我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊 Aurora PostgreSQL:使用逻辑复制进行跨账户同步
在这篇文章中,我们将向您展示如何使用兼容
您可以自定义解决方案以满足特定要求,包括在数据库、架构或表级别进行选择性复制。这种方法提供了灵活性、可扩展性和增强的安全性,使组织能够满足特定的用例,例如
- 开发和测试: 您可以将跨账户副本用于开发和测试目的,而不会影响生产环境。开发人员和测试人员可以在不影响实时制作数据库的情况下处理副本、进行实验、运行模拟和验证更改。
- 数据分析和报告: 您可以使用副本进行数据分析、报告和生成见解,而不会影响主数据库的性能。这允许减轻资源密集型分析查询的负担,促进商业智能计划并及时生成报告。
- 审计和合规性报告: 如果您有专门用于审计的 亚马逊云科技 账户,则可以使用跨账户副本进行审计和合规性报告。它提供了生产数据的单独且不可变的副本,从而确保了数据的完整性并便于审计跟踪。
解决方案概述
PostgreSQL 逻辑复制提供了对数据库部分内容的复制和同步的精细控制。例如,您可以使用逻辑复制来复制数据库的单个表或表集合。有关 PostgreSQL 实现逻辑复制的更多信息,请参阅逻
下图说明了我们的解决方案架构。
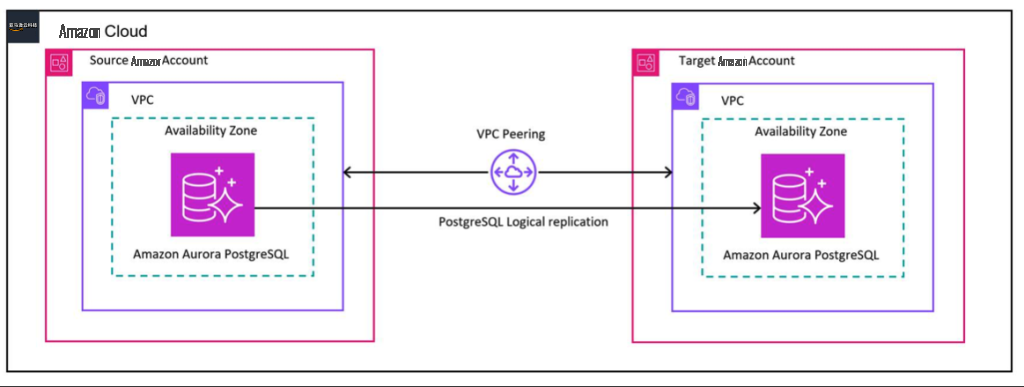
亚马逊 Aurora PostgreSQL 有一个名为
aurora_volume_logical_start_lsn () 的函数,它识别给定 Aurora 集群卷的逻辑 Write Ahead L
og (WAL) 流中记录的开头。可以在逻辑复制设置期间使用此功能来确定使用目标数据库克隆时使用的日志序列号 (LSN)。然后,您可以使用逻辑复制来持续流式传输在 LSN 之后记录的新数据,并将更改从发布者同步到订阅者。
此函数在以下版本的 Aurora PostgreSQL 上可用:
- 15.2 及更高版本 15
- 14.3 及更高版本 14
- 13.6 及更高版本 13
