我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 SageMaker Python SDK 配置和使用亚马逊 SageMaker 资源的默认值
从 SageMaker Python 软件开发工具包版本 2.148.0 开始,您现在可以为 IAM 角色、VPC 和 KMS 密钥等参数配置默认值。管理员和最终用户可以使用 YAML 格式的配置文件中指定的默认值初始化 亚马逊云科技 基础设施原语。
配置完成后,Python SDK 会自动继承这些值并将其传播到底层 SageMaker API 调用,例如 createP
该开发工具包还支持多个配置文件,允许管理员为所有用户设置配置文件,用户可以通过用户级配置来覆盖该文件,该配置可以存储在
rocessingJob () 、createT rainingJob ()
和 createEndpointConfig () ,无需
执行其他操作。
在这篇文章中,我们将向您展示如何在 Studio 中创建和存储默认配置文件,以及如何使用 SDK 默认功能来创建 SageMaker 资源。
解决方案概述
我们使用端到端
- 在您的账户中启动 CloudFormation 堆栈。或者,如果您想在现有 SageMaker 域名或笔记本电脑上探索此功能,请跳过此步骤。
-
填充
config.yaml文件并将该文件保存在默认位置。 - 运行包含端到端机器学习用例的示例笔记本,包括数据处理、模型训练和推理。
- 覆盖默认配置值。
先决条件
开始之前,请确保您拥有 亚马逊云科技 账户和具有管理员权限的 IAM 用户或角色。如果您是一名数据科学家,目前正在将基础架构参数传递给笔记本中的资源,则可以跳过设置环境的下一步,开始创建配置文件。
要使用此功能,请务必通过运行
pip install--up
grade sagemaker 来升级你的 SageMaker SDK 版本。
设置环境
要部署包括网络和 Studio 域在内的完整基础架构,请完成以下步骤:
-
克隆
GitHub 存储库 。 - 登录您的 亚马逊云科技 账户并打开 亚马逊云科技 CloudFormation 控制台。
- 要部署网络资源,请选择 创建堆栈 。
-
在 setup/vpc_mode
/01_networking.yaml下上传模板。 -
为堆栈提供名称(例如,
网络堆栈 ),然后完成创建堆栈的剩余步骤。 - 要部署 Studio 域,请 再次选择 创建堆栈 。
-
在
setup/vpc_mode/02_sagemaker_studio.yaml下上传模板。 -
提供堆栈的名称(例如sagemaker-stack ),并在提示输入 coreNetworkingStackName 参数时提供网络堆栈的名称。 - 继续执行剩余的步骤,选择 IAM 资源的确认信息,然后创建堆栈。
当两个堆栈的状态更新为 CREATE_COM PLETE 时 ,继续执行下一步。
创建配置文件
要使用 SageMaker Python SDK 的默认配置,您需要按软件开发工具包期望的格式创建一个 config.yaml 文件。有关 config.yaml 文件的格式,请参阅
要轻松创建
config.yaml
文件,请在 Studio 系统终端中运行以下单元,将占位符替换为上一步中的 CloudFormation 堆栈名称:
此脚本会自动填充 YAML 文件,用基础架构默认值替换占位符,并将文件保存在主文件夹中。然后它将文件复制到 Studio 笔记本电脑的默认位置。生成的配置文件应与以下格式类似:
如果您已经设置了现有的域和网络配置,请按所需格式创建
config.yaml
文件,并将其保存在 Studio 笔记本电脑的默认位置。
请注意,这些默认值只是自动填充相应的 SageMaker SDK 调用的配置值,并不强制用户使用任何特定的 VPC、子网或角色。作为管理员,如果您希望用户使用特定的配置或角色,请使用
