我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
采用 亚马逊云科技 AppSync 和 GraphQL Fusion 的基于 GraphQL 网关的
将多个 GraphQL 架构组合成单个端点使开发人员能够独立开发、部署和扩展其服务,同时将其作为单个 GraphQL 架构公开。
合并的 API 是编写 AppSync API 子图的绝佳解决方案。但是,如果您的要求是编写 AppSync API 和非 AppSync API,则需要实现 GraphQL 网关。GraphQL 网关负责将多个 GraphQL 子图端点组合成一个统一的架构。在运行时,网关会接收每个 GraphQL 请求,并智能地将它们路由到不同的子图中。对网关的单个请求可能会导致向后端子图发出多个内部请求,以成功检索数据。
尽管在网关内构建 GraphQL 架构的现有方法有很多,但 GraphQL 社区缺乏开放的 GraphQL 网关规范,该规范是从头开始设计的,旨在实现可扩展性和与各种工具集的集成。最近,在GraphQLConf上,亚马逊云科技 AppSync很自豪地支持Grap
符合 GraphQL Fusion 规范的网关将包括查询规划和联接数据的逻辑,并且能够将请求分发到任何 GraphQL 服务器或端点,包括任何基于 亚马逊云科技 AppSync 构建的无服务器 GraphQL API,甚至是合并的 API。GraphQL-Fusion 规范扩展了传统的联合方法,允许网关在单个 GraphQL 架构 下使用 GraphQL、REST 或 g
在这篇博客文章中,我们将讨论 GraphQL-Fusion 规范如何简化多个架构的组合,并通过示例以运行时方法编写子图。在这个演示中,我们将多个 亚马逊云科技 AppSync 子图和一个使用开源 GraphQL 服务器
以下是演示架构的示意图:
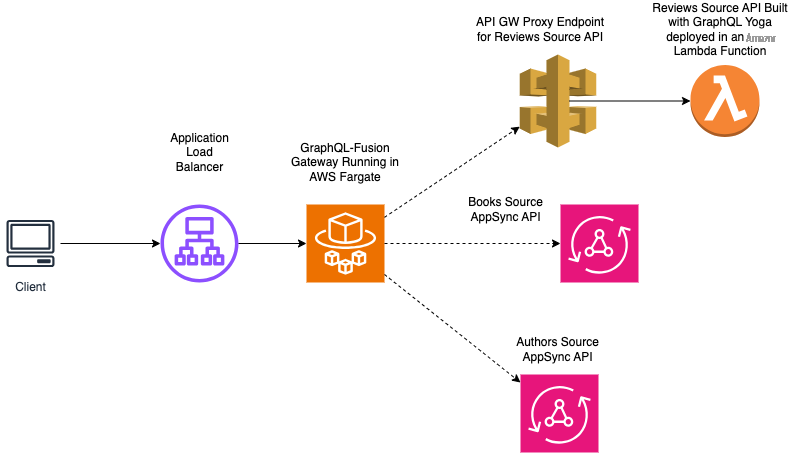
在本演示中,我们将构建一个类似于
-
Books Subg
raph → 此子图负责将与每本书相关的数据存储在网站目录中。子图提供了查询图书元数据以及从目录中添加、更新和删除书籍的功能。这本书的子图是使用 亚马逊云科技 AppSync 和
亚马逊 Dyn amoDB 创建的,用于存储 数据。 - 作者子图 → 此子图负责在网站目录中存储与图书作者相关的数据。它提供了查询与作者相关的信息(包括姓名和电子邮件)以及用于在目录中添加、更新和删除作者的变更的功能。此子图也是使用 亚马逊云科技 AppSync 和亚马逊 DynamoDB 创建的。
-
评论子图
→ 此子图负责在网站目录中存储与图书评论相关的数据。该网站的用户可以为一本书添加评论,包括评论和评分。评论子图提供了按书籍或作者查询评论以及添加、更新和删除评论的功能。在本子图中,我们选择创建非 AppSync 端点。取而代之的是,我们将添加一个
亚马逊 API Gatew ay 端点,该 端点将每个 Graphql 请求代理到使用 Typescript 编写的 亚马逊云科技 Lam bda 函数。在这个 Lambda 函数中,我们使用开源GraphQL 服务器 GraphQL Y oga 和亚马逊 DynamoDB 来存储评论数据。
GraphQL 网关将处理 GraphQL 请求路由到一个或多个子图。我们的 GraphQL 网关使用
先决条件
为了部署演示,您将需要以下内容:
- 一个活跃的 亚马逊云科技 账户
-
亚马逊云科技 CDK -
.NET 8.0 版本 8.0.100-preview.7 -
Docker -
NPM -
纱线 - 一个 git 客户端。
部署子图
首先,让我们克隆演示存储库并部署子图。
$ git clone https://github.com/aws-samples/aws-appsync-graphql-fusion-demo.git
$ cd appsync-graphql-fusion-demo
$ ./deploy-subgraphs
现在,我们已经部署了子图,让我们来看看子图暴露的每个 GraphQL 架构:
子图 1:作者子图
schema {
query: Query,
mutation: Mutation
}
type Author {
id: ID!
