我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 S3 和亚马逊 Athena 为适用于 PostgreSQL 的亚马逊 RDS 构建集中式审计数据集
数据库审计是组织需要满足的重要合规要求之一。您可能需要长期捕获、存储和保留审计数据。您还需要满足组织的信息安全法规和标准。
在这篇文章中,我们将向您展示如何从
解决方案概述
下图显示了解决方案架构,该架构使用以下 亚马逊云科技 服务来分析 PostgreSQL 审计文件:
- Amazon Athena
-
亚马逊 CloudWatch - 亚马逊云科技 Glue
-
亚马逊 Kinesis Data Firehose -
亚马逊云科技 Lambda - 亚马逊 S3
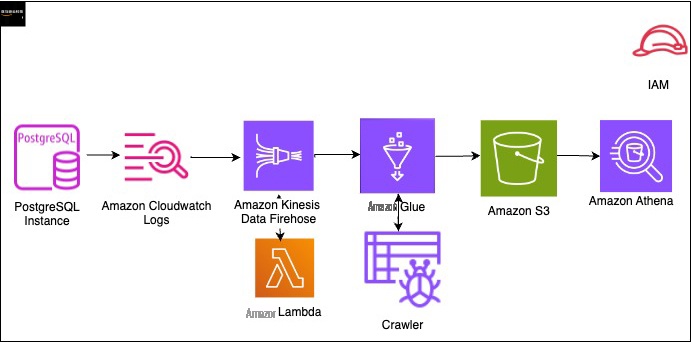
实施此解决方案的高级步骤如下:
-
创建
亚马逊云科技 身份和访问管理 (IAM) 角色。 - 创建 Lambda 函数来解密流。
- 创建一个 S3 存储桶来存储 Kinesis Data Firehose 生成的文件。
- 允许亚马逊 RDS 写入 CloudWatch 日志。
- 创建 Firehose 配送流。
- 创建订阅过滤器。
- 设置 亚马逊云科技 Glue 数据库、爬虫和表。
- 运行 Athena 查询以识别数据库性能问题。
先决条件
要关注这篇文章,你必须具备以下先决条件:
- 具有创建和配置必要基础设施的适当权限的 亚马逊云科技 账户。
