我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊云科技 对大型语言模型 (LLM) 进行微调,为一家大型游戏公司对有害言论进行分类
据估计,视频游戏行业在全球拥有超过30亿的用户群 1 。它由大量玩家组成,他们每天都在虚拟地互动。不幸的是,与现实世界一样,并非所有玩家都能以适当和尊重的方式进行沟通。为了创建和维护对社会负责的游戏环境,亚马逊云科技 Professional Services被要求建立一种机制,以检测在线游戏玩家互动中的不当语言(有害言论)。总体业务成果是通过自动化现有的手动流程来改善组织的运营,并通过提高检测玩家之间不当互动的速度和质量来改善用户体验,最终促进更清洁、更健康的游戏环境。
客户要求创建一个英语检测器,将语音和文本摘录分为他们自己定义的有害语言类别。他们想首先确定给定的语言摘录是否有毒,然后将该摘录归类为客户定义的特定毒性类别,例如亵渎或辱骂性语言。
亚马逊云科技 ProServe 通过生成式人工智能创新中心 (GAIIC) 和 ProServe 机器学习交付团队 (MLDT) 的共同努力解决了这个用例。亚马逊云科技 GAIIC 是 亚马逊云科技 ProServe 中的一个小组,负责将客户与专家配对,使用概念验证 (PoC) 版本为各种业务用例开发生成式 AI 解决方案。然后,亚马逊云科技 ProServe MLDT 通过为客户扩展、强化和集成解决方案,让 PoC 进入生产阶段。
该客户用例将在两篇单独的文章中介绍。这篇文章(第 1 部分)深入探讨了科学方法论。它将解释解决方案背后的思考过程和实验,包括模型训练和开发过程。第 2 部分将深入探讨生产解决方案,解释设计决策、数据流以及模型训练和部署架构的示意图。
这篇文章涵盖以下主题:
- 在这个用例中,亚马逊云科技 ProServe 必须解决的挑战
- 有关大型语言模型 (LLM) 的历史背景以及为什么这项技术非常适合此用例
- 从数据科学和机器学习 (ML) 的角度来看 亚马逊云科技 GAIIC 的 PoC 和 亚马逊云科技 ProServe MLDT 的解决方案
数据挑战
亚马逊云科技 ProServe 在训练有毒语言分类器时面临的主要挑战是从客户那里获取足够的标签数据,以便从头开始训练准确的模型。亚马逊云科技 从客户那里收到了大约 100 个带标签的数据样本,这比数据科学社区推荐的 1,000 个 LLM 样本要少得多。
历史上,自然语言处理 (NLP) 分类器的训练成本非常高,而且需要大量的词汇(称为语 料库)才能得出准确的预测 ,这是一项固有的挑战。如果提供足够数量的标签数据,严格而有效的自然语言处理解决方案将是使用客户的标签数据训练自定义语言模型。该模型将仅使用玩家的游戏词汇进行训练,使其根据游戏中观察到的语言进行量身定制。客户既有成本限制,又有时间限制,这使得该解决方案不可行。亚马逊云科技 ProServe 被迫寻找解决方案,使用相对较小的标签数据集训练准确的语言毒性分类器。解决方案在于所谓的 迁移学习 。
迁移学习背后的想法是使用预训练模型的知识并将其应用于不同但相对相似的问题。例如,如果对图像分类器进行了训练,可以预测图像中是否包含猫,则可以使用模型在训练期间获得的知识来识别老虎等其他动物。对于这种语言用例,亚马逊云科技 ProServe 需要找到以前经过培训的语言分类器,该分类器经过培训,可以检测有害语言,并使用客户的标记数据对其进行微调。
解决方案是找到一个 LLM 并对其进行微调,以便对有毒语言进行分类。LLM 是使用大量参数(通常约为数十亿)使用未标记的数据进行训练的神经网络。在介绍 亚马逊云科技 解决方案之前,以下部分概述了 LLM 的历史及其历史用例。
发挥 LLM 的力量
自从 ChatGPT 成为历史上增长最快的消费者应用程序 2 吸引公众的注意力以来,LLM 最近已成为寻求机器学习新应用的企业的焦点 2 ,到 2023 年 1 月 ,也就是发布仅两个月后,活跃用户达到了 1 亿。但是,在机器学习领域,LLM 并不是一项新技术。它们已被广泛用于执行自然语言处理任务,例如分析情绪、总结语料、提取关键字、翻译语音和对文本进行分类。