name: String!
bio: String
contactEmail: String
nationality: String
}
type AuthorConnection {
items: [Author]
nextToken: String
}
type Book {
authorId: ID!
author: Author
}
input CreateAuthorInput {
name: String!
bio: String
contactEmail: String
nationality: String
}
input DeleteAuthorInput {
id: ID!
}
type Mutation {
createAuthor(input: CreateAuthorInput!): Author
deleteAuthor(input: DeleteAuthorInput!): Author
}
type Query {
authorById(id: ID!): Author
authors(limit: Int): AuthorConnection
bookByAuthorId(authorId: ID!): Book
}
子图 2:书籍副图
schema {
query: Query,
mutation: Mutation
}
type Author {
id: ID!
books: BookConnection
}
type Book {
id: ID!
title: String!
authorId: ID!
genre: String
publicationYear: Int
}
type BookConnection {
items: [Book]
nextToken: String
}
input CreateBookInput {
title: String!
authorId: ID!
genre: String
publicationYear: Int
}
input DeleteBookInput {
id: ID!
}
type Mutation {
createBook(input: CreateBookInput!): Book
deleteBook(input: DeleteBookInput!): Book
}
type Query {
bookById(id: ID!): Book
books(limit: Int): BookConnection
authorById(id: ID!): Author
}
子图 3:评论子图
schema {
query: Query
mutation: Mutation
}
type Author {
id: ID!
reviews: ReviewConnection
}
type Book {
id: ID!
reviews: ReviewConnection
}
type Review {
id: ID!
authorId: String!
bookId: String!
comment: String!
rating: Int!
}
type ReviewConnection {
items: [Review]
nextToken: String
}
input CreateReviewInput {
bookId: ID!
reviewerId: ID!
authorId: ID!
comment: String!
rating: Int!
}
input DeleteReviewInput {
id: ID!
}
type Query {
reviewById(id: ID!): Review
reviews(limit: Int): ReviewConnection
authorById(id: ID!): Author
bookById(id: ID!): Book
}
type Mutation {
createReview(input: CreateReviewInput!): Review
deleteReview(input: DeleteReviewInput!): Review
}
在查看我们的子图架构时,首先要注意的是,我们无需添加任何特殊指令或注释即可使其与我们的 GraphQL Gateway 兼容,这是 GraphQL Fusion 规范的主要优点之一。GraphQL-Fusion 规范的目标之一是简化网关的配置方式,不需要子图来实现任何附加协议。
架构组合是 GraphQL Fusion 规范的主要组成部分。当 Fusion 架构由多个子图 “ 组成 ” 时,它能够推断出 GraphQL 架构的语义含义,这意味着几乎不需要额外的注释。架构组合可以理解命名模式和 GraphQL 最佳实践,例如中继模式。架构组合逻辑在构建时执行,并生成单个文档,该文档为网关在运行时执行查询计划提供了所有必需的信息,以便在子图中联接数据。
以作者子图架构中的以下片段为例:
type Book {
authorId: ID!