-
适用于 PostgreSQL 的 RDS 数据库。有关说明,请参阅
创建并连接到 PostgreSQL 数据库 。 -
PostgreSQL 数据库的审计设置。有关说明,请参阅使用
pgAudit 扩展程序 在会话和对象级别进行 日志记录 。 - 与服务交互所需的角色。我们在下一节中提供更多详细信息。
由于此解决方案涉及设置和使用 亚马逊云科技 资源,因此会在您的账户中产生费用。有关更多信息,请参阅
创建 IAM 角色
您可以使用 IAM 控制台、A
你需要三个角色:
Lambda-exec-Role。
cwltokinesisFirehoseRole 允许 CloudWatch Logs 将数据
流式传输到 Kinesis Data Fire参见以下代码:
FireHosetos3
Role 允许 Kinesis Data Firehose 写入亚马逊 S3。参见以下代码:
cwltoFirehose-Lambda-exec-Role 是 Lambda 执行角色
。参见以下代码:
创建 Lambda 函数
我们创建了 Lambda 函数来解密流并将记录通过 Kinesis Data Firehose 推送到亚马逊 S3。然后,我们在记录器的函数中添加一个图层。要在 Lambda 控制台上创建函数,请完成以下步骤:
- 在 Lambda 控制台上, 在导航 窗格中选择函数 。
- 选择 创建函数 。
-
将你的函数命名为
