这是一篇由亚马逊云科技和Voxel51共同撰写的联合文章。Voxel51是FiftyOne背后的公司,FiftyOne是一款用于构建高质量数据集和计算机视觉模型的开源工具包。
一家零售公司正在开发一款移动应用程序来帮助客户购买衣服。要创建此应用程序,他们需要一个包含服装图像的高质量数据集,并标有不同的类别。
在这篇文章中,我们将介绍如何使用Fi
ftyOne中的零镜头分类模型通过数据清理、预处理和预标记来重新利用现有数据集,并使用Amazon SageMaker Ground Tr
uth调整这些标签。
你可以使用 Ground Truth 和 FiftyOne 来加速你的数据标签项目。我们将说明如何将这两个应用程序无缝地结合使用来创建高质量的标记数据集。在我们的示例用例中,我们使用的是在 ICCV 2017 上发布的
Fashion200K 数据集
。
解决方案概述
Ground Truth 是一项完全自助和托管的数据标签服务,它使数据科学家、机器学习 (ML) 工程师和研究人员能够构建高质量的数据集。
Voxel51
的 Fi@@
ftyOn
e 是一款开源工具包,用于整理、可视化和评估计算机视觉数据集,这样您就可以通过加速用例来训练和分析更好的模型。
在以下部分中,我们将演示如何执行以下操作:
-
在 FiftyOne 中可视化数据集
-
在 FiftyOne 中使用过滤和图像重复数据删除功能清理数据集
-
在 FiftyOne 中使用零镜头分类对已清理的数据进行预标记
-
使用 Ground Truth 标记较小的精选数据集
-
将来自 Ground Truth 的带标签结果注入 FiftyOne 中,然后在 FiftyOne
用例概述
假设你拥有一家零售公司,想要开发一个移动应用程序来提供个性化推荐,帮助用户决定穿什么。您的潜在用户正在寻找一款应用程序,该应用程序可以告诉他们壁橱里哪些衣物可以很好地搭配使用。你可以在这里看到机会:如果你能找到好的服装,你可以用它来推荐新的服装,以补充客户已经拥有的服装。
你想让最终用户尽可能轻松地完成工作。理想情况下,使用你的应用程序的人只需要拍下衣柜里的衣服的照片,你的机器学习模型就会在幕后发挥他们的魔力。你可以训练一个通用模型,或者通过某种形式的反馈来根据每个用户的独特风格对模型进行微调。
但是,首先,你需要确定用户捕捉的是哪种服装。是衬衫吗?一条裤子?或者别的什么?毕竟,你可能不想推荐一套有多件连衣裙或多顶帽子的服装。
为了解决这个最初的挑战,你需要生成一个训练数据集,该数据集由具有不同图案和款式的各种服装的图像组成。要在有限的预算下进行原型设计,您需要使用现有数据集进行引导。
为了说明和引导你完成这篇文章中的流程,我们使用了在ICCV 2017上发布的Fashion200K数据集。它是一个成熟且被广泛引用的数据集,但它并不直接适合你的用例。
尽管服装商品标有类别(和子类别),并包含从原始产品描述中提取的各种有用标签,但数据并未系统地标有图案或款式信息。您的目标是将现有数据集转化为服装分类模型的强大训练数据集。您需要清理数据,使用样式标签增强标签架构。而且你希望以尽可能少的支出快速完成这项工作。
在本地下载数据
首先,按照 F
ashion200K 数据集 G
itHub 存储库中提供的说明下载 women.tar 压缩文件和标签文件夹(及其所有子文件夹)。 将它们都解压缩后,创建一个父目录 fashion200k,然后将标签和女士文件夹移到这个目录中。幸运的是,这些图像已经被裁剪到物体检测边界框中,因此我们可以专注于分类,而不必担心物体检测。
尽管名字中有 “200K”,但我们提取的女性名录包含338,339张图片。为了生成官方Fashion200K数据集,该数据集的作者在网上搜寻了超过30万种产品,只有描述中包含超过四个字的商品才入围。出于我们的目的,如果商品描述不是必需的,我们可以使用所有已抓取的图片。
让我们来看看这些数据的组织方式:在女性文件夹中,图片按顶级文章类型(裙子、上衣、裤子、夹克和连衣裙)和文章类型子类别(衬衫、T 恤、长袖上衣)排列。
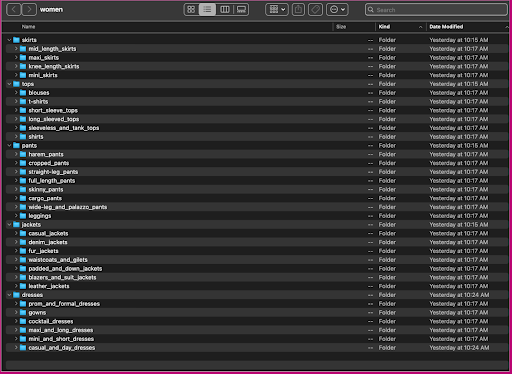
在子类别目录中,每个产品列表都有一个子目录。其中每一个都包含可变数量的图像。例如,cropped_pants 子类别包含以下产品列表和相关图片。
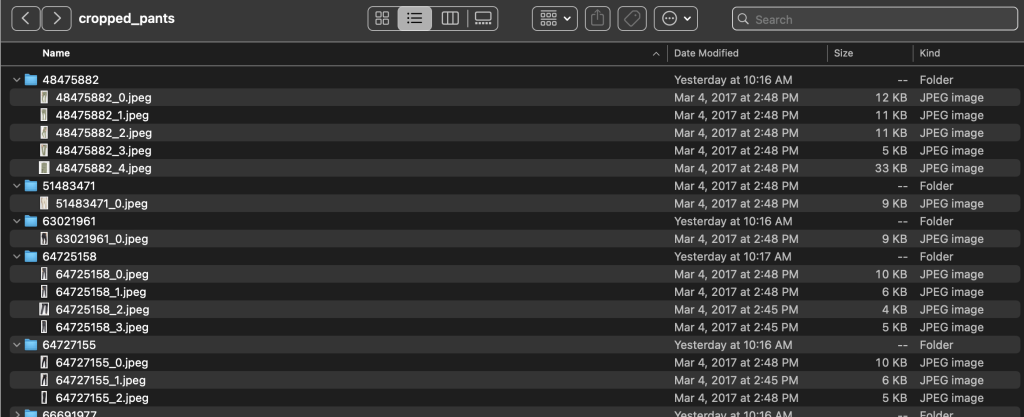
标签文件夹包含每种顶级文章类型的文本文件,用于训练和测试拆分。在每个文本文件中,每张图片都有单独的行,指定产品描述中的相对文件路径、分数和标签。
因为我们正在重新利用数据集,所以我们会合并所有的训练和测试图像。我们使用它们来生成高质量的应用程序特定数据集。完成此过程后,我们可以将生成的数据集随机拆分为新的训练和测试拆分。
在 FiftyOne 中注入、查看和整理数据集
如果你还没有这样做,可以使用 pip 安装开源 FiftyOne:
最佳做法是在新的虚拟(venv 或 conda)环境中执行此操作。然后导入相关模块。导入基础库 fiftyone、具有内置机器学习方法的 FiftyOne Brain、FiftyOne Zoo(我们将从中加载模型为我们生成零镜头标签)和 ViewField(允许我们高效筛选数据集中的数据):
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
from fiftyone import ViewField as F