- 12.10 及更高版本 12
- 11.15 及更高版本 11
先决条件
要使用
-
- 两个 亚马逊云科技 账户(源账户和目标账户)。
-
一个 Aurora PostgreSQL 数据库集群。
你的 Aurora PostgreSQL 版本必须满足上述指定级别才能使用 aurora_volume_logical_start_lsn() 函数。
在源和目标集群上的RDS 数据库集群 参数组中设置 rds.logical_replication参数。- 主 亚马逊云科技 账户和辅助 亚马逊云科技 账户之间的 VPC 对等关系。 在
- 同一区域的不同 亚马逊云科技 账户上设置你的 Aurora PostgreSQL 的克隆。
- 要通过 亚马逊云科技 账户从源数据库逻辑复制到目标数据库的所有表都必须具有主键。
局限性
在进行逻辑复制设置时,重要的是要考虑 PostgreSQL 中存在的限制。有关详细信息,请参阅
Aurora PostgreSQL 不支持跨区域的跨账户克隆,因此源数据库和目标(克隆)数据库应位于同一个区域。
解决方案演练
使用这些 亚马逊云科技 服务会产生成本,因此,如果您使用这篇文章进行测试,请记住清理这些服务
在本节中,我们使用以下步骤实现解决方案:
- 在目标账户中克隆源 Aurora 集群
- 配置源数据库
- PostgreSQL 逻辑复制出版物
- 为源数据库创建复制槽
- 获取目标数据库的 LSN
- 在目标上删除复制
- 在目标数据库上创建订阅
- 开始逻辑复制
- 监控复制
- 清理
在目标账户中克隆源 Aurora 集群
-
在您的源 亚马逊云科技 账户上,打开 AW
S 资源访问管理器 控制台并为您的 Amazon Aurora PostgreSQL 创建资源共享

-
指定资源共享详细信息(来源:Aurora PostgreSQL 数据库集群)

-
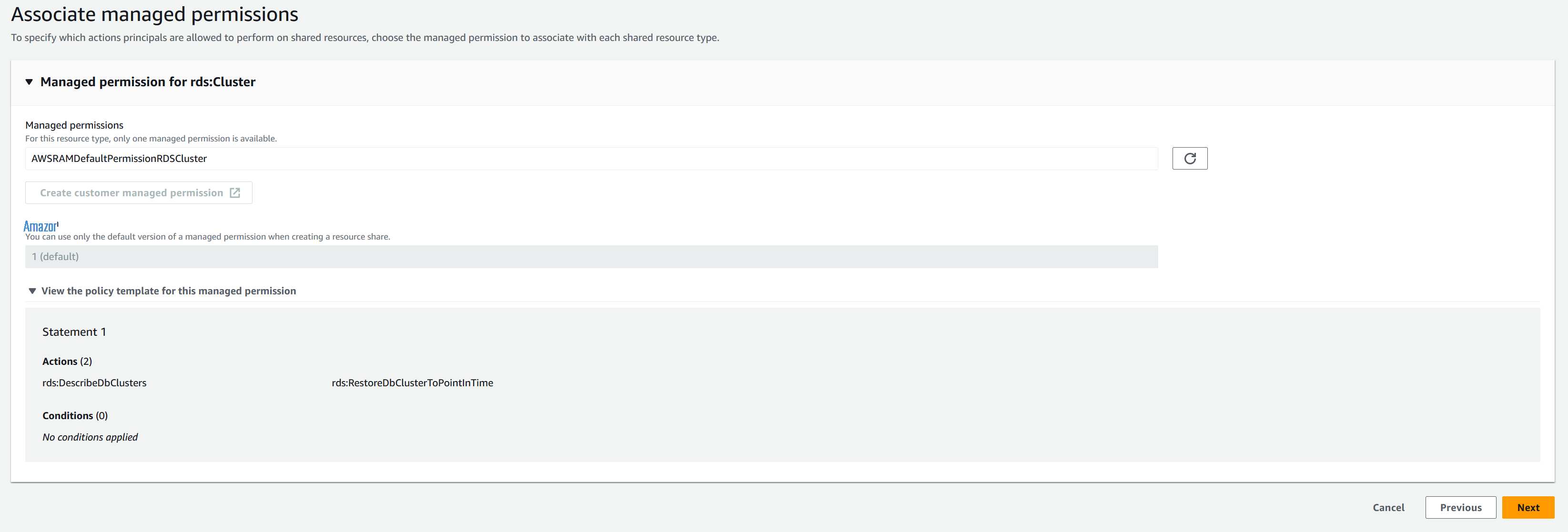
提供权限详情
-
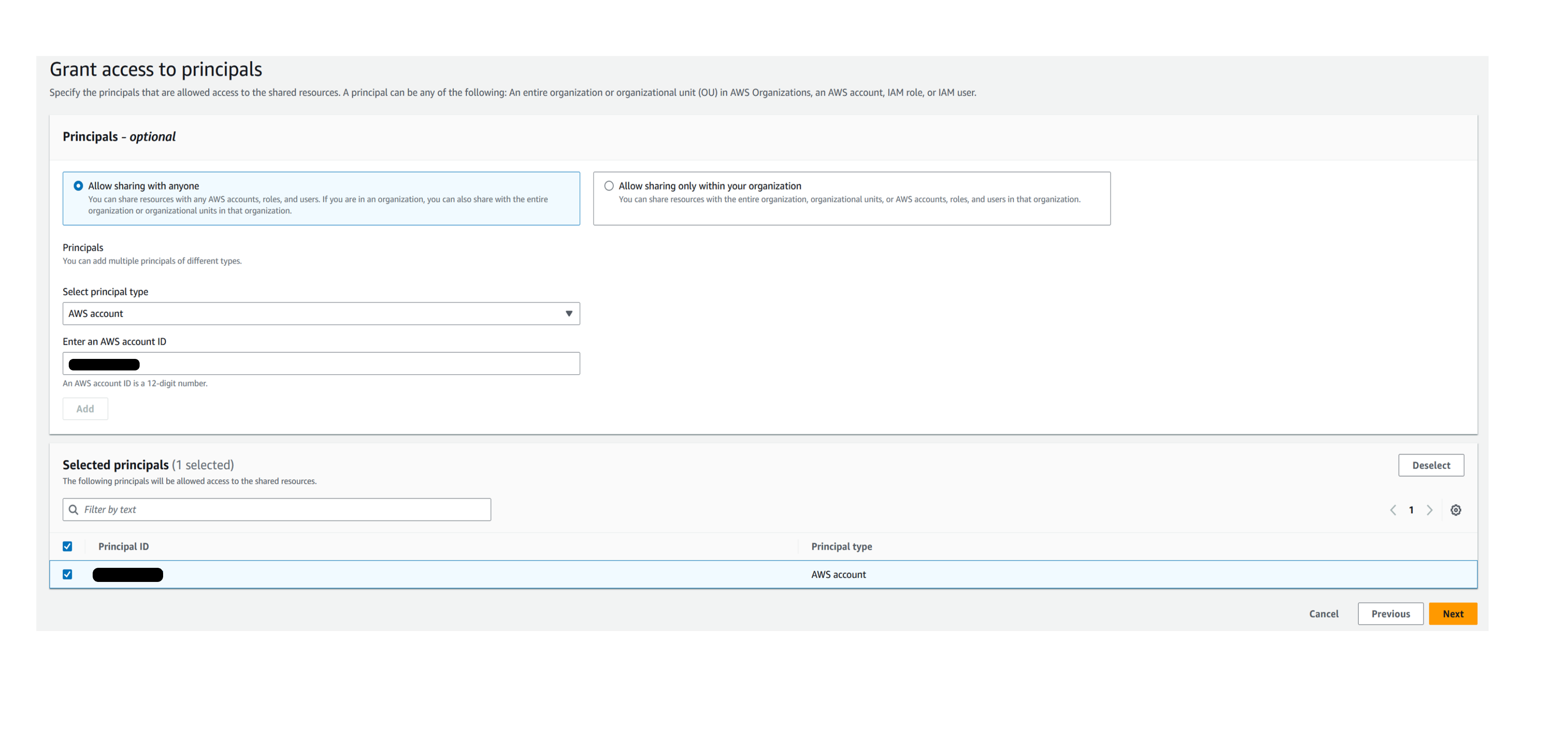