author: Author
}
type Query {
authorById(id: ID!): Author
authors(limit: Int, nextToken: String): AuthorConnection
bookByAuthorId(authorId: ID!): Book
}
在此示例中,我们使用 “
{type} By {key}
” 命名惯例来定义哪些查询操作可用。例如,要从该子图中检索图书类型,您必须提供一个 Au
thorID
输入,该输入充当检索数据的密钥。图书类型包含一个作者字段,该字段用于将一本书的数据与其对应的作者连接起来。在其他方法中,我们可能需要使用指令对架构进行注释,以便定义这种关系以及如何使用此子图检索
Book.Author
字段。使用 GraphQL Fusion,这将由架构组合例程自动处理,因此无需进行任何更改即可将子图与网关集成。
以下是本示例中整个组合架构文档类型的简要摘要。请注意,对于 书籍 类型,架构组合例程包括字段 作者 。该字段有 @source 指令,表示该指令是在作者子图中定义的。 图书类型还包含 @resolver 指令,该指令表示可以使用传递 $book_AuthorID 变量的 bookbyAuthorID 查询来检索以作者子图为来源的字 段:
schema @fusion(version: 1)
@httpClient(subgraph: "Books", baseAddress: "<server endpoint url>")
@httpClient(subgraph: "Authors", baseAddress: "<server endpoint url>")
@httpClient(subgraph: "Reviews", baseAddress: "<server endpoint url>")
query: Query
}
type Book @variable(subgraph: "Books", name: "Book_id", select: "id")
@variable(subgraph: "Reviews", name: "Book_id", select: "id")
@variable(subgraph: "Books", name: "Book_authorId", select: "authorId")
@variable(subgraph: "Authors", name: "Book_authorId", select: "authorId")
@resolver(subgraph: "Books", select: "{ bookById(id: $Book_id) }", arguments: [ { name: "Book_id", type: "ID!" } ])
@resolver(subgraph: "Authors", select: "{ bookByAuthorId(authorId: $Book_authorId) }", arguments: [ { name: "Book_authorId", type: "ID!" } ])
@resolver(subgraph: "Reviews", select: "{ bookById(id: $Book_id) }", arguments: [ { name: "Book_id", type: "ID!" } ]) {
author: Author @source(subgraph: "Authors")
authorId: String! @source(subgraph: "Books") @source(subgraph: "Authors")