你还想导入 glob 和 os Python 模块,这将帮助我们处理目录内容的路径和模式匹配:
from glob import glob
import os
现在我们已经准备好将数据集加载到 FiftyOne 中。首先,我们创建一个名为 fashion200k 的数据集并将其永久化,这使我们能够保存计算密集型操作的结果,因此我们只需要计算一次所述数量。
dataset = fo.Dataset("fashion200k", persistent=True)
现在,我们可以遍历所有子类别目录,将所有图像添加到产品目录中。我们在每个样本中添加一个 FiftyOne 分类标签,字段名为 article_type,由图片的顶级文章类别填充。我们还将类别和子类别信息添加为标签:
# Map dir categories to article type labels
labels_map = {
"dresses": "dress",
"jackets": "jacket",
"pants": "pants",
"skirts": "skirt",
"tops": "top",
}
dataset_dir = "./fashion200k"
for d in glob(os.path.join(dataset_dir, "women", "*", "*")):
_, _, category, subcategory = d.split("/")
subcategory = subcategory.replace("_", " ")
label = labels_map[category]
dataset.add_samples(
[
fo.Sample(
filepath=filepath,
tags=[category, subcategory], article_type=fo.Classification(label=label),
)
for filepath in glob(os.path.join(d, "*", "*"))
]
)
此时,我们可以通过启动会话在 FiftyOne 应用程序中可视化我们的数据集:
session = fo.launch_app(dataset)
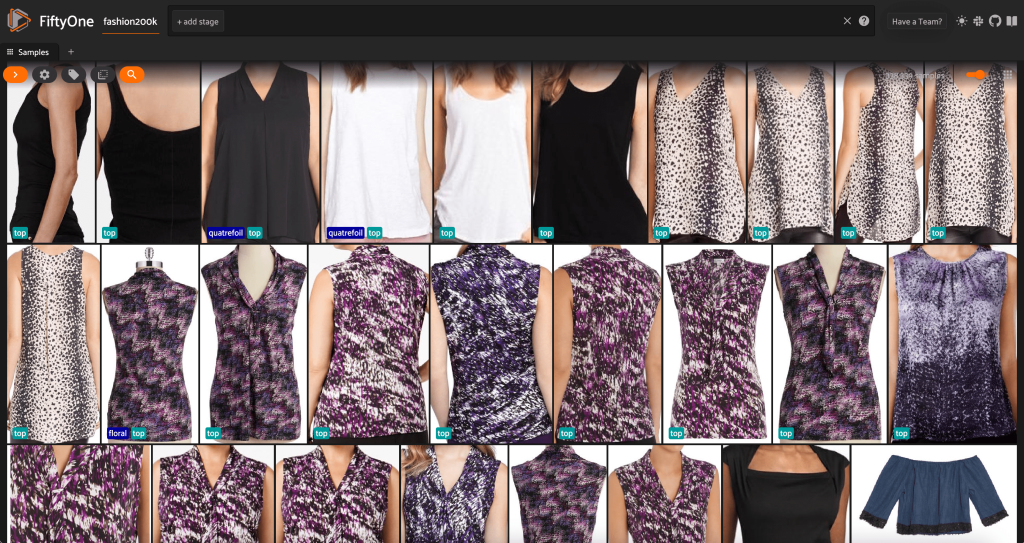
我们还可以通过运行 print
(数据集)在 Python 中 打印出数据集
的摘要 :
Name: fashion200k
Media type: image
Num samples: 338339
Persistent: True
Tags: []
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
article_type: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Classification)
我们还可以将标签 目录中的
标签
添加到数据集中的样本中:
working_dir = os.getcwd()
tags = {
f: set(t)
for f, t in zip(*dataset.values(["filepath", "tags"]))
}
for label_file in glob("fashion200k/labels/*"):
with open(label_file, 'r') as f:
for line in f.readlines():
line_list = line.split()
fp = os.path.join(
working_dir,
dataset_dir,
line_list[0]
)
# add new tags
new_tags_for_fp = line_list[2:]
tags[fp].update(new_tags_for_fp)
# Update tags
dataset.set_values("tags", tags, key_field="filepath")
从数据来看,有几件事变得清晰起来:
-
有些图像相当粗糙,分辨率低。这可能是因为这些图像是通过在物体检测边界框中裁剪初始图像而生成的。
-
有些衣服是人穿的,有些是自己拍的。
这些细节由 viewpoint 属性封装。
-
同一产品的许多图像都非常相似,因此至少在最初阶段,每个产品包含多张图像可能不会增加太大的预测能力。在大多数情况下,每个产品的第一张图片(以
_0.jpeg
结尾 )是最干净的。
最初,我们可能想根据这些图像的受控子集来训练我们的服装风格分类模型。为此,我们使用产品的高分辨率图像,并将查看范围限制为每个产品一个代表性样本。
首先,我们过滤掉低分辨率的图像。我们使用 com
pute_metadata () 方法来计算和存储数据
集中每张图像的图像宽度和高度(以像素为单位)。然后,我们使用 FiftyOne
ViewField
根据允许的最小宽度和高度值筛选出图像。参见以下代码:
dataset.compute_metadata()
min_width = 200
min_height = 300
width_filter = F("metadata.width") > min_width
height_filter = F("metadata.height") > min_height
high_res_view = dataset.match(
