我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
ByteDance 在亚马逊云科技 Inferentia2 上使用其多模态视频理解模型每天处理数十亿个视频
这是一篇由字节跳动团队撰写的客座帖子。
ByteDance 是一家科技公司,运营一系列内容平台,为不同语言、文化和地域的人们提供信息、教育、娱乐和激励他们。用户信任并喜欢我们的内容平台,因为它们提供了丰富、直观和安全的体验。我们的机器学习 (ML) 后端引擎使这些体验成为可能,其机器学习模型专为视频理解、搜索、推荐、广告和新颖视觉效果而构建。
为了支持其"激发创造力,丰富生活"的使命,我们让人们参与、创作和消费内容变得简单而有趣。人们还可以发现十几种产品和服务并进行交易,例如 CapCut、e-Shop、Lark、Pico 和 Mobile Legends:Bang Bang。
在字节跳动,我们与亚马逊云科技合作,使用 Amazon Inferentia2 在全球多个亚马逊云科技区域部署多模式大型语言模型(LLM)以进行视频理解。通过使用复杂的机器学习算法,该平台每天可以高效扫描数十亿个视频。我们使用此流程来识别和举报违反社区准则的内容,从而为所有用户提供更好的体验。通过使用 Amazon EC2 Inf2 实例来处理这些视频理解工作负载,我们得以将推理成本降低一半。
在这篇文章中,我们讨论了使用多模态 LLM 进行视频理解、解决方案架构和性能优化技术。
使用多模式 LLM 克服视频理解障碍
多模式 LLM 可以更好地了解世界,使各种形式的数字内容作为 LLM 的输入,极大地增加了我们现在可以构建的有用应用程序的范围。对能够处理各种内容形式的人工智能系统的需求变得越来越明显。多模态 LLM 通过采用多种数据模式来应对这一挑战,包括文本、图像、音频和视频(参见下图),这些模式允许对内容的充分理解,模仿人类的感知以及与世界的互动。这些模型的增强功能在性能上显而易见,在从复杂的虚拟助手到高级内容创建等任务中,它们远远超过了传统模型。通过扩大人工智能能力的边界,为与技术的更自然、更直观的交互铺平道路,这些模型不仅改善了现有应用程序,而且为人工智能和用户体验领域的全新可能性打开了大门。
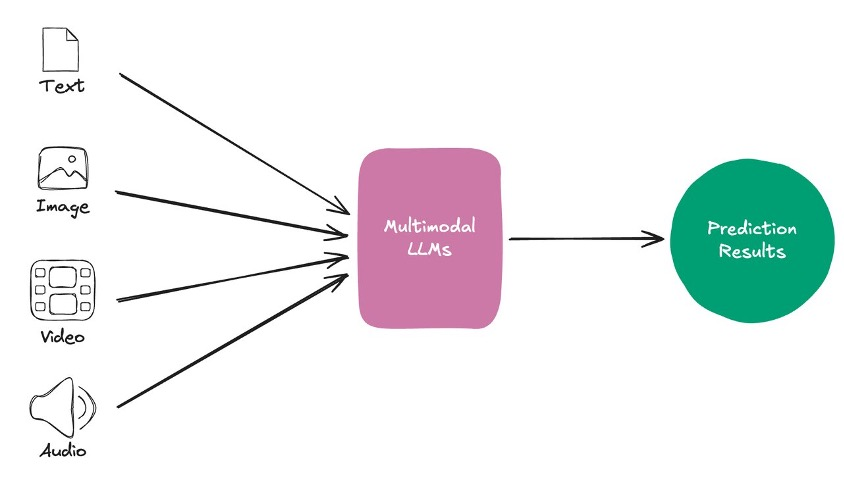
