我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 DMS 实现从本地 Oracle 向 Amazon RDS 的高性能迁移
许多客户将
有多个选项可用于将 Oracle 数据库迁移到适用于 Oracle 的亚马逊 RDS(有关详细信息,请参阅
在我们上一篇博客文章
解决方案概述
下图描述了 亚马逊云科技 DMS 如何从本地 Oracle 数据库提取数据并将其推送到适用于 Oracle 的亚马逊 RDS。
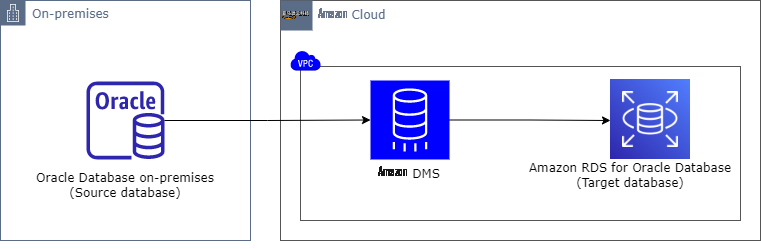
在以下部分中,我们将讨论迁移大型表和 LOB 列、将表拆分为多个任务的策略以及其他重要注意事项。
先决条件
在我们使用 亚马逊云科技 DMS 迁移数据库之前,您必须具备以下条件:
- 在现有本地环境上运行的 Oracle 源数据库
- 在亚马逊 RDS 上运行的目标 Oracle 数据库
-
具有 适用于您的迁移工作负载
的最佳实例类型 的 亚马逊云科技 DMS 复制实例 -
从 亚马逊云科技 DMS 复制实例到源和目标 Oracle 数据库的@@
网络连接 -
对
源 和目标 Oracle 数据库具有所需权限的数据库用户帐户
此外,在开始迁移
迁移期间适用于 Oracle 的亚马逊 RDS
在本节中,我们将讨论迁移过程中的一些注意事项,然后再深入研究迁移方法。
禁用存档日志
在迁移期间,适用于 Oracle 的 Amazon RDS 上的数据库无法用于生产,因此您可以临时禁用存档日志。这有助于将存储 I/O 专用于数据迁移。此外,在
noarchivelog
模式运行目标数据库更有意义。
禁用多可用区
Amazon RDS 提供了在
增加重做日志组的大小
默认情况下,适用于 Oracle 的亚马逊 RDS 有四个在线重做日志,每个日志 128 MB。如果这太小,将导致频繁切换日志,并增加
此消息表示重做日志的切换速度如此之快,以至于与日志切换相关的检查点未完成。这意味着重做日志组由 Oracle LGWR 进程填充,现在正在等待第一个检查点完成。在第一个检查点完成之前,处理将停止。尽管这会花更短的时间,但由于这种情况会多次发生,它会导致数据库迁移的总体降级。为了解决这个问题,建议
确保启用存档日志记录、启用多可用区并设置重做日志大小,以便日志切换间隔为 15 到 30 分钟,然后再转到生产环境。
