我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
FactSet 如何在 亚马逊云科技 和本地统一网络监控
这是 FactSet、Sreekanth Sarma Vanam(网络工程总监、Saurabh Gadi)、首席系统工程师兼亚马逊云科技解决方案架构师、Mony Kiem和Amit Borulkar的帖子。
用@@ Factset自己的话说:“FactSet为全球成千上万的投资专业人士创建灵活、开放的数据和软件解决方案。这些解决方案可即时访问财务数据和分析,投资者使用这些数据和分析来做出关键决策。在FactSet,我们一直在努力使我们的产品对客户更有价值。”
简介
FactSet 的混合云基础设施(由 亚马逊云科技、美国的数据中心和全球接入点 (PoP) 组成)的快速扩张需要高效而全面的网络监控解决方案。FactSet 的网络工程师负责在所有这些地点之间建立连接,并在它们之间实现最佳延迟。这篇文章探讨了FactSet如何通过实施与基础设施无关的分布式监控系统来应对这一挑战,为其不同场所的网络性能提供了宝贵的见解。
解决方案概述
FactSet 必须确保最佳的网络延迟,并支持其应用程序的高交易性质。在整个 亚马逊云科技 中,FactSet 使用共享的 VPC 拓扑,其中不同的 亚马逊云科技 账户在 亚马逊云科技 组织单位 (OU) 中共享相同的 VPC。我们在下图中显示了这一点(图 1)。
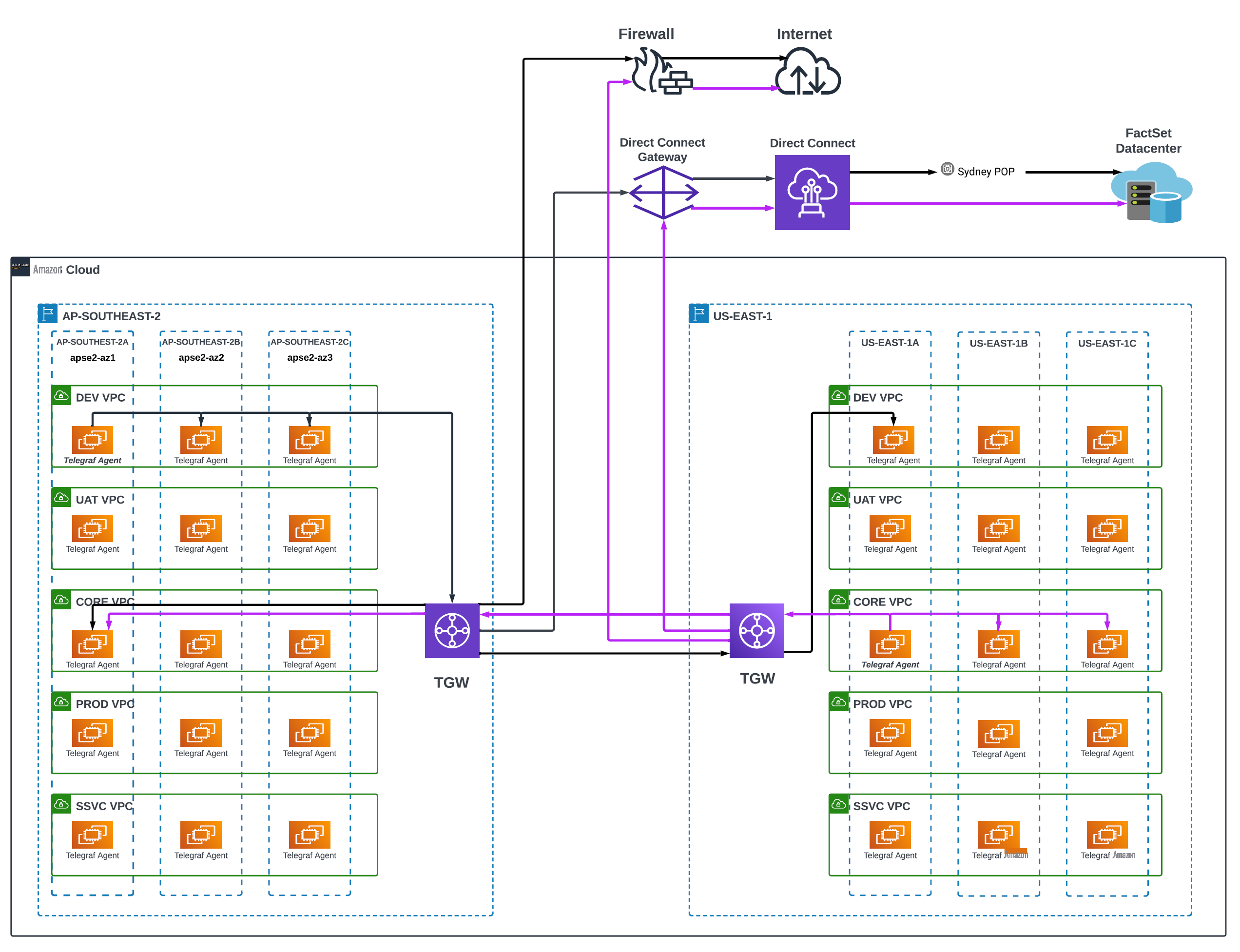
图 1:FactSet 网络和 Telegraf 代理架构
网络工程部配置 VPC 并在 VPC 和其他各个 FactSet 场所之间建立连接。在开发、UAT、生产和共享服务环境中也有不同的网络分段。相同的环境分段转换为
FactSet 选择了原生 亚马逊云科技 网络监控功能和
除T
Telegraf 服务器通过启动和响应探测来监控网络运行状况。以下是所有环境中使用的一些常见探测器/流:
- 可用区间 — Telegraf 启动 ICMP 探测以测量在不同可用区中运行的 EC2 实例之间的响应时间和数据包。