width_filter & height_filter
)
session.view = high_res_view.view()
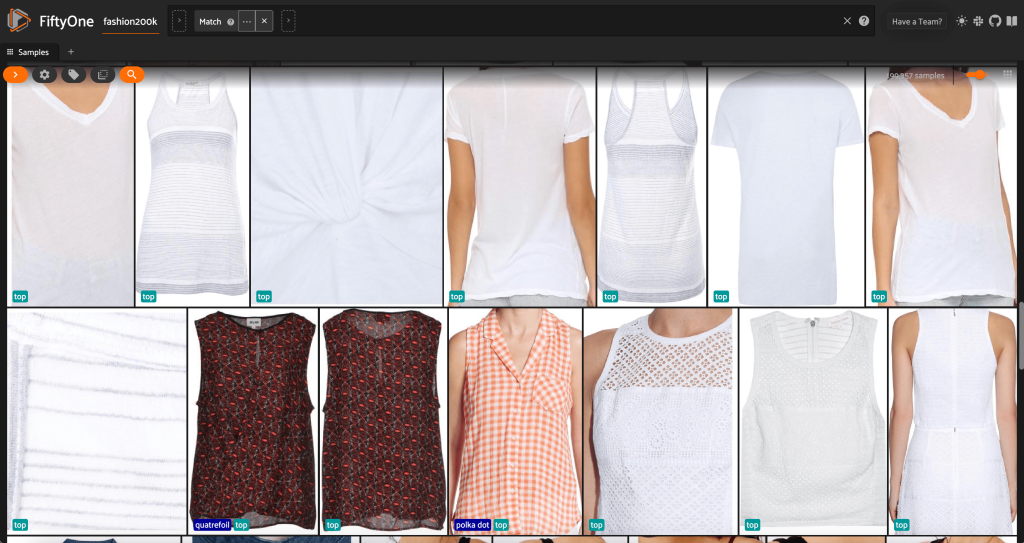
这个高分辨率子集的样本略低于 200,000 个。
从这个视图中,我们可以为数据集创建一个新视图,其中每种产品仅包含一个代表性样本(最多)。我们 再次使用
ViewField
,对以
_0.jpeg
结尾的文件路径进行模式匹配:
representative_view = high_res_view.match(
F("filepath").ends_with("_0.jpeg")
)
让我们来看一下这个子集中图像的随机排序:
session.view = representative_view.shuffle()
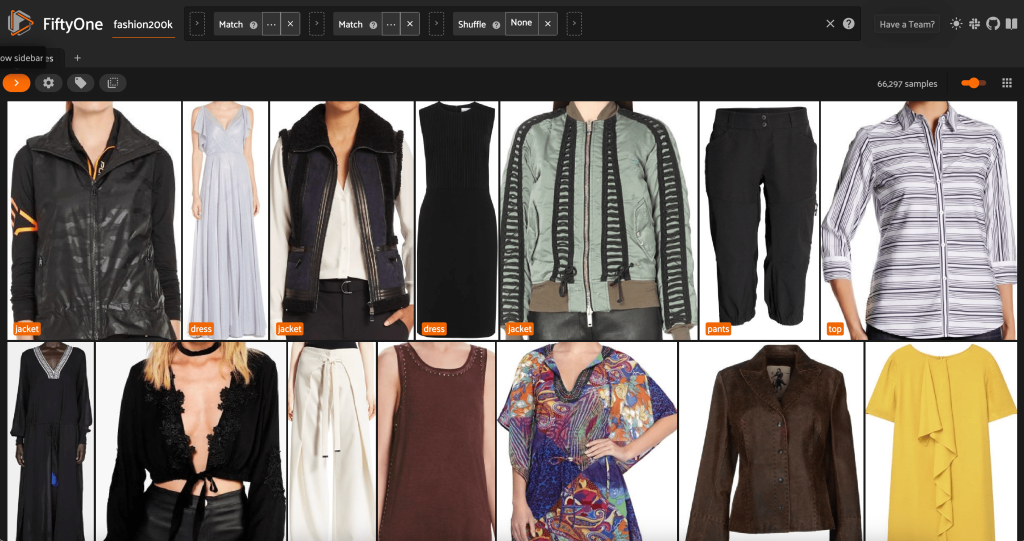
移除数据集中的冗余图像
此视图包含 66,297 张图像,略高于原始数据集的 19%。但是,当我们查看视图时,我们会发现有许多非常相似的产品。保留所有这些副本可能只会增加我们的标签和模型训练成本,而不会显著提高性能。取而代之的是,让我们删除近乎重复的内容,创建一个仍然具有相同冲击力的较小数据集。
由于这些图像并非完全重复,因此我们无法检查像素是否相等。幸运的是,我们可以使用 FiftyOne Brain 来帮助我们清理数据集。特别是,我们将计算每张图像(代表图像的低维向量)的嵌入,然后寻找嵌入向量彼此接近的图像。矢量越近,图像越相似。
我们使用 CLIP 模型为每张图像生成 512 维嵌入向量,并将这些嵌入存储在数据集样本的字段嵌入中:
## load model
model = foz.load_zoo_model("clip-vit-base32-torch")
## compute embeddings
representative_view.compute_embeddings(
model,
embeddings_field="embedding"
)
然后,我们使用
余弦相似度计算嵌入之间的接近度 ,并断言任何两个相似度
大于某个阈值的向量都可能接近重复。余弦相似度分数在 [0, 1] 范围内,从数据来看,阈值分数为阈值=0.5 似乎差不多。再说一遍,这不一定是完美的。一些近乎重复的图像不太可能破坏我们的预测能力,丢掉一些不重复的图像不会对模型性能产生重大影响。
results = fob.compute_similarity(
view,
embeddings="embedding",
brain_key="sim",
metric="cosine"
)
results.find_duplicates(thresh=0.5)
我们可以查看所谓的重复项,以验证它们确实是多余的:
## view the duplicates, paired up,
## to make sure it is doing what we think it is doing
dup_view = results.duplicates_view()
session = fo.launch_app(dup_view)

当我们对结果感到满意并认为这些图像确实接近重复时,我们可以从每组相似样本中选择一个样本进行保存,而忽略其他样本:
## get one image from each group of duplicates
dup_rep_ids = list(results.neighbors_map.keys())
# get ids of non-duplicates
non_dup_ids = representative_view.exclude(
dup_view.values("id")
).values("id")
# ids to keep
ids = dup_rep_ids + non_dup_ids
# create view from ids
non_dup_view = representative_view[ids]
现在这个视图有 3,729 张图像。通过清理数据并识别Fashion200K数据集的高质量子集,FiftyOne允许我们将焦点从超过30万张图像限制到略低于4,000张图像,减少了98%。仅使用嵌入删除近乎重复的图像就使我们考虑的图像总数减少了90%以上,对根据这些数据进行训练的任何模型几乎没有影响。
在预先标记该子集之前,我们可以通过可视化已经计算的嵌入来更好地理解数据。我们可以使用 FiftyOne Brain 内置的 com
pute_visualization ( ) 方法,该方法采用均匀流形近似 (UMAP) 技术将 512 维嵌入向量投影到二维空间中,这样我们就可以将它们可视
化:
fob.compute_visualization(
non_dup_view,
embeddings="embedding",
brain_key="vis"
)
我们在FiftyOne应用程序 中打开一个新的
嵌入面板
,并按文章类型着色,我们可以看到这些嵌入大致编码了文章类型的概念(除其他外!)。
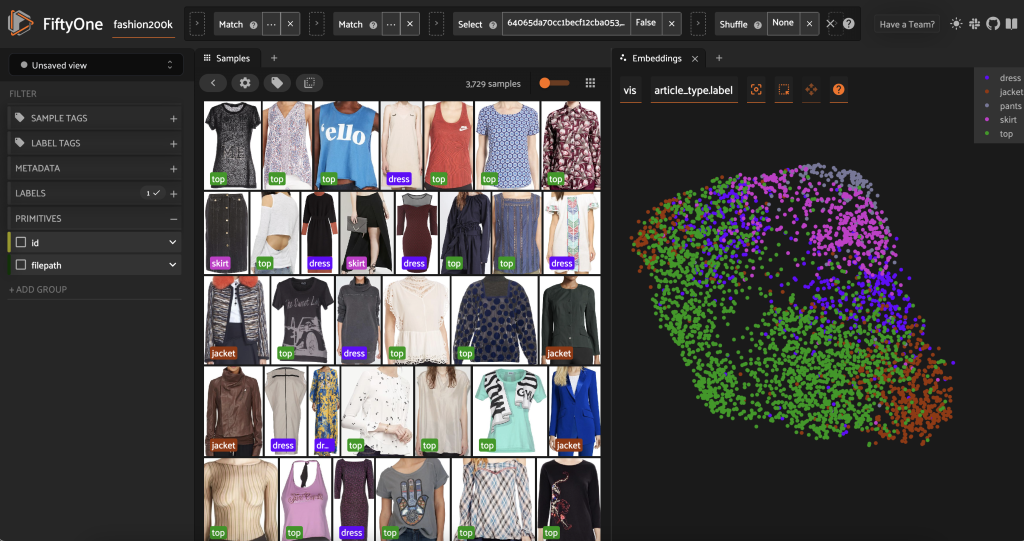
现在我们可以预先标记这些数据。
