我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Light & Wonder 如何在 亚马逊云科技 上为游戏机构建预测性维护解决方案
这篇文章是与《光与奇迹》(L&W)的阿鲁娜·阿贝亚库恩和丹尼斯·科林共同撰写的。
L
Light & Wonder 与
该项目的性质极具探索性,这是游戏行业首次尝试进行预测性维护。Amazon ML 解决方案实验室和 L&W 团队开始了从制定机器学习问题和定义评估指标到提供高质量解决方案的端到端旅程。最终的机器学习模型结合了 CNN 和 Transformer,它们是用于对顺序机器日志数据进行建模的最先进的神经网络架构。这篇文章详细描述了这段旅程,我们希望你能像我们一样喜欢它!
在这篇文章中,我们将讨论以下内容:
- 我们如何使用一组适当的评估指标将预测性维护问题描述为机器学习问题
- 我们如何为训练和测试准备数据
- 我们采用的数据预处理和特征工程技术来获取性能模型
-
使用
亚马逊 SageMaker 自动模型调整执行超参数调整步骤 - 基准模型与最终 CNN+变压器模型之间的比较
- 我们用于提高模型性能的其他技术,例如组合
背景
在本节中,我们将讨论需要此解决方案的问题。
数据集
老虎机环境受到严格监管,部署在气隙环境中。在 LnW Connect 中,加密过程旨在为将数据导入 亚马逊云科技 数据湖进行预测建模提供安全可靠的机制。聚合文件经过加密,解密密钥仅在
LnW Connect 可直播各种机器事件,例如游戏开始、游戏结束等。该系统收集了 500 多种不同类型的事件。如下所示
,记录每个事件以及事件发生时间的时间戳和记录该事件的机器的 ID。LnW Connect 还会记录机器何时进入不可玩状态,如果在足够短的时间内没有恢复到可玩状态,它将被标记为机器故障或故障。
| Machine ID | Event Type ID | Timestamp |
|---|---|---|
| 0 | E1 | 2022-01-01 00:17:24 |
| 0 | E3 | 2022-01-01 00:17:29 |
| 1000 | E4 | 2022-01-01 00:17:33 |
| 114 | E234 | 2022-01-01 00:17:34 |
| 222 | E100 | 2022-01-01 00:17:37 |
除了动态计算机事件外,还提供有关每台计算机的静态元数据。这包括计算机唯一标识符、机柜类型、位置、操作系统、软件版本、游戏主题等信息,如下表所示。(表中的所有姓名都经过匿名化处理,以保护客户信息。)
| Machine ID | Cabinet Type | OS | Location | Game Theme |
|---|---|---|---|---|
| 276 | A | OS_Ver0 | AA Resort & Casino | StormMaiden |
| 167 | B | OS_Ver1 | BB Casino, Resort & Spa | UHMLIndia |
| 13 | C | OS_Ver0 | CC Casino & Hotel | TerrificTiger |
| 307 | D | OS_Ver0 | DD Casino Resort | NeptunesRealm |
| 70 | E | OS_Ver0 | EE Resort & Casino | RLPMealTicket |