由于文本的顺序性,循环神经网络 (RNN) 一直是最先进的 NLP 建模方法。具体而言,之所以制定 编码器-解码 器 网络架构,是因为它创建了一种能够接受任意长度的输入并生成任意长度的输出的 RNN 结构。这对于翻译等自然语言处理任务来说非常理想,在这种任务中,可以从另一种语言的输入短语中预测一种语言的输出短语,通常输入和输出之间的字数不同。Transformer 架构 3 (Vaswani,2017 年)是对编码器-解码器的突破性改进;它引入了 自我注意力的 概念 ,这使模型能够将注意力集中在输入和输出短语中的不同单词上。在典型的编码器-解码器中,模型以相同的方式解释每个单词。当模型按顺序处理输入短语中的每个单词时,开头的语义信息可能会在短语结尾丢失。自注意力机制通过在编码器和解码器模块中添加注意力层来改变这种状况,因此在输出短语中生成特定单词时,模型可以对某些单词与输入短语赋予不同的权重。因此,变压器模型的基础诞生了。
变压器架构是当今使用的两个最著名和最受欢迎的 LLM 的基础,即《变形金刚》(BERT) 4 (Radford,2018)和生成式预训练变压器 (GPT) 5 (Devlin 2018)。GPT 模型的更高版本,即 GPT3 和 GPT4,是为 ChatGPT 应用程序提供动力的引擎。让 LLM 如此强大的最后一个秘诀是,它能够通过名为 UlmFit 的流程从庞大的文本语料库中提取信息,而无需进行大量的标签或预处理。这种方法有一个预训练阶段,在此阶段可以收集一般文本,然后训练模型的任务是根据先前的单词预测下一个单词;这里的好处是,任何用于训练的输入文本本质上都会根据文本的顺序预先标记。法学硕士确实能够从互联网规模的数据中学习。例如,最初的 BERT 模型是在 BookCorpus 和整个英语维基百科文本数据集上预先训练的。
这种新的建模模式催生了两个新概念:基础模型 (FM) 和生成式 AI。与使用特定任务的数据从头开始训练模型不同(传统监督学习的常见情况),LLM 经过预训练,可以从宽泛的文本数据集中提取常识,然后再使用小得多的数据集(通常约为数百个样本)适应特定任务或领域。新的机器学习工作流程现在从名为基础模型的预训练模型开始。
亚马逊云科技 GAIIC 概念验证
亚马逊云科技 GAIIC 选择使用带有 BERT 架构的 LLM 基础模型进行实验,以微调有毒语言分类器。共测试了来自 Hugging Face 模型中心的三款模型:
-
vinai/bertweet-base -
cardiffnlp/bertweet-base-Af -
cardifnlp/bertweet-base-hate
所有三种模型架构都基于
- 在更多数据上使用更大的批次训练模型
- 移除下一个句子预测目标
- 在较长的序列上训练
- 动态更改应用于训练数据的屏蔽模式
基于bertWeet的模型使用RobertA研究中先前的预训练程序,使用8.5亿条英语推文对原始的BERT架构进行预训练。这是第一个针对英语推文进行预训练的公共大规模语言模型。
使用推文进行预训练的 FM 被认为符合用例,主要有两个理论原因:
- 推文的长度与在线游戏聊天中发现的不当或有毒短语的长度非常相似
- 推文来自拥有各种不同用户的人群,类似于游戏平台中的人群
亚马逊云科技 决定首先使用客户的标记数据对 berTweet 进行微调,以获得基准。然后选择对另外两个 FM 进行微调 bertweet base-base-hate 和 bertweet-base-hate 这两个 FM 进行了进一步的预训练,专门针对更相关的有毒推文进行预训练,以获得可能更高的准确性。 bertweet-base-Affective模型使用基本的BerttWeet FM,并对14,100条被视为攻击性7的带注释的推文进行了进一步的预训练(Zampieri 2019)。 bertweet-base-hate模型也使用基本的BerttWeet FM,但对19,600条被视为仇恨言论8的推文进行了进一步的预训练(Basile 2019)。