通过检查这些高度独特、高分辨率的图像,我们可以生成一份不错的初始样式列表,用于预先标记的零镜头分类中,用作类别。我们为这些图片预先贴标签的目标不一定是正确标记每张图片。相反,我们的目标是为人工注释者提供一个良好的起点,这样我们就可以减少标签时间和成本。
styles = [
"graphic",
"lettered",
"plain",
"striped",
"polka dot",
"floral",
"jersey",
"checkered",
"denim",
"plaid",
"houndstooth",
"chevron",
"paisley",
"animal print",
"quatrefoil",
“camouflage”
]
然后,我们可以为该应用程序实例化一个零样本分类模型。我们使用 CLIP 模型,这是一种在图像和自然语言上训练的通用模型。我们使用文本提示 “样式中的服装” 来实例化一个 CLIP 模型,这样模型就会输出最适合 “风格的服装 [class]” 的类。CLIP 没有接受过零售或时尚特定数据的培训,因此这并不完美,但它可以为您节省标签和注释成本。
zero_shot_model = foz.load_zoo_model(
"clip-vit-base32-torch",
text_prompt="Clothing in the style ",
classes=styles,
)
然后,我们将此模型应用于我们的简化子集,并将结果存储在 article
_style 字段
中:
non_dup_view.apply_model(
zero_shot_model,
label_field="article_style"
)
再次启动 FiftyOne 应用程序,我们可以使用这些预测的样式标签对图像进行可视化。我们按预测置信度排序,因此我们首先查看最自信的风格预测:
high_conf_view = non_dup_view.sort_by(
"article_style.confidence", reverse=True
)
session.view = high_conf_view
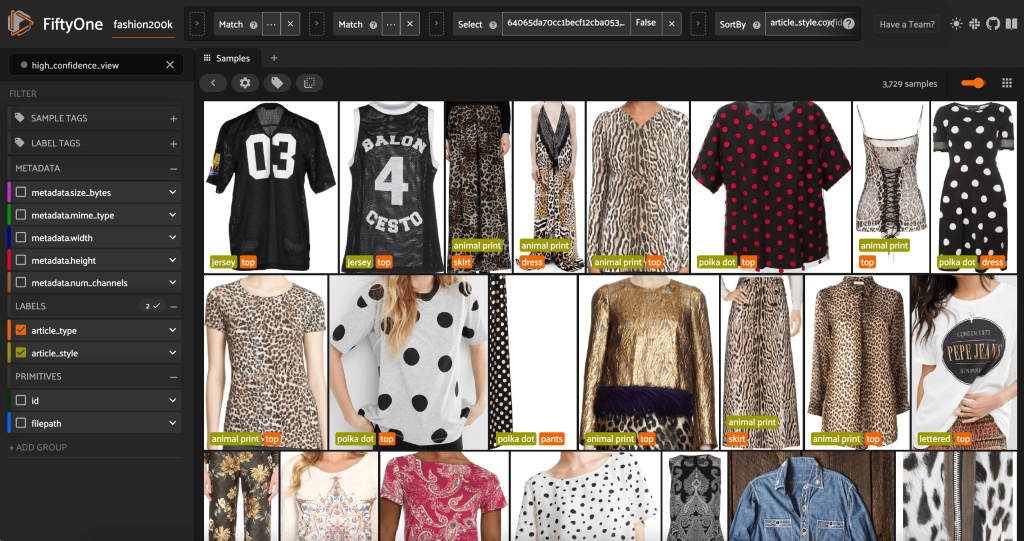
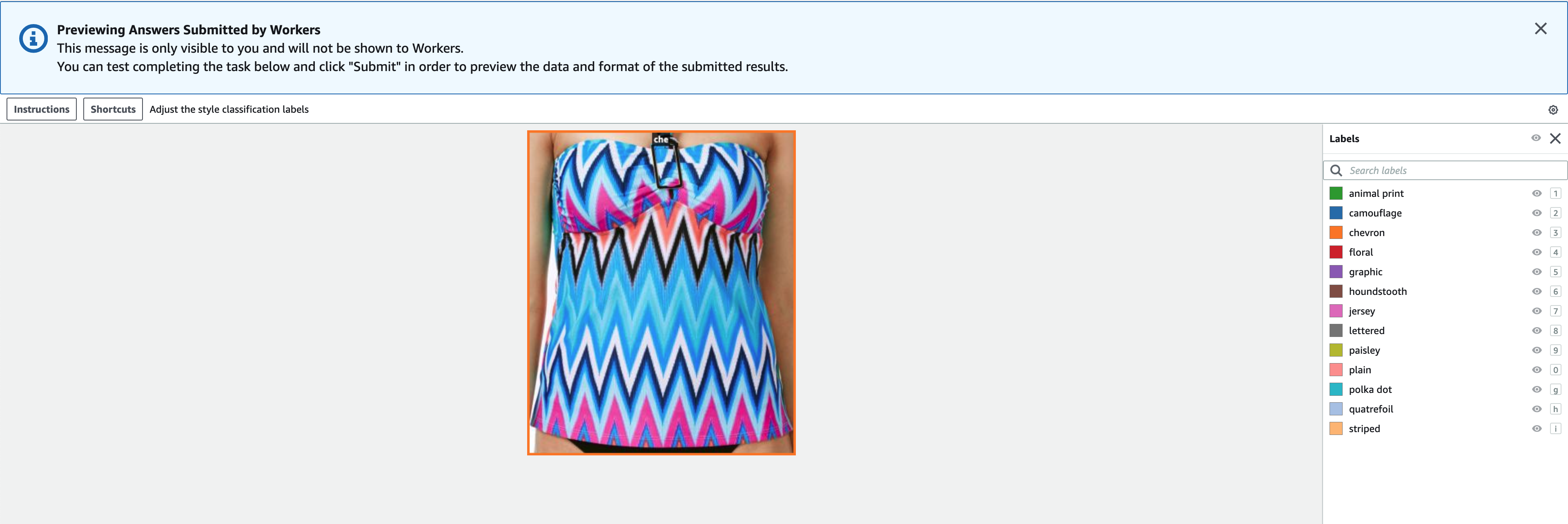
我们可以看到,最高的置信度预测似乎是 “球衣”、“动物印花”、“圆点” 和 “字母” 款式。这是有道理的,因为这些风格相对不同。在大多数情况下,预测的样式标签似乎也是准确的。
我们还可以看看最低置信度风格的预测:
low_conf_view = non_dup_view.sort_by(
"article_style.confidence"
)
session.view = low_conf_view
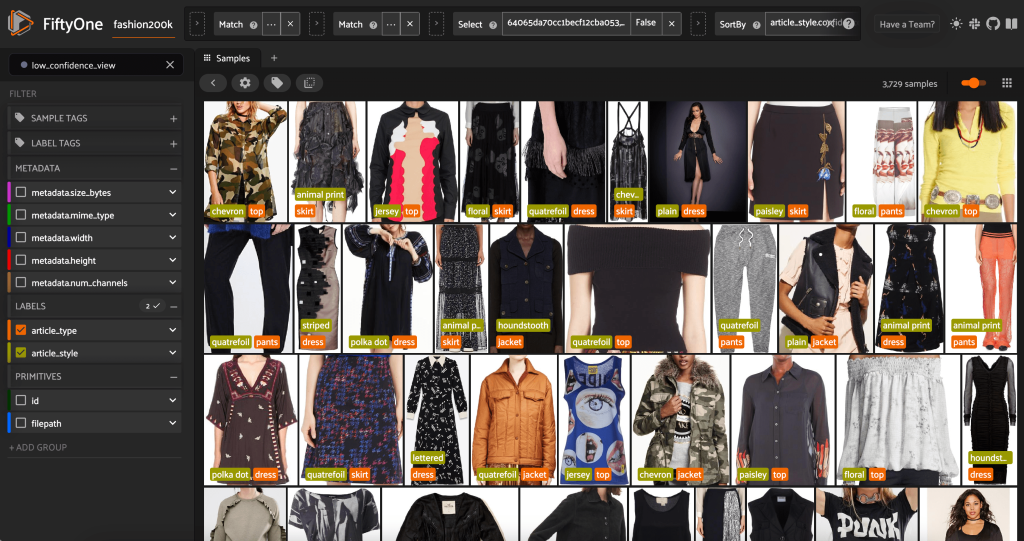
对于其中一些图片,相应的款式类别位于提供的列表中,而服装的标签不正确。例如,网格中的第一张图像显然应该是 “伪装” 而不是 “V 形”。但是,在其他情况下,这些产品并不完全符合样式类别。例如,第二行第二张图片中的连衣裙并不完全是 “条纹”,但如果标签选项相同,人工注释者也可能遇到了冲突。在构建数据集时,我们需要决定是删除这样的边缘案例、添加新的样式类别还是增强数据集。
从 FiftyOne 导出最终数据集
使用以下代码导出最终数据集:
# The directory to which to write the exported dataset
export_dir = "200kFashionDatasetExportResult"
# The name of the sample field containing the label that you wish to export
# Used when exporting labeled datasets (e.g., classification or detection)
label_field = "article_style" # for example
# The type of dataset to export
# Any subclass of `fiftyone.types.Dataset` is supported
dataset_type = fo.types.COCODetectionDataset # for example
# Export the dataset
high_conf_view.export(
export_dir=export_dir,
dataset_type=dataset_type,
label_field=label_field,
)
我们可以将较小的数据集(例如 16 张图片)导出到
200k
FashiondatasetExportResult-16Images 文件夹。我们使用它创建了一个 Ground Truth 调整任务:
# The directory to which to write the exported dataset
export_dir = "200kFashionDatasetExportResult-16Images"
# The name of the sample field containing the label that you wish to export
# Used when exporting labeled datasets (e.g., classification or detection)
label_field = "article_style" # for example