问题定义
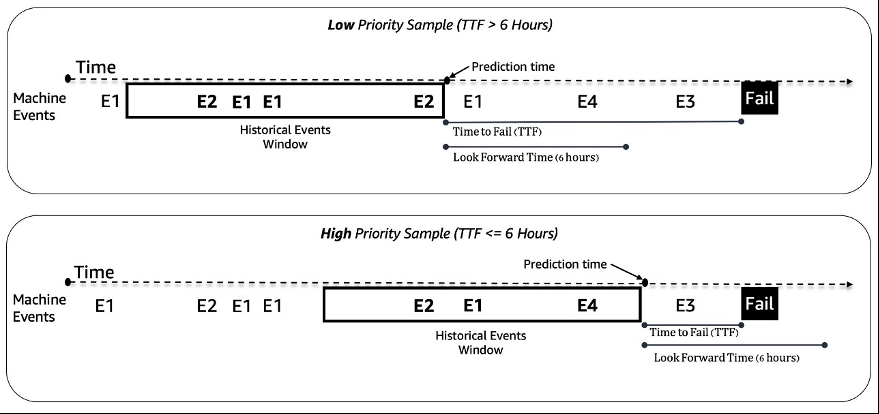
我们将老虎机的预测性维护问题视为二元分类问题。机器学习模型采纳计算机事件和其他元数据的历史顺序,预测机器在未来 6 小时内是否会遇到故障。如果一台机器在 6 小时内出现故障,则将其视为需要维护的高优先级机器。否则,它的优先级较低。下图给出了低优先级(顶部)和高优先级(底部)样本的示例。我们使用固定长度的回顾时间窗口来收集历史机器事件数据进行预测。实验表明,更长的回顾时间窗口可以显著提高模型性能(更多细节将在本文后面介绍)。
建模挑战
我们在解决这个问题时遇到了几个挑战:
- 我们有大量的事件日志,每月包含大约 5000 万个事件(来自大约 1,000 个游戏样本)。在数据提取和预处理阶段需要仔细优化。
- 由于随着时间的推移,事件的分布极其不均匀,因此事件序列建模具有挑战性。3 小时窗口可以包含数万到数千个事件。
- 机器大多数时候都处于良好状态,高优先级维护属于罕见类别,这引入了等级不平衡问题。
- 系统中不断添加新机器,因此我们必须确保我们的模型能够在训练中从未见过的新机器上进行预测。
数据预处理和特征工程
在本节中,我们将讨论我们的数据准备和特征工程方法。
功能工程
老虎机源是间隔不均匀的时间序列事件流;例如,3 小时窗口内的事件数量可能从数万到数千不等。为了处理这种不平衡,我们使用了事件频率而不是原始序列数据。一种直接的方法是聚合整个回顾窗口的事件频率并将其输入到模型中。但是,使用这种表示形式时,时间信息会丢失,事件顺序得不到保留。相反,我们使用了时间分组,方法是将时间窗口分成 N 个相等的子窗口,然后计算每个子窗口中的事件频率。时间窗的最终特征是其所有子窗口功能的组合。增加垃圾箱的数量可以保留更多的时间信息。下图说明了示例窗口上的时间分箱。
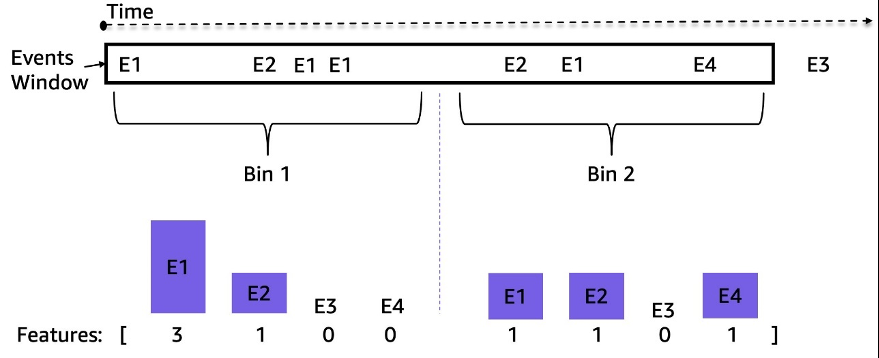
首先,将采样时间窗口分成两个相等的子窗口(bin);为了便于说明,我们在这里只使用了两个分栏。然后,在每个立方格中计算事件 E1、E2、E3 和 E4 的计数。最后,它们被串联起来用作功能。
除了基于事件频率的功能外,我们还使用了特定于机器的功能,例如软件版本、机柜类型、游戏主题和游戏版本。此外,我们还添加了与时间戳相关的功能以捕捉季节性,例如一天中的某个小时和一周中的某天。
数据准备
为了高效地提取数据用于培训和测试,我们使用了亚马逊 Athena 和 亚马逊云科技 Glue 数据目录。事件数据以 Parquet 格式存储在 Amazon S3 中,并根据日/月/小时进行分区。这便于在指定的时间窗口内高效提取数据样本。我们使用最近一个月来自所有机器的数据进行测试,其余数据用于训练,这有助于避免潜在的数据泄露。
机器学习方法和模型训练
在本节中,我们将讨论使用 AutoGluon 的基准模型,以及如何使用 SageMaker 自动模型调整来构建自定义神经网络。
使用 AutoGluon 构建基准模型
对于任何 ML 用例,建立用于比较和迭代的基准模型都很重要。我们使用
使用 SageMaker 自动模型调整来构建和调整自定义的神经网络模型
在尝试了不同的神经网络架构之后,我们构建了一个用于预测性维护的自定义深度学习模型。我们的模型召回率比AutoGluon基准模型高出121%,精度为80%。最终模型采集历史计算机事件序列数据、时间特征(例如一天中的某个小时)和静态计算机元数据。我们利用
