我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
如何使用自定义运算符扩展 亚马逊云科技 Trainium 的功能
深度学习 (DL) 是一个快速发展的领域,从业者不断创新深度学习模型并发明加速这些模型的方法。自定义运算符是开发人员通过扩展 PyTorch 等现有机器学习 (ML) 框架的功能来突破 DL 创新的边界的机制之一。通常, 运算符 描述深度学习模型中图层的数学函数。 自定义运算符 允许开发人员为深度学习模型中的图层构建自己的数学函数。
接下来,暗示熟悉
PyTorch 中的自定义运算符及其优点
适用于 PyTorch 的 CustomOps 起源于 1.10 版,名为 PyTorch C++ 前端,它提供了一种易于使用的机制来注册用 C++ 编写的 CustomOps。以下是自定义操作提供的一些好处:
- 性能优化 — CustomOps 可以针对特定用例进行优化,从而加快模型运行速度并提高性能。
- 提高模型表现力 — 使用 CustomOps,你可以使用 PyTorch 提供的内置运算符来表达不容易表达的复杂计算。
- 增强模块化 — 您可以使用 CustomOps 作为构建模块,通过创建可重用组件的 C++ 库来创建更复杂的模型。这使开发过程更容易、更模块化,并便于快速实验。
- 提高灵活性 — CustomOps 支持内置运算符之外的操作,也就是说,它们提供了一种灵活的方式来定义未使用标准运算符实现的复杂操作。
Trainium 对自定义运算符的支持
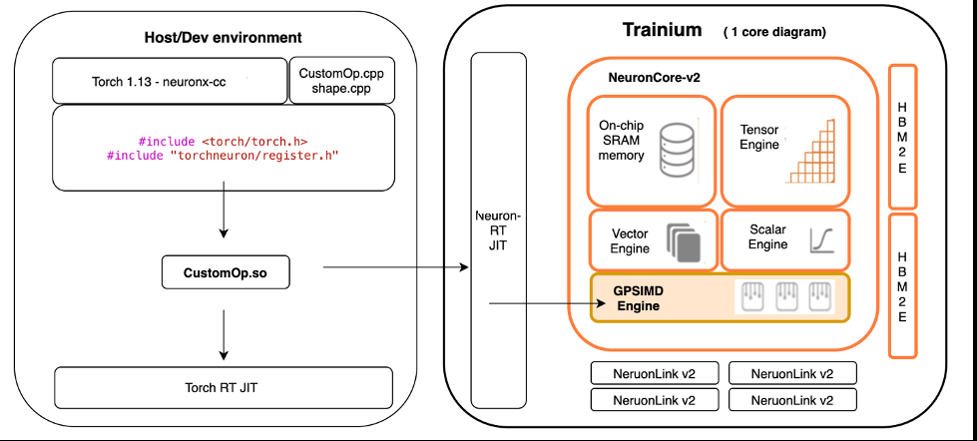
Trainium(和 亚马逊云科技 Inferentia2)通过 Neuron SDK 在软件中支持 CustomOps,并使用 GPSIMD 引擎(通用单指令多数据引擎)在硬件中加速这些操作。让我们来看看它们如何在开发和创新 DL 模型时实现高效的 CustomOps 实施并提供更高的灵活性和性能。
神经元 SDK
Neuron SDK 可帮助开发人员在 Trainium 上训练模型并在 亚马逊云科技 Inferentia 加速器上部署模型。它与 PyTorch 和 TensorFlow 等框架进行了原生集成,因此您可以继续使用现有的工作流程和应用程序代码在 Trn1 实例上训练模型。
Neuron SDK 使用适用于 CustomOps 的标准 PyTorch 接口。开发人员可以使用 PyTorch 中的标准编程接口用 C++ 编写 CustomOps 并扩展 Neuron 的官方运算符支持。然后,Neuron 编译这些 CustomOps 以在 GPSIMD 引擎上高效运行,下一节将对此进行更详细的介绍。这样可以轻松实现新的实验性 CustomOps,并在专用硬件上对其进行加速,而无需对此底层硬件一无所知。
通用单指令多数据引擎
Trainium 优化的核心是 NeuronCore 架构,这是一个完全独立的异构计算单元,具有四个主引擎:张量、向量、标量和 GPSIMD 引擎。标量和向量引擎高度并行化,并针对浮点运算进行了优化。张量引擎基于功率优化的系统数组,支持混合精度计算。
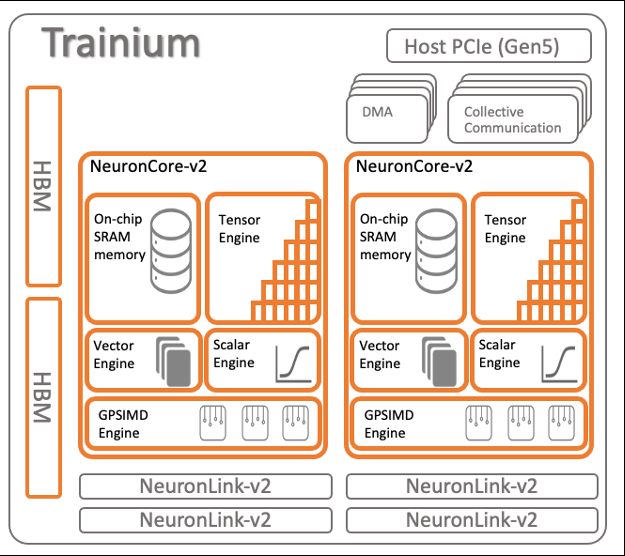
GPSIMD 引擎是一种通用的单指令多数据 (SIMD) 引擎,专为运行和加速 CustomOps 而设计。该引擎由八个完全可编程的 512 位宽通用处理器组成,这些处理器可以运行直线 C 代码,并可以直接在线访问其他 NeuronCore-v2 引擎以及嵌入式 SRAM 和 HBM 存储器。这些功能共同帮助在 Trainium 上高效运行自定义操作。
以诸如 TopK、LayerNorm 或 ZeroCompressiment 之类的运算符为例,它们从内存中读取数据,并且仅将其用于最少数量的 ALU 计算。常规 CPU 系统完全受内存限制,用于这些计算,性能受到将数据移入 CPU 所需的时间的限制。在 Trainium 中,GP-SIMD 引擎使用高带宽流接口与片上缓存紧密耦合,该接口可以维持 2 TB/sec 的内存带宽。因此,像这样的自定义操作可以在 Trainium 上非常快速地运行。
实践中的 Neuron SDK 自定义运算符