在我们的运营中,用于视频理解的多模态 LLM 的实施代表了对人工智能驱动内容分析的思维的重大转变。这项创新解决了处理数十亿量视频内容的日常挑战,克服了传统 AI 模型的效率极限。我们开发了自己的多模式 LLM 架构,旨在实现单图像、多图像和视频应用程序的最先进性能。与传统机器学习模型不同,这种支持人工智能的新一代系统将多个输入流集成到一个统一的表示空间中。跨模态注意力机制促进了模式之间的信息交换,融合层结合了来自不同模式的表现形式。然后,解码器根据融合的多模态表示生成输出,从而可以对内容进行更加细致入微的情境感知分析。
解决方案概述
自第一代 Inferentia 芯片问世以来,我们就一直与亚马逊云科技合作。我们的视频理解部门一直致力于寻找更具成本效益的解决方案,以提供更高的性能,更好地满足不断增长的业务需求。在此期间,我们发现亚马逊云科技一直在为其亚马逊云科技 Neuron 软件开发套件 (SDK) 发明和添加特性和功能,该软件支持在 Inferentia 芯片上运行高性能工作负载。广受欢迎的 Meta Llama 和 Mistral 模型在开源发布后不久便在 Inferentia2 上得到了良好的支持,性能也很高。因此,我们开始评估基于 Inferentia2 的解决方案,如下图所示。
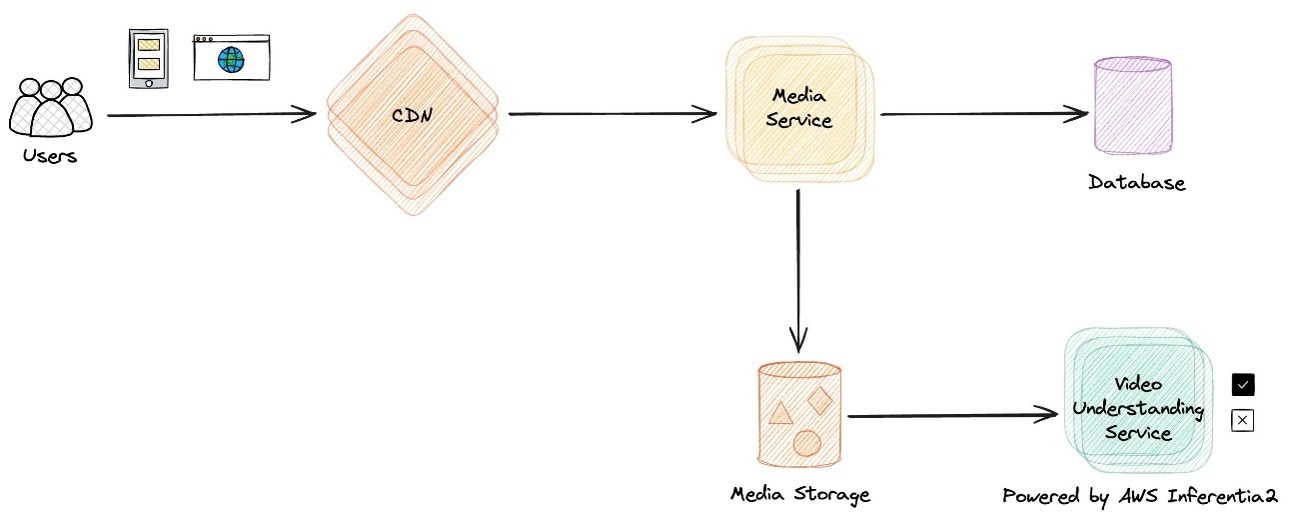
我们做出了战略决定,在 Inferentia2 上部署经过微调的中型 LLM,以提供高性能且具有成本效益的解决方案,能够每天处理数十亿个视频。该过程是一项综合性工作,旨在优化我们的视频理解工作负载的端到端响应时间。该团队探索了广泛的参数,包括张量并行大小、编译配置、序列长度和批次大小。我们采用了各种并行化技术,例如跨多个 NeuronCore 的多线程和模型复制(适用于非 LLM 模型)。通过这些优化,包括并行化序列步骤、重复使用设备以及使用自动基准测试和分析工具,我们实现了显著的性能提升,保持了我们在行业性能标准前沿的地位。
我们使用张量并行度在 Inf2 实例中的多个加速器上有效地分布和扩展模型。我们使用静态批处理,通过确保在推理期间以统一、固定大小的批处理数据来改善模型的延迟和吞吐量。使用重复的 n-gram 过滤可以显著提高自动生成的文本的质量并缩短推理时间。量化从 FP16/BF16 到 INT8 格式的多模态模型的权重使其能够在不影响精度的前提下,在 Inferentia2 上更高效地运行,同时减少设备内存使用量。使用这些技术和模型序列化,我们通过最大化批量大小来优化 inf2.48xlarge 实例的吞吐量,使模型仍然可以安装在实例中的单个加速器上,因此我们可以在同一个实例上部署多个模型副本。这种全面的优化策略帮助我们满足了延迟要求,同时提供了优秀的吞吐量和成本降低。值得注意的是,与同类的 Amazon EC2 实例相比,基于 Inferentia2 的解决方案将成本降低了一半,这凸显了使用 Inferentia2 芯片执行大规模视频理解任务的显著经济优势。