为了进一步提高 PoC 模型的性能,亚马逊云科技 GAIIC 做出了两个设计决策:
- 创建了一个两阶段预测流程,其中第一个模型充当二进制分类器,用于对文本片段是否有毒进行分类。第二个模型是细粒度模型,它根据客户定义的有毒类型对文本进行分类。只有当第一个模型预测文本有毒时,它才会传递给第二个模型。
-
增强了训练数据,并在最初从客户那里收到的 100 份样本中添加了来自 Kaggle 公开竞赛(
拼图毒性 )的第三方标记有毒 文本数据集的子集。他们将 Jigsaw 标签映射到相关的客户定义的毒性标签,并将 80% 拆分为训练数据,20% 拆分为测试数据,以验证模型。
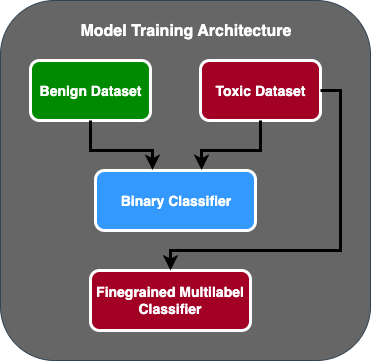
亚马逊云科技 GAIIC 使用
| Model | Precision | Recall | F1 | AUC |
| Binary | .92 | .90 | .91 | .92 |
| Fine-grained | .81 | .80 | .81 | .89 |
从那时起,GAIIC 将 PoC 交给 亚马逊云科技 ProServe 机器学习交付团队来制作 PoC。
亚马逊云科技 ProServe 机器学习交付团队解决方案
为了生产模型架构,客户要求 亚马逊云科技 ProServe ML 交付团队 (MLDT) 创建可扩展且易于维护的解决方案。两阶段模型方法存在一些维护难题:
- 这些模型需要双倍的模型监控量,这使得再训练的时间不一致。有时候,一个模型可能比另一个模型更频繁地接受再训练。
- 运行两个模型而不是一个模型的成本增加。
- 推理速度会减慢,因为推理要经过两个模型。
为了应对这些挑战,亚马逊云科技 ProServe MLDT 必须弄清楚如何将两阶段模型架构转变为单一模型架构,同时仍然能够保持两阶段架构的准确性。
解决方案是首先要求客户提供更多的训练数据,然后将所有标签(包括无毒样本)上的bertweet-base-Affence模型微调为一个模型。当时的想法是,使用更多数据微调一个模型将产生与在更少的数据上微调两阶段模型架构相似的结果。为了微调两阶段模型架构,亚马逊云科技 ProServe MLDT 更新了预训练的模型多标签分类标题,增加了一个代表无毒类的节点。
以下是代码示例,说明如何使用Hugging Face模型中心的变形金刚平台对预训练模型进行微调,并更改模型的多标签分类标题以预测所需的类别数量。亚马逊云科技 ProServe MLDT 使用该蓝图作为微调的基础。它假设你已经准备好了训练数据和验证数据,并采用了正确的输入格式。
首先,从 Hugging Face 模型中心导入 Python 模块以及所需的预训练模型:
然后加载预训练的模型并做好微调的准备。在此步骤中定义毒性类别的数量和所有模型参数:
模型微调从输入训练和验证数据集的路径开始:
亚马逊云科技 ProServe MLDT 又收到了大约 5,000 个带有标签的数据样本,3,000 个是无毒的,2,000 个是有毒的,并对所有三个基于推文的模型进行了微调,将所有标签合并为一个模型。除了来自PoC的5,000个样本外,他们还使用这些数据来微调新的单阶段模型,使用相同的 80% 训练集、20% 的测试集方法来微调新的单阶段模型。下表显示性能分数与两阶段模型的性能分数相当。
| Model | Precision | Recall | F1 | AUC |
| bertweet-base (1-Stage) | .76 | .72 | .74 | .83 |
| bertweet-base-hate (1-Stage) | .85 | .82 | .84 | .87 |
| bertweet-base-offensive (1-Stage) | .88 | .83 | .86 | .89 |