- VPC 间 — Telegraf 启动 ICMP 探测以测量同一 亚马逊云科技 区域共享服务环境中实例的响应时间和数据包丢失情况。这些流量穿过公交网关,为穿过交通网关的网络运行状况提供指示。
- 区域间 — Telegraf 启动 ICMP 探测以测量其他 亚马逊云科技 区域的响应时间和数据包丢失目标实例。这些流量通过 Transit Gateway 区域间对等连接,表明区域之间的网络运行状况。
-
混合云
— Telegraf 针对该地区以外的各种目标启动 ICMP、HTTP 和 DNS 探测。这些流量穿过
亚马逊云科技 Direct Connect 网 关、传输网关和直接连接虚拟接口 (VIF),记录整个网络的运行状况。 - 互联网 — 实例启动各种 ICMP、HTTP 和 DNS 探测,以评估从每个 亚马逊云科技 区域访问互联网的可访问性。这些探测器遍历 FactSet 管理防火墙、NAT 网关和互联网网关 (IGW),确保互联网连接和性能。
解决方案技术堆栈和运营
FactSet 依赖 TICK(Telegraf、Influx DB、Captacions 和 Kibana)堆栈作为其网络监控解决方案。这个 TICK 堆栈提供了一个强大且可扩展的监控架构。作为主要的数据收集器,Telegraf带有内置
- 输入插件用于捕获插件定义的指标
- 输出插件用于将指标数据写入各种收集器/目的地
以下是当前 Telegraf 安装所使用的插件:
-
Ping 输入插件 — 此输入插件用于 ping telegraf.conf 文件中指定的各个目的地,并报告 RTT 和损失。FactSet 已将其设置为每秒轮询一次。 -
HTTP 响应输入插件 — 此输入插件用于探测各种 HTTP/s 端点、验证可访问性并根据 200 个 HTTP 响应代码报告 Response_Time。 -
DNS 查询输入登录 — 此输入插件用于查询 telegraf.conf 文件中配置的各种名称,并报告查询状态(成功/失败)和响应时间。 -
HTTP 输出插件 — 此输出插件用于将从前面的输入插件获得的指标数据导出到 monster-data-api(用于收集 Telegraf 指标的内部 API)。