cwltoFireHose。 - 选择运行时的 Python 3.10。
-
选择现有角色
cwltoFirehose-Lambda-exec-role。 - 输入以下代码并创建您的函数:
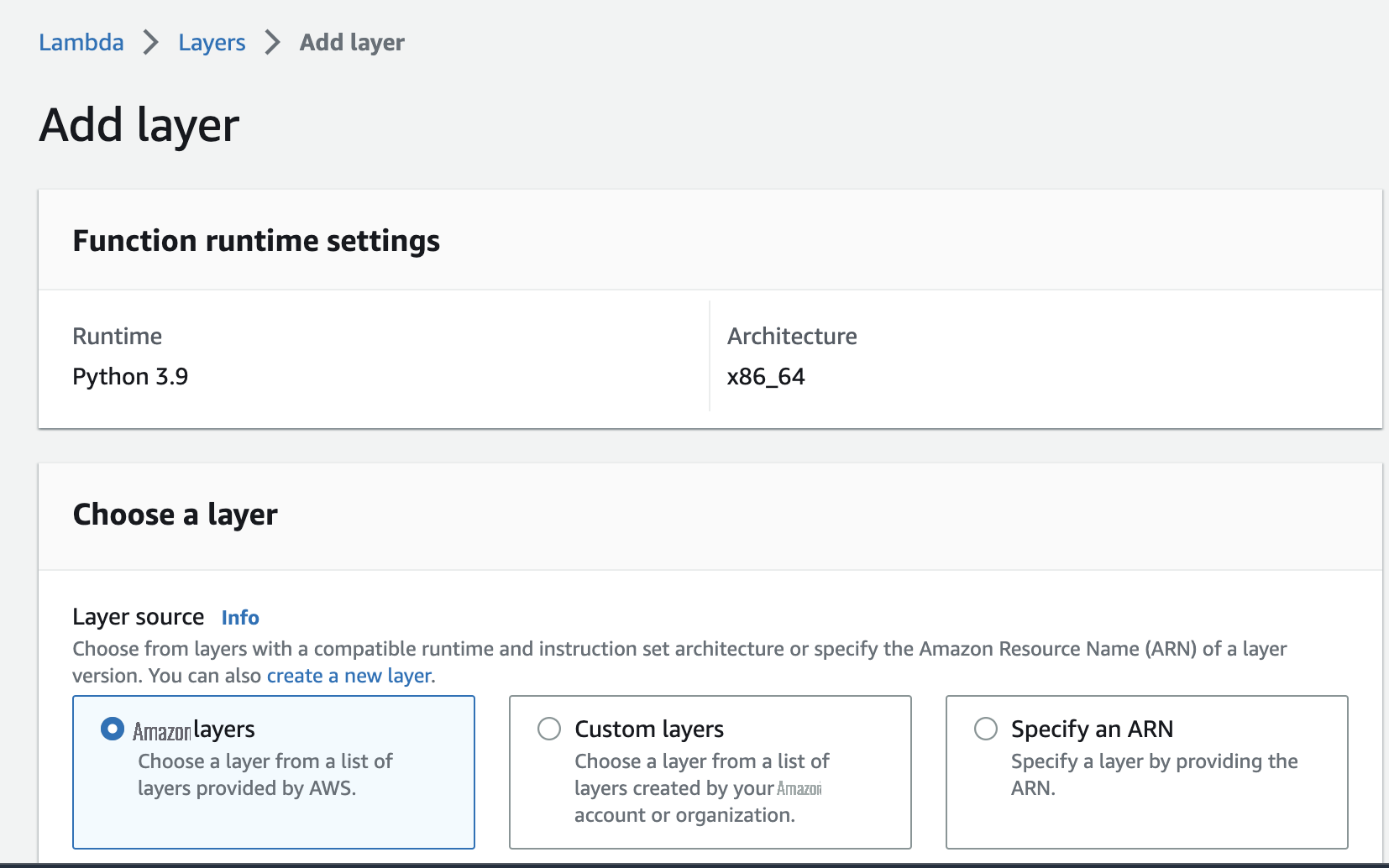
- 在 Lambda 控制台上, 在导航 窗格中选择图层 。
- 选择 添加图层 。
-
对于
层源
,选择
亚马逊云科技 层
。
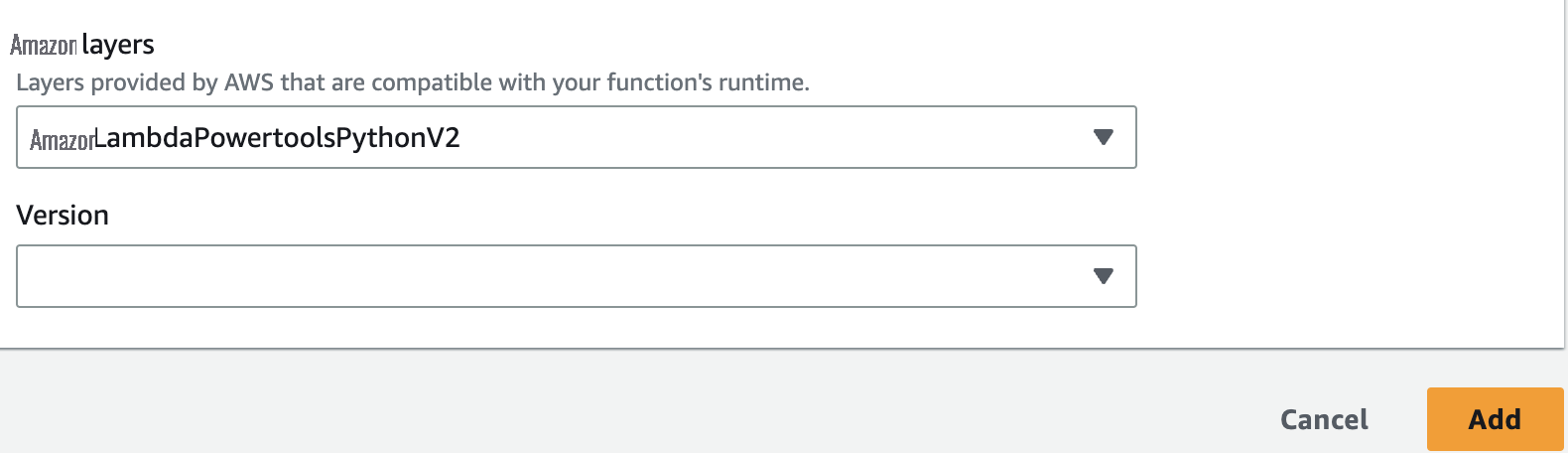
-
对于
亚马逊云科技 层 ,请选择图层
awslambdaPowerToolspythonV2。 -
选择 “
添加
” 。
创建 S3 存储桶
接下来,我们创建一个存储桶来存储 Kinesis Data Firehose 生成的审计文件。有关创建 S3 存储桶的说明,请参阅
允许亚马逊 RDS 写入 CloudWatch 日志
要使亚马逊 RDS 能够写入 CloudWatch 日志,请完成以下步骤:
- 在 Amazon RDS 控制台上, 在导航窗格中选择 数据库 。
-
选择要向 CloudWatch 发布日志的实例,然后选择
修改
。

-
在
日志导出
部分中,选择要发布的日志类型。

创建 Firehose 配送流
使用以下步骤创建 Firehose 交付流:
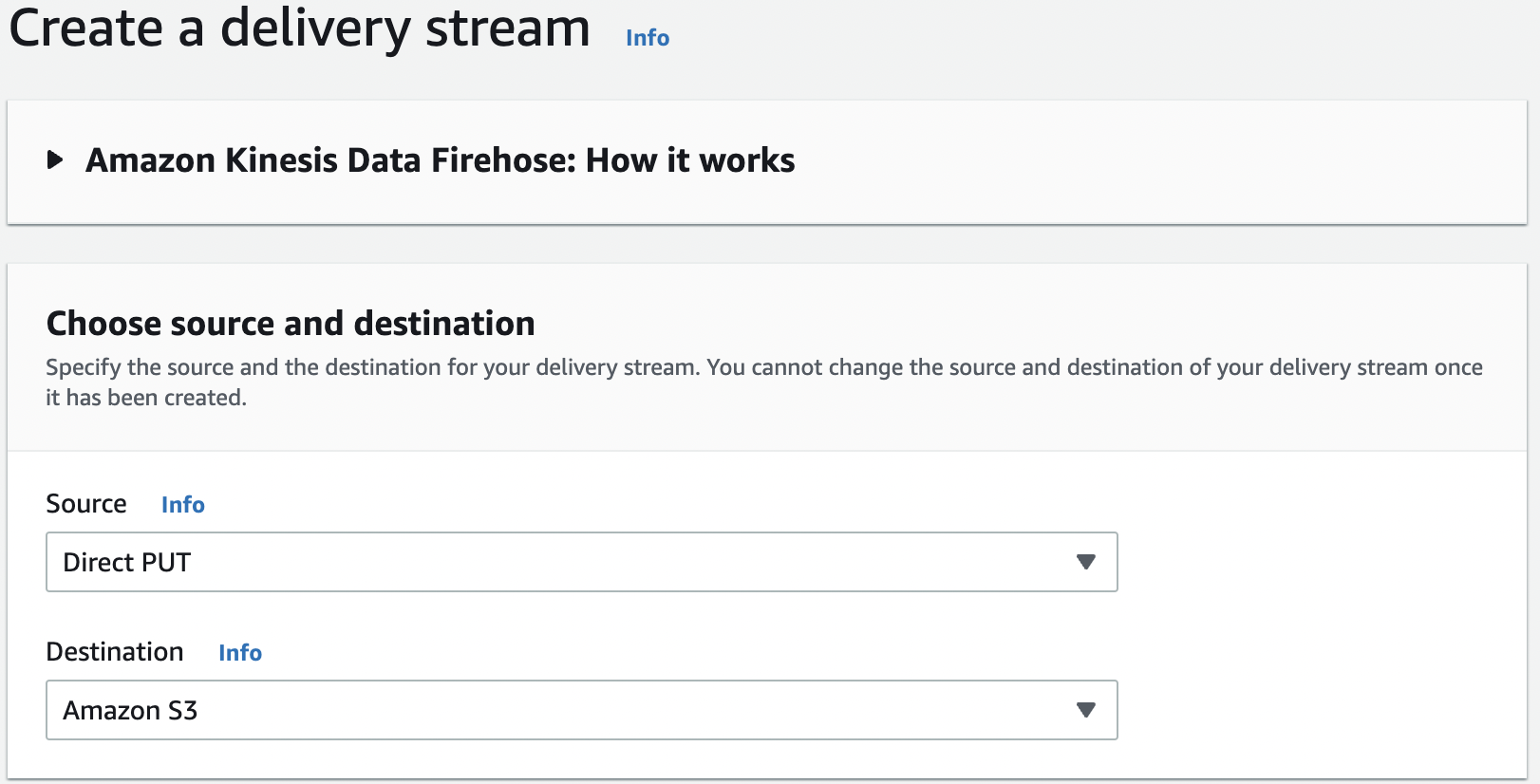
- 在 Kinesis Data Firehose 控制台上,选择 创建传输流 。