id: ID! @source(subgraph: "Books") @source(subgraph: "Reviews")
reviews: ReviewConnection! @source(subgraph: "Reviews")
title: String @source(subgraph: "Books")
}
type Query {
authorById(id: ID!): Author
@variable(subgraph: "Books", name: "id", argument: "id")
@resolver(subgraph: "Books", select: "{ authorById(id: $id) }", arguments: [ { name: "id", type: "ID!" } ])
@variable(subgraph: "Authors", name: "id", argument: "id")
@resolver(subgraph: "Authors", select: "{ authorById(id: $id) }", arguments: [ { name: "id", type: "ID!" } ])
@variable(subgraph: "Reviews", name: "id", argument: "id")
@resolver(subgraph: "Reviews", select: "{ authorById(id: $id) }", arguments: [ { name: "id", type: "ID!" } ])
bookByAuthorId(authorId: ID!): Book
@variable(subgraph: "Authors", name: "authorId", argument: "authorId")
@resolver(subgraph: "Authors", select: "{ bookByAuthorId(authorId: $authorId) }", arguments: [ { name: "authorId", type: "ID!" } ])
bookById(id: ID!): Book
@variable(subgraph: "Books", name: "id", argument: "id")
@resolver(subgraph: "Books", select: "{ bookById(id: $id) }", arguments: [ { name: "id", type: "ID!" } ])
@variable(subgraph: "Reviews", name: "id", argument: "id")
@resolver(subgraph: "Reviews", select: "{ bookById(id: $id) }", arguments: [ { name: "id", type: "ID!" } ])
}
撰写子图
在我们的 GraphQL-Fusion 实现中,使用开放包惯例将撰写文档元数据打包到
.fgp
文件中。为了将 Gateway 与我们的子图集成,我们使用以下脚本打包子图元数据:
./compose-gateway-schema.sh
部署 GraphQL 网关
现在网关架构已经构成,我们可以使用以下脚本部署网关端点:
./deploy-fusion-gateway.sh
记下上面脚本输出的 G raphqlGateway.graphqlGatewayEndpoint ,因为我们将在下一节中使用它:
Outputs:
