我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
高效地为 Amazon DynamoDB 表生成一组不同的分区键
在某些情况下,你可能需要一个不同的分区键列表:
- 分区键是客户 ID,您需要表中包含所有客户的列表。当然,它不一定是客户。它可能是设备、购物车、游戏或表格中任何实体类型的 ID。
- 您正在推出一项新功能,并希望在每个项目集合中插入一个新项目(项目集合是一组具有相同分区键但排序键值不同的项目)。您需要知道分区键才能插入新项目。
扫描整张桌子
如果你的表架构只有一个分区键(没有排序键),那么使用表扫描可以相当高效地生成不同的分区键列表。扫描返回的每件商品都将具有唯一的分区键值。没有不必要地阅读任何项目。
以下代码显示如何使用
pk
的分区键属性 。如果您的分区键属性名称不同,则只需要调整示例代码以匹配您的表架构。
此命令会扫描
SampleT
able 表并仅为每个项目选择
pk
属性。然后,它将分区键输出为以空格分隔的列表,该列表通过
tr
命令通过管道传送以将制表符转换为换行符。然后使用排序命令对列表进行排
序
和去重。
如果你的表架构包含排序键,同样的扫描方法也会起作用,但是随着平均项目集合大小的增加,它的效率会降低。如果物品集合中平均有一千件物品,那么在看到下一个不同的分区键之前,你需要扫描999件额外的物品。想象一下,如上所述,你有 200 万个不同的分区键,但每个分区键的项目集合中有 1,000 个项目。现在,该表将为 1 TB,要使用扫描提取 200 万个不同的值,则需要 125,000,000 个读取请求单元。这要高 1000 倍的成本,而且按比例来说也要慢一些。它也更有可能创建滚动热分区,因为在跳转到下一个分区之前,扫描一次会从一个分区读取大量数据。
使用全局二级索引
提高这种效率的一种方法是创建全局二级索引 (GSI)。在每个项目集合中,您可以插入一个特殊项目,该项目的 GSI 分区键等于基表上的分区键。这会将这些物品(仅限那些物品)传播到 GSI 中。扫描此 GSI 非常高效,因为 GSI 的每个基表分区键值仅保存一个项目。另外一个优势是,GSI 中的平均物品大小将小于基表中的平均物品大小,因为 GSI 可以投影
KEYS_ON
LY 并避免持有任何非键属性。如果 GSI 项目的平均大小为 150 字节,则保存 200 万个不同分区键值的 GSI 将只有 300 MB,而全面扫描仅需要 37,500 个读取请求单元。缺点是你需要管理放入每个物品集合中的特殊物品的生命周期,才能将其投射到GSI中。
图 1 显示了跟踪两台设备数据的表,这两台设备有 ID 和分区键
1
和
2
。它们各有一个
#static
元素,用于保存有关该设备的静态元数据,其分区键值以
Gsi
-pk 的形式存入其中。
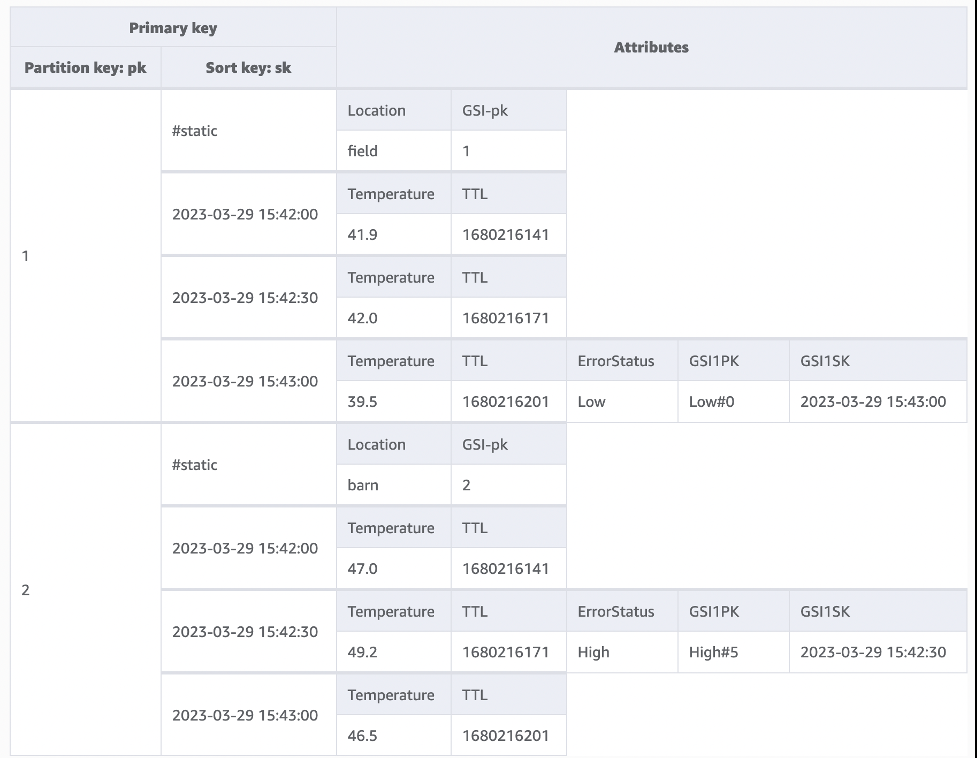
图 1:包含两个项目集合和许多项目的基表
图 2 显示了根据该
基表构建的 Gsi-PK
索引。可以对其进行扫描以高效地提取分区键值。GSI 分区键具有高基数,可确保均匀的写入分布且没有热分区。
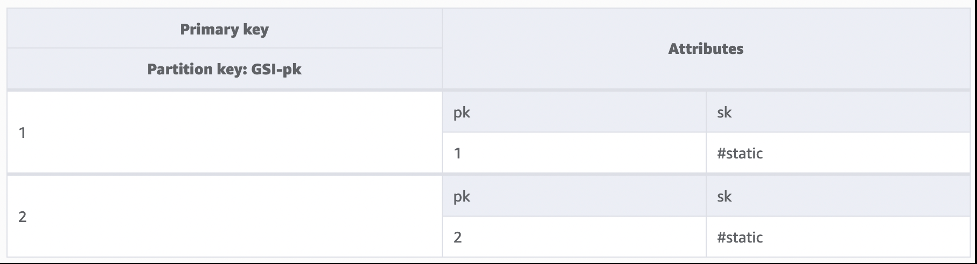
图 2:一个 GSI 只包含两个项目,每个分区键值对应一个
使用修改后的专属启动密钥进行扫描
如果生成一组不同的分区键是你不经常运行的访问模式,或者你需要在没有事先预料到这一要求的情况下运行,那么有一种创造性的方法可以最大限度地减少实际读取的数据量,通过对
LasteValuatedKey
值通常被视为不透明值,但它实际上是一个包含分区键和排序键的映射结构。例如,
LasteValuatedKey 的值可能是
:
可以在扫描期间操作排序键以跳过可能的最大排序键值,从而确保下一次读取从下一个项目集合开始。
步骤如下:
-
使用
扫描操作从表中检索单个项目,限制为 1。 -
如果响应包含这将 从上一个项目收集完毕后立即继续扫LasteValuatedKey,请修改该密钥以使其具有该分区键的最大可能排序键值,并在下次扫描操作中将其用作 ExclusiveStartKey。描,因此下一次扫描操作应返回一个新的唯一分区键值。 -
重复步骤 1 和 2,直到响应中不包含
LasteValuatedKey。这表示桌子的结尾。 - 从响应中提取分区键。
此解决方案的成本是读取每个项目集合的所有第一项所需的读取请求单位总数。如果项目大小不超过 4 KB,则将是不同分区键数量的 0.5 倍。以我们包含 200 万个项目的示例为例,这将消耗 1,000,000 个读取请求单元。这比优化后的 GSI 效率低(因为 GSI 可以在每次请求时返回许多物品),但比全表扫描效率要高得多(因为不会有大量物品被提取到浪费的物品中)。当平均项目集合大小超过 4 KB 时,这种方法将降低成本。这种方法具有特殊的优势,它不需要特殊的预先设置或持续的维护。
以下部分介绍如何在 Python、Node.js 和 Java 中实现这种方法。这些示例的完整源代码以及一些加载示例数据进行测试的测试脚本可在
请注意,这些示例执行串行扫描。如果您喜欢挑战并希望在大型桌子上获得最佳性能,则可以将其转换为使用并行扫描。
巨蛇
对于 Python,请使用以下代码:
import argparse
import boto3
import decimal
import time
import boto3.dynamodb.types
from botocore.exceptions import ClientError
MAX_SORT_KEY_VALUE_S = str(256 * chr(0x10FFFF))
MAX_SORT_KEY_VALUE_N = decimal.Decimal('9.9999999999999999999999999999999999999E+125')
MAX_SORT_KEY_VALUE_B = boto3.dynamodb.types.Binary(b'\xFF' * 1024)
def print_distinct_pks(region, table_name):
dynamodb = boto3.resource('dynamodb', region_name=region)
table = dynamodb.Table(table_name)
