我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
火箭公司如何在亚马逊云科技上实现数据科学解决方案的现代化
这篇文章由火箭公司的徐迪安和乔尔·霍金斯撰写。
Rocket Companies 是一家总部位于底特律的金融科技公司,其使命是"帮助所有人回家"。面对当前的住房短缺和可负担性问题,Rocket 通过直观和人工智能驱动的体验简化了房屋所有权流程。这个全面的框架简化了房屋所有权之旅的每一个步骤,使消费者能够毫不费力地搜索、购买和管理房屋融资。Rocket 将房屋搜索、融资和服务整合到一个环境中,提供无缝高效的体验。
Rocket 品牌是为复杂交易提供简单、快速和值得信赖的数字解决方案的代名词。Rocket 致力于帮助客户实现房屋所有权和财务自由的梦想。自成立以来,Rocket 已从一家单一的抵押贷款机构发展成为一个为客户创造新机会的业务网络。
Rocket 采用复杂的过程,并使用技术使其变得更简单。申请抵押贷款可能既复杂又耗时。这就是为什么我们使用先进的技术和数据分析来简化房屋所有权体验的每一个步骤,从申请到结算。通过分析各种数据点,我们能够快速准确地评估与贷款相关的风险,使我们能够做出更明智的贷款决策,为客户提供所需的融资。
我们在 Rocket 的目标是为我们当前和潜在的客户提供个性化的体验。Rocket 的多样化产品可以定制,以满足特定的客户需求,而我们熟练的银行家团队必须根据他们的技能和知识来匹配优秀的客户机会。与庞大而忠诚的客户群保持牢固的关系并对冲头寸以偿还财务义务是我们成功的关键。就我们的业务量而言,即使是微小的改进也可以产生重大影响。
在这篇文章中,我们分享了我们如何在亚马逊云科技上对 Rocket 的数据科学解决方案进行现代化改造,将交付速度从八周提高到不到一小时,通过在 18 个月内将事故单减少 99% 以上来提高运营稳定性和支持,为每天做出 1000 万个自动化数据科学和 AI 决策提供支持,并提供无缝的数据科学开发体验。
Rocket 的传统数据科学环境挑战
Rocket 之前的数据科学解决方案是围绕 Apache Spark 构建的,结合了传统版本的 Hadoop 环境和供应商提供的数据科学体验开发工具。Hadoop 环境托管在 Amazon EC2(Amazon Elastic Compute Cloud)服务器上,由 Rocket 的技术团队内部管理,而数据科学体验基础设施则在本地托管。这两个系统之间的通信是通过基于 Amazon PrivateLink 的 Kerberized Apache Livy (HTTPS) 连接建立的。
数据探索和模型开发是使用著名的机器学习(ML)工具进行的,例如 Jupyter 或 Apache Zeppelin 笔记本电脑。Apache Hive 用于为存储在 HDFS 中的数据提供表格界面,并与 Apache Spark SQL 集成。Apache HBase 被用来提供基于密钥的实时数据访问权限。模型训练和评分要么在 Jupyter 笔记本上进行,要么通过 Apache 的 Oozie 编排工具(Hadoop 实现的一部分)安排的作业进行。
尽管这种架构有好处,但 Rocket 还是面临着限制其有效性的挑战:
- 可访问性限制:数据湖存储在 HDFS 中,只能从 Hadoop 环境访问,这阻碍了与其他数据源的集成。这也导致了需要采集的数据积压。