# The type of dataset to export
# Any subclass of `fiftyone.types.Dataset` is supported
dataset_type = fo.types.COCODetectionDataset # for example
# Export the dataset
high_conf_view.take(16).export(
export_dir=export_dir,
dataset_type=dataset_type,
label_field=label_field,
)
上传修改后的数据集,将标签格式转换为 Ground Truth,上传到 Amazon S3,然后为调整任务创建清单文件
我们可以转换数据集中的标签以匹配 Ground Truth 边界框作业 的
输出清单架构
,并将图像上传到
Amazon Simple Storage Service (Amazon S3) 存储
桶以启动
基本真相调整任务
:
import json
# open the labels.json file of ground truth bounding box
#labels from the exported dataset
f = open('200kFashionDatasetExportResult-16Images/labels.json')
data = json.load(f)
# provide your aws s3 bucket name, prefix, and aws credentials
bucket_name = 'sagemaker-your-preferred-s3-bucket'
s3_prefix = 'sagemaker-your-preferred-s3-prefix'
session = boto3.Session(
aws_access_key_id='<AWS_ACCESS_KEY_ID>',
aws_secret_access_key='<AWS_SECRET_ACCESS_KEY>'
)
s3 = session.resource('s3')
for image in data['images']:
file_name = image['file_name']
file_id = file_name[:-4]
image_id = image['id']
# upload the image to s3
s3.meta.client.upload_file('200kFashionDatasetExportResult-16Images/data/'+image['file_name'], bucket_name, s3_prefix+'/'+image['file_name'])
gt_annotations = []
confidence = 0.00
for annotation in data['annotations']:
if annotation['image_id'] == image['id']:
confidence = annotation['score']
gt_annotation = {
"class_id": gt_class_array.index(style_category),
# convert the original ground_truth bounding box
#label to predicted style label
"left": annotation['bbox'][0],
"top": annotation['bbox'][1],
"width": annotation['bbox'][2],
"height": annotation['bbox'][3]
}
gt_annotations.append(gt_annotation)
break
gt_metadata_objects = []
for gt_annotation in gt_annotations:
gt_metadata_objects.append({
"confidence": confidence
})
gt_label_attribute_metadata = {
"class-map": gt_class_map,
"objects": gt_metadata_objects,
"type": "groundtruth/object-detection",
"human-annotated": "yes",
"creation-date": "2023-02-19T00:23:25.339582",
"job-name": "labeling-job/200k-fashion-origin"
}
gt_output = {
"source-ref": f"s3://{bucket_name}/{s3_prefix}/{image['file_name']}",
"200k-fashion-origin": {
"image_size": [
{
"width": image['width'],
"height": image['height'],
"depth": 3
}
],
"annotations": gt_annotations