在这篇文章中,我们假设使用 DLAMI(参阅
与 PyTorch 与 C++ 代码集成的过程类似,Neuron CustomOps 需要通过 NeuronCore 移植的 Torch C++ API 子集实现 C++ 运算符。运算符的 C++ 实现称为
内核函数
,C++ API 的端口包含自定义操作开发和模型集成所需的所有内容,特别是
orch.h
标头,这样你才能访问由 Neuroncore 移植的 Pytorch C++ API 子集:
Neuron CustomOps 还需要 形状函数 。 形状函数与内核函数具有相同的函数签名,但不执行任何计算。它仅定义输出张量的形状,而不定义实际值。
Neuron CustomOps 被分组到库中,使用宏从形状函数中将它们注册到 NE
URON_LIBRARY
作用域中。该函数将在编译时在主机上运行,并且需要 torchneuron 库中的
register.h
标头:
最后,通过调用 load API 来构建自定义库。如果提供
build_directory 参数,则库文件将存储在指定的目录
中:
要使用来自 PyTorch 模型的 customOp,只需通过调用 lo
ad_
library API 加载库,然后像在 PyTorch 中通过 torch.ops 命名空间调用 CustomOp 一样调用 Neuron CustomOp 即可。格式通常为
torch.ops。
请注意,cu
stom_op.load API 构建 C++ 库,而 cust
已经构建的库文件。
om_op.load_lib
rary API 会加载
示例:MLP 训练中的 Neuron CustomOps
要开始使用,请执行以下步骤:
-
创建并启动您的 EC2 Trn1 实例。确保使用 DLAMI 映像(
Ubuntu 或亚马逊 Linux ,预先安装了所有必需的 Neuron 软件),并且已指定根卷大小为 512 GB。 - 在您的实例启动并运行后,通过 SSH 连接到您的实例。
-
在你正在运行的 Trn1 实例上安装 PyTorch Neuron(torch-neuronx)。有关说明,请参阅
MLP 训练中的 Neuron 自定义 C++ 运算符 。 -
从
GitHub 存储库 下载示例代码 。
现在您的环境已经设置完毕,请继续阅读这篇文章,我们将介绍在 Neuron 中实现典型的 C++ CustomOp,其形式为 Relu 向前和向后函数,用于简单的多层感知器 (MLP) 模型。
存储库中的示例代码显示了两个文件夹:
- 。/customop_mlp/PyTorch — 包含将为 CP U 编译的 Relu 代码
- 。/customop_mlp/neuron — 包含将为 Tra inium 编译的 Relu 代码
开发 Neuron CustomOp:内核函数
用于开发内核函数(Neuron CustomOp)的主机或开发环境可以在 Linux 环境中运行 PyTorch 1.13 和兼容 C++17 的编译器。这与为 PyTorch 开发任何 C++ 函数相同,开发环境中唯一需要存在的库是用于 PyTorch 和 C++ 的库。在以下示例中,我们使用自定义 Relu 向前和向后函数创建了一个 relu.cpp 文件:
在开发适用于 Neuron 的 Neuron CustomOp 时,请务必考虑当前支持的功能和 API。有关更多信息,请参阅
生成并注册 Neuron customOp:形状函数
Neuron customOp 和运行时环境的构建是将在其中进行训练的 Trn1 实例,Neuron CustomOp 将被编译并注册为神经元-cc 库,并由 Neuron 运行时解释为在高度优化的 GP-SIMD 引擎上运行。
要构建和注册 Neuron CustomOp,我们需要创建一个形状函数 (
参见以下代码:
shape.cpp
) 来定义输入和输出张量并注册运算符:relu_fwd_shape 和
relu
_bwd_shape 函数。
relu_fwd_shap
e 和
relu_bwd_shap
e 函数定义输出张量的形状(大小与输入张量相同)。然后我们在 NE
URON_
LIBRARY 范围内注册这些函数。
在
.