- 数据科学家的学习曲线很艰难:Rocket 的许多数据科学家都没有使用 Spark 的经验,与 scikit-learn 等其他流行的机器学习解决方案相比,Spark 的编程模型更加细致入微。这给数据科学家提高工作效率带来了挑战。
- 维护和故障排除责任:Rocket 的 DevOps/技术团队负责安装在裸 EC2 实例上的 Hadoop 集群的所有升级、扩展和故障排除。这导致两家供应商的积压问题仍未解决。
- 平衡开发和生产需求:Rocket 必须管理开发和生产之间的工作队列,这些队列一直在争夺相同的资源。
- 部署挑战:Rocket 试图支持更多的实时推理和流媒体推理用例,但这受到了 mLeap 用于实时模型和用于流式传输用例的 Spark Streaming 的能力的限制,这两个用例当时仍处于试验阶段。
- 数据安全性和 DevOps 支持不足 — 先前的解决方案缺乏强大的安全措施,对数据科学工作的开发和运营的支持也很有限。
Rocket 的传统数据科学架构如下图所示。
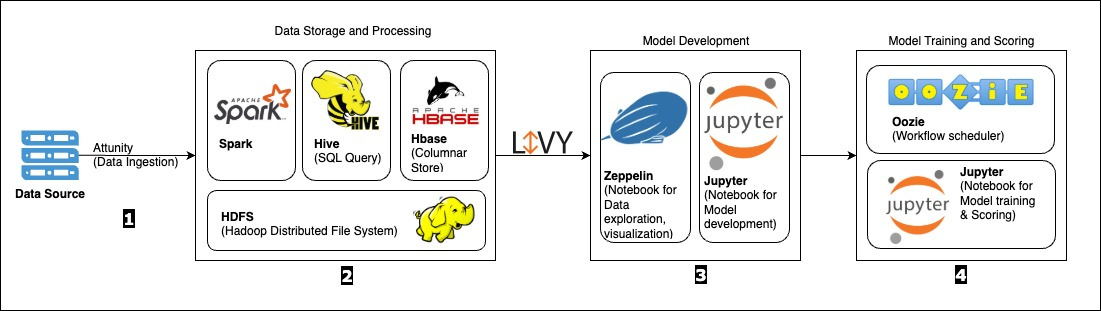
该图描绘了流程;关键组件详述如下:
- 数据提取:使用 Spark SQL 中的 Attunity 数据摄取将数据摄取到系统中。
- 数据存储和处理:所有计算都是使用 Apache Livy 和 Spark 在 Hadoop 集群内作为 Spark 任务完成的。数据存储在 HDFS 中,可通过 Hive 进行访问,Hive 提供数据表格界面并与 Spark SQL 集成。HBase 用于提供基于密钥的实时数据访问。
- 模型开发:使用 Jupyter 或 Orchestration 等工具进行数据探索和模型开发,这些工具通过 Kerberized Livy 连接与 Spark 服务器通信。
- 模型训练和评分:模型训练和评分要么通过 Jupyter 笔记本执行,要么通过 Apache 的 Oozie 编排工具(Hadoop 实现的一部分)安排的作业进行。
火箭的迁徙之旅
在 Rocket,我们相信持续改进的力量,并不断寻找新的机会。其中一个机会是使用数据科学解决方案,但要做到这一点,我们必须有一个强大而灵活的数据科学环境。
为了应对传统的数据科学环境挑战,Rocket 决定将其机器学习工作负载迁移到 Amazon SageMaker 人工智能套件。这将使我们能够提供更个性化的体验,更好地了解我们的客户。为了促进此次迁移的成功,我们与亚马逊云科技团队合作创建了自动化和智能的数字体验,展示了 Rocket 对客户的理解并保持了他们的联系。
我们实施了亚马逊云科技多账户策略,使用网络隔离的 Amazon VPC 在构建账户中建立了 Amazon SageMaker Studio。这使我们能够将开发和生产环境分开,同时也改善了我们的安全状况。
我们将新工作移至 SageMaker Studio,将传统的 Hadoop 工作负载移至 Amazon EMR,使用 Livy 和 SageMaker 笔记本连接到旧的 Hadoop 集群以简化过渡。这使我们能够获得更广泛的工具和技术,使我们能够为我们要解决的每个问题选择最合适的工具和技术。
此外,我们将数据从 HDFS 转移到 Amazon S3(Amazon Simple Storage Service),现在使用 Amazon Athena 和 Amazon Lake Formation 为生产数据提供适当的访问控制。这样可以更轻松地访问和分析数据,并将其与其他系统集成。该团队还通过 Amazon EKS(Amazon Elastic Kubernetes Service)提供安全的交互式集成,进一步改善了公司的安全状况。
