我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Amazon AppSync 字段级解析器:加强 GraphQL API 开发
导言
在这篇文章中,我们将探讨 Amazon AppSync 字段级解析器以及它们如何增强您的 GraphQL API 开发。字段级解析器是强大的代码单元,用于确定如何提取、处理和返回架构类型中特定字段的数据。通过利用 Amazon AppSync 中的字段级解析器,您将学习如何高效地处理复杂数据操作、集成多个数据源以及创建更灵活、性能更高的 API。我们将介绍现场解析器的基础知识以及它们如何帮助您构建可扩展的响应式应用程序。无论您是刚接触 GraphQL 还是希望优化现有 Amazon AppSync 实施,这篇文章都将为您提供实用的见解,让您在项目中充分利用字段级解析器。
使用 Amazon AppSync 的解析器模式
Amazon AppSync 提供各种解析器策略,以适应不同的数据访问模式和复杂性级别。对于涉及单一数据源的简单操作,单位解析器是首选解决方案。这些解析器处理简单查询或突变,直接映射到特定的数据源,如 Amazon DynamoDB 或 Amazon Lambda。随着应用程序变得越来越复杂,管道解析器对于协调多个数据操作变得非常宝贵。它们允许开发人员将一系列函数链接在一起,每个函数执行特定的任务,例如来自多个来源的数据验证、转换或聚合。这种模块化方法增强了代码的可重用性和可维护性。
GraphQL 中的字段级解析器可对类型中的单个字段进行精细控制,允许单独对每个字段进行自定义数据获取或计算。当需要从各种数据源解析相同类型的不同字段或需要独特的处理时,它们特别有用。现场级解析器和管道解析器之间的选择取决于特定的应用程序要求,现场级解析器提供精细控制,管道解析器为复杂的多步骤操作提供结构化方法。
字段级解析器提供了一种不同的方法来在代码中重用查询逻辑。在管道解析器中,您可以通过 Amazon AppSync 函数重用代码,而字段级解析器允许使用来自多个查询模式的相同逻辑解析与类型关联的字段。
餐厅场景
为了更好地了解字段级解析器的实现,我们将讨论一个实际场景。本场景探讨了餐饮业中的一个常见用例,在该用例中,查询操作检索有关餐厅的全面信息,包括其菜单项。
创建解析器
在本示例中,我们将使用 Amazon DynamoDB 表来存储有关餐厅的信息,并使用 Amazon Aurora PostgreSQL 数据库来存储菜单信息。
// Restaurant DynamoDB table design
Primary key: id (String)
Attributes:
- name (String)
- address (String)
- menu_id (String)
// Menu table schema
CREATE TABLE menu (
id VARCHAR(36),
menu_id VARCHAR(36),
item TEXT NOT NULL,
description TEXT NOT NULL,
price NUMERIC(10,2) NOT NULL,
PRIMARY KEY (id)
);创建 getRestaurantDetails 字段解析器
要检索单个餐厅的餐厅详细信息,我们可以将以下单位解析器附加到 getRestaurantDetails 查询操作中。在下面的解析器中,我们可以使用 Amazon AppSync DynamoDB 模块简化与 DynamoDB 表的交互。
import { util } from '@aws-appsync/utils';
import { get } from '@aws-appsync/utils/dynamodb';
export function request(ctx) {
return get({ key: { id: ctx.args.id } });
}
export function response(ctx) {
if (ctx.error) {
util.error(ctx.error.message, ctx.error.type);
}
return ctx.result;
}解析该 menu 字段
之前的解析器允许我们检索特定餐厅的 name、address 和 menu_id。现在我们需要一种方法来检索菜单项,这是同一个查询操作的一部分。下面的单位解析器附加到 Restaurant 类型的 menu 字段,因此,每当使用查询操作返回该 Restaurant 类型时,都会执行此解析器代码来解析该字段。与上面的解析器类似,我们能够使用 Amazon AppSync RDS 模块简化与 PostgreSQL 数据库的交互。
import { util } from "@aws-appsync/utils";
import { select, sql, createPgStatement, toJsonObject, typeHint } from "@aws-appsync/utils/rds";
export function request(ctx) {
const menuId = ctx.source.menu_id;
const fetchMenu = select({
table: "menus",
columns: "*",
where: {
menu_id: { eq: menuId },
