我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 Systems Manager 集中管理配置
在这篇客座文章中,来自Xero的凯特琳·费多拉克(工程师)和撰稿人、科迪·奥尔森(高级工程师)、威尔·斯科特(工程师)、塞缪尔·拉古南丹(工程师)讨论了他们使用亚马逊云科技 Systems Manager库存和状态管理器对亚马逊EC2实例进行配置管理。任何团队或公司都可以利用本文中描述的类似设计来节省许可成本,更灵活地使用输出数据,提高对其中实例和软件配置的可见性,并减少因错误配置而导致的事件。
Xero是新西兰、澳大利亚和英国云会计领域的领导者,为180多个国家的350多万用户提供服务。Xero以简单、智能和安全的方式为企业主提供其财务状况和绩效的实时可见性。Xero将小型企业与他们的顾问和其他服务联系起来。对于会计师而言,Xero通过在线合作与客户建立了信任关系,并为会计师提供了扩展服务的机会。
整个系统的错误配置可能会导致许多易于避免的生产事件或合规性问题,但是如果您没有简单的方法来查看当前的配置设置,则几乎不可能提前找到这些事件。市面上有许多预建的配置管理工具,但是如果这些预建工具无法检查您需要管理的系统的每个区域呢?
特别是,除了操作系统和硬件等更通用的检查之外,找到一种能够在实例上检查特定软件(例如
概述
市场上的许多预建工具都有一组原生支持的支票,但是除了这些检查组之外,你可能需要涵盖许多支票。由于权限限制,例如访问多个安全性良好的 亚马逊云科技 账户进行 CLI 调用或授予对数据库服务运行查询的权限,其中一些检查可能非常难以构建。还需要考虑额外的费用,因为您需要为大多数可用工具支付企业许可证,更不用说管理实例来托管工具本身了。
架构
在评估了几种可用的预建工具之后,Xero 决定构建自己的解决方案。该选项比购买预建工具的企业许可证便宜,因为大部分成本来自将包含配置数据的文本文件存储在 S3 中,然后使用 Athena;Systems Manager 设计的所有部分都不会产生任何额外费用。
此外,由于Xero已经在其实例上使用了Systems Manager的其他方面,因此该解决方案消除了授予新工具访问所有配置数据的权限所产生的所有开销。最后,由于数据收集脚本的组织方式,该工具提供了一种针对新的配置区域进行调整的简便方法,使其具有高度的可定制性,可与任何团队的工具集一起使用。
下图显示了 Xero 配置管理工具的架构。它从 “
库存数据由 亚马逊云科技 账户 ID 和区域自动分隔,因此您需要在每个 亚马逊云科技 账户和区域中部署资源数据同步器,并使用您希望监控的托管节点。通过将从所有托管节点收集的库存数据发送到单个 S3 存储桶,您可以全面了解队列。
Xero 还托管自我管理的 JavaScript 对象表示法 (JSON) 文件,这些文件在 S3 存储桶中包含所需的理想配置状态。这些 JSON 文件可以手动更新或添加到您的自动更新/配置流程中。