},
"200k-fashion-origin-metadata": gt_label_attribute_metadata
}
# write to the manifest file
with open(200k-fashion-output.manifest', 'a') as output_file:
output_file.write(json.dumps(gt_output) + "\n")
使用以下代码将清单文件上传到 Amazon S3:
s3.meta.client.upload_file(200k-fashion-output.manifest', bucket_name, s3_prefix+'/200k-fashion-output.manifest')
使用 Ground Truth 创建经过更正的样式标签
要使用 Ground Truth 使用样式标签为数据添加注释,请按照《Gro
und Truth 入门 》指南中概述的步骤,将数据集放在同一 S3 存储桶中,完成启动
边界框标签作业的必要步骤。
-
在 SageMaker 控制台上,创建 Ground Truth 标注作业。
-
将
输入数据集的位置
设置 为我们在前面的步骤中创建的清单。
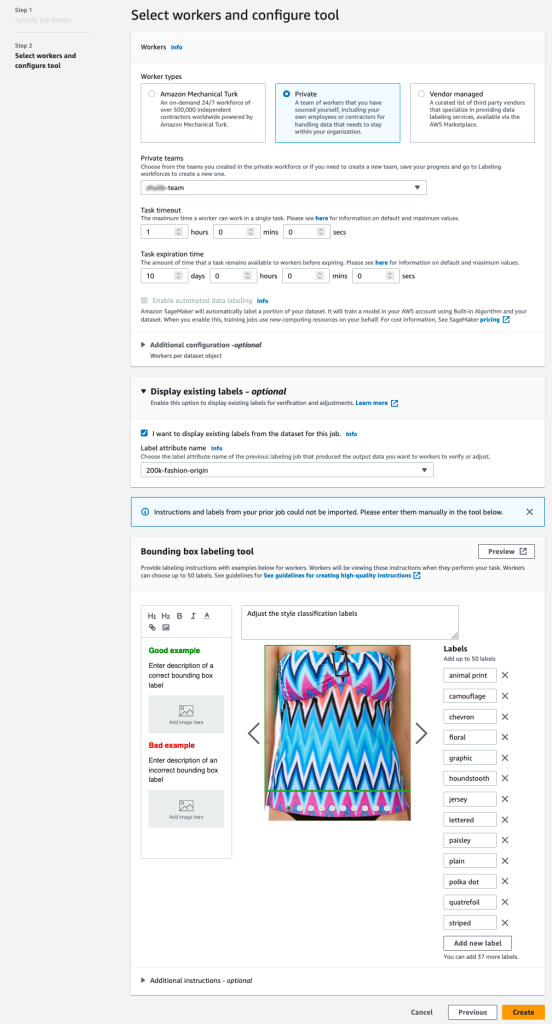
-
为
输出数据集的位置
指定 S3 路径 。
-
对于
IAM 角色
,选择
输入自定义 IAM 角色
ARN
,然后输入角色 ARN。
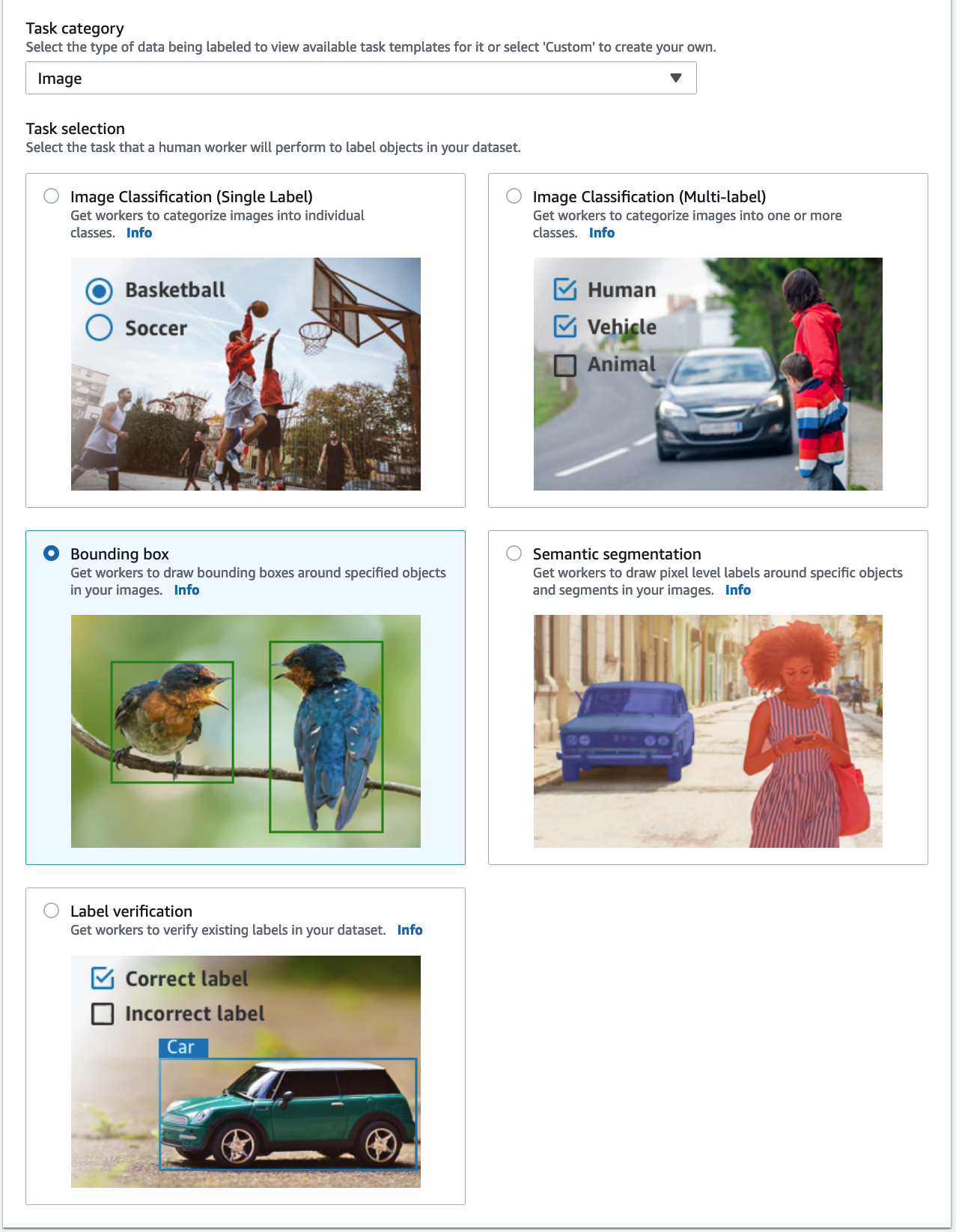
-
对于 “
任务” 类别
,选择 “
图像
”, 然后选择 “
边界框
”。
-
选择 “
下一步
” 。
-
在 “
员工
” 部分中,选择您想要使用的员工队伍类型。
您可以通过
Amazon Mechanical Turk
、第三方供应商或您自己的私人员工队伍来选择员工。有关您的员工队伍选项的更多详细信息,请参阅
创建和管理员工
。
-
展开
现有标签显示选项
, 然后选择
我想要显示此作业数据集中的现有标签。
-
对于
标签属性
名称,请从清单中选择与要显示以进行调整的标签相对应的名称。
您只能看到与您在前面步骤中选择的任务类型相匹配的标签的标签属性名称。
-
手动输入边
界框标签工具 的标签
。
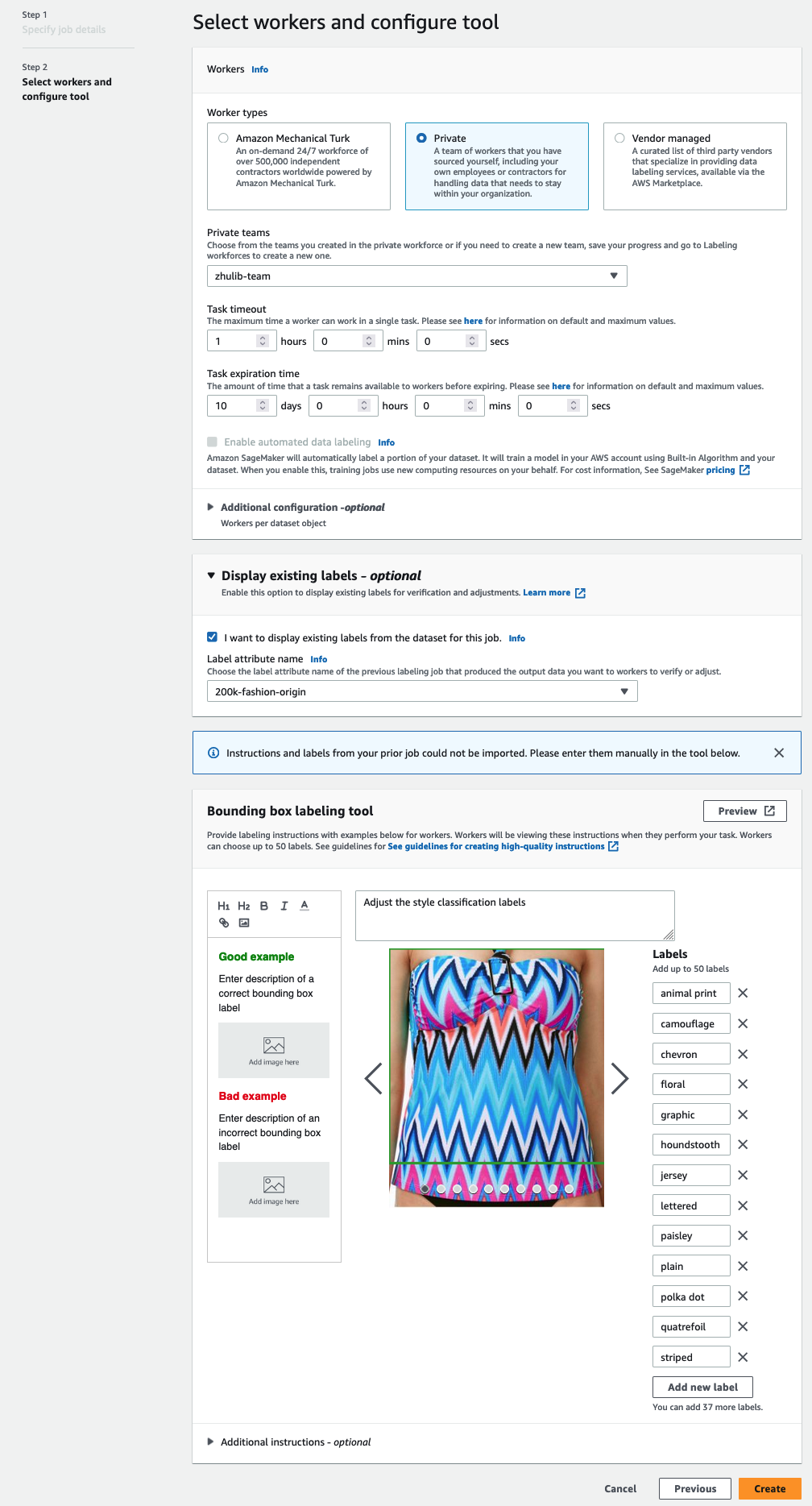 标签必须包含在公共数据集中使用的相同标签。您可以添加新标签。以下屏幕截图显示了如何为标注作业选择工作人员和配置工具。
标签必须包含在公共数据集中使用的相同标签。您可以添加新标签。以下屏幕截图显示了如何为标注作业选择工作人员和配置工具。
-
选择 “
预览
” 可预览图像和原始批注。
现在,我们已经在 Ground Truth 中创建了一个标签任务。工作完成后,我们可以将新生成的带标签数据加载到 FiftyOne 中。Ground Truth 在 Ground Truth 输出清单中生成输出数据。有关输出清单文件的更多详细信息,请参阅
Bounding Box 任务输出
。以下代码显示了这种输出清单格式的示例:
{
"source-ref": "s3://AWSDOC-EXAMPLE-BUCKET/example_image.png",
"bounding-box-attribute-name":
{
"image_size": [{ "width": 500, "height": 400, "depth":3}],
"annotations":
[
{"class_id": 0, "left": 111, "top": 134,
"width": 61, "height": 128},
{"class_id": 5, "left": 161, "top": 250,
"width": 30, "height": 30},
{"class_id": 5, "left": 20, "top": 20,
"width": 30, "height": 30}
]
},
"bounding-box-attribute-name-metadata":
{
"objects":
[
{"confidence": 0.8},
{"confidence": 0.9},
{"confidence": 0.9}
],
"class-map":
{
"0": "jersey",
"5": "polka dot"
},
"type": "groundtruth/object-detection",
"human-annotated": "yes",
"creation-date": "2018-10-18T22:18:13.527256",
"job-name": "identify-fashion-set"
},
"adjusted-bounding-box":
{
"image_size": [{ "width": 500, "height": 400, "depth":3}],
"annotations":
[
{"class_id": 0, "left": 110, "top": 135,
"width": 61, "height": 128},
{"class_id": 5, "left": 161, "top": 250,
"width": 30, "height": 30},
{"class_id": 5, "left": 10, "top": 10,