满载后创建主键和二级索引
禁用主键和二级索引可以显著提高负载性能。使用 亚马逊云科技 DMS,您可以选择在加载数据后通过更改任务设置
createpkAfterFullLoad 来创建
主键。
迁移大型表
默认情况下,亚马逊云科技 DMS 使用单线程从要迁移的表中读取数据。这意味着,在满负载数据迁移阶段,亚马逊云科技 DMS 会在源表上启动 SELECT 语句。它会进行全表扫描,但不建议对大型表进行这种扫描,因为它会导致按顺序扫描所有块并产生大量不必要的 I/O。这最终会降低源数据库的整体性能和迁移速度。
尽管这对于较小的表来说是可以接受的,但在大型表上执行全表扫描可能会导致整个迁移工作变慢,还可能导致 ORA-01555 错误。
在索引列上使用并行加载将显著提高性能,因为它会强制优化器在卸载期间使用索引扫描而不是全表扫描。选择范围分段的重要因素之一是确定正确数量的分区,并确保数据分布均匀。例如,如果您有一个包含 20 亿行的表,并且使用五个范围来并行加载它们,那么您仍在对该表执行全表扫描。
识别 亚马逊云科技 DMS 向源数据库发送的 SELECT 查询是否未进行全表扫描的一种方法是使用登录触发器 在会话级别
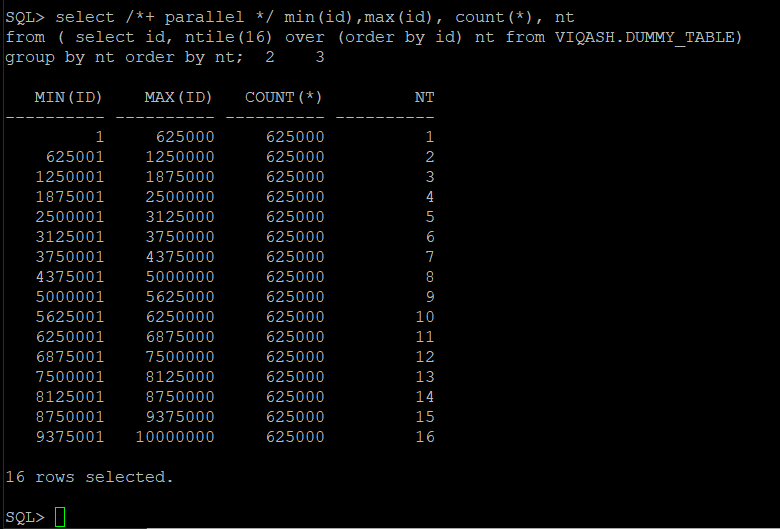
以下查询使用
ntile
函数来标识具有每个分区中确切行数的列。它还提供了最大值,可以将其用作表映射的范围,以便并行加载。即使你的列是 UUID,你也可以使用它。
在主实例上运行之前,请务必在备用实例或开发实例中运行它。
以下屏幕截图显示了查询输出的示例。
ID
是我们计划在其上为表
VIQ
ASH.DUMMY_TABLE 创建范围边界的列。指定的分区数为 16,这对于一个 1000 万行的表来说似乎足够了。
在表映射中,可以为 JSON 中的非分区表指定此值。有关更多信息,请参阅
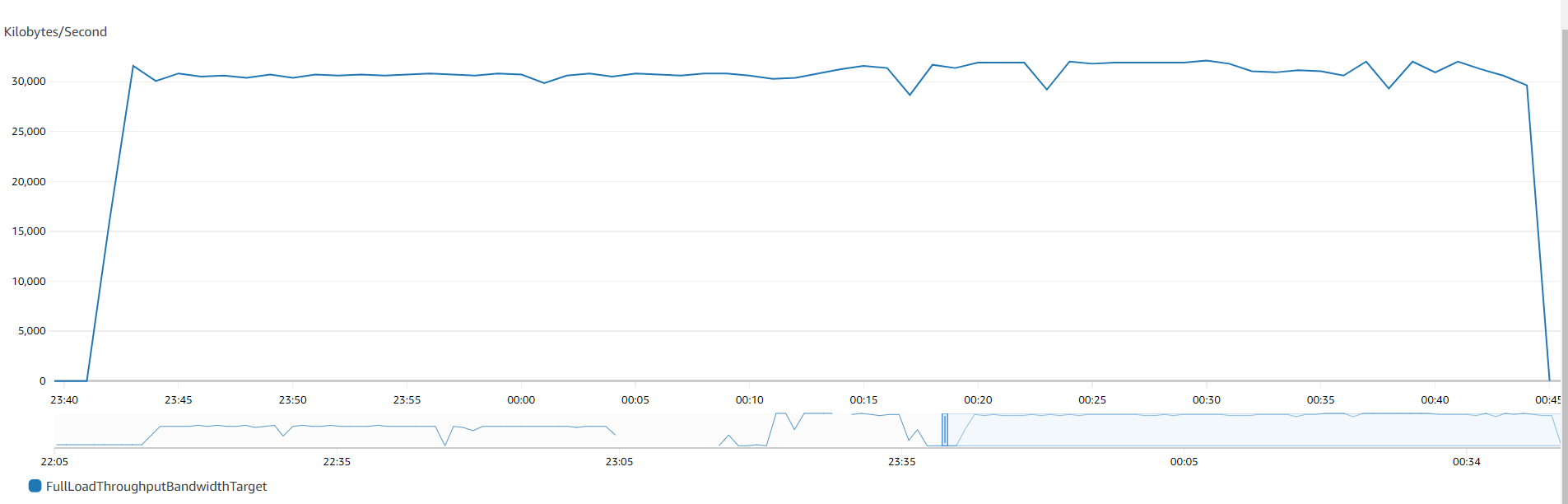
在我们的测试环境(
第一张图显示了没有并行加载选项的单线程方法。
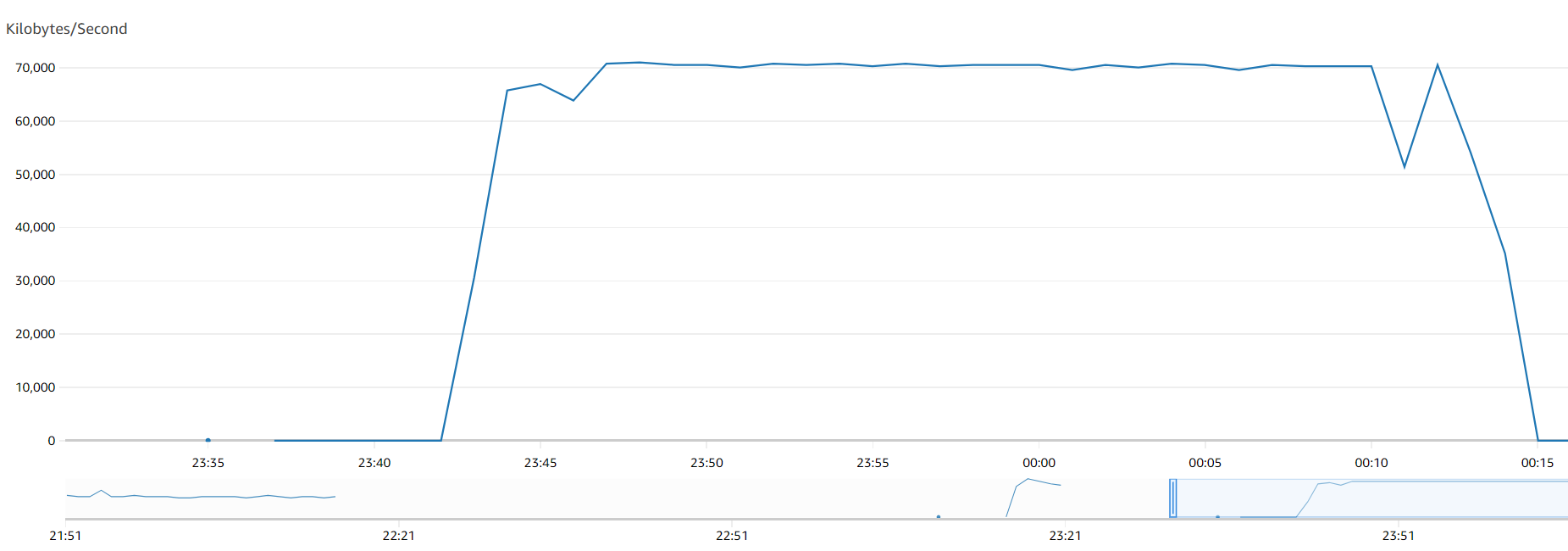
下图显示了 24 个范围内的吞吐量。
请记住,性能可能因不同因素而有很大差异,例如:
-
良好的网络带宽