partition_key_name = table.key_schema[0]['AttributeName']
sort_key_name = table.key_schema[1]['AttributeName']
sort_key_type = table.attribute_definitions[1]['AttributeType']
# Determine the maximum value of the sort key based on its type
max_sort_key_value = ''
if sort_key_type == 'S':
max_sort_key_value = MAX_SORT_KEY_VALUE_S
elif sort_key_type == 'N':
max_sort_key_value = MAX_SORT_KEY_VALUE_N
elif sort_key_type == 'B':
max_sort_key_value = MAX_SORT_KEY_VALUE_B
else:
raise ValueError(f"Unsupported sort key type: {sort_key_type}")
last_evaluated_key = None
while True:
try:
scan_params = {
'TableName': table_name,
'Limit': 1,
'ProjectionExpression': 'pk',
}
if last_evaluated_key:
scan_params['ExclusiveStartKey'] = last_evaluated_key
response = table.scan(**scan_params)
items = response['Items']
if len(items) > 0:
print(items[0]['pk'])
if 'LastEvaluatedKey' not in response:
break
last_key = response['LastEvaluatedKey']
partition_key_value = last_key[partition_key_name]
sort_key_value = last_key[sort_key_name]
# Create a new key with the maximum value of the sort key
new_key = {
partition_key_name: partition_key_value,
sort_key_name: max_sort_key_value
}
last_evaluated_key = new_key
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'InternalServerError' or error_code == 'ThrottlingException':
print(f"Received an error: {error_code}, retrying...")
time.sleep(1)
else:
raise
if __name__ == '__main__':
# Define CLI arguments
parser = argparse.ArgumentParser()
parser.add_argument('--region', required=True, help='AWS Region')
parser.add_argument('--table-name', required=True, help='Name of the DynamoDB table')
args = parser.parse_args()
# Call the function with the specified table name
print_distinct_pks(args.region, args.table_name)
Node.js
对于 Node.js,请使用以下代码:
const { DynamoDBClient, ScanCommand, DescribeTableCommand } = require('@aws-sdk/client-dynamodb');
const { program } = require('commander');
async function printDistinctPKs(region, tableName) {
const dynamoDb = new DynamoDBClient({ region : region });
const describeTableCommand = new DescribeTableCommand({ TableName: tableName });
const table = await dynamoDb.send(describeTableCommand);
const partitionKeyName = table.Table.KeySchema[0].AttributeName;
const sortKeyName = table.Table.KeySchema[1].AttributeName;
const sortKeyType = table.Table.AttributeDefinitions.find(attr => attr.AttributeName === sortKeyName).AttributeType;
const MAX_SORT_KEY_VALUE_S = String.fromCharCode(0x10FFFF).repeat(256);
const MAX_SORT_KEY_VALUE_N = '9.9999999999999999999999999999999999999E+125';
const MAX_SORT_KEY_VALUE_B = Buffer.alloc(1024, 0xFF);
let maxSortKeyValue = '';
// Determine the maximum value of the sort key based on its type
if (sortKeyType === 'S') {