| bertweet-base-offensive (2-Stage) | .91 | .90 | .90 | .92 |
单阶段建模方法改善了成本和维护,而精度仅降低了3%。在权衡利弊之后,客户选择了 亚马逊云科技 ProServe MLDT 来生产单阶段模型。
通过使用更多标签数据对一个模型进行微调,亚马逊云科技 ProServe MLDT 能够提供满足客户模型准确性阈值的解决方案,满足他们对易于维护的要求,同时降低成本并提高稳定性。
结论
一家大型游戏客户正在寻找一种方法来检测其沟通渠道中的有害语言,以促进对社会负责的游戏环境。亚马逊云科技 GAIIC 通过微调 LLM 来检测有毒语言,从而创建了有毒语言检测器的 PoC。然后,亚马逊云科技 ProServe MLDT 将模型训练流程从两阶段方法更新为单阶段方法,并制作了 LLM 供客户大规模使用。
在这篇文章中,亚马逊云科技 演示了微调 LLM 以解决该客户用例的有效性和实用性,分享了基础模型和 LLM 的历史背景,并介绍了 亚马逊云科技 Genterative AI 创新中心与 亚马逊云科技 ProServe ML 交付团队之间的工作流程。在本系列的下一篇文章中,我们将深入探讨 亚马逊云科技 ProServe MLDT 如何使用 SageMaker 制作生成的单阶段模型。
如果您有兴趣与 亚马逊云科技 合作构建生成式 AI 解决方案,请联系 GA
参考文献
-
玩家人口统计:关于世界上最受欢迎的爱好的事实和统计数据 -
分析师指出,ChatGPT 创下了用户群增长最快的记录 - Vaswani 等人,“你只需要注意力”
- Radford 等人,“通过生成式预训练改善语言理解”
- Devlin 等人,“BERT:用于语言理解的深度双向变换器的预训练”
- 刘茵涵等人,“RobertA:一种经过强大优化的 BERT 预训练方法”
-
Marcos Zampieri 等人,“Semeval-2019 任务 6:识别和分类社交媒体中的攻击性语言(OffenseVal)” -
瓦莱里奥·巴西尔等人,“Semeval-2019 任务5:多语言检测推特中针对移民和女性的仇恨言论”
作者简介
 James Poqu iz
是位于加利福尼亚州奥兰治县的 亚马逊云科技 专业服务的数据科学家。他拥有加州大学尔湾分校的计算机科学学士学位,在数据领域有数年的工作经验,曾担任过许多不同的角色。如今,他致力于实施和部署可扩展的机器学习解决方案,以实现 亚马逊云科技 客户的业务成果。
James Poqu iz
是位于加利福尼亚州奥兰治县的 亚马逊云科技 专业服务的数据科学家。他拥有加州大学尔湾分校的计算机科学学士学位,在数据领域有数年的工作经验,曾担任过许多不同的角色。如今,他致力于实施和部署可扩展的机器学习解决方案,以实现 亚马逊云科技 客户的业务成果。
 Han Man
是位于加利福尼亚州圣地亚哥的 亚马逊云科技 专业服务的高级数据科学和机器学习经理。他拥有西北大学的工程博士学位,并拥有多年管理顾问经验,为制造业、金融服务和能源领域的客户提供咨询。如今,他热衷于与来自不同垂直行业的关键客户合作,在 亚马逊云科技 上开发和实施 ML 和 GenAI 解决方案。
Han Man
是位于加利福尼亚州圣地亚哥的 亚马逊云科技 专业服务的高级数据科学和机器学习经理。他拥有西北大学的工程博士学位,并拥有多年管理顾问经验,为制造业、金融服务和能源领域的客户提供咨询。如今,他热衷于与来自不同垂直行业的关键客户合作,在 亚马逊云科技 上开发和实施 ML 和 GenAI 解决方案。
 Safa Tinaztepe
是 亚马逊云科技 专业服务的全栈数据科学家。他拥有埃默里大学的计算机科学学士学位,并对 mLOP、分布式系统和 web3 感兴趣。
Safa Tinaztepe
是 亚马逊云科技 专业服务的全栈数据科学家。他拥有埃默里大学的计算机科学学士学位,并对 mLOP、分布式系统和 web3 感兴趣。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。