-例如,如果您在本地数据库与 亚马逊云科技 区域之间有共享链接 (VPN),则您看到的性能可能与我们的示例不同,因为您的网络带宽可能会饱和。这可能会影响负载,你可能无法使用更高的并行度。另一方面,如果您使用专用链接或
亚马逊云科技 Direct Connect ,则在加载大型数据集时可能会看到更好的性能。 - LOB — 表中的 LOB 列数越多,加载此类表需要额外的内存,而配置较低内存的复制实例将影响负载性能。下一节将介绍高效复制 LOB 数据的其他选项。
-
复制实例
— 拥有更多的 CPU 和内存是实现并行处理的理想选择。有关选择最佳大小的指南,请参阅
为复制实例 选择最佳大小 。
根据我们的测试,当使用具有最佳配置的并行加载表时,我们花费了一半的时间来加载表,并且我们在卸载数据时避免了对源数据库进行全表扫描。
迁移 LOB 列
对于任何数据库迁移而言,迁移 LOB 列都具有挑战性,因为它们包含大量数据。亚马逊云科技 DMS 提供三种迁移 LOB 列的选项:有限模式、完整模式和内联模式。
有限的 LOB 模式
这是任何 LOB 列迁移的首选模式,因为它指示 亚马逊云科技 DMS 将 LOB 列视为 VARCHAR 数据类型、
列中任何大于 LOB 大小 (KB) 的数据都将被截断,并在 亚马逊云科技 DMS 日志中写入以下警告:
要确定 LOB 列的最大大小(以 KB 为单位),可以使用以下查询:
因此,如果您的 LOB 列大于 63 KB,请考虑完整的 LOB 模式或内联 LOB 模式,这可能会在加载表时提供更好的性能。
完整 LOB 模式
不管 LOB 大小如何,此模式都会迁移整列。这是最慢的 LOB 迁移选项,因为 亚马逊云科技 DMS 没有关于预期的最大 LOB 大小的信息。它只使用 LOB 区块大小 (KB)(默认为 64 KB)来分段 LOB 数据。然后,它将所有区块逐段发送到目标,直到整个 LOB 列都迁移完毕。
完整 LOB 模式执行两步加载数据的方法:它在目标上插入
empty_clob
或
empty_blob
,然后在源 上查找以对目标执行更新。因此,您需要在源表上使用主键才能使用完整 LOB 模式加载 LOB。如果您没有主键,亚马逊云科技 DMS 会在日志上打印以下消息:
内联 LOB 模式