maxSortKeyValue = MAX_SORT_KEY_VALUE_S;
} else if (sortKeyType === 'N') {
maxSortKeyValue = MAX_SORT_KEY_VALUE_N;
} else if (sortKeyType === 'B') {
maxSortKeyValue = MAX_SORT_KEY_VALUE_B;
} else {
throw new Error(`Unsupported sort key type: ${sortKeyType}`);
}
let lastEvaluatedKey = null;
while (true) {
try {
const scanParams = {
TableName: tableName,
Limit: 1,
ExclusiveStartKey: lastEvaluatedKey,
ProjectionExpression: 'pk',
};
const scanCommand = new ScanCommand(scanParams);
const response = await dynamoDb.send(scanCommand);
const items = response.Items;
if (items && items.length > 0) {
console.log(items[0].pk.S);
}
lastEvaluatedKey = response.LastEvaluatedKey;
if (!lastEvaluatedKey) {
break;
}
// Create a new key with the maximum value of the sort key
lastEvaluatedKey = {
[partitionKeyName]: lastEvaluatedKey[partitionKeyName],
[sortKeyName]: { [sortKeyType]: maxSortKeyValue },
};
} catch (error) {
if (error.code === 'InternalServerError' || error.code === 'ThrottlingException') {
console.error(`Received an error: ${error.code}, retrying...`);
await new Promise(resolve => setTimeout(resolve, 1000));
} else {
throw error;
}
}
}
}
// Define CLI arguments
program
.option('--table-name <tableName>', 'Name of the DynamoDB table')
.option('--region <region>', 'AWS region for the DynamoDB table')
.parse(process.argv);
const options = program.opts();
if (!options.region) {
console.error('Error: --region option is required.');
process.exit(1);
}
if (!options.tableName) {
console.error('Error: --table-name option is required.');
process.exit(1);
}
// Call the function with the specified table name and region
printDistinctPKs(options.region, options.tableName);
Java
对于 Java,请使用以下代码:
package org.example;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import software.amazon.awssdk.core.SdkBytes;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.dynamodb.DynamoDbClient;
import software.amazon.awssdk.services.dynamodb.model.AttributeValue;
import software.amazon.awssdk.services.dynamodb.model.DescribeTableRequest;
import software.amazon.awssdk.services.dynamodb.model.DescribeTableResponse;
import software.amazon.awssdk.services.dynamodb.model.DynamoDbException;
import software.amazon.awssdk.services.dynamodb.model.ScanRequest;
import software.amazon.awssdk.services.dynamodb.model.ScanResponse;
import software.amazon.awssdk.services.dynamodb.model.*;
import software.amazon.awssdk.core.SdkBytes;
import software.amazon.awssdk.core.exception.SdkException;
import software.amazon.awssdk.services.sts.StsClient;
import software.amazon.awssdk.services.sts.model.GetCallerIdentityRequest;
import software.amazon.awssdk.services.sts.model.GetCallerIdentityResponse;
public class PrintDistinctPKs {
static DynamoDbClient dynamoDb;
