我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
宣布推出亚马逊云科技 CDK Glue L2 结构
今天,我们宣布发布适用于 Amazon Glue 的全新亚马逊云科技云开发套件 (CDK) L2 架构。此结构简化了 Glue 作业、工作流程和触发器的正确配置。查看 Glue 文档和每种作业类型和语言的有效参数示例需要时间,而必须依靠合成器、部署和运行时错误处理来验证配置选择可能会让开发人员感到沮丧。使用这种新结构,开发人员可以利用特定于工作类型的构造函数。新的构造函数默认采用自以为是的优秀实践配置,并利用便利功能来缩短构建可重复的 ETL 解决方案的时间。新的 Glue CDK L2 结构现已在 alpha 阶段推出,将在稳定后纳入核心 CDK 库。
背景
亚马逊云科技 CDK 是一个开源软件开发框架,用于使用现代编程语言在代码中定义云基础架构,并通过 Amazon CloudFormation 进行配置。它使用通过构造进行分层来为使用云组件提供不同级别的抽象。分层可确保在部署基础设施即代码 (IaC) 堆栈时,不必编写太多代码或对资源属性的访问权限过少。第 1 层 (L1) 结构直接映射到 CloudFormation 原语,而第 2 层 (L2) 构造提供辅助函数和优秀实践默认值,可改善开发人员体验并使其更容易做正确的事情。
大规模定义 Glue 资源带来了这个 L2 结构可以解决的几个挑战。首先,开发人员必须参考文档来确定作业类型、Glue 版本、工作器类型、语言版本和其他仅在有限组合中有效的参数的有效组合。此外,开发人员必须已经知道或查找数据源连接的网络限制,而且如何安全地存储 JDBC 连接的密钥存在模糊之处。最后,开发人员希望通过优秀实践默认值为工作人数和批处理等吞吐量参数提供规范性指导。
新的 Glue L2 构造具有便捷的方法和构造函数,这些方法和构造函数可以从常见用例向后运行,并将所需的参数设置为默认值,以符合每种作业类型的推荐优秀实践。它还为客户提供了通过可选参数覆盖的灵活性与不鼓励反模式的自以为是的界面之间的平衡,从而缩短了开发和部署新资源的时间。
使用 L2
L2 构造仅通过各自的构造函数公开适用于每种作业和工作流程类型的参数。例如,Python 和 Ray 作业不需要配置额外的 jar 文件的 Scala 作业参数或从中开始执行的主类。使用该构造,语言和特定任务的配置元素位于其自己的属性接口定义中,从而将所有作业中通用的配置元素(例如任务名称、任务描述和 CloudWatch 指标)保留在父任务类中。它还与 Glue Studio 主机体验提供的优秀实践默认设置一致,即在使用主机和 CDK 时提供一致的体验。
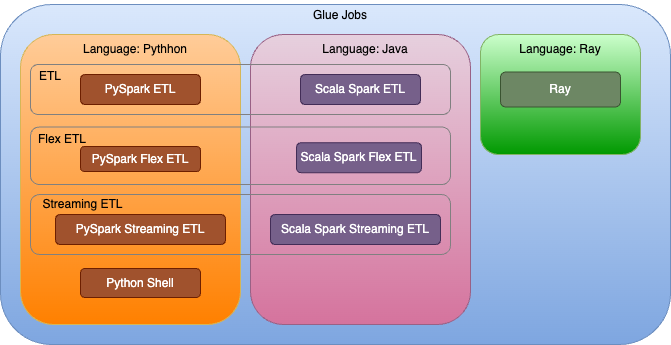
图 1 — 显示配置选项的 Glue 作业类型和语言支持的层次结构
新构造会自动设置映射到开发人员用于创建作业的构造函数的 Glue 作业类型,并将 Glue 版本和语言版本设置为该服务支持的最新版本。此外,它还为开发人员原本必须尝试的参数设置默认值,例如超时、工作人员数量和最大重试次数。
这些接口、继承和默认值允许我们创建只需要几个参数即可创建完整任务的构造函数,而在试验 L1 构造时可能需要将近 20 个选项以及更多有效和无效组合的排列。通过接口强制执行值意味着开发人员可以在合成器或部署之前通过自动完成和 Q Developer 代码推荐获得有关允许的正确配置的快速反馈。
当构造处于 alpha 阶段时,您需要遵循使用实验构造库的流程。稳定后,该库将合并到核心 CDK 库中,您可以像使用任何其他 L1 或 L2 构造一样使用它。
使用 Typescript 创建新的 Python Spark ETL Glue
以下示例显示如何在 Typescript 中创建新的 Python Spark ETL Glue 作业。
glue_job = new glue.PySparkEtlJob(stack, 'PySparkETLJob', {
glueIamRole,