信息存入 S3 存储桶后,Glue 爬虫会扫描该存储桶以创建数据库和表,然后您可以使用 Athena 进行查询。然后,Lambda 使用理想的状态文件来编写 Athena 查询,以查找任何配置错误的实例。生成的输出可用于任意数量的解决方案,例如自动修复或待命警报。
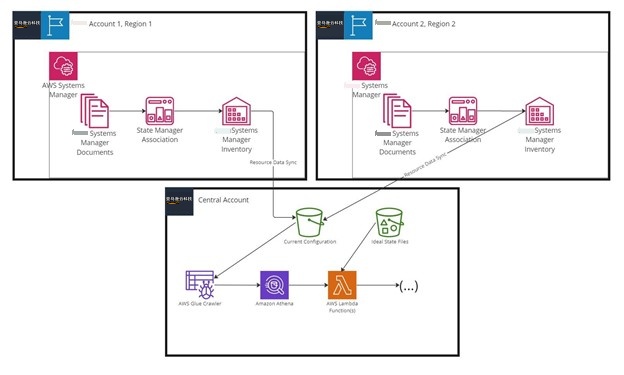
图 1:配置管理的架构图。
根据您的数据创建自定义解决方案
Xero 能够创建单一解决方案来收集多个组件的配置状态,最值得注意的是硬件、亚马逊云科技 中的其他设置、操作系统和 SQL Server。该解决方案易于定制,在获得适当权限时可以收集您想要的任何类型的配置数据。自定义解决方案在两个关键领域会根据您自己的配置数据的外观而有所不同,即在状态管理器和 Lambda 函数中。
先决条件
州经理协会
该文档至少必须有两项操作:
-
aws: runshellScript 或 aws: run Powershell -
亚马逊云科技:软件清单
可以在 GitHub 上查看允许你传入 PowerShell 命令的最小文档示例:
第一个操作
aws: runShellScript
或
aws: runPowerShellScript
允许你运行自己的 Shell 或 PowerShell 脚本来收集清单收集的
第二个操作
aws: SoftwareInv
entory 可以做两件事:它从您的实例中收集标准元数据,并允许将您的
自定义清单
索引到清单中,然后使用资源数据同步将清单同步到 S3 存储桶。务必确保
aws: SoftwareIn
ventory 在自定义脚本块之后 运行,否则不会为自定义清单数据建立索引。
此外,托管节点应仅与单个库存关联相关联,以防止出现意外行为,有关更多信息,请参阅
定义自定义库存数据结构
设计这个阶段的大部分工作都放在命令文档中的自定义代码块中。这将根据您自己的配置数据的结构而有所不同。Xero团队需要检查大量设置,因此Xero首先将这些设置分为几类,最后是将近20个单独的类别。例如,收集的两个设置与服务器的缓冲池扩展 (BPE) 比率和文件大小有关:
{
"common": {
"BPE_Ratio": {
"{*}": "1:8"
},
"BPE_File_Size": {
"i3.xlarge": "244",
"i3.2xlarge": "488",
"i3.4xlarge": "976",
"i3.8xlarge": "1952",
"i3en.xlarge": "256",
"i3en.2xlarge": "512",
"i3en.3xlarge": "768",
"i3en.6xlarge": "1536",
"i3en.12xlarge": "3072"