GraphQLGateway.GraphQLGatewayEndpoint = _http://GraphQ-Graph-<AAA>.<region>.elb.amazonaws.com/graphql
_GraphQLGateway.GraphQLGatewayServiceLoadBalancerDNS691F4497 = _[GraphQ-Graph-<AAA>.us-west-2.elb.amazonaws.com](http://graphq-graph-ugfqnjtfi6lc-301122370.us-west-2.elb.amazonaws.com/)_GraphQLGateway.GraphQLGatewayServiceServiceURL267E9CE0 = _[http://GraphQ-Graph-UgfqNJTFI6Lc-301122370.us-west-2.elb.amazonaws.com](http://graphq-graph-ugfqnjtfi6lc-301122370.us-west-2.elb.amazonaws.com/)_
测试样本
部署网关后,您可以通过作为上一步输出提供的 G
raphqlGateway.graphqlGatewayE
ndpoint 对其进行访问。在浏览器中导航到端点将打开网关实现提供的 GraphQL 浏览器。选择 “
创建文档
” 以插入示例数据。

1。添加样本作者
mutation createAuthor {
createAuthor(input: {
name: "Mark Twain",
bio: "Mark Twain was an American humorist, journalist, lecturer, and novelist",
contactEmail: "markTwain@example.com",
nationality: "USA"
}) {
id,
bio,
contactEmail,
nationality
}
}
示例响应:
{
"data": {
"createAuthor": {
"id": "bab29018-c276-4636-840e-099e227e634f",
"bio": "Mark Twain was an American humorist, journalist, lecturer, and novelist",
"contactEmail": "markTwain@example.com",
"nationality": "USA"
}
}
}
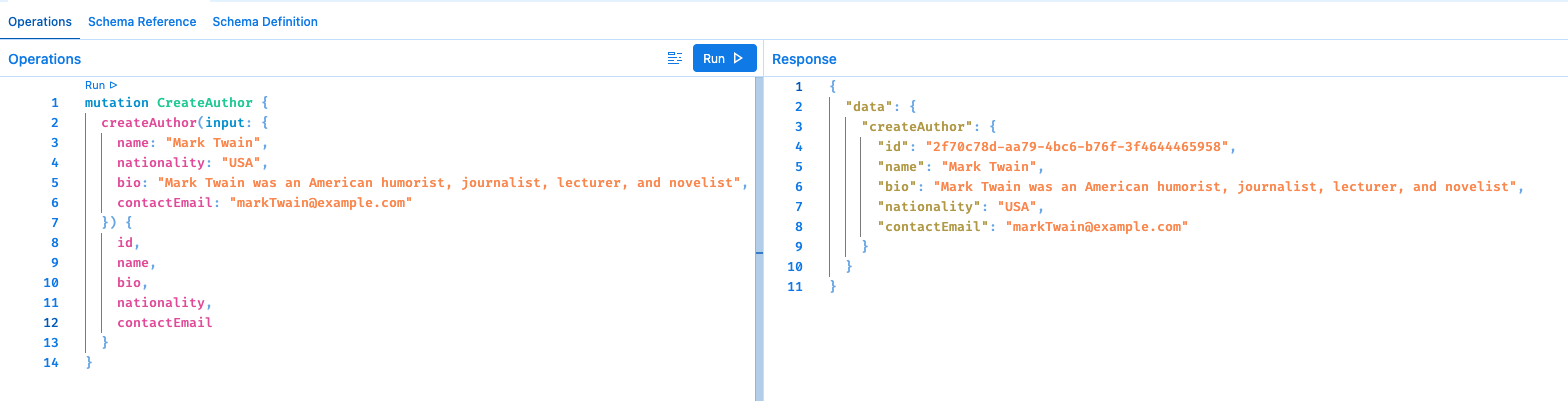
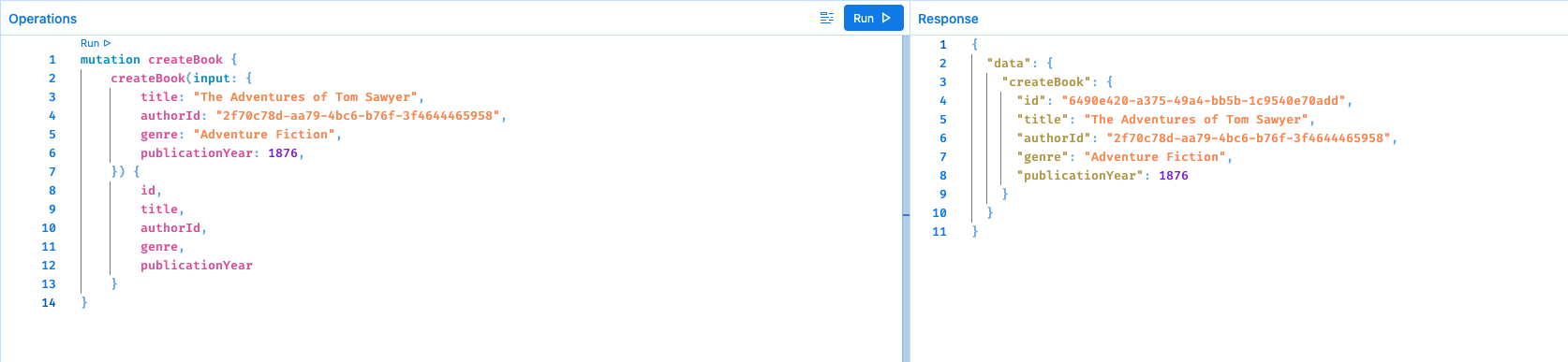
2。使用上面步骤中该作者的 ID 添加该作者的样本书。
mutation createBook {
createBook(input: {
title: "The Adventures of Tom Sawyer",
authorId: "bab29018-c276-4636-840e-099e227e634f",
genre: "Adventure Fiction",
publicationYear: 1876,
}) {
id,
title,
authorId,
genre,
publicationYear
}
}
示例响应:
{
"data": {
"createBook": {
"id": "6490e420-a375-49a4-bb5b-1c9540e70add",
"title": "The Adventures of Tom Sawyer",