下图显示了我们如何使用 Neuron 在 Amazon EC2 Inf2 实例上部署 LLM 容器。
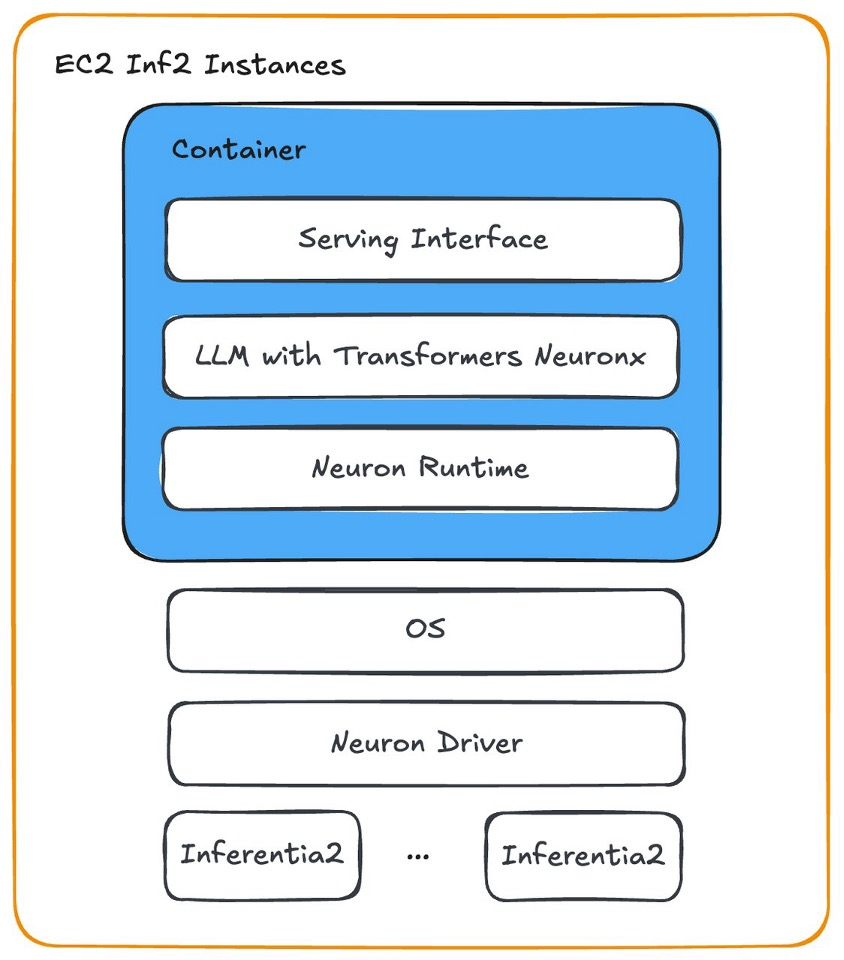
总之,我们与亚马逊云科技的合作彻底改变了视频理解,为效率和准确性设定了新的行业标准。多模态 LLM 适应全球市场需求的能力及其在 Inferentia2 芯片上的可扩展性能突显了该技术对保护该平台全球社区的深远影响。
未来的计划
展望未来,统一的多模式 LLM 的开发代表着视频理解技术的重要转变。这个雄心勃勃的项目旨在创建一个通用的内容代币生成器,该标记器能够处理所有内容类型并将其协调在一个共同的语义空间中。对内容进行标记化后,将由高级大型模型对内容进行分析,无论原始格式如何,都会生成相应的内容理解输出(如下图所示)。这种统一的方法可以简化内容理解过程,有可能提高不同内容类型的效率和一致性。
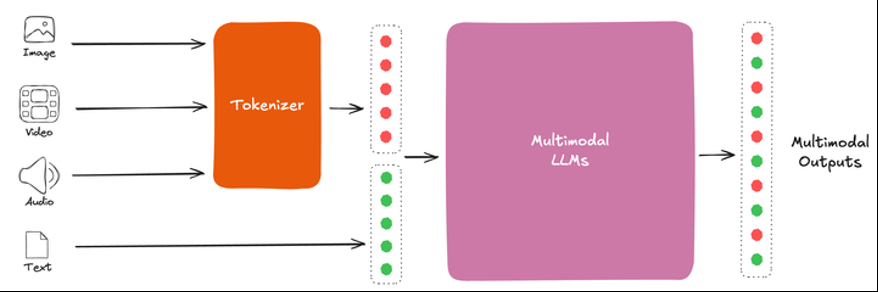
要了解更多信息,请参阅论文《多模态模型架构的演变》。
这项综合战略的实施为视频理解技术树立了新的基准,在日益复杂的数字生态系统中,在准确性、速度和文化敏感度之间取得了平衡。这种前瞻性的方法不仅解决了当前视频理解方面的挑战,而且在可预见的将来,将系统置于人工智能驱动的内容分析和管理的最前沿。
通过使用尖端的人工智能技术和全面的内容理解方法,这种下一代内容理解系统旨在设定新的行业标准,提供更安全、更具包容性的在线环境,同时适应不断变化的数字通信格局。同时,亚马逊云科技正在投资下一代人工智能芯片,例如 Amazon Trainium2,它将继续突破性能界限,同时控制成本。在 ByteDance,我们计划测试新一代的亚马逊云科技 AI 芯片,并在模型和工作负载不断演变时适当地采用它们。
结论
通过在 Inferentia2 芯片上部署多模态 LLM,字节跳动和亚马逊云科技之间的合作彻底改变了视频理解。与同类 EC2 实例相比,这种合作取得了显著成果,能够每天处理数十亿个视频,并显著降低了成本,提高了性能。