-
选择您的来源和目的地。
- 在 交付流名称 中 ,输入一个名称。
- 对于 “ 数据转换 ” ,选择 “ 启用 ” 。
-
对于
亚马逊云科技 Lambda
函数,请输入您的函数 ARN。

- 对于 缓冲区大小 ,输入函数的首选缓冲区大小。
- 对于 缓冲间隔 ,输入函数的首选缓冲间隔。
-
对于 “
录制格式转换
” ,选择 “
禁用
” 。

- 对于 S3 存储桶 ,输入您的 S3 存储桶的名称。
- 对于 动态分区 ,请选择 禁用 。
-
对于
S3 存储桶前缀
,输入可选前缀。

-
在
S3 缓冲提示
下 ,选择您的首选缓冲区和间隔。
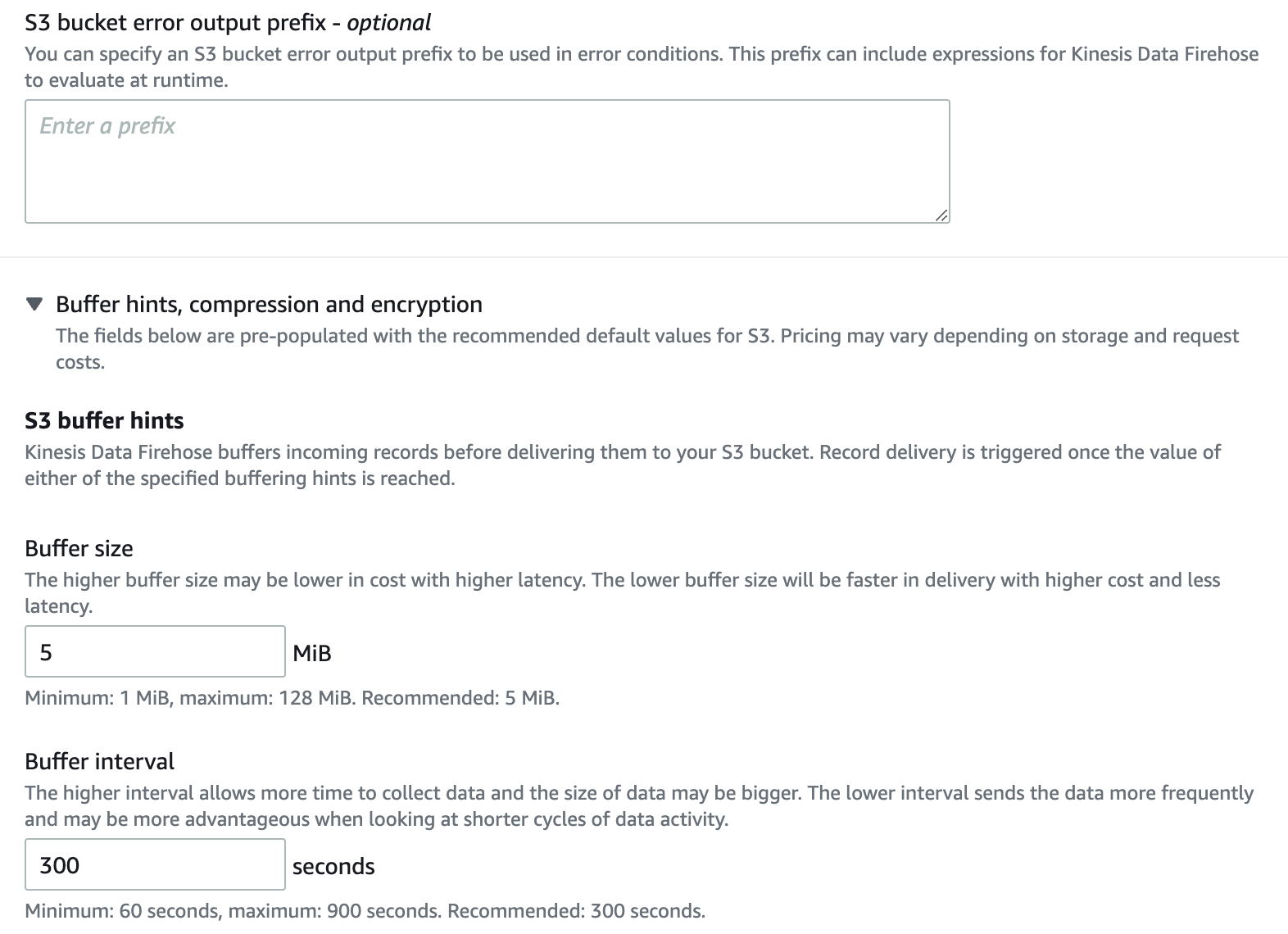
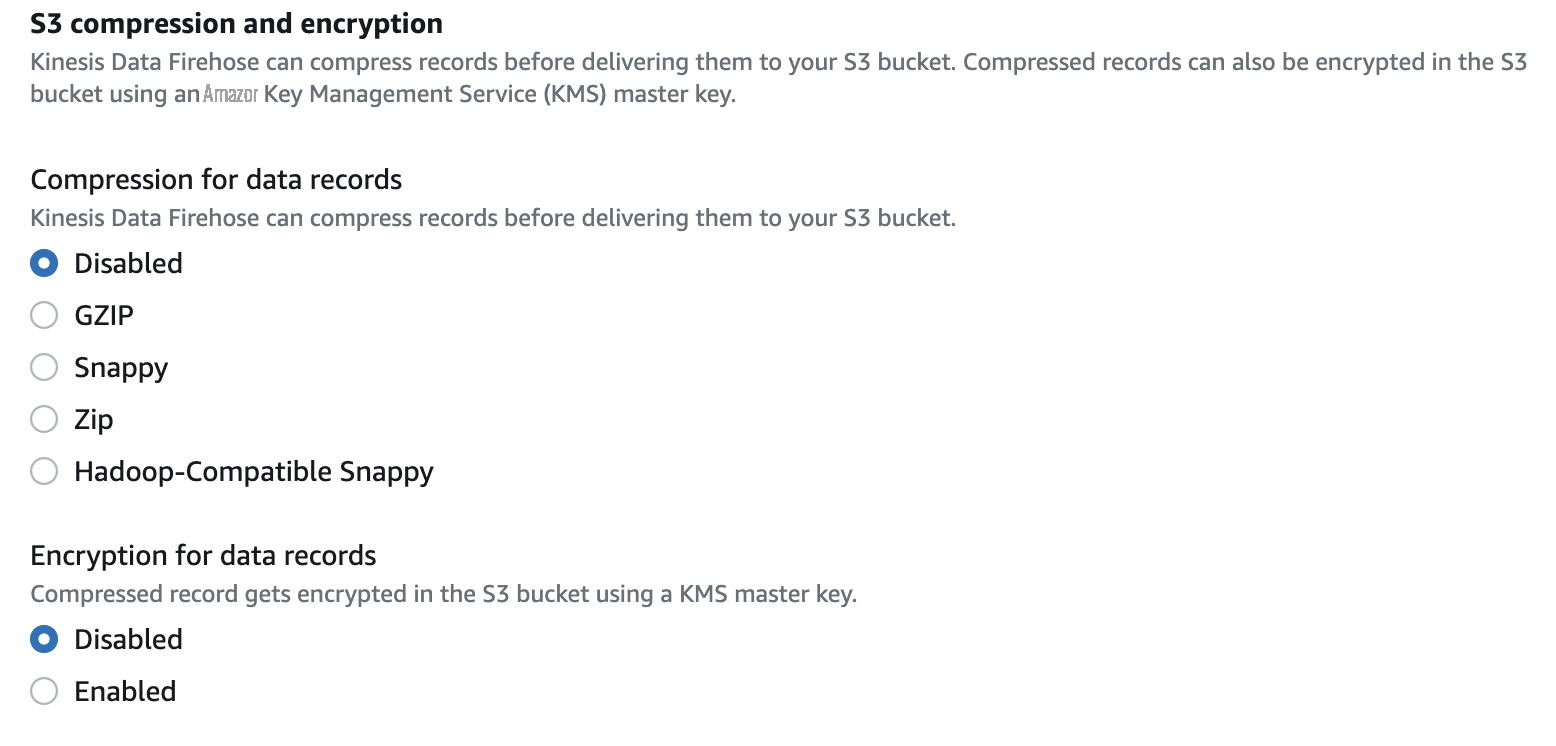
- 对于数据记录的 压缩 ,选择 禁用 。
-
对于数据记录的 加密
,选择
禁用
。
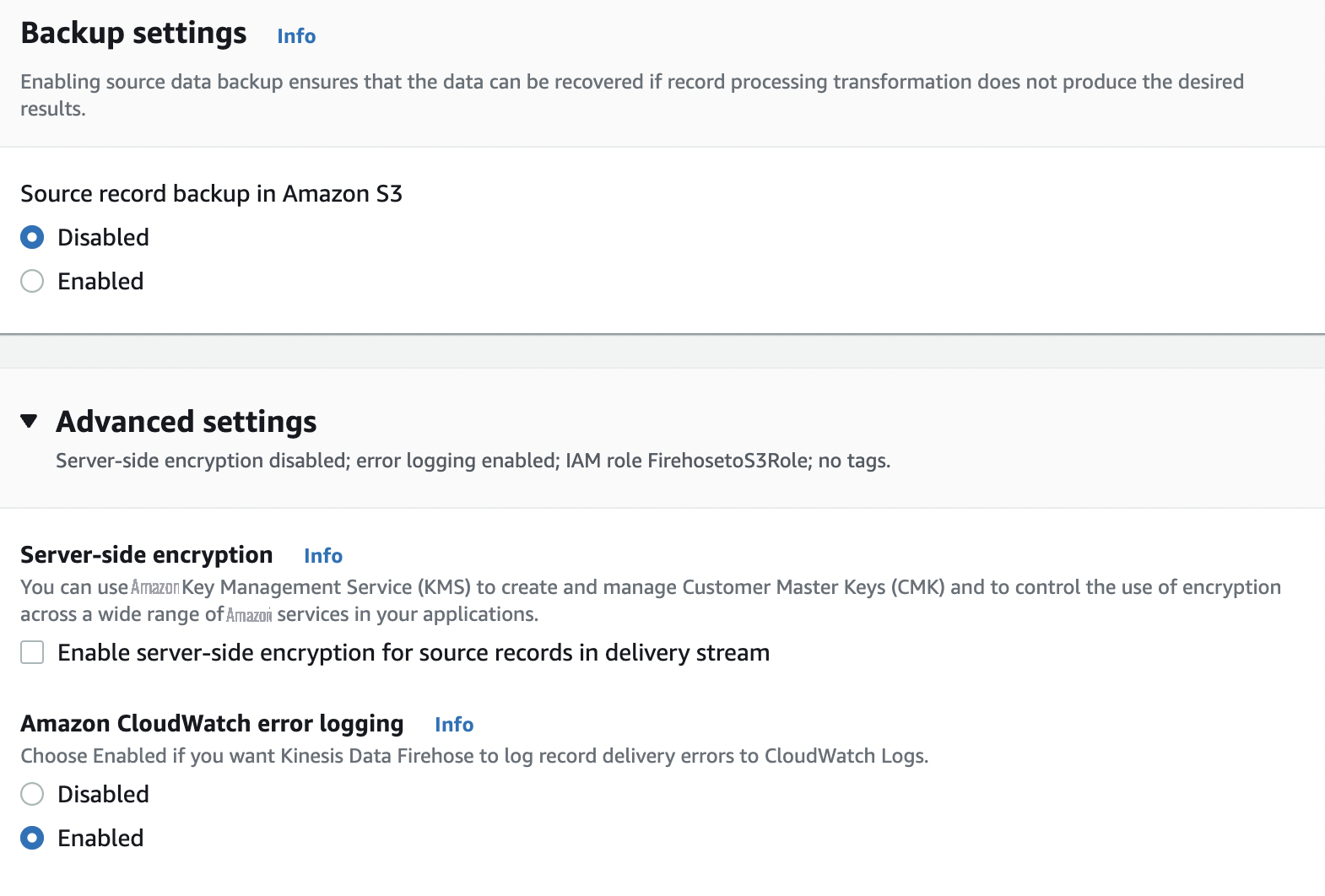
- 对于 Amazon S3 中的 源记录备份 ,选择 禁用 。
-
展开
高级设置
,对于
亚马逊 CloudWatch 错误记录
,选择 启用。
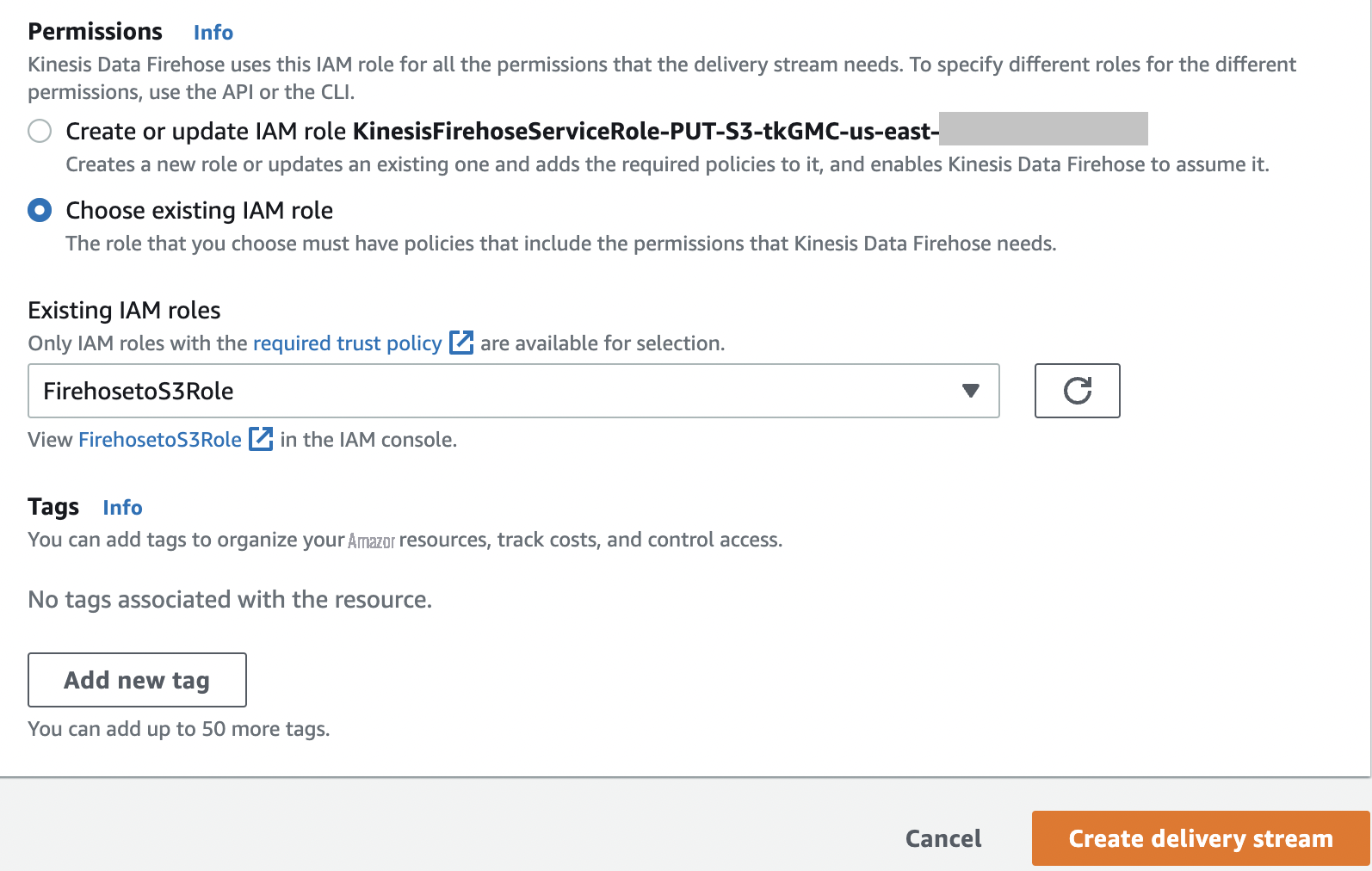
- 在 “ 权限 ” 下 , 选择 “选择现有角色 ” 。
-
选择角色
FireHosetos3Role。 -
选择
创建交付流
。