"authorId": "bab29018-c276-4636-840e-099e227e634f",
"genre": "Adventure Fiction",
"publicationYear": 1876
}
}
}
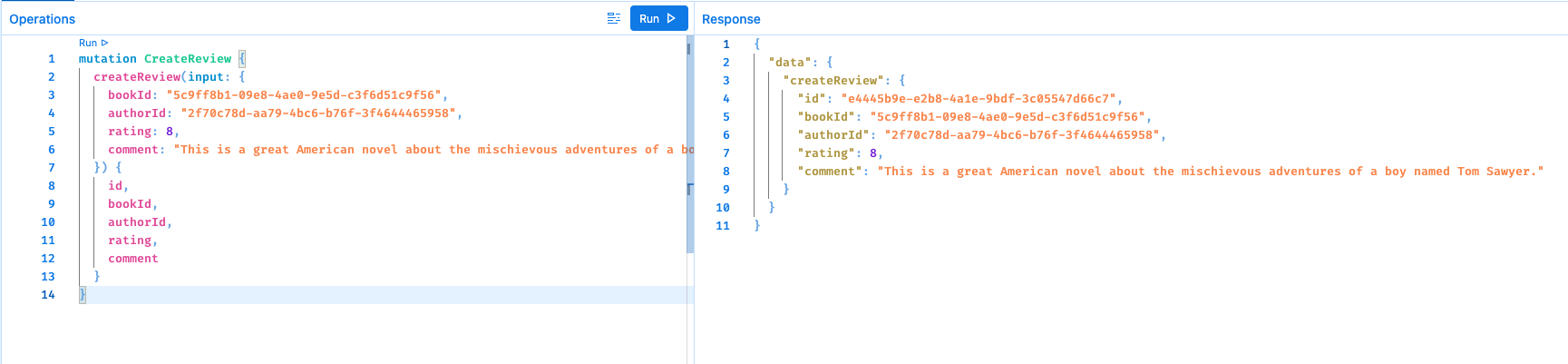
3。使用生成的图书 ID 和作者 ID 为这本书添加样本评论。
mutation createReview {
createReview(input: {
authorId: "bab29018-c276-4636-840e-099e227e634f",
bookId: "6490e420-a375-49a4-bb5b-1c9540e70add",
comment: "This is a great American novel about the mischievous adventures of a boy named Tom Sawyer",
rating: 8
}) {
id,
authorId,
bookId,
comment,
rating
}
}
示例响应:
{
"data": {
"createReview": {
"id": "2d07d856-522f-4259-9848-0a67a14929fd",
"authorId": "bab29018-c276-4636-840e-099e227e634f",
"bookId": "6490e420-a375-49a4-bb5b-1c9540e70add",
"comment": "This is a great American novel about the mischievous adventures of a boy named Tom Sawyer",
"rating": 8
}
}
4。运行测试查询
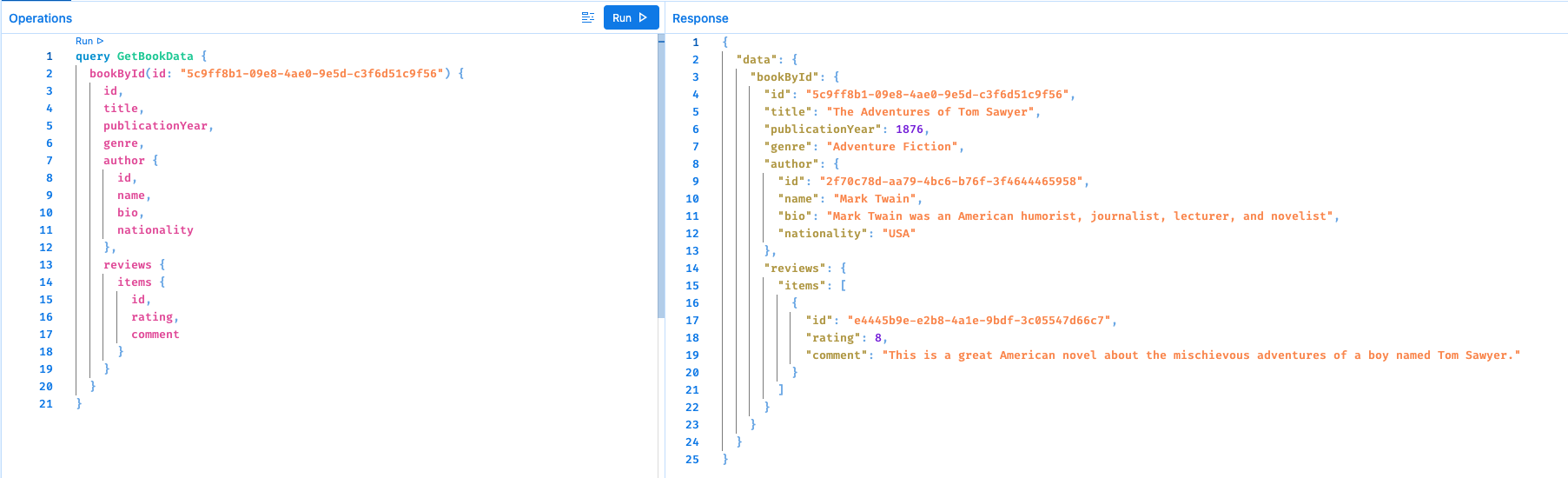
query GetBookData {
bookById(id: "6490e420-a375-49a4-bb5b-1c9540e70add") {
id,
title,
publicationYear,
genre,
author {
id,
name,
bio,
nationality
},
reviews {
items {
id,
rating,
comment
}
}
}
}
响应示例:
{
"data": {
"bookById": {
"id": "6490e420-a375-49a4-bb5b-1c9540e70add",
"title": "The Adventures of Tom Sawyer",
"publicationYear": 1876,
"genre": "Adventure Fiction",
"author": {
"id": "bab29018-c276-4636-840e-099e227e634f",
"name": "Mark Twain",
"bio": "Mark Twain was an American humorist, journalist, lecturer, and novelist",
"nationality": "USA"
},
"reviews": {
"items": [
{
"id": "2d07d856-522f-4259-9848-0a67a14929fd",
"rating": 8,
"comment": "This is a great American novel about the mischievous adventures of a boy named Tom Sawyer."