SageMaker AI 在帮助我们的数据科学社区灵活地为每个问题选择最合适的工具和技术方面发挥了重要作用,从而缩短了开发周期,提高了模型精度。借助 SageMaker Studio,我们的数据科学家可以无缝开发、训练和部署模型,无需额外的基础设施管理。
由于这项现代化工作,SageMaker AI 使 Rocket 能够在火箭公司中扩展我们的数据科学解决方案,并使用中心辐射模型进行集成。SageMaker AI 能够自动预置和管理实例,这使我们能够专注于数据科学工作而不是基础设施管理,从而使生产中的模型数量增加了五倍,数据科学家的工作效率提高了 80%。
我们的数据科学家有权使用最合适的技术来解决眼前的问题,我们的安全立场也有所改善。Rocket 现在可以对数据和计算进行划分,也可以划分开发和生产。此外,我们能够使用 Amazon SageMaker 实验提供模型追踪和谱系,以及可通过 SageMaker 模型注册表和 Amazon SageMaker 功能商店发现的文物。所有数据科学工作现已迁移到 SageMaker 上,所有旧的 Hadoop 工作都已迁移到 Amazon EMR。
总体而言,SageMaker AI 通过构建更具可扩展性和灵活性的 ML 框架、减轻运营负担、提高模型准确性和加快部署时间,在支持 Rocket 的现代化之旅中发挥了关键作用。
成功的现代化使 Rocket 克服了我们以前的局限性,更好地支持我们的数据科学工作。我们得以改善安全态势,使工作更具可追溯性和可发现性,并让我们的数据科学家能够灵活地为每个问题选择最合适的工具和技术。这帮助我们更好地为客户提供服务并推动业务增长。
下图显示了 Rocket 在亚马逊云科技上的新数据科学解决方案架构。
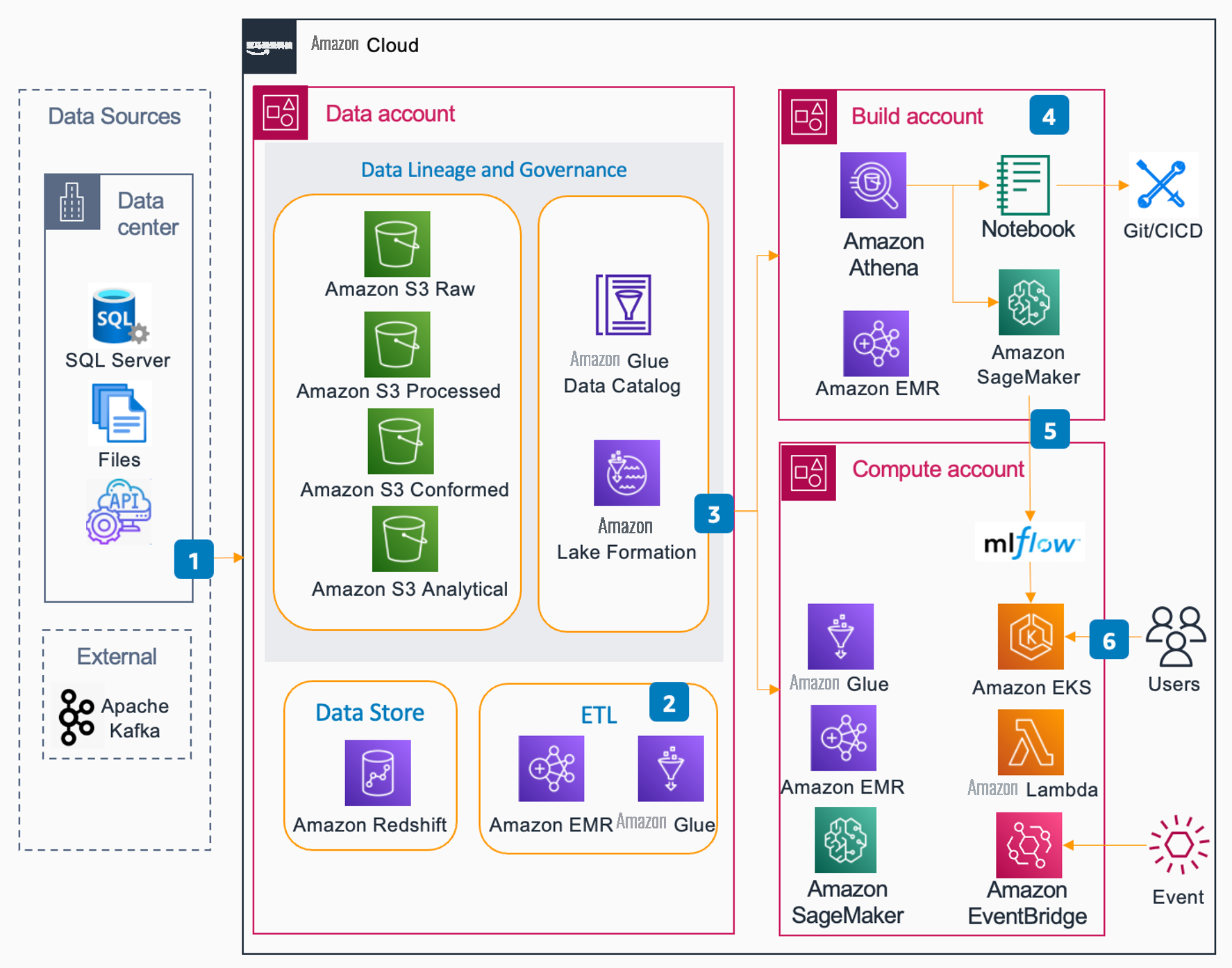
该解决方案由以下组件组成:
- 数据提取:数据从本地和外部来源摄取到数据账户。
- 数据优化:结合使用 Amazon Glue 提取、转换和加载 (ETL) 任务和 EMR 任务,将原始数据细化为可消耗层(原始、处理、一致和分析)。
- 数据访问:精炼后的数据注册在数据账户的 Amazon Glue 数据目录中,并通过 Lake Formation 向其他账户公开。分析数据存储在 Amazon Redshift 中。Lake Formation 向构建和计算账户提供这些数据。对于构建帐户,生产数据的访问权限仅限于只读。
- 开发:数据科学开发是使用 SageMaker 工作室完成的。数据工程开发是使用 Amazon Glue Studio 完成的。这两个学科都有权使用 Amazon EMR 进行 Spark 开发。数据科学家可以在构建账户中访问整个 SageMaker 生态系统。
- 部署:在构建账户中开发的 SageMaker 训练过的模型在 MLFlow 实例中注册。数据科学活动和数据工程活动的代码工件存储在 Git 中。部署启动作为 CI/CD 的一部分进行控制。
- 工作流程:我们有许多工作流程触发器。为了进行在线评分,我们通常使用带有 Istio 的 Amazon EKS 来提供面向外部的终端节点。我们有许多由 Amazon Lambda 函数启动的任务,这些任务又由计时器或事件触发。运行的流程可能包括 Amazon Glue ETL 作业、用于其他数据转换或模型训练和评分活动的 EMR 作业,或 SageMaker 管道和执行训练或评分活动的作业。