}
});
return createPgStatement(fetchMenu);
}
export function response(ctx) {
const { error, result } = ctx;
if (error) {
return util.appendError(error.message, error.type, result);
}
return toJsonObject(result)[0];
}请注意,在上面解析器的第 4 行中,我们可以引用已解析为父 Restaurant 类型的一部分的 menu_id。在解析器中,您可以使用 ctx.source 对象访问父类型中任何先前解析的字段。有关 ctx 对象结构的更多信息,请参阅文档。
设置数据
在执行查询之前,让我们在数据库中添加一些示例数据。对于 PostgreSQL 数据库,执行以下语句:
INSERT INTO
menus (id, menu_id, item, description, price)
VALUES ('39a4e192-92ce-4665-b874-7ffe7ba2d757', '9ce86066-1a49-4f41-b817-8fa605f680d5', 'Strawberry Milkshake', 'Made with 100% artificial ingredients', 10.21);
INSERT INTO
menus (id, menu_id, item, description, price)
VALUES ('0f75668f-3014-4c42-bf82-3da8543b59ad', '9ce86066-1a49-4f41-b817-8fa605f680d5', 'Apple Pie', 'Contains zero apples', 7.11);对于 DynamoDB 表,插入以下项目:
{
"id": {
"S": "0cbf6478-d2c3-4549-a2d6-b4b8a3ddb582"
},
"address": {
"S": "1234 Main Avenue"
},
"menu_id": {
"S": "9ce86066-1a49-4f41-b817-8fa605f680d5"
},
"name": {
"S": "Sam's Diner"
}
}示例查询
以下是一个示例查询,它说明了我们上面描述的字段分辨率。为了解析此查询操作的请求数据,Amazon AppSync 将首先解析该 Restaurant 类型,然后解析父 Restaurant 类型中的 menu 字段。此操作会导致来自客户端的 1 次网络调用,而支持的分辨率复杂性则完全脱离了客户端。
query MyQuery {
getRestaurantDetails(id: '0cbf6478-d2c3-4549-a2d6-b4b8a3ddb582') {
name
id
menu_id
address
menu {
item
price
description
}
}
}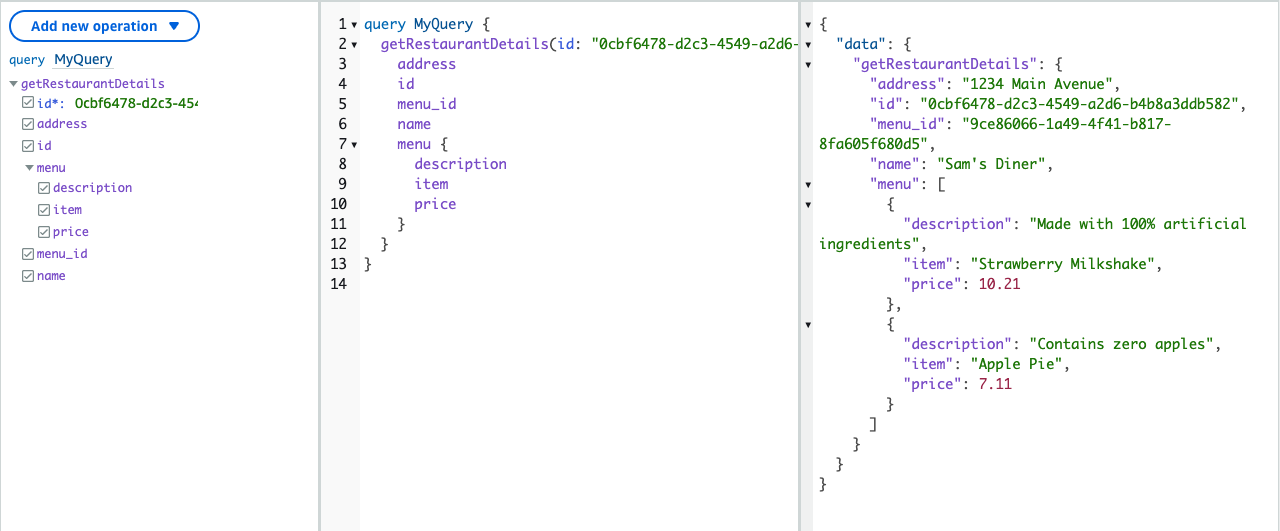
Amazon AppSync 查询编辑器
在处理相对静态的信息(例如不经常更改的菜单项)时,利用缓存可以显著提高查询操作的性能。Amazon AppSync 提供两种缓存模式:每解析器缓存和完整请求缓存。对于具有许多解析器的昂贵的整体请求,全操作缓存可最大限度地减少负载并提高整个请求的性能,而每解析器缓存可最大限度地减少解析器的负载,即使是多种请求类型也是如此。通过启用此功能,您可以显著缩短响应时间并最大限度地减少不必要的数据提取,从而提高应用程序的响应速度和效率。要在 Amazon AppSync 中实现缓存,只需在 Amazon AppSync 服务菜单的缓存部分激活"每解析器缓存"或"完整请求缓存"选项即可。每个解析器缓存允许通过为缓存数据配置缓存密钥和 TTL 来微调缓存策略
结论
总之,Amazon AppSync 字段级解析器为增强 GraphQL API 开发提供了一种强大而灵活的方式。通过利用字段解析器,您可以高效地处理复杂的数据操作,集成多个数据源,并创建响应速度更快、可扩展性更强的应用程序。无论您是处理简单的查询还是更复杂的数据关系,字段级解析器都能提供独立解析单个字段所需的精细控制。这种方法不仅可以优化性能,还可以提高代码的可重用性和可维护性。随着 API 的发展,您可以将实现拆分为不同的 API,这些 API 可以合并到 Amazon AppSync 合并的 API 中,从而进一步增强模块化和可扩展性。如餐厅场景所示,字段解析器可以无缝地从不同的来源提取数据,并将其聚合到一个高效的 GraphQL 查询中。通过了解和实施字段级解析器,您可以发挥 Amazon AppSync 的全部潜力,以构建更具动态和更强大的 API。
Amazon Aurora 与 MySQL 兼容的版本现在支持为 Aurora Serverless v2 和 Aurora 预配置的数据库实例重新设计的 RDS 数据 API。数据 API 允许通过直接数据源通过 Amazon AppSync GraphQL API 访问 Aurora 数据库,这意味着您可以将同一博客与 MySQL Aurora 数据库一起使用,对解析器代码进行一些细微的更改。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。