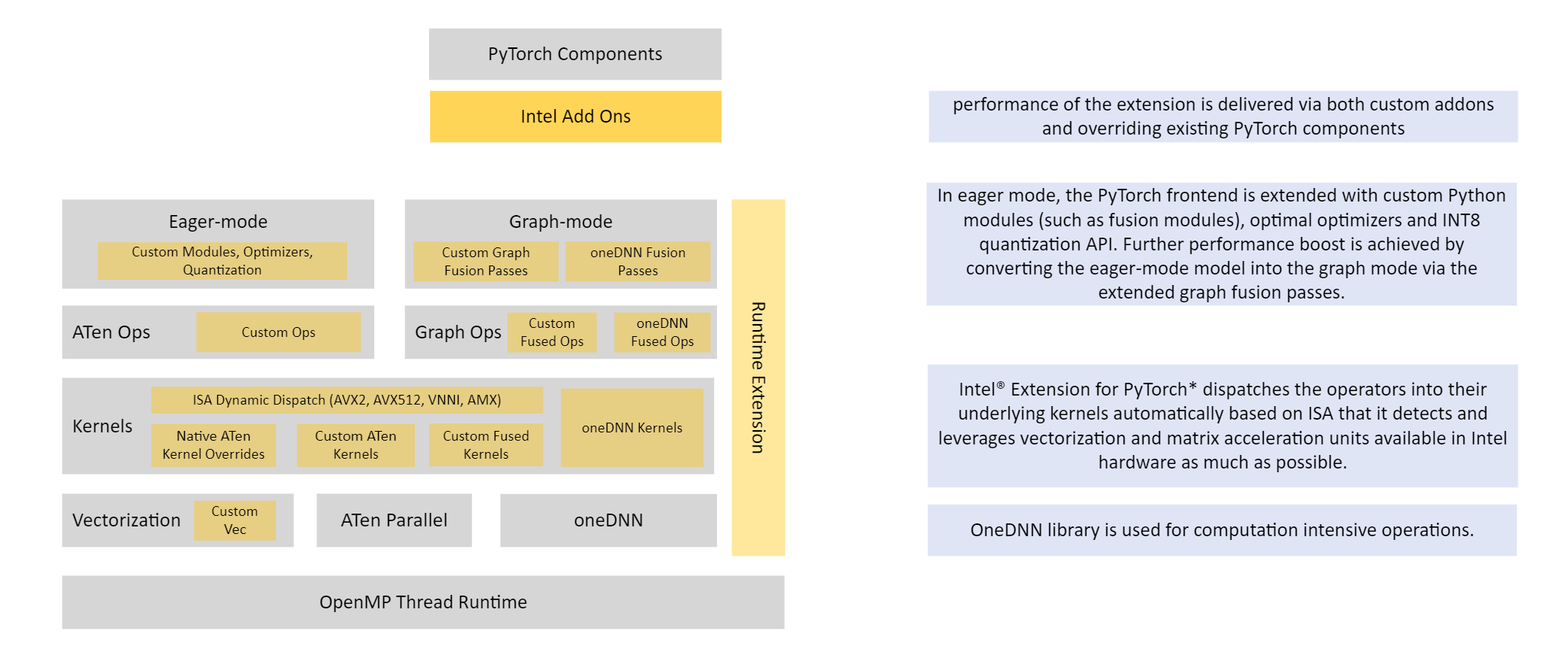
有关英特尔® PyTorch 扩展模块的更多详细用户指南(功能、性能调整等),请参阅
作者简介
 Rohit Chowdhary 是 亚马逊云科技
战略客户团队的高级解决方案架构师。
Rohit Chowdhary 是 亚马逊云科技
战略客户团队的高级解决方案架构师。
 Aniruddha Kappagantu 是 AW
S 人工智能平台团队的软件开发工程师。
Aniruddha Kappagantu 是 AW
S 人工智能平台团队的软件开发工程师。
 Antony Vance
是英特尔的人工智能架构师,在计算机视觉、机器学习、深度学习、嵌入式软件、GPU 和 FPGA 方面拥有 19 年的经验。
Antony Vance
是英特尔的人工智能架构师,在计算机视觉、机器学习、深度学习、嵌入式软件、GPU 和 FPGA 方面拥有 19 年的经验。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。