迁移影响
我们在实现基础设施和工作负载的现代化方面已经取得了长足的发展。我们开始了支持六个业务渠道和 26 种生产模式的旅程,还有数十种正在开发中。部署时间持续了几个月,需要一个由三名系统工程师和四名机器学习工程师组成的团队来保持一切平稳运行。尽管得到了我们内部 DevOps 团队的支持,但我们向供应商提出的待处理问题却达到了令人羡慕的 200 多个。
如今,我们正在为九个组织和 20 多个业务渠道提供支持,超过 210 种模型正在生产中,还有更多模型正在开发中。我们的平均部署时间从几个月缩短到几周——有时甚至缩短到几天!由于只有一名兼职机器学习工程师提供支持,我们向供应商提供的平均待处理问题几乎不存在。我们现在为 120 多名数据科学家、机器学习工程师和分析人员提供支持。我们的框架组合已扩展到包括 50% 的 SparkML 模型和各种其他机器学习框架,例如 PyTorch 和 scikit-learn。这些进步为我们的数据科学界提供了力量和灵活性,可以轻松处理更复杂和更具挑战性的项目。
下表比较了我们在迁移前后的一些指标。
| 迁移前 | 迁移后 | |
|---|---|---|
| 交货速度 | 新的数据摄取项目耗时 4—8 周 | 数据驱动的摄取不到一小时 |
| 操作稳定性和可支持性 | 18 个月内发生了一百多起事件和罚单 | 更少的事件:每 18 个月发生一起 |
| 数据科学 | 数据科学家将 80% 的时间花在等待工作运行上 | 无缝的数据科学开发体验 |
| 可扩展性 | 无法扩展 | 为每天做出 1000 万个自动化数据科学和 AI 决策提供支持 |
吸取的教训
在数据科学解决方案现代化的整个过程中,我们吸取了宝贵的经验教训,我们认为这些经验可以对计划开展类似工作的其他组织大有帮助。
首先,我们已经意识到,在优化数据科学运营方面,托管服务可以改变游戏规则。
将开发隔离到自己的账户中,同时提供生产数据的只读访问权限,这是使数据科学家能够在不给生产环境带来风险的情况下对模型进行实验和迭代的一种非常有效的方法。这是我们通过将 SageMaker AI 和 Lake Formation 相结合来实现的。
我们吸取的另一个教训是团队培训和入职的重要性。对于正在迁移到像 SageMaker AI 这样的新环境的团队来说尤其如此。了解利用 SageMaker AI 资源和功能的优秀实践,并对如何从笔记本转向工作有扎实的了解至关重要。
最后,我们发现,尽管 Amazon EMR 仍需要一些调整和优化,但与直接在 Amazon EC2 上托管相比,管理负担要轻得多。这使得 Amazon EMR 成为需要管理大型数据处理工作负载的组织更具扩展性和成本效益的解决方案。
结论
这篇文章概述了亚马逊云科技和火箭公司之间的成功合作伙伴关系。通过这种合作,Rocket Companies 得以迁移许多机器学习工作负载并实现可扩展的机器学习框架。Rocket Companies 继续与亚马逊云科技合作,致力于创新,始终站在客户满意度的最前沿。
不要让传统系统阻碍组织的潜力。了解亚马逊云科技如何帮助您实现数据科学解决方案现代化并取得与 Rocket Companies 类似的显著成果。
作者简介