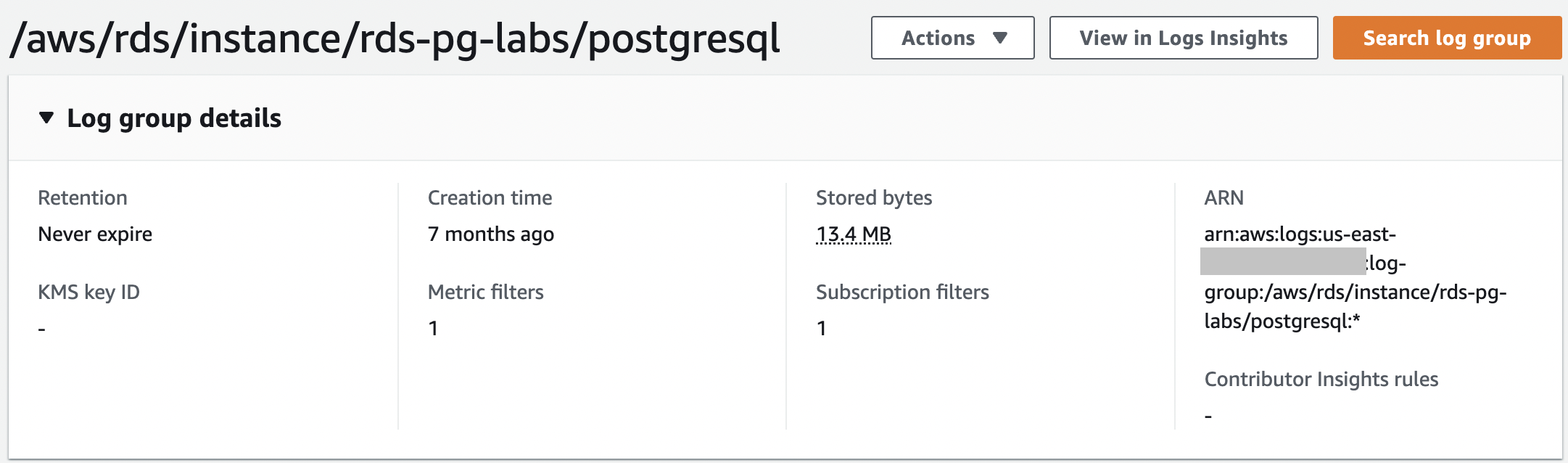
要查看您的日志组,请 在 CloudWatch 控制台导航窗格中选择
日志组
。CloudWatch 日志组有一个审计文件;例如,
创建订阅过滤器
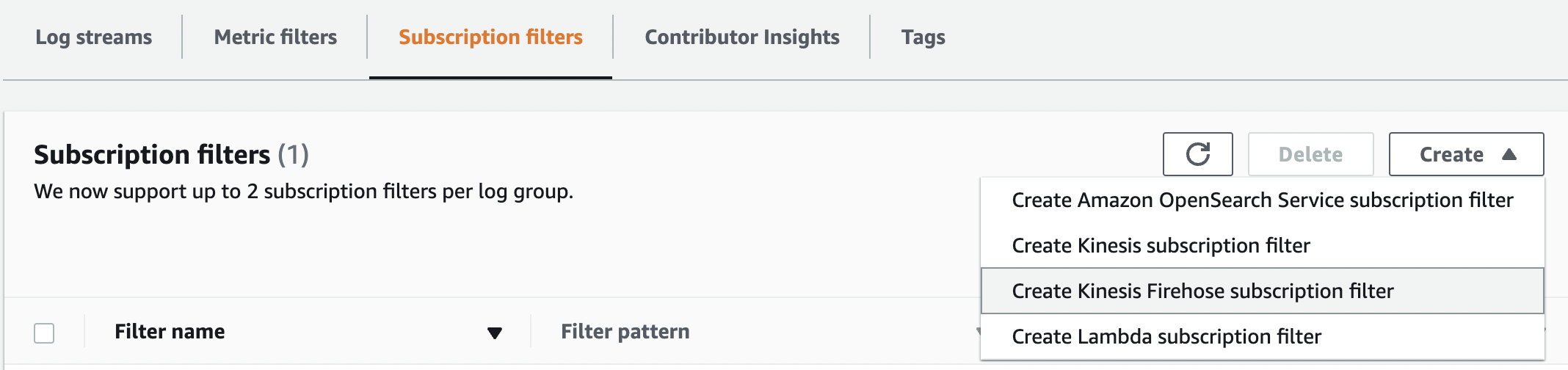
要创建 Kinesis Data Firehose 订阅过滤器,请完成以下步骤:
- 在 Kinesis Data Firehose 控制台上,导航到 订阅筛选器 选项卡 。
-
在 “
创建
” 菜单上,选择 “创
建 Kinesis Firehose 订阅过滤器
”。
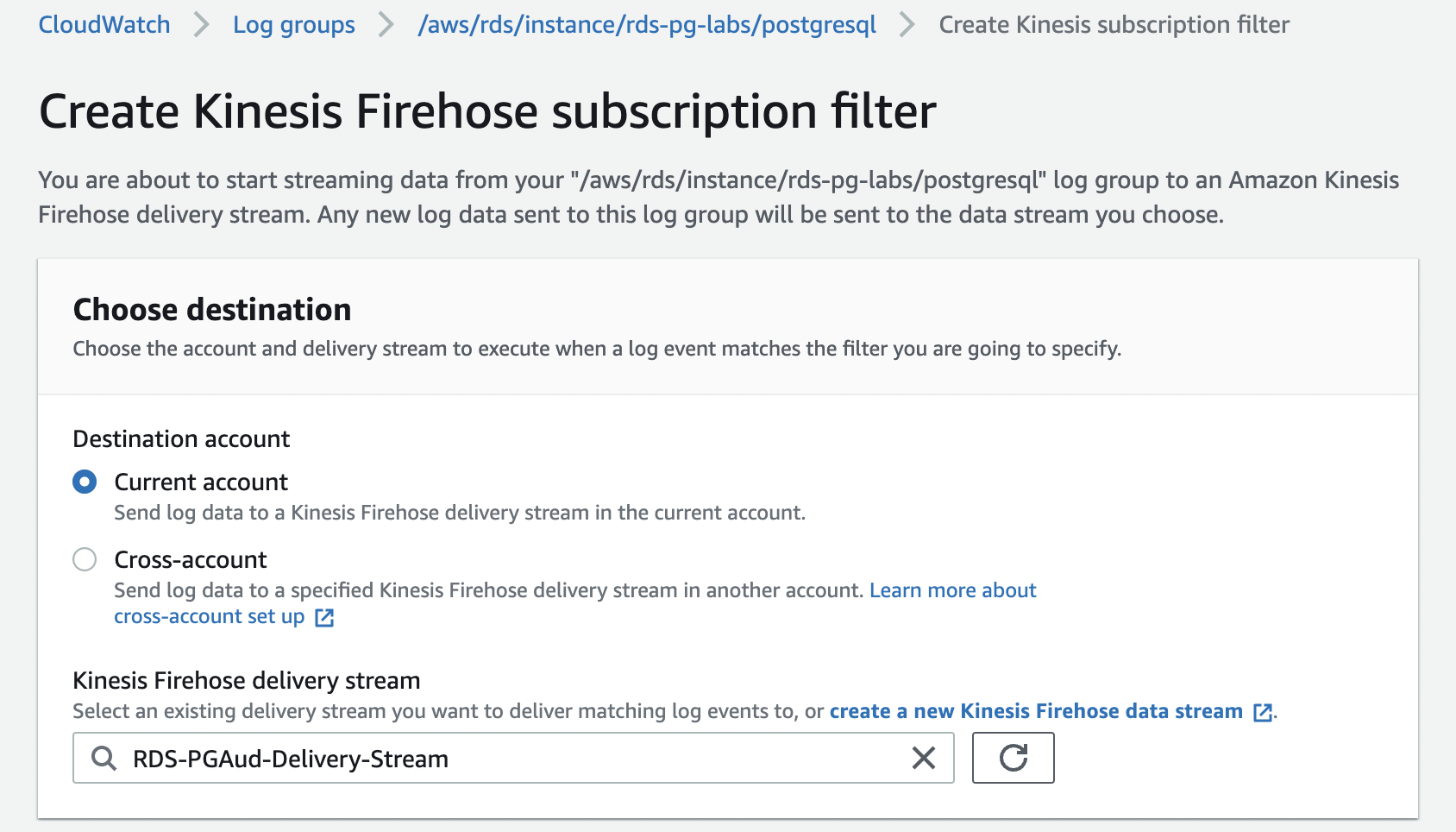
- 对于 目标账户 ,选择往来 账户 。
-
对于
Kinesis Firehose 传送流
,请输入您的传输流的名称。
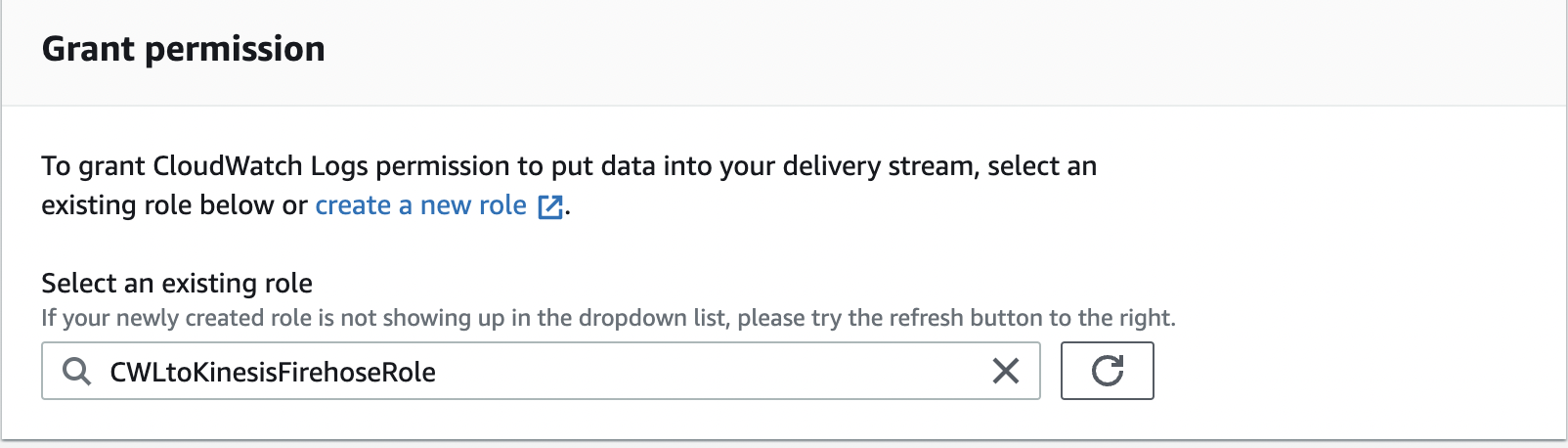
-
在
选择现有角色中,选择角色
cwlto kinesisFireHoseRole。
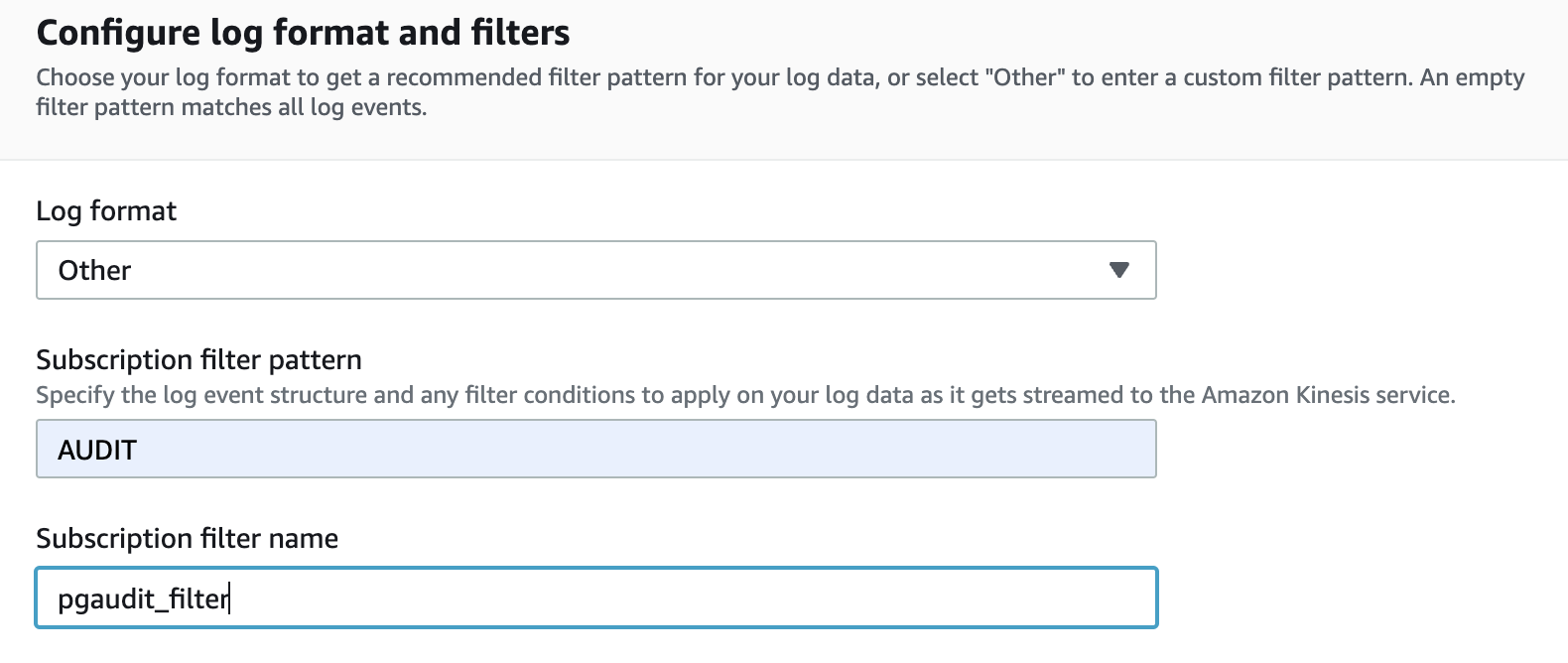
- 对于 日志格式 ,选择 其他 。
-
对于
订阅筛选模式
,输入 AUD
IT。 -
在订
阅筛选器名称
中 ,输入一个名称。
- 在 日志事件消息 中 ,输入您的日志数据。
-
选择 “
开始直播
” 。
设置 亚马逊云科技 Glue 数据库、爬虫和表