提供目标 亚马逊云科技 账户详细信息以共享源 Aurora PostgreSQL 数据库资源。
-
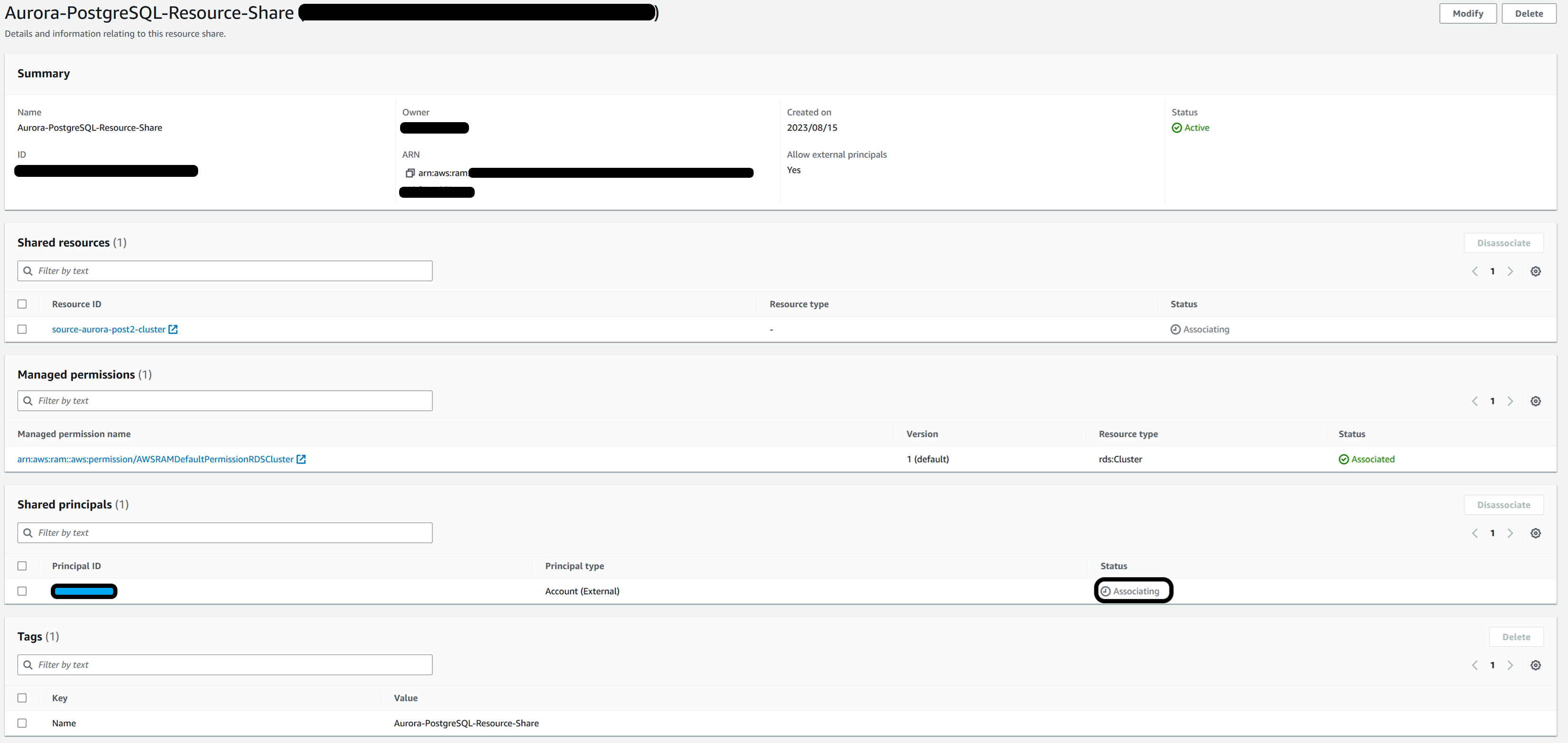
在 亚马逊云科技 资源访问管理器控制台上验证资源共享的状态(状态将显示 “正在关联”)
-
在您的目标 亚马逊云科技 账户上,打开 亚马逊云科技 资源访问管理器控制台并接受资源共享邀请。选择 Aurora 数据库资源和 “接受共享”

-
目标 亚马逊云科技 账户接受邀请后,返回源 亚马逊云科技 账户的 Amazon RDS 控制台,在 “
连接与安全
” 下向下滚动,验证是否可以在 “
与其他 亚马逊云科技 账户 共享数据库集群” 部分中找到目标账户
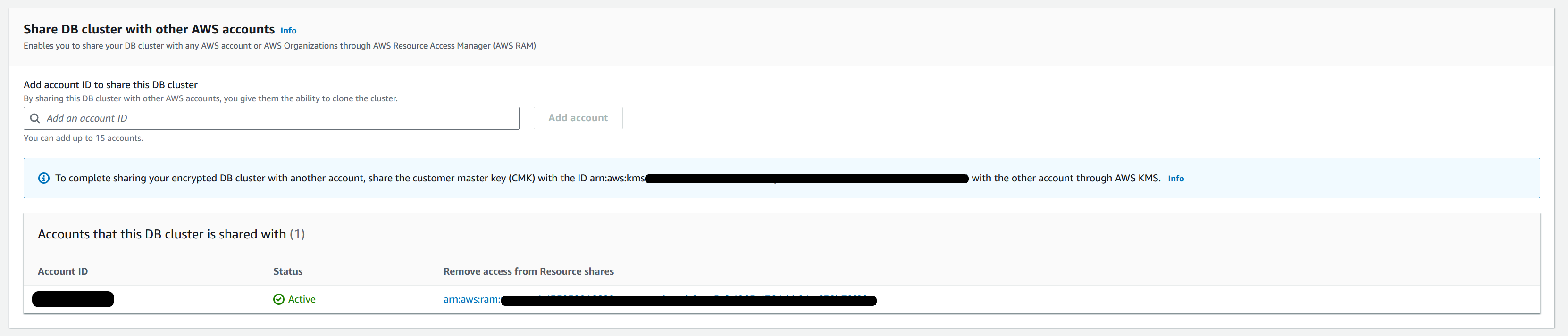
-
与目标账户共享源数据库后,在目标账户上创建克隆数据库。

要了解更多详情,请按照
配置源数据库
配置 WAL 参数
在 PostgreSQL 中,逻辑复制基于
在当前的源数据库上,确保配置了以下设置。如果尚未启用,则可以在新的参数组中配置这些参数并将该参数组分配给您的数据库,这需要重新启动数据库。
- 在 Amazon RDS 控制台上,选择导航窗格 中的 参数组 。
- 选择 创建新参数组 。
-
修改以下参数
-
wal_level
— wal_level 参数决定向 WAL 写入多少信息。默认值为最小值,它仅写入从崩溃或立即关机中恢复所需的信息。该副本添加了 WAL 存档所需的日志记录以及在备用服务器上运行只读查询所需的信息。将此参数设置为 logical 可使副本数据库处于只读模式。
在这篇文章中,我们将这样,将记录与副本相同的信息,以及允许从 WAL 中提取逻辑更改集所需的信息。逻辑设置还添加了支持逻辑解码所需的信息。rds.logical_replication=1 设置为 wal_level=Logical。 - max_replication_slot s — 设置此参数可确保主数据库集群保留足够的 WAL 段以供副本接收它们,并且主数据库集群仅在事务日志被所有副本消耗后才会回收这些分段。优点是副本永远不会落后到需要重新同步的程度。必须将此参数设置为至少要连接的订阅数量,外加一些用于表同步的预留款。