}
]
}
}
}
}
检查查询计划
Gateway IDE 允许您检查请求的查询计划,通过启用融合查询计划来识别针对后端子图执行的子查询。
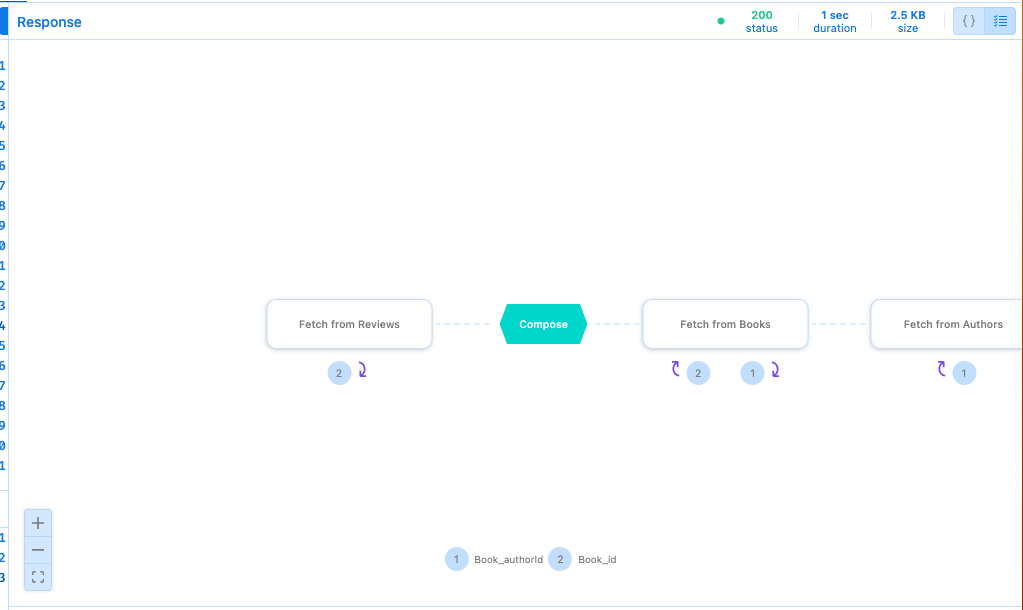
此请求的查询计划表明,网关对 3 个不同的后端子图执行了 3 个请求。首先,网关使用输入 ID 并行从评论子图和图书子图中检索有关图书的数据。然后,解析包括图书作者 ID 在内的图书数据后,网关会向作者子图发送后续查询,以检索图书数据中返回相应作者 ID 的作者的作者数据。您可以在
清理
该示例提供了用于清理所有资源的清理脚本:
./cleanup-infrastructure.sh
走得更远
随着社区共同努力完善草案,GraphQL-Fusion规范的制定正在进行中。
作者简介

|
Nicholas is a Senior Software Engineer who has been working on 亚马逊云科技 AppSync for the past 3 years. He spends his work days focused on improving GraphQL query execution performance and weekends roaming around San Francisco with his dog Pippa. |
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。