通过 API 提取指标后,数据存储在时间序列数据库 Influx DB 中。然后,使用
FactSet 采用持续集成/持续部署 (CI/CD) 流程来确保一致性并减少管理 亚马逊云科技 区域的 Telegraf 配置的运营负担。如下图所示(图 2)。
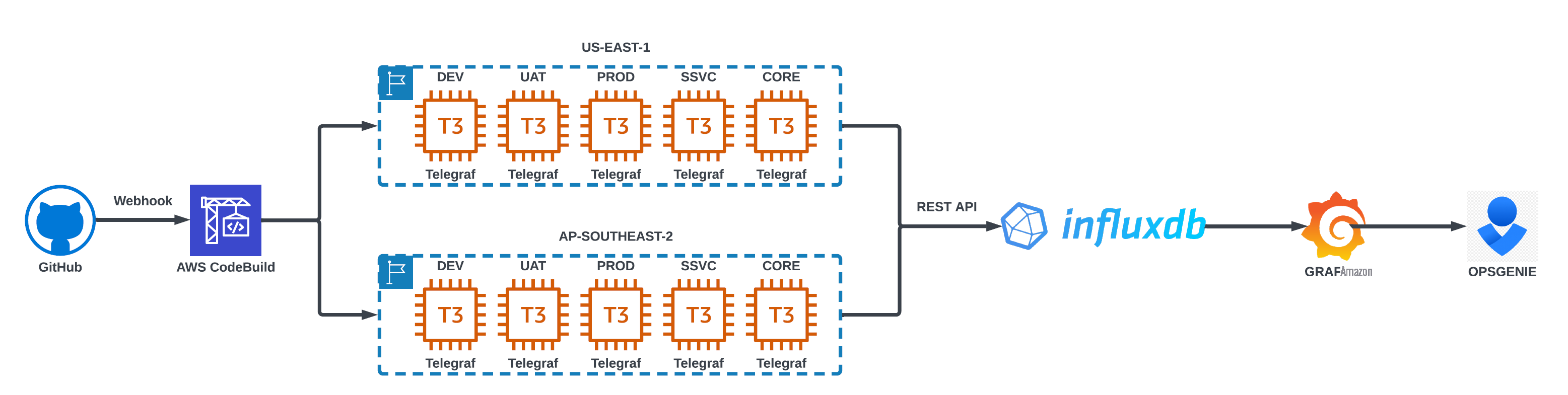
图 2:FactSet Telegraf 部署工作流程
观察到的结果
在规则引擎中定义了以下自定义警报:
- 目标持续一分钟会损失 100% 的 ICMP
- 在过去 30 分钟内,持续 ICMP 损失超过 5%
- 在过去 10 分钟内 5 分钟内,与基线的持续偏差超过 50%
- 任何目标的 HTTP 代码响应均不是 200
- 针对已配置目标的任何 DNS 查询均为非零的 DNS 响应码
这使得 FactSet 能够迅速检测网络降级事件。自定义警报引擎旨在识别指定时间段内的持续异常情况,有助于消除误报警报并专注于关键网络问题。该解决方案加快了故障排除和问题解决,使FactSet和亚马逊云科技工程团队都受益,并支持未来的迁移。
结论
FactSet 的统一网络监控解决方案结合了 亚马逊云科技 的原生监控功能和 Telegraf 的灵活架构,为网络基础设施的性能和运行状况提供了宝贵的见解。该解决方案的可扩展性、全面的可见性和有效的警报机制改善了事件响应,并有助于识别性能差距。尽管当前的解决方案符合 FactSet 的要求,但设置自动化和部署需要付出足够的努力,以减轻在 EC2 实例上运行软件的运营负担。FactSet 预计,网络性能监控和 亚马逊云科技 Network Manager — 基础设施性能等未来将采用 亚马逊云科技 服务,以减少运营开销、部署弹性全球应用程序并简化新 亚马逊云科技 区域的采用。
贡献者
这篇文章中的内容和观点包括第三方作者的内容和观点,亚马逊云科技 对这篇文章的内容或准确性不承担任何责任。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。