- max_worker_proc esses — 此参数设置数据库可以支持的最大后台进程数。它创建足够的工作进程来为与 WAL 发送器相对应的每个副本提供服务,并处理数据库系统正在运行的其他后台进程。最佳做法是将其设置为你想专门为 PostgreSQL 共享的 CPU 数量。通常,除了后台进程外,在提供者节点上每个数据库都需要一个,在订阅节点上需要每个数据库一个。
- max_wal_senders — 此参数设置来自复制数据库的最大并发连接数(同时运行的 WAL 发送器进程的最大数量)。默认值为零,表示已禁用复制。如果从一个副本开始,则必须将其设置为 3。对于每个副本,您可以添加两个 WAL 发送器。
-
wal_level
— wal_level 参数决定向 WAL 写入多少信息。默认值为最小值,它仅写入从崩溃或立即关机中恢复所需的信息。该副本添加了 WAL 存档所需的日志记录以及在备用服务器上运行只读查询所需的信息。将此参数设置为 logical 可使副本数据库处于只读模式。
要使用 亚马逊云科技 CLI 完成这些步骤,请输入以下命令在参数组中设置参数:
您可以在 Amazon RDS 控制台上验证参数的更改。在以下屏幕截图中,设置了
rds.log
ical_replication=1。

- 修改参数组中的参数设置后,您需要重新启动集群以使更改生效,这会导致中断。
- 将参数组应用于数据库实例。
PostgreSQL 逻辑复制出版物
-
连接到源数据库并指定以下命令,在源数据库上为所有要复制的表(或一组表)创建新的发布。
-
验证出版物是否在源数据库上创建。
为源数据库创建复制槽
-
为上一步中创建的源数据库发布创建复制时段。
-
使用以下查询验证复制槽是否已创建。
获取目标数据库的 LSN
-
识别目标数据库中用于逻辑复制的逻辑序列号 d -