public static void main(String[] args) {
String tableName;
String region;
if (args.length != 4 || !args[0].equals("--table-name") || !args[2].equals("--region")) {
System.out.println("Error: --table-name and --region params not passed, checking AWS_DEFAULT_REGION and DYNAMODB_TABLE_NAME environment variables.");
// If they didn't pass the table name and region on the command line, see if they
// passed it in environment variables
region = System.getenv("AWS_DEFAULT_REGION");
if (region == null || region.isEmpty()) {
System.out.println("Error: AWS_DEFAULT_REGION environment variable is not set.");
System.exit(1);
} else {
software.amazon.awssdk.regions.Region awsRegion = null;
try {
awsRegion = software.amazon.awssdk.regions.Region.of(region);
} catch (IllegalArgumentException e) {
System.out.println("Error: Invalid AWS region specified in AWS_DEFAULT_REGION.");
System.exit(1);
}
dynamoDb = DynamoDbClient.builder().region(awsRegion).build();
// Validate region by making an API call to AWS STS service
try {
StsClient stsClient = StsClient.builder().region(awsRegion).build();
GetCallerIdentityRequest request = GetCallerIdentityRequest.builder().build();
GetCallerIdentityResponse response = stsClient.getCallerIdentity(request);
System.out.println("Region is valid. Account ID: " + response.account());
} catch (SdkException e) {
System.out.println("Error: Unable to validate region. Check your AWS credentials and region.");
System.exit(1);
}
}
tableName = System.getenv("DYNAMODB_TABLE_NAME");
if (tableName == null || tableName.isEmpty()) {
System.out.println("Error: DYNAMODB_TABLE_NAME environment variable is not set.");
System.exit(1);
}
} else {
tableName = args[1];
region = args[3];
}
printDistinctPKs(Region.of(region), tableName);
}
public static void printDistinctPKs(Region awsRegion, String tableName) {
DynamoDbClient dynamoDb = DynamoDbClient.builder().region(awsRegion).build();
DescribeTableResponse table = dynamoDb.describeTable(DescribeTableRequest.builder().tableName(tableName).build());
String partitionKeyName = table.table().keySchema().get(0).attributeName();
if (table.table().keySchema().size() == 1) {
throw new RuntimeException("Table needs to be a hash/range table");
}
String sortKeyName = table.table().keySchema().get(1).attributeName();
String sortKeyType = table.table().attributeDefinitions().stream()
.filter(attr -> attr.attributeName().equals(sortKeyName))
.findFirst()
.orElseThrow(() -> new RuntimeException("Could not find schema for attribute name: " + sortKeyName))
.attributeType().toString();
// We need to create a string that is encoded in UTF-8 to 1024 bytes of the highest
// code point. This is 256 code points. Each code point is a 4 byte value in UTF-8.