下图显示了模型架构。我们首先根据训练集中每个事件的平均频率对分箱事件序列数据进行标准化,以消除高频事件(游戏开始、游戏结束等)的压倒性影响。
- 卷积层 (CNN) — 每个 CN N 层由两个具有剩余连接的一维卷积运算组成。每个 CNN 层的输出与输入具有相同的序列长度,便于与其他模块堆叠。CNN 层的总数是一个可调的超参数。
- 变压器编码层 (TRANS) — CNN 层的输出与位置编码一起馈送到多头自注意力结构。我们使用 TRANS 直接捕获时间依赖关系,而不是使用循环神经网络。在这里,对原始序列数据进行分组(长度从数千减少到数百)有助于缓解 GPU 内存瓶颈,同时将按时间顺序排列的信息保持在可调的范围内(箱数是一个可调的超参数)。
- 聚合层 (AGG) — 最后一层组合元数据信息(游戏主题类型、机柜类型、位置)以生成优先级概率预测。它由多个池化层和用于增量缩小维度的完全连接层组成。元数据的多热嵌入也是可学习的,不能通过 CNN 和 TRANS 层,因为它们不包含顺序信息。
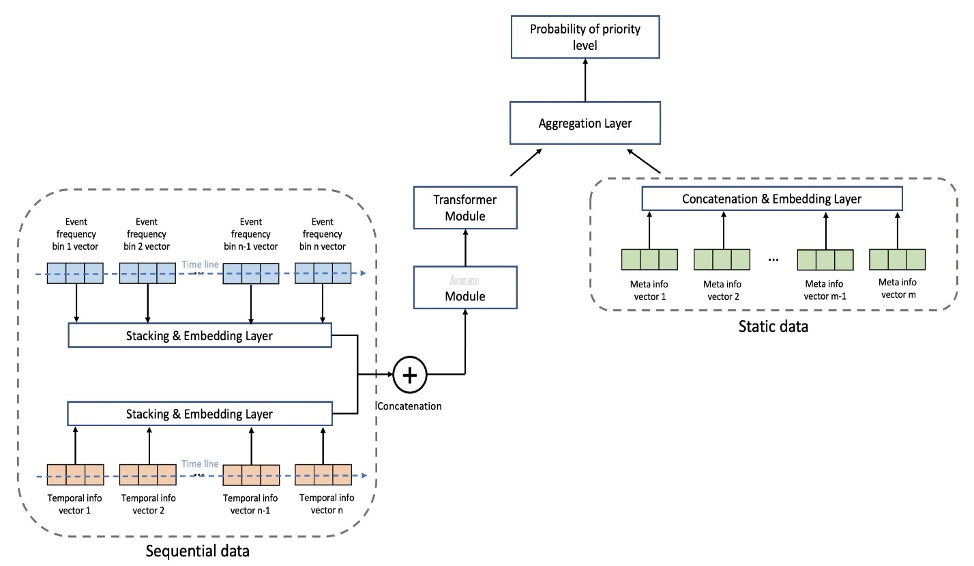
我们使用具有类别权重的交叉熵损失作为可调超参数来调整类别不平衡问题。此外,CNN 和 TRANS 层的数量是关键的超参数,可能的值为 0,这意味着模型架构中可能并不总是存在特定的层。这样,我们就有了统一的框架,可以在其中搜索模型架构以及其他常用的超参数。
我们利用 SageMaker 自动模型调整(也称为超参数优化 (HPO))来有效地探索模型变化和所有超参数的庞大搜索空间。自动模型调整接收自定义算法、训练数据和超参数搜索空间配置,并使用不同的策略(例如贝叶斯、超频带等)在多个 GPU 实例并行运行的情况下搜索最佳超参数。在评估了抵制验证集之后,我们获得了具有两层 CNN、一层具有四个头的 TRANS 层和一个 AGG 层的最佳模型架构。
我们使用以下超参数范围来寻找最佳的模型架构:
为了进一步提高模型准确性并减少模型方差,我们使用多个独立的随机权重初始化来训练模型,并将结果与平均值聚合在一起,作为最终的概率预测。在更多的计算资源和更好的模型性能之间需要权衡,我们观察到,在当前用例中,5—10 应该是一个合理的数字(结果将在本文后面显示)。
模型性能结果
在本节中,我们将介绍模型性能评估指标和结果。
评估指标
精度对于这种预测性维护用例非常重要。低精度意味着报告更多的虚假维护呼叫,这会通过不必要的维护提高成本。由于平均精度 (AP) 与高精度目标不完全一致,我们引入了一项名为高精度平均召回率 (ARHP) 的新指标。ARHP 等于召回的平均值,分别为 60%、70% 和 80% 的精确度。我们还使用了顶部 K%(K=1、10)、AUPR 和 AU ROC 的精度作为附加指标。
结果
下表汇总了使用基线和自定义神经网络模型得出的结果,以 2022 年 7 月 1 日作为训练/测试分割点。实验表明,增加窗口长度和样本数据大小都可以提高模型性能,因为它们包含更多有助于预测的历史信息。无论数据设置如何,神经网络模型在所有指标上的表现都优于 AutoGluon。例如,固定精度为80%的召回率提高了121%,如果使用神经网络模型,则可以快速识别出更多出现故障的机器。
| Model | Window length/Data size | AU ROC | AUPR | ARHP | Recall@Prec0.6 | Recall@Prec0.7 | Recall@Prec0.8 | Prec@top1% | Prec@top10% |