查询 LSN,它标识了 WAL 流中一条记录的开头,逻辑复制应该从哪里开始,稍后需要这个数字,所以记下来。
如果您的 Aurora PostgreSQL 版本 不支持从克隆的数据库 a
urora_volume_logical_start_lsn () 检索 LSN
的查询,请对克隆进行一次小规模的数据库升级,使其达到上一节中提到的最接近的支持版本。
删除目标数据库上的复制槽
-
目标数据库上的复制槽是作为克隆过程的一部分引入的,不需要在目标数据库上使用。
-
删除目标数据库上的复制槽
1 行) -
验证复制槽是否已删除到目标数据库
在目标数据库上创建订阅
-
在目标 Aurora 数据库克隆(使用源数据库凭据)上创建订阅:
'); 创建订阅 -
验证在目标数据库上创建的订阅
在源数据库和目标数据库之间启动逻辑复制
-
从克隆(目标)数据库的系统目录表中确定复制的原始值
) -
使用前面步骤中确定的值在克隆的目标数据库中开始复制:。---> 0/6799E20,log_sequence_number 是之前查询 aurora_volume_logical_start_lsn 函数返回的值。前面的命令使用
pg_replication_origin_advance 函数在日志序列中指定复制 的起点。 -
使用以下代码在目标数据库上启用订阅:
监控复制
要监控复制,请在主 亚马逊云科技 账户中的源 Aurora 数据库上运行以下查询
“活动” 列应显示值 t(真),并 应根据源数据库和目标数据库之间的同步减少
dif f_siz
e 和 diff_bytes
的值。参见以下示例:
您可以在 RDS 控制台 的事件 选项卡上查看 PostgreSQL 日志。参见以下示例代码:
请注意,序列数据不会被复制。由序列支持的序列或标识列中的数据作为表的一部分进行复制,但序列本身仍显示订阅服务器上的起始值。如果将订阅者用作只读数据库,那么这通常应该不是问题。但是,如果打算以某种方式切换或故障转移到订阅者数据库,则需要将序列更新为最新值,方法是从发布者那里复制当前数据(可能使用