此外,每个 API 调用可以有自己的配置。
例如,在前面的配置文件示例中,您可以为训练作业指定
vpc-a
和
子网
a, 为处理作业指定
vpc-b
和 子网 c、子网 d。
运行示例笔记本
现在您已经设置了配置文件,您可以像往常一样开始运行模型构建和训练笔记本,无需为大多数 SDK 函数明确设置网络和加密参数。有关
在 Studio 中,选择导航窗格中的文件资源管理器图标并打开
03_feature_engineering/03_feature_eng
ineering.ipynb,如以下屏幕截图所示。
逐个运行笔记本单元,注意您没有指定任何其他配置。创建处理器对象时,您将看到像以下示例一样的单元输出。
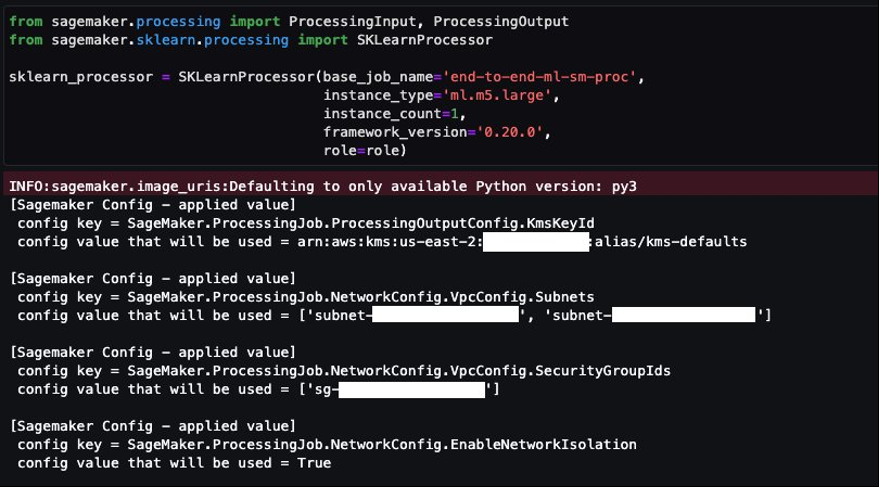
正如您在输出中看到的那样,默认配置会自动应用于处理作业,无需用户进行任何其他输入。
当您运行下一个单元来运行处理器时,您还可以通过在 SageMaker 控制台上查看作业来验证是否设置了默认值。在导航窗格 中选择 “ 处理 ” 下的 “处理作 业 ”,如以下屏幕截图所示。
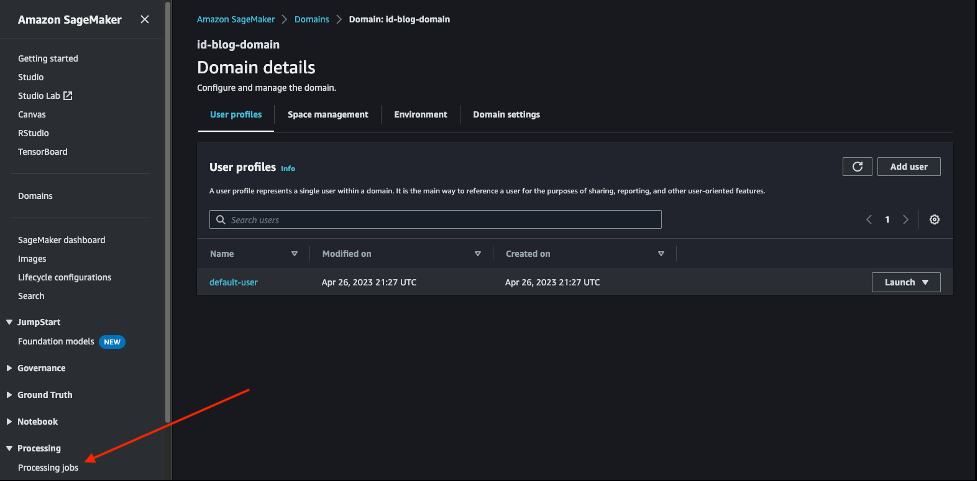
选择前缀为
端到端 ml-sm-proc
的处理作业 ,您应该能够查看已经配置的网络和加密。

您可以继续运行剩余的笔记本来训练和部署模型,并且您会注意到基础架构默认值会自动应用于训练作业和模型。
覆盖默认配置文件
在某些情况下,用户可能需要覆盖默认配置,例如,尝试公共互联网接入,或者在子网用完 IP 地址时更新网络配置。在这种情况下,Python SDK 还允许您为配置文件提供自定义位置,可以在本地存储上,也可以指向 Amazon S3 中的某个位置。在本节中,我们将探讨一个示例。
在 TrainingJob 部分打开主目录下的
user-config.yaml
文件,然后将
enableNetworkSolation
值更新为 True。
现在,打开同一个笔记本,并将以下单元格添加到笔记本的开头:
使用此单元格,将配置文件的位置指向 SDK。现在,当你创建处理器对象时,你会注意到默认配置已被重写以启用网络隔离,并且处理作业将在网络隔离模式下失败。
如果您使用本地环境(如 VSCode),则可以使用相同的替代环境变量来设置配置文件的位置。
调试和检索默认值
如果您在笔记本上运行 API 调用时遇到任何错误,为了快速排除故障,单元输出会显示应用的默认配置,如上一节所示。要查看为查看从默认配置文件传递的属性值而创建的确切的 Boto3 调用,您可以通过启用 Boto3 日志记录进行调试。要开启日志记录,请在笔记本顶部运行以下单元:
任何后续的 Boto3 调用都将与完整请求一起记录,该请求将在日志的正文部分下方可见。
您还可以使用 s
ession.sagemaker_config
值查看默认配置的集合,如以下示例所示。
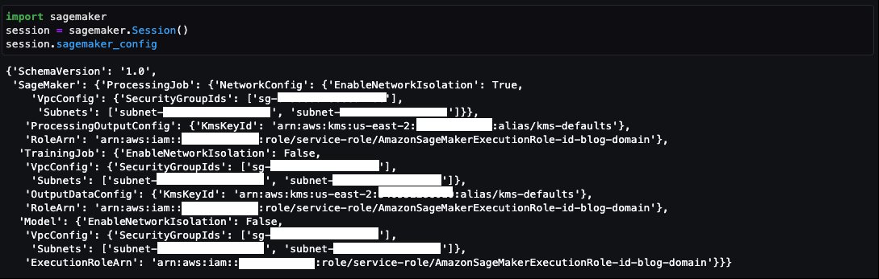
最后,如果你使用 Boto3 来创建 SageMaker 资源,你可以使用 sagemaker_config 变量检索默认配置值。
例如,要 使用
Boto3 运行 03_feature_engineering.ipynb
中的处理作业,可以在同一个笔记本中输入以下单元格的内容并运行该单元:
自动创建配置文件
对于管理员来说,必须创建配置文件并将文件保存到每个 SageMaker 笔记本实例或 Studio 用户配置文件可能是一项艰巨的任务。尽管您可以建议用户使用存储在默认 S3 位置的通用文件,但这会给数据科学家带来额外的开销。
要自动执行此操作,管理员可以使用 SageMaker 生命周期配置 (LCC)。对于 Studio 用户配置文件或笔记本实例,您可以将以下示例 LCC 脚本附加为用户默认 Jupyter Server 应用程序的默认 LCC:
有关创建和设置
清理
试用完此功能后,请清理资源以避免支付额外费用。如果您已按照本文中的说明配置了新资源,请完成以下步骤来清理资源:
-
为用户配置文件关闭您的 Studio 应用程序。有关说明,请参阅
关闭和更新 SageMaker Studio 和 Studio 应用程序 。在删除堆栈之前,请确保删除所有应用程序。 -
删除为工作室域创建的 EFS 卷。您可以使用 DescribeDomain API 调用查看与该域关联
的 E FS 卷。 - 删除 Studio 域堆栈。
-
删除为 Studio 域创建的安全组。你可以在
亚马逊弹性计算云 (Amazon EC2)控制台上找到它们,其名称分别为入境安全组-nfs-d-xxx 和安全组-for-bound-nfs-d-xxx - 删除网络堆栈。
结论
在这篇文章中,我们讨论了使用 SageMaker Python SDK 配置和使用关键基础设施参数的默认值。这允许管理员为数据科学家设置默认配置,从而为用户和管理员节省时间,消除重复指定参数的负担,从而生成更精简、更易于管理的代码。有关支持的参数和 API 的完整列表,请参阅使用
作者简介
 Giuseppe Angelo Porcel li
是亚马逊网络服务的首席机器学习专家解决方案架构师。凭借数年的软件工程和机器学习背景,他与任何规模的客户合作,深入了解他们的业务和技术需求,并设计出充分利用 亚马逊云科技 云和亚马逊机器学习堆栈的人工智能和机器学习解决方案。他曾参与过不同领域的项目,包括 mLOP、计算机视觉、自然语言处理,并涉及大量 亚马逊云科技 服务。在空闲时间,朱塞佩喜欢踢足球。
Giuseppe Angelo Porcel li
是亚马逊网络服务的首席机器学习专家解决方案架构师。凭借数年的软件工程和机器学习背景,他与任何规模的客户合作,深入了解他们的业务和技术需求,并设计出充分利用 亚马逊云科技 云和亚马逊机器学习堆栈的人工智能和机器学习解决方案。他曾参与过不同领域的项目,包括 mLOP、计算机视觉、自然语言处理,并涉及大量 亚马逊云科技 服务。在空闲时间,朱塞佩喜欢踢足球。
 Bruno Pistone
是 亚马逊云科技 的人工智能/机器学习专业解决方案架构师,总部位于米兰。他与任何规模的客户合作,帮助他们深入了解他们的技术需求,设计能够充分利用 亚马逊云科技 云和亚马逊机器学习堆栈的人工智能和机器学习解决方案。他的专业领域是端到端机器学习、机器学习工业化和 mLOP。他喜欢与朋友共度时光,探索新地方,也喜欢去新的目的地旅行。
Bruno Pistone
是 亚马逊云科技 的人工智能/机器学习专业解决方案架构师,总部位于米兰。他与任何规模的客户合作,帮助他们深入了解他们的技术需求,设计能够充分利用 亚马逊云科技 云和亚马逊机器学习堆栈的人工智能和机器学习解决方案。他的专业领域是端到端机器学习、机器学习工业化和 mLOP。他喜欢与朋友共度时光,探索新地方,也喜欢去新的目的地旅行。
 杜尔加·苏里
是亚马逊 SageMaker Service SA 团队的机器学习解决方案架构师。她热衷于让每个人都能使用机器学习。在 亚马逊云科技 工作的 4 年中,她帮助企业客户建立了 AI/ML 平台。当她不工作时,她喜欢骑摩托车、神秘小说,还喜欢和她5岁的哈士奇一起长途跋涉。
杜尔加·苏里
是亚马逊 SageMaker Service SA 团队的机器学习解决方案架构师。她热衷于让每个人都能使用机器学习。在 亚马逊云科技 工作的 4 年中,她帮助企业客户建立了 AI/ML 平台。当她不工作时,她喜欢骑摩托车、神秘小说,还喜欢和她5岁的哈士奇一起长途跋涉。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。