|---|---|---|---|---|---|---|---|---|---|
| AutoGluon baseline | 12H/500k | 66.5 | 36.1 | 9.5 | 12.7 | 9.3 | 6.5 | 85 | 42 |
| Neural Network | 12H/500k | 74.7 | 46.5 | 18.5 | 25 | 18.1 | 12.3 | 89 | 55 |
| AutoGluon baseline | 48H/1mm | 70.2 | 44.9 | 18.8 | 26.5 | 18.4 | 11.5 | 92 | 55 |
| Neural Network | 48H/1mm | 75.2 | 53.1 | 32.4 | 39.3 | 32.6 | 25.4 | 94 | 65 |
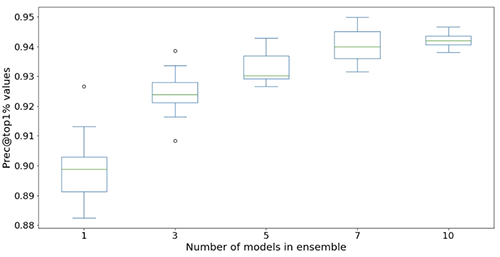
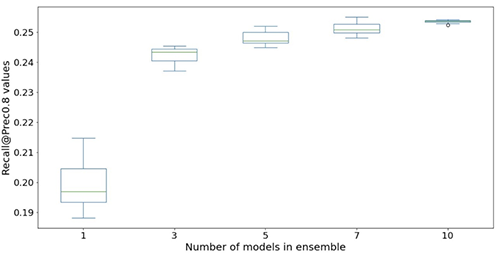
下图说明了使用集合来提高神经网络模型性能的效果。x 轴上显示的所有评估指标都得到了改进,均值更高(更准确),方差更低(更稳定)。每个箱形图来自 12 个重复实验,从无集合到集合中的 10 个模型(x 轴)。除了显示的 Prec @top1% 和 Recall @Prec80% 外,所有指标都存在类似的趋势。
在考虑了计算成本之后,我们发现集合中使用 5—10 个模型适合 Light & Wonder 数据集。
结论
我们的合作为游戏行业创建了开创性的预测性维护解决方案,以及可用于各种预测性维护场景的可重复使用框架。采用 SageMaker 自动模型调整等 亚马逊云科技 技术有助于 Light & Wonder 使用近乎实时的数据流抓住新机遇。Light & Wonder 已开始在 亚马逊云科技 上进行部署。
如果您想获得帮助,加快机器学习在产品和服务中的使用,请联系
作者简介
 Aruna Abeyakoon
是总部位于Light & Wonder Land的游戏部门的数据科学与分析高级总监。Aruna领导业界首个Light & Wonder Connect计划,为赌场合作伙伴和内部利益相关者提供消费者行为和产品见解,以制作更好的游戏、优化产品供应、管理资产以及健康监测和预测性维护。
Aruna Abeyakoon
是总部位于Light & Wonder Land的游戏部门的数据科学与分析高级总监。Aruna领导业界首个Light & Wonder Connect计划,为赌场合作伙伴和内部利益相关者提供消费者行为和产品见解,以制作更好的游戏、优化产品供应、管理资产以及健康监测和预测性维护。
 丹尼斯·科林
是全球领先的跨平台游戏公司Light & Wonder的高级数据科学经理。她是游戏数据与分析团队的成员,通过Light & Wonder Connect帮助开发创新解决方案,以改善产品性能和客户体验。
丹尼斯·科林
是全球领先的跨平台游戏公司Light & Wonder的高级数据科学经理。她是游戏数据与分析团队的成员,通过Light & Wonder Connect帮助开发创新解决方案,以改善产品性能和客户体验。
 Tesfagabir Meharizghi