glue.Code.fromAsset('glue-jobs/helloworld.py'),
jobName: 'PySparkETLJob',
});如果开发人员要覆盖所有可选值,则最详细的配置选项将如下所示:
glue_job = new glue.PySparkEtlJob(stack, 'PySparkETLJob', {
jobName: 'PySparkETLJobCustomName',
description: 'This is PySpark ETL Job',
glueIamRole,
glue.Code.fromAsset('glue-jobs/helloworld.py'),
glueVersion: glue.GlueVersion.V3_0,
continuousLogging: { enabled: false },
workerType: glue.WorkerType.G_2X,
maxConcurrentRuns: 100,
timeout: cdk.Duration.hours(2),
connections: [glue.Connection.fromConnectionName(stack, 'Connection', 'connectionName')],
securityConfiguration: glue.SecurityConfiguration.fromSecurityConfigurationName(stack, 'SecurityConfig', 'securityConfigName'),
tags: {
FirstTagKey: 'FirstTagValue',
SecondTagKey: 'SecondTagValue',
XTagKey: 'XTagValue',
},
numberOfWorkers: 2,
maxRetries: 2,
});创建按需工作流程触发器
新结构还简化了配置工作流程和触发器的方式,利用现有 Schedule 类来定义正确的执行频率。它还提供了辅助函数来添加不同类型的触发器。
以下示例显示如何创建按需工作流触发器。
myWorkflow = new glue.Workflow(this, "GlueWorkflow", {
name: "MyOnDemandWorkflow";
description: "New On Demand Workflow";
});
myWorkflow.addOnDemandTrigger(this, 'TriggerJobOnDemand', {
actions: [{ glue_job }]
});有关如何创建其他任务类型和触发器配置的更多示例,请查看 Glue L2 构造文档。
迁移到新结构时的注意事项
新结构保留了连接和数据库、表和作业运行队列的现有功能,因为它们对所有作业类型都是一致的。它还默认启用 CloudWatch 日志记录和 SparkUI 日志记录(如果适用),因此,除非您明确将其关闭,否则使用此结构将利用这些优秀实践的可观察性功能。
如果您当前使用的是旧版本的 Glue 或您的 Glue 任务支持的语言,我们建议您考虑将此构造发布作为升级计划的一部分,以充分利用新版本的性能、功能和语言安全增强功能。如果您更愿意继续使用该服务或语言的旧版本,我们建议您迁移到 L1 结构,该结构对默认强制执行最新版本并不固执己见。
结论
亚马逊云科技 CDK Glue L2 结构将在完成稳定阶段(通常需要 3 个月)后从其当前的 alpha 状态迁移到亚马逊云科技 CDK 核心库。有关新 Glue L2 结构的更多详细信息及其使用示例,请参阅 Glue CDK 文档。与往常一样,如果您对新结构或总体 CDK 有任何反馈,可以在亚马逊云科技 CDK GitHub 存储库上创建 GitHub 问题。
如果您是亚马逊云科技 CDK 的新手并想入门,我们强烈建议您查看 CDK 文档和 CDK 研讨会。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。