现在,您应该已配置 CloudWatch 指标流,并将指标流转到您的 S3 存储桶。在此步骤中,我们配置 亚马逊云科技 Glue 数据库、爬虫、表和表分区。
-
在 亚马逊云科技 Glu
e 控制台 上 ,选择 添加数据库 。 -
输入数据库的名称,例如
pgaudit_db。
现在我们已经准备好了 亚马逊云科技 Glue 数据库,我们设置了爬虫。 - 在导航窗格中,选择 Crawlers。
- 选择 “ 添加爬虫 ”。
-
输入您的爬虫的名称,例如
pgaudit_crawler。 - 选择 “ 下一步 ” 。
- 对于 “添加数据存储 ” ,选择 S3。
- 在 包含路径 中 ,输入要抓取的文件夹或文件的 S3 路径。
- 选择 “ 下一步 ” 。
- 对于 “添加其他数据存储 ” ,选择 “ 否 ” 。
- 对于 选择 IAM 角色 ,选择具有必要权限的现有角色或让 亚马逊云科技 Glue 为您创建角色。
-
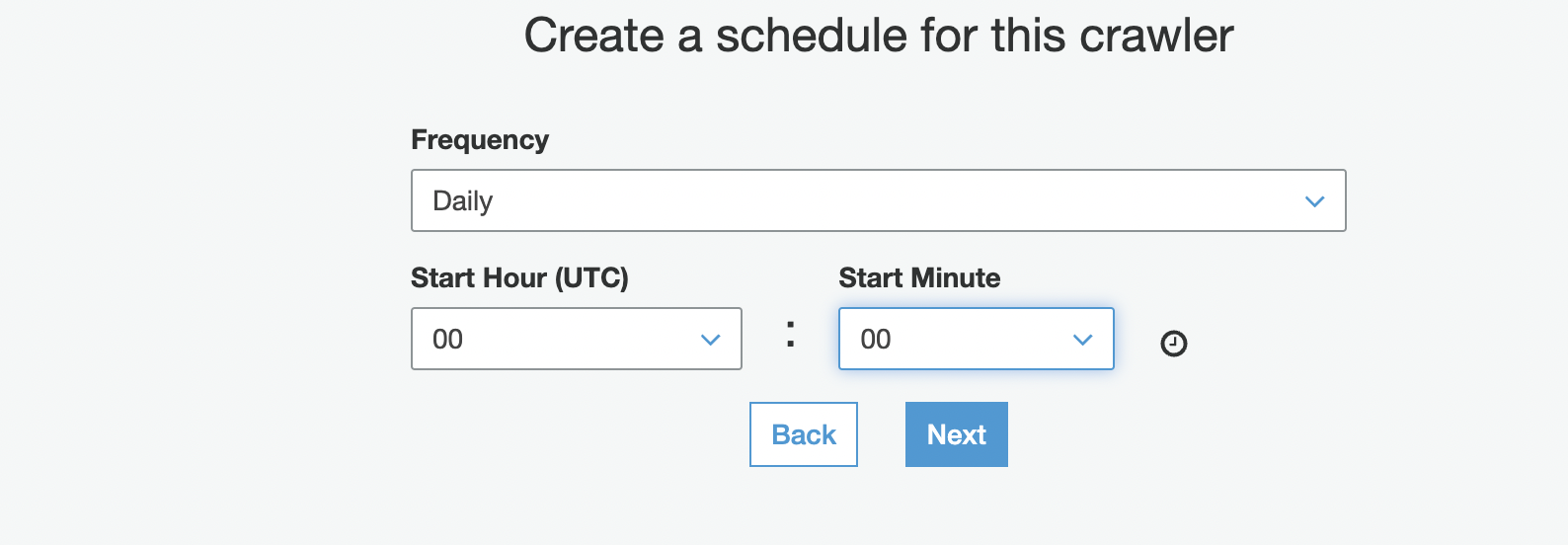
在 “
为该爬虫 创建时间表
” 部分的 “
频率
” 中 ,选择 “
每日
”。
您也可以选择按需运行爬虫。 - 输入您的起始小时和分钟信息。
- 选择 “ 下一步 ” 。
有关配置爬虫的更多信息,请参阅
当这个爬虫运行时,它会自动创建一个 亚马逊云科技 Glue 表。它还基于 S3 存储桶中的文件夹结构创建表架构和分区。
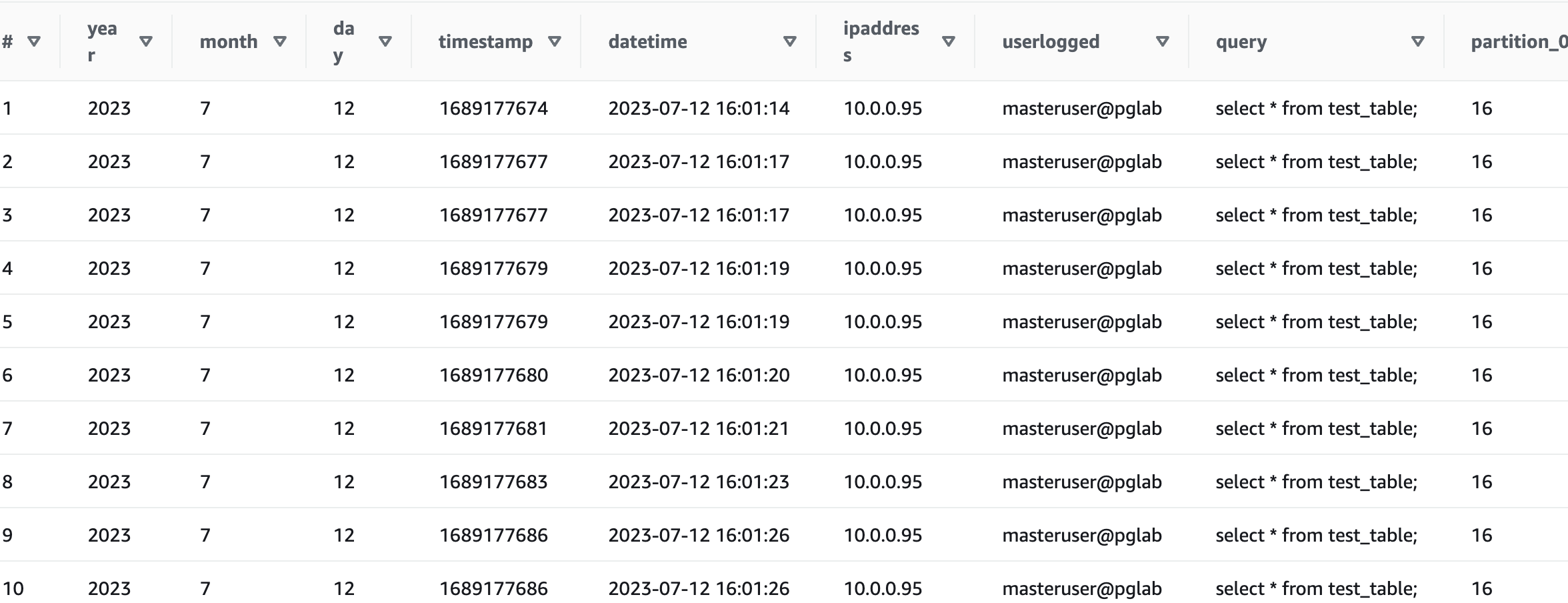
运行 Athena 查询以识别数据库性能问题