是亚马逊 ML 解决方案实验室的数据科学家,在那里他帮助游戏、医疗保健和生命科学、制造业、汽车、体育和媒体等各行各业的 亚马逊云科技 客户加速使用机器学习和 亚马逊云科技 云服务来解决他们的业务挑战。
Tesfagabir Meharizghi
是亚马逊 ML 解决方案实验室的数据科学家,在那里他帮助游戏、医疗保健和生命科学、制造业、汽车、体育和媒体等各行各业的 亚马逊云科技 客户加速使用机器学习和 亚马逊云科技 云服务来解决他们的业务挑战。
 Mohamad Aljazaery
是亚马逊机器学习解决方案实验室的应用科学家。他帮助 亚马逊云科技 客户识别和构建 ML 解决方案,以应对他们在物流、个性化和推荐、计算机视觉、欺诈预防、预测和供应链优化等领域的业务挑战。
Mohamad Aljazaery
是亚马逊机器学习解决方案实验室的应用科学家。他帮助 亚马逊云科技 客户识别和构建 ML 解决方案,以应对他们在物流、个性化和推荐、计算机视觉、欺诈预防、预测和供应链优化等领域的业务挑战。
 王亚伟
是亚马逊机器学习解决方案实验室的应用科学家。他帮助 亚马逊云科技 业务合作伙伴识别和构建 ML 解决方案,以应对其组织在现实场景中面临的业务挑战。
王亚伟
是亚马逊机器学习解决方案实验室的应用科学家。他帮助 亚马逊云科技 业务合作伙伴识别和构建 ML 解决方案,以应对其组织在现实场景中面临的业务挑战。
 周云
是亚马逊 ML 解决方案实验室的应用科学家,他在那里帮助研发,确保 亚马逊云科技 客户取得成功。他使用统计建模和机器学习技术为各个行业开发开创性的解决方案。他的兴趣包括生成模型和顺序数据建模。
周云
是亚马逊 ML 解决方案实验室的应用科学家,他在那里帮助研发,确保 亚马逊云科技 客户取得成功。他使用统计建模和机器学习技术为各个行业开发开创性的解决方案。他的兴趣包括生成模型和顺序数据建模。
 Panpan Xu
是 亚马逊云科技 亚马逊 ML 解决方案实验室的应用科学经理。她正在研究和开发机器学习算法,用于各种工业垂直领域的高影响力客户应用程序,以加速其人工智能和云的采用。她的研究兴趣包括模型可解释性、因果分析、人工智能和交互式数据可视化。
Panpan Xu
是 亚马逊云科技 亚马逊 ML 解决方案实验室的应用科学经理。她正在研究和开发机器学习算法,用于各种工业垂直领域的高影响力客户应用程序,以加速其人工智能和云的采用。她的研究兴趣包括模型可解释性、因果分析、人工智能和交互式数据可视化。
 Raj Salvaji
领导 亚马逊云科技 酒店领域的解决方案架构。他通过提供战略指导和技术专长与酒店业客户合作,为复杂的业务挑战制定解决方案。他拥有在酒店、金融和汽车行业担任多个工程职位的25年的经验。
Raj Salvaji
领导 亚马逊云科技 酒店领域的解决方案架构。他通过提供战略指导和技术专长与酒店业客户合作,为复杂的业务挑战制定解决方案。他拥有在酒店、金融和汽车行业担任多个工程职位的25年的经验。
 Shane Rai
是 亚马逊云科技 亚马逊机器学习解决方案实验室的首席机器学习策略师。他与各行各业的客户合作,使用 亚马逊云科技 广泛的基于云的 AI/ML 服务来解决他们最紧迫和最具创新性的业务需求。
Shane Rai
是 亚马逊云科技 亚马逊机器学习解决方案实验室的首席机器学习策略师。他与各行各业的客户合作,使用 亚马逊云科技 广泛的基于云的 AI/ML 服务来解决他们最紧迫和最具创新性的业务需求。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。