此模式是一种混合方法,它结合了受限 LOB 模式和完整 LOB 模式的功能,并在加载 LOB 对象时提供更好的性能。根据您的任务配置,亚马逊云科技 DMS 将选择根据数据大小执行内联或 LOB 查询。因为它也使用完整 LOB 模式,所以在源表上也必须有主键或唯一键。允许的行内 LOB 大小的最大值也为 2 GB,这与限制 LOB 模式相同。
了解您的 LOB 数据
如前所述,迁移 LOB 通常很乏味,因此在选择设置之前,了解表的 LOB 分布非常重要。如果表中的分布差异很大,则加载数据会变得更具挑战性。以下查询可能有助于分析您的 LOB 分布和为任务选择正确的设置。此脚本创建了一个表,用于分析表的 LOB 分布:
*将
LOB-COLUMN-NAME 替换为实际的 L
。
OB 列 ,将 LOB_TABLE
替换为实际的表名
在生产环境上运行之前,请务必在备用实例或开发实例中运行它。
创建表后,您可以使用以下查询来检查源表中的 LOB 分布:
输出与以下屏幕截图类似(基于源数据库表中的行数)。

此查询输出突出显示,有六行的最大 LOB 大小为 5 字节,占整个表数据(查询输出的第一行)的 85%。只有一行,其长度为 120,045,568 字节 (115 MB),占表中整个数据的14%。
基于这些信息,如果我们使用内联 LOB 模式迁移六行,使用完整 LOB 模式仅迁移一行,则效率会更高。为此,我们可以按如下方式修改任务设置:
使用此任务设置,使用内联 LOB 模式迁移六行(每行 5 字节)。这是因为参数
inlineLobmaxSize
设置 为 32 KB。这意味着 LOB 大小小于 32 KB 的任何 LOB 行都将使用受限 LOB 模式方法加载数据。大小为 115 MB 的行将使用完整 LOB 模式进行迁移,过程分为两步。
将表拆分成多个 亚马逊云科技 DMS 任务
对于大型数据库,您必须始终首先了解和规划迁移。其中最重要的部分是决定总共需要创建多少任务。创建多个任务的一个重要原因是更好地利用 亚马逊云科技 DMS 复制实例资源(CPU、内存和磁盘 I/O)。例如,迁移 100 个表的单个任务将无法使用所有资源,相比之下,每个任务迁移 10 个表的任务为 10 个任务。
复制实例类型在决定在其上并行运行多少 亚马逊云科技 DMS 任务方面起着至关重要的作用。它完全依赖于复制实例上可用的资源。这需要通过查看
默认情况下,亚马逊云科技 DMS 会根据参数 m
在测试环境中(
maxFullloadSub