随着 ByteDance 继续通过统一多模态大型模型等项目进行创新,我们将继续致力于突破人工智能驱动的内容分析的界限。我们的目标是确保我们的平台为全球社区提供安全、包容和创新的空间,为高效的视频理解设定新的行业标准。
要了解有关 Inf2 实例的更多信息,请参阅 Amazon EC2 Inf2 架构。
作者简介
 安旺鹏,抖音首席算法工程师,专门研究用于视频理解、广告和推荐的多模态 LLM。他领导了模型加速、内容审核和广告 LLM 管道方面的关键项目,增强了 TikTok 的实时机器学习系统。
安旺鹏,抖音首席算法工程师,专门研究用于视频理解、广告和推荐的多模态 LLM。他领导了模型加速、内容审核和广告 LLM 管道方面的关键项目,增强了 TikTok 的实时机器学习系统。
 张浩天是 TikTok 的科技主管 MLE,专门研究内容理解、搜索和推荐。他获得了滑铁卢大学的机器学习博士学位。在 TikTok,他带领一组工程师提高 LLM 和多模态 LLM(尤其是大型分布式 ML 系统)的训练和推理的效率、稳健性和有效性。
张浩天是 TikTok 的科技主管 MLE,专门研究内容理解、搜索和推荐。他获得了滑铁卢大学的机器学习博士学位。在 TikTok,他带领一组工程师提高 LLM 和多模态 LLM(尤其是大型分布式 ML 系统)的训练和推理的效率、稳健性和有效性。
 丁小杰是 TikTok 的高级工程师,专注于内容审核系统开发、模型资源和部署优化以及算法工程稳定性构建。在空闲时间,他喜欢玩单人游戏。
丁小杰是 TikTok 的高级工程师,专注于内容审核系统开发、模型资源和部署优化以及算法工程稳定性构建。在空闲时间,他喜欢玩单人游戏。
 杨娜川是抖音的高级工程师,专注于内容安全和审核。他先后从事审核系统的构建、模型应用程序以及部署和性能优化。
杨娜川是抖音的高级工程师,专注于内容安全和审核。他先后从事审核系统的构建、模型应用程序以及部署和性能优化。
 孙开荣是字节跳动反洗钱团队的高级管理人员。他的职责侧重于维护集群内资源的无缝运行和高效分配,专门从事集群计算机维护和资源优化。
孙开荣是字节跳动反洗钱团队的高级管理人员。他的职责侧重于维护集群内资源的无缝运行和高效分配,专门从事集群计算机维护和资源优化。
作者要感谢其他字节跳动和亚马逊云科技团队成员的贡献:来自字节跳动的戴希、赵凯丽、张志新、叶金和夏燕;来自亚马逊云科技的董佳、黄冰洋、卡姆兰·汗、什鲁蒂·科帕卡尔和迪瓦卡尔·班萨尔。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。