pg_dump
),也可以从表本身确定足够高的值。
清理
要在完成后进行清理,请完成以下步骤:
-
停止逻辑复制并删除复制槽,方法是连接到发布者(源数据库)并运行以下 SQL 命令 ; -
运行此命令时,复制槽无法处于活动状态。
要停用该插槽,请执行以下步骤:按照 modify-db-cluster-parameter-group 中所 述, 修改与发布者关联的数据库集群参数组。 -
将
rds.logical_replication 静态参数设置为 0。 -
重新启动发布商数据库集群,以使对
rds.logical_replication静态参数的更改生效。
-
将
- 要删除上游不再有复制槽的订阅,请在目标数据库中运行以下命令更改订阅 my_s ;
-
删除 Aurora 数据库集群和您不再需要的数据库实例,以避免与数据库实例相关的任何费用。有关说明,请参阅
删除 Aurora 数据库集群和数据库实例 。
WAL 存储
在适用于 PostgreSQL 的亚马逊 Aurora 中,预写日志 (WAL) 存储由该服务自动管理,您无法直接控制其大小。 TransactionLogsDiskUsage、WriteTownalthy 和 DiskQueueDepth 等
故障排除
通过遵循
逻辑复制设置中的潜在问题。值得注意的是,由于网络故障或源系统意外的大容量,数据在到达目标系统时可能会出现延迟;但是,系统最终会相应地赶上并同步数据。
常见问题之一是目标订阅者数据库上的重复密钥,为避免此类错误,请确保使用 a
urora_volume_logical_start_lsn () 函数来捕获正确的 LSN
号码,以便在目标上启用订阅。
未来的对象复制:在这种情况下,我们为所有表启用了逻辑复制。启用复制后创建的表我们必须运行以下命令来推送新表的更改。
结论
在这篇文章中,我们回顾了使用主数据库进行持续复制来执行 Aurora PostgreSQL 数据库跨账户克隆(独立集群)的步骤。此外,我们还讨论了将 a
urora_volume_logical_start_lsn () 函数与原生 PostgreSQL 逻辑复制结合