/customop_ml/ 神经元存储库示例,我们有一个 build.py 脚本可以运行 CustomOp 的构建和注册,只需从 torch_neuronx.xla_impl 包中调用加载函数即可:
在 b
uild_directory 中
,
我们应该找到
librelu.so
库,可以加载并用于训练我们的模型。
使用 Neuron CustomOp 构建 MLP 模型
在本节中,我们将介绍使用 Neuron CustomOp 构建 MLP 模型的步骤。
定义 Relu 类
有关如何训练 MLP 模型的详细说明,请参阅
在构建 CustomOp 之后,我们创建了一个名为
my_ops.py 的
Python 包 ,在其中定义了一个继承自 torch autograd 函数的 Relu PyTorch 类。autograd 函数实现了自动微分,因此可以在训练循环中使用。
首先我们加载 librelu.so 库,然后使用静态方法装饰器定义的前向和向后函数定义新类。这样,当我们定义模型时,可以直接调用这些方法。参见以下代码:
检查 MLP 模型
现在,我们可以通过导入定义了 Relu 类的
my_ops
包,使用 Neuron CustomOp 编写多层感知器模型了:
运行训练脚本
现在我们可以使用
train.py
提供的脚本来训练我们的模型:
通过将模型发送到 xla 设备,模型和 Relu 自定义运算符被编译为由 Neuron 运行时使用优化的 Trainium 硬件运行。
在此示例中,我们展示了如何创建利用 Trainium ML 加速器芯片上可用的硬件引擎 (GP-SIMD) 的自定义 Relu 运算符。结果是一个经过训练的 PyTorch 模型,现在可以部署该模型进行推理。
结论
现代最先进的模型架构需要越来越多的资源,从工程人员(数据科学家、机器学习工程师、mLOP 工程师等)到包括存储、计算、内存和加速器在内的实际基础架构。这些要求增加了开发和部署深度学习模型的成本和复杂性。Trainium 加速器为云端深度学习训练提供高性能、低成本的解决方案。Neuron SDK 促进了 Trainium 的使用,其中包括深度学习编译器、运行时以及原生集成到 PyTorch 和 TensorFlow 等流行框架中的工具。(请注意,在撰写本文时,Neuron SDK 2.9 仅支持 PyTorch 用于开发自定义运算符。)
如本文所示,Trainium 不仅提供了高性能、高效地训练模型的方法,还提供了自定义操作员的能力,以增加训练和实验的灵活性和表现力。
有关更多信息,请参阅
作者简介
 Lorea Arrizabalaga
是一名隶属于英国公共部门的解决方案架构师,她帮助客户使用亚马逊 SageMaker 设计机器学习解决方案。她还是致力于硬件加速的技术领域社区的一员,并帮助对 亚马逊云科技 Inferentia 和 亚马逊云科技 Trainium 工作负载进行测试和基准测试。
Lorea Arrizabalaga
是一名隶属于英国公共部门的解决方案架构师,她帮助客户使用亚马逊 SageMaker 设计机器学习解决方案。她还是致力于硬件加速的技术领域社区的一员,并帮助对 亚马逊云科技 Inferentia 和 亚马逊云科技 Trainium 工作负载进行测试和基准测试。
 Shruti Koparkar
是 亚马逊云科技 的高级产品营销经理。她帮助客户探索、评估和采用 Amazon EC2 加速计算基础设施以满足其机器学习需求。
Shruti Koparkar
是 亚马逊云科技 的高级产品营销经理。她帮助客户探索、评估和采用 Amazon EC2 加速计算基础设施以满足其机器学习需求。
 Ashley Miller
是亚马逊网络服务的高级人工智能/机器学习推广员,他与公共部门合作伙伴密切合作,在 亚马逊云科技 上开发 AI/ML 解决方案。
Ashley Miller
是亚马逊网络服务的高级人工智能/机器学习推广员,他与公共部门合作伙伴密切合作,在 亚马逊云科技 上开发 AI/ML 解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。