"width": 30, "height": 30}
]
},
"adjusted-bounding-box-metadata":
{
"objects":
[
{"confidence": 0.8},
{"confidence": 0.9},
{"confidence": 0.9}
],
"class-map":
{
"0": "dog",
"5": "bone"
},
"type": "groundtruth/object-detection",
"human-annotated": "yes",
"creation-date": "2018-11-20T22:18:13.527256",
"job-name": "adjust-identify-fashion-set",
"adjustment-status": "adjusted"
}
}
查看 FiftyOne 中来自 Ground Truth
任务完成后,从 Amazon S3 下载标签任务的输出清单。
读取输出清单文件:
with open('<path-to-your-output.manifest>', 'r') as fh:
adjustment_manifest_lines = fh.readlines()
创建 FiftyOne 数据集并将清单行转换为数据集中的样本:
def get_classification_labels(manifest_line, dataset, attr_name) -> fo.Classifications:
label_attribute_data = manifest_line.get(attr_name)
metadata = manifest_line.get(f"{attr_name}-metadata")
annotations = label_attribute_data.get("annotations")
image_data = label_attribute_data.get("image_size")[0]
width = image_data.get("width")
height = image_data.get("height")
predictions = []
for i, annotation in enumerate(annotations):
label = metadata.get("class-map").get(str(annotation.get("class_id")))
confidence = metadata.get("objects")[i].get("confidence")
prediction = fo.Classification(label=label, confidence=confidence)
predictions.append(prediction)
return fo.Classifications(classifications=predictions)
def get_bounding_box_labels(manifest_line, dataset, attr_name) -> fo.Detections:
label_attribute_data = manifest_line.get(attr_name)
metadata = manifest_line.get(f"{attr_name}-metadata")
annotations = label_attribute_data.get("annotations")
image_data = label_attribute_data.get("image_size")[0]
width = image_data.get("width")
height = image_data.get("height")
detections = []
for i, annotation in enumerate(annotations):
label = metadata.get("class-map").get(str(annotation.get("class_id")))
confidence = metadata.get("objects")[i].get("confidence")
# Bounding box coordinates should be relative values
# in [0, 1] in the following format:
# [top-left-x, top-left-y, width, height]
bounding_box = [
annotation.get("left") / width,
annotation.get("top") / height,
annotation.get("width") / width,
annotation.get("height") / height,
]
detection = fo.Detection(
label=label, bounding_box=bounding_box, confidence=confidence
)
detections.append(detection)
return fo.Detections(detections=detections)