使用情况。 这种组合允许在 亚马逊云科技 账户之间复制您的数据库,
同时还利用了 Aurora 克隆的功能。此功能对于在不同的 亚马逊云科技 账户上运行较低的数据库环境克隆(与主数据库同步)非常有用。
我们欢迎反馈。如果您有任何问题或意见,请将其留在评论部分。
作者简介
 Senthil Ramasamy
是亚马逊网络服务的高级数据库顾问。他与 亚马逊云科技 客户合作,提供有关数据库服务的指导和技术援助,帮助他们将数据库迁移到 亚马逊云科技 云并提高其解决方案在使用 亚马逊云科技 时的价值。
Senthil Ramasamy
是亚马逊网络服务的高级数据库顾问。他与 亚马逊云科技 客户合作,提供有关数据库服务的指导和技术援助,帮助他们将数据库迁移到 亚马逊云科技 云并提高其解决方案在使用 亚马逊云科技 时的价值。
 John Lonappan
是亚马逊网络服务的高级数据库专家顾问/解决方案架构师,专注于关系数据库。在加入 亚马逊云科技 之前,John 曾在全球大型数据中心提供商担任数据库架构师。工作之余,他热衷于长途驾驶、电动汽车改装、下棋和旅行。
John Lonappan
是亚马逊网络服务的高级数据库专家顾问/解决方案架构师,专注于关系数据库。在加入 亚马逊云科技 之前,John 曾在全球大型数据中心提供商担任数据库架构师。工作之余,他热衷于长途驾驶、电动汽车改装、下棋和旅行。
 H
arshad Gohil
是亚马逊网络服务专业服务团队的云/数据库顾问。他帮助客户在 亚马逊云科技 云中构建可扩展、高度可用和安全的解决方案。他的重点领域是将本地基础设施同构和异构迁移到 亚马逊云科技 云。
H
arshad Gohil
是亚马逊网络服务专业服务团队的云/数据库顾问。他帮助客户在 亚马逊云科技 云中构建可扩展、高度可用和安全的解决方案。他的重点领域是将本地基础设施同构和异构迁移到 亚马逊云科技 云。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。