Task 设置为默认八个),我们有一个包含 58 GB 和 4.5 TB LOB 的表,最大大小为 80 MB LOB 列,亚马逊云科技 DMS 估计迁移所有数据大约需要 5 天。该估计值是通过确定几个小时内传输的行数计算得出的。将
maxFullloadSub
Tasks 的值设置为 49 后 ,亚马逊云科技 DMS 能够在 20 小时内迁移所有数据。
需要考虑的其他重要 亚马逊云科技 DMS 参数
在具有直接路径负载的目标上使用并行负载时,重要的是禁用目标中的约束条件,并在目标端点上添加这些直接路径设置,以避免任何
DirectPathnoLog
不会生成重做日志。
有关
DirectPathnolog 和 Direc
tPathParallelLoad
的更多信息 ,请参阅
摘要
在这篇文章中,我们讨论了如何使用 亚马逊云科技 DMS 在本地甲骨文数据库之间高效地迁移到适用于 Oracle 的亚马逊 RDS。我们还研究了各种 亚马逊云科技 DMS 设置,并使用 SQL 查询来确定理想的配置,这将有助于迁移您的数据库。
在下次将 Oracle 数据库迁移到适用于 Oracle 的亚马逊 RDS 时尝试这些设置。如果您有任何意见或问题,请将其留在评论部分。
作者简介
 Viqash Adwani
是亚马逊网络服务的高级数据库专业架构师。他与内部和外部亚马逊客户合作,在 亚马逊云科技 云中构建安全、可扩展和有弹性的架构,并帮助客户从本地数据库迁移到 Amazon RDS 和 Amazon Aurora 数据库。
Viqash Adwani
是亚马逊网络服务的高级数据库专业架构师。他与内部和外部亚马逊客户合作,在 亚马逊云科技 云中构建安全、可扩展和有弹性的架构,并帮助客户从本地数据库迁移到 Amazon RDS 和 Amazon Aurora 数据库。
 Aswin Sankarapillai
是 亚马逊云科技 数据库迁移服务的高级数据库工程师。他与我们的客户合作,为数据库迁移项目提供指导和技术援助,帮助他们在使用 亚马逊云科技 时提高解决方案的价值。
Aswin Sankarapillai
是 亚马逊云科技 数据库迁移服务的高级数据库工程师。他与我们的客户合作,为数据库迁移项目提供指导和技术援助,帮助他们在使用 亚马逊云科技 时提高解决方案的价值。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。