 徐迪安是 Rocket Companies 数据工程高级总监,她领导变革性举措,以实现企业数据平台现代化并培养协作、数据优先的文化。在她的领导下,Rocket 的数据科学、人工智能和机器学习平台每年为数十亿次自动化决策提供动力,推动创新和行业颠覆。作为一代人工智能和云技术的热情倡导者,徐也是全球论坛上备受追捧的演讲者,激励了下一代数据专业人士。工作之余,她将自己对节奏的热爱融入舞蹈中,拥抱从宝莱坞到巴查塔的各种风格,以此来庆祝文化多样性。
徐迪安是 Rocket Companies 数据工程高级总监,她领导变革性举措,以实现企业数据平台现代化并培养协作、数据优先的文化。在她的领导下,Rocket 的数据科学、人工智能和机器学习平台每年为数十亿次自动化决策提供动力,推动创新和行业颠覆。作为一代人工智能和云技术的热情倡导者,徐也是全球论坛上备受追捧的演讲者,激励了下一代数据专业人士。工作之余,她将自己对节奏的热爱融入舞蹈中,拥抱从宝莱坞到巴查塔的各种风格,以此来庆祝文化多样性。
 乔尔·霍金斯是火箭公司的首席数据科学家,负责数据科学和 MLOps 平台。Joel 在开发复杂工具和处理大规模数据方面拥有数十年的经验。作为一名积极进取的创新者,他与数据科学团队携手合作,确保我们拥有最新技术来提供尖端解决方案。在业余时间,他是一名狂热的自行车手,并以涉足老式跑车修复而闻名。
乔尔·霍金斯是火箭公司的首席数据科学家,负责数据科学和 MLOps 平台。Joel 在开发复杂工具和处理大规模数据方面拥有数十年的经验。作为一名积极进取的创新者,他与数据科学团队携手合作,确保我们拥有最新技术来提供尖端解决方案。在业余时间,他是一名狂热的自行车手,并以涉足老式跑车修复而闻名。
 Venkata Santosh Sajjan Alla 是亚马逊云科技金融服务的高级解决方案架构师。他与 Rocket 等北美金融科技公司和其他金融服务组织合作,推动云和人工智能战略,加速大规模采用人工智能。凭借在人工智能和机器学习、生成式人工智能和云原生架构方面的深厚专业知识,他帮助金融机构开启新的收入来源,优化运营并推动有影响力的业务转型。Sajjan 与 Rocket Companies 密切合作,以推进其建立以人工智能为燃料的房屋所有权平台以帮助所有人回家的使命。工作之余,他喜欢旅行,与家人共度时光,并且是女儿的骄傲父亲。
Venkata Santosh Sajjan Alla 是亚马逊云科技金融服务的高级解决方案架构师。他与 Rocket 等北美金融科技公司和其他金融服务组织合作,推动云和人工智能战略,加速大规模采用人工智能。凭借在人工智能和机器学习、生成式人工智能和云原生架构方面的深厚专业知识,他帮助金融机构开启新的收入来源,优化运营并推动有影响力的业务转型。Sajjan 与 Rocket Companies 密切合作,以推进其建立以人工智能为燃料的房屋所有权平台以帮助所有人回家的使命。工作之余,他喜欢旅行,与家人共度时光,并且是女儿的骄傲父亲。
 阿拉克·埃斯瓦拉达斯是总部位于伊利诺伊州芝加哥的亚马逊云科技的首席解决方案架构师。她热衷于帮助客户使用亚马逊云科技服务设计云架构以解决业务挑战,并热衷于为亚马逊云科技客户解决各种机器学习用例。当她不工作时,阿拉克喜欢与女儿共度时光,也喜欢和狗一起探索户外活动。
阿拉克·埃斯瓦拉达斯是总部位于伊利诺伊州芝加哥的亚马逊云科技的首席解决方案架构师。她热衷于帮助客户使用亚马逊云科技服务设计云架构以解决业务挑战,并热衷于为亚马逊云科技客户解决各种机器学习用例。当她不工作时,阿拉克喜欢与女儿共度时光,也喜欢和狗一起探索户外活动。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。