现在我们已经使用 亚马逊云科技 Glue 创建了数据库和表,我们可以分析和找到有关数据库的有用见解。我们使用 Athena 运行 SQL 查询,以了解数据库的使用情况并识别潜在问题(如果有)。Athena 是一种无服务器交互式查询服务,可使用标准 SQL 轻松分析数据。您只需为运行的查询付费。有关更多信息,请参阅
要测试我们的解决方案,请运行以下查询:
运行以下查询:
清理
为了避免持续产生费用,请删除您在这篇文章中创建的资源。
-
删除 IAM 角色 。 - 删除 Lambda 函数。
-
删除 S3 存储桶 。 -
删除 PostgreSQL 版的 RDS 实例。 - 删除 Firehose 配送流。
-
删除 亚马逊云科技 Glue 数据库 。
结论
在这篇文章中,我们演示了如何从 RDS for PostgreSQL 数据库中捕获和存储审计数据并将其存储在 Amazon S3 中、使用 Aws Glue 对其进行处理,以及如何使用 Athena 对其进行查询。此解决方案可以帮助您生成审计报告。该解决方案也适用于兼容
如果您对此帖子有任何意见或疑问,请在评论中分享。
作者简介
 Kavita Vellala
是 亚马逊云科技 的高级数据库顾问,在数据库技术方面拥有丰富的经验。Kavita 曾开发过甲骨文、SQL Server、PostgreSQL、MySQL、Couchbase 和亚马逊 Redshift 等数据库引擎。在 亚马逊云科技,她帮助客户进行数字化转型,并加快将其数据库工作负载迁移到 亚马逊云科技 云的速度。她喜欢调整创新的人工智能和机器学习技术来帮助公司解决新问题,并更高效、更有效地解决旧问题。
Kavita Vellala
是 亚马逊云科技 的高级数据库顾问,在数据库技术方面拥有丰富的经验。Kavita 曾开发过甲骨文、SQL Server、PostgreSQL、MySQL、Couchbase 和亚马逊 Redshift 等数据库引擎。在 亚马逊云科技,她帮助客户进行数字化转型,并加快将其数据库工作负载迁移到 亚马逊云科技 云的速度。她喜欢调整创新的人工智能和机器学习技术来帮助公司解决新问题,并更高效、更有效地解决旧问题。
 Sharath Lingareddy
是亚马逊网络服务专业服务团队的高级数据库架构师。他曾使用甲骨文、PostgreSQL、MySQL DynamoDB、亚马逊 RDS 和 Aurora 提供解决方案。他的重点领域是将本地数据库同构和异构迁移到亚马逊 RDS 和 Aurora PostgreSQL。
Sharath Lingareddy
是亚马逊网络服务专业服务团队的高级数据库架构师。他曾使用甲骨文、PostgreSQL、MySQL DynamoDB、亚马逊 RDS 和 Aurora 提供解决方案。他的重点领域是将本地数据库同构和异构迁移到亚马逊 RDS 和 Aurora PostgreSQL。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。