// In Java, the code point needs to be specified as a surrogate pair of characters, thus
// 512 characters.
StringBuilder sb = new StringBuilder(512);
for (int i = 0; i < 256; i++) {
sb.append("\uDBFF\uDFFF");
}
String maxSortKeyValueS = sb.toString();
String maxSortKeyValueN = "9.9999999999999999999999999999999999999E+125";
byte[] maxBytes = new byte[1024];
Arrays.fill(maxBytes, (byte)0xFF);
SdkBytes maxSortKeyValueB = SdkBytes.fromByteArray(maxBytes);
Map<String, AttributeValue> lastEvaluatedKey = null;
while (true) {
try {
ScanRequest scanRequest = ScanRequest.builder()
.tableName(tableName)
.limit(1)
.exclusiveStartKey(lastEvaluatedKey)
.projectionExpression("pk").build();
ScanResponse response = dynamoDb.scan(scanRequest);
if (!response.items().isEmpty()) {
System.out.println(response.items().get(0).get(partitionKeyName).s());
}
if (!response.hasLastEvaluatedKey()) {
break;
}
lastEvaluatedKey = response.lastEvaluatedKey();
AttributeValue maxSortKeyValue;
switch (sortKeyType) {
case "S":
maxSortKeyValue = AttributeValue.builder().s(maxSortKeyValueS).build();
break;
case "N":
maxSortKeyValue = AttributeValue.builder().n(maxSortKeyValueN).build();
break;
case "B":
maxSortKeyValue = AttributeValue.builder().b(maxSortKeyValueB).build();
break;
default:
throw new RuntimeException("Unsupported sort key type: " + sortKeyType);
}
lastEvaluatedKey = new HashMap<>(lastEvaluatedKey);
lastEvaluatedKey.put(sortKeyName, maxSortKeyValue);
} catch (DynamoDbException e) {
if (e.awsErrorDetails().errorCode().equals("InternalServerError")
|| e.awsErrorDetails().errorCode().equals("ThrottlingException")) {
System.err.println("Received an error: " + e.awsErrorDetails().errorCode() + ", retrying...");
try {
Thread.sleep(1000);
} catch (InterruptedException interruptedException) {
break;
}
} else {
throw e;
}
}
}
}
}
结论
在这篇文章中,我们探讨了在 DynamoDB 表中生成一组不同的分区键所面临的挑战。我们讨论了扫描整个表格的传统方法,这种方法对于没有排序键的表格或小型项目集合来说效果很好,但是对于包含大量项目集合的表格来说,它可能既昂贵又缓慢。然后,我们提出了一个使用 DynamoDB 中的分页功能的更有效的解决方案,该功能允许您一次检索一个分区键,从而最大限度地减少扫描的数据量并降低成本。
这种优化的解决方案不仅可以加快生成一组不同的分区键的过程,还可以帮助您节省读取容量并避免节流。请记住,调整方法以适应您的特定用例和表格大小非常重要。此方法的效率将取决于分区键的分布和表的整体结构。如果您需要为大型表生成一组不同的分区键或执行其他需要扫描表的操作,请考虑使用本文中概述的高效分页方法来节省时间和成本。
作者简介
 查德·廷德尔
是驻纽约市的首席DynamoDB专业解决方案架构师。他与大型企业合作,评估、设计和部署基于 DynamoDB 的解决方案。在加入亚马逊之前,他曾在红帽、Cloudera、MongoDB和Elastic担任过类似的职务。
查德·廷德尔
是驻纽约市的首席DynamoDB专业解决方案架构师。他与大型企业合作,评估、设计和部署基于 DynamoDB 的解决方案。在加入亚马逊之前,他曾在红帽、Cloudera、MongoDB和Elastic担任过类似的职务。

 杰森·亨特
是驻加州的 DynamoDB 首席专业解决方案架构师。自 2003 年以来,他一直在使用 NoSQL 数据库。他以对 Java、开源和 XML 的贡献而闻名。
杰森·亨特
是驻加州的 DynamoDB 首席专业解决方案架构师。自 2003 年以来,他一直在使用 NoSQL 数据库。他以对 Java、开源和 XML 的贡献而闻名。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。