def get_sample_from_manifest_line(manifest_line, dataset, attr_name):
"""
For each line in manifest, transform annotations into Fiftyone format
Args:
line: manifest line
Output:
Fiftyone image sample
"""
file_name = manifest_line.get("source-ref")[5:].split("/")[-1]
file_loc = f'200kFashionDatasetExportResult-16Images/data/{file_name}'
sample = fo.Sample(filepath=file_loc)
sample['ground_truth'] = get_bounding_box_labels(
manifest_line=manifest_line, dataset=dataset, attr_name=attr_name
)
sample["prediction"] = get_classification_labels(
manifest_line=manifest_line, dataset=dataset, attr_name=attr_name
)
return sample
adjustment_dataset = fo.Dataset("adjustment-job-dataset")
samples = [
get_sample_from_manifest_line(
manifest_line=json.loads(manifest_line), dataset=adjustment_dataset, attr_name='smgt-fiftyone-style-adjustment-job'
)
for manifest_line in adjustment_manifest_lines
]
adjustment_dataset.add_samples(samples)
session = fo.launch_app(adjustment_dataset)
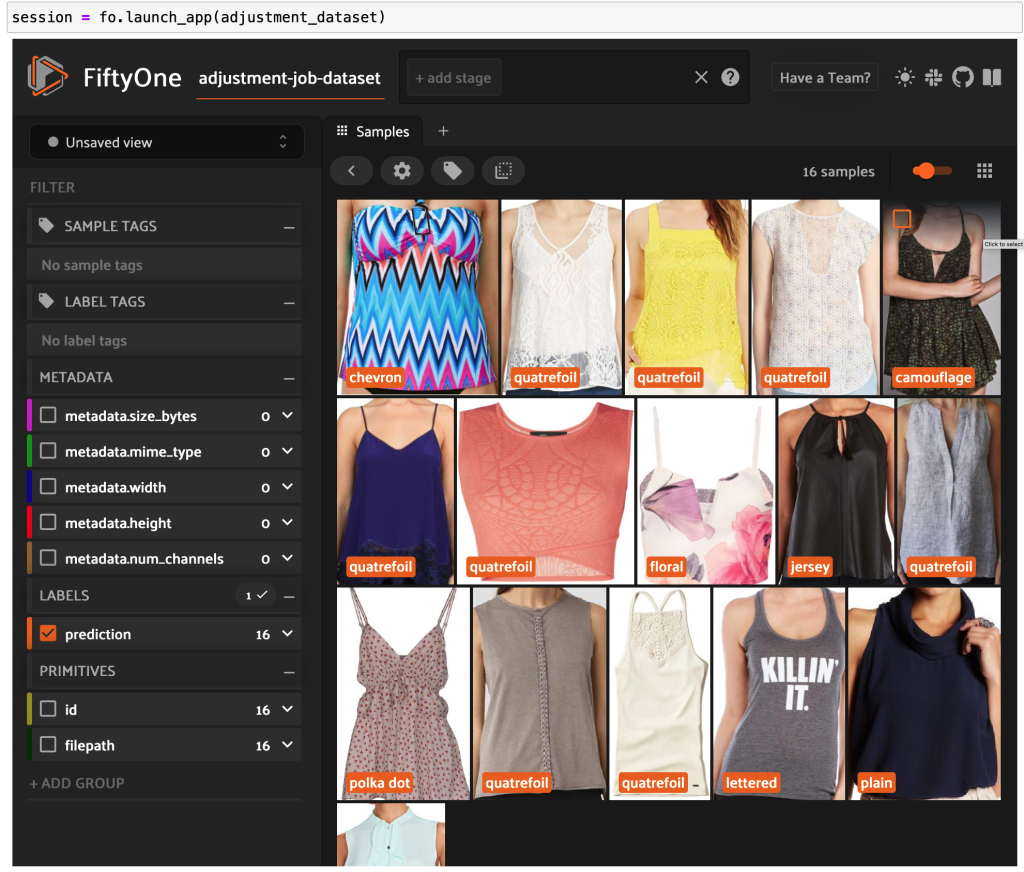
现在,你可以在 FiftyOne 中看到来自 Ground Truth 的高质量标签数据。
结论
在这篇文章中,我们展示了如何将 Fi
ftyOne by
Voxel51
(一种
允许您管理 、跟踪、可视化和整理数据集的开源工具包)和 Ground Truth(一种数据标签服务,通过提供对多个内置任务模板的访问权限,以及通过 Mechanical Turk、第三方供应商或您自己的私人员工访问多元化工作人员)的强大功能,来构建高质量的数据集。
我们鼓励你通过安装 FiftyOne 实例并使用 Ground Truth 控制台来试用这项新功能。要了解有关 Ground Truth 的更多信息,请参阅
标签数据
、
Amazon SageMaker 数据标签
常见问题和
亚马逊云科技
机器学习博客。
如果您有任何问题或反馈,请联系
机器学习和人工智能社区
!
加入 FiftyOne 社区!
加入成千上万的工程师和数据科学家的行列,他们已经在使用FiftyOne来解决当今计算机视觉中一些最具挑战性的问题!
-
每月活跃用户超过 20 万
-
1,400 多名 FiftyOne Slack 会
员
-
GitHub 上有 2700 多颗星
-
3,400 多 名聚会会员
作者简介
沙伦德拉·查布拉
目前 是亚马逊 SageMaker Human-in-the-Loop (HIL) 服务的产品管理主管。此前,沙伦德拉曾孵化并领导微软团队会议的语言和对话情报,曾在亚马逊Alexa Techstars创业加速器担任EIR、Discus
s.i
o的产品和营销副总裁、剪贴板产品和营销主管(被Salesforce收购)以及Swype(被Nuance收购)的首席产品经理。总的来说,Shalendra帮助制造、运送和销售影响了十亿多人生活的产品。
雅各布·马克斯
是Voxel51的机器学习工程师和开发者推广员,他在那里帮助提高世界数据的透明度和清晰度。在加入Voxel51之前,雅各布创立了一家初创公司,帮助新兴音乐家与粉丝建立联系并分享创意内容。在此之前,他曾在谷歌 X、三星研究院和 Wolfram Research 工作。在前世中,雅各布是一名理论物理学家,在斯坦福大学完成了博士学位,在那里他研究了物质的量子相。在业余时间,雅各布喜欢攀岩、跑步和阅读科幻小说。
杰森·科索
(Jason Corso) 是Voxel51的联合创始人兼首席执行官,他指导战略,通过最先进的灵活软件帮助世界数据提高透明度和清晰度。他还是密歇根大学机器人、电气工程和计算机科学教授,主要研究计算机视觉、自然语言和物理平台交叉点的尖端问题。在空闲时间,杰森喜欢与家人共度时光,阅读,置身于大自然中,玩棋盘游戏以及各种创意活动。
布莱恩·摩尔
是Voxel51的联合创始人兼首席技术官,负责领导技术战略和愿景。他拥有密歇根大学电气工程博士学位,他的研究重点是解决大规模机器学习问题的高效算法,特别侧重于计算机视觉应用。在业余时间,他喜欢打羽毛球、打高尔夫球、徒步旅行以及和他的双胞胎约克夏犬一起玩。
白竹玲
是亚马逊网络服务的软件开发工程师。她致力于开发大规模分布式系统来解决机器学习问题。