}
}
}完成此操作后,他们设计了如何构造每个类别的最终输出 JSON,以完全理解 JSON 条目指的是哪个设置。有了这个,他们发现他们可以使用两种不同的 JSON 结构来完全理解其配置数据的每个类别。
为了创建自定义清单数据,每个数据点的 JSON 结构必须相同,因此收集所有配置数据意味着有两种自定义清单类型。如果您要涵盖大量类别,或者类别中包含类似信息,很难为其编写单独的查询,则可能需要在每个条目中包含一个 c
ategoryName
键。
收集自定义清单元数据
一旦创建了整体数据结构,就可以编写实际收集数据的命令行管理程序或 PowerShell 脚本。根据你需要收集多少积分,将内容拆分成一个顶级脚本,每个数据类别调用一个下标可能是有意义的。这些脚本通过内置函数、API 调用、查询或任何其他可用方法以编程方式收集你想要检查的每项设置。
每个设置都是一个添加到 JSON 列表中的数据点,每个 JSON 结构都有单独的列表。为了便于调试,你可以将它们作为 JSON 文本文件存储在临时文件夹中。收集完所有这些信息后,该脚本的最后步骤必须将这些数据点合并为每个 JSON 结构的单个文件。将此自定义清单发送到清单的 SSM 代理要求将 JSON 文件存储在
Lambda 函数
满足您自己需求的自定义解决方案的第二个关键部分是管道末尾的 Lambda 函数。根据配置数据的结构和创建的自定义清单类型的数量,为每个数据类别创建一个比较 Lambda 可能是有意义的,这样就不会出现庞大且难以管理的 Lambda 函数。
这些 Lambda 函数应从 S3 存储桶中提取理想的配置文件,并使用它们来构造 Athena 查询。生成的 Athena 查询返回的项目示例如下:
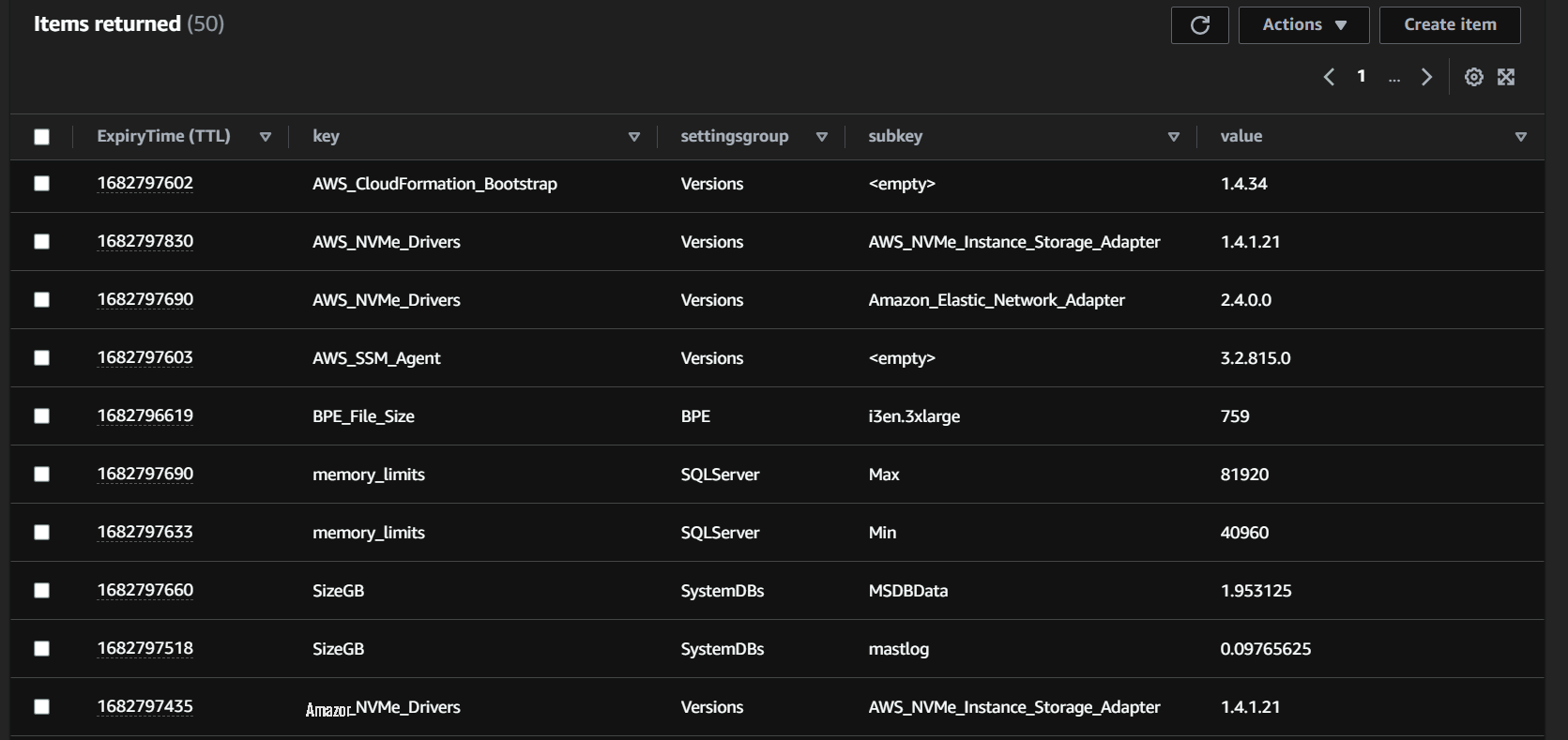
图 2:自定义清单元数据的 Athena 查询结果示例。
这些 Athena 查询应查找并列出在返回的项目中发现的任何错误配置。如果理想配置文件的格式足够一致,则可以创建辅助函数,这些函数可以根据理想文件的内容动态构建查询,否则您可以维护硬编码查询,这对于一次性配置来说更容易。
一旦您的 Lambda 函数给出了错误配置列表,您就可以选择如何处理这些错误。您可以设计具有自动修复功能的系统,向值班工程师发送紧急问题,或者发送非紧急配置错误报告,以便在预定的维护时段内进行处理。 可以利用
可以在以下 GitHub 存储库中找到 Lambda 函数示例:
摘要
这篇文章介绍了 Xero 如何能够创建具有广泛用途和覆盖范围的配置管理工具。任何团队或公司都可以利用类似的设计来节省许可成本,更灵活地使用输出数据,提高他们对实例和其中软件配置的可见性,并减少因错误配置而导致的事件。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。