我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在 NFL 的《下一代统计数据》中确定防守保险计划
这篇文章是与国家橄榄球联盟的乔纳森·荣格、迈克·班德、迈克尔·奇和汤普森·布利斯共同撰写的。
保险计划
是指每位负责阻止进攻传球的足球后卫的规则和责任。它是理解和分析任何足球防守策略的核心。对每场传球比赛的报道方案进行分类将为球队、广播公司和球迷提供对足球比赛的见解。
NFL 的 Ne
在这篇文章中,我们深入探讨了这个机器学习模型的技术细节。我们描述了我们如何设计准确、可解释的机器学习模型,根据玩家追踪数据进行覆盖率分类,然后进行定量评估和模型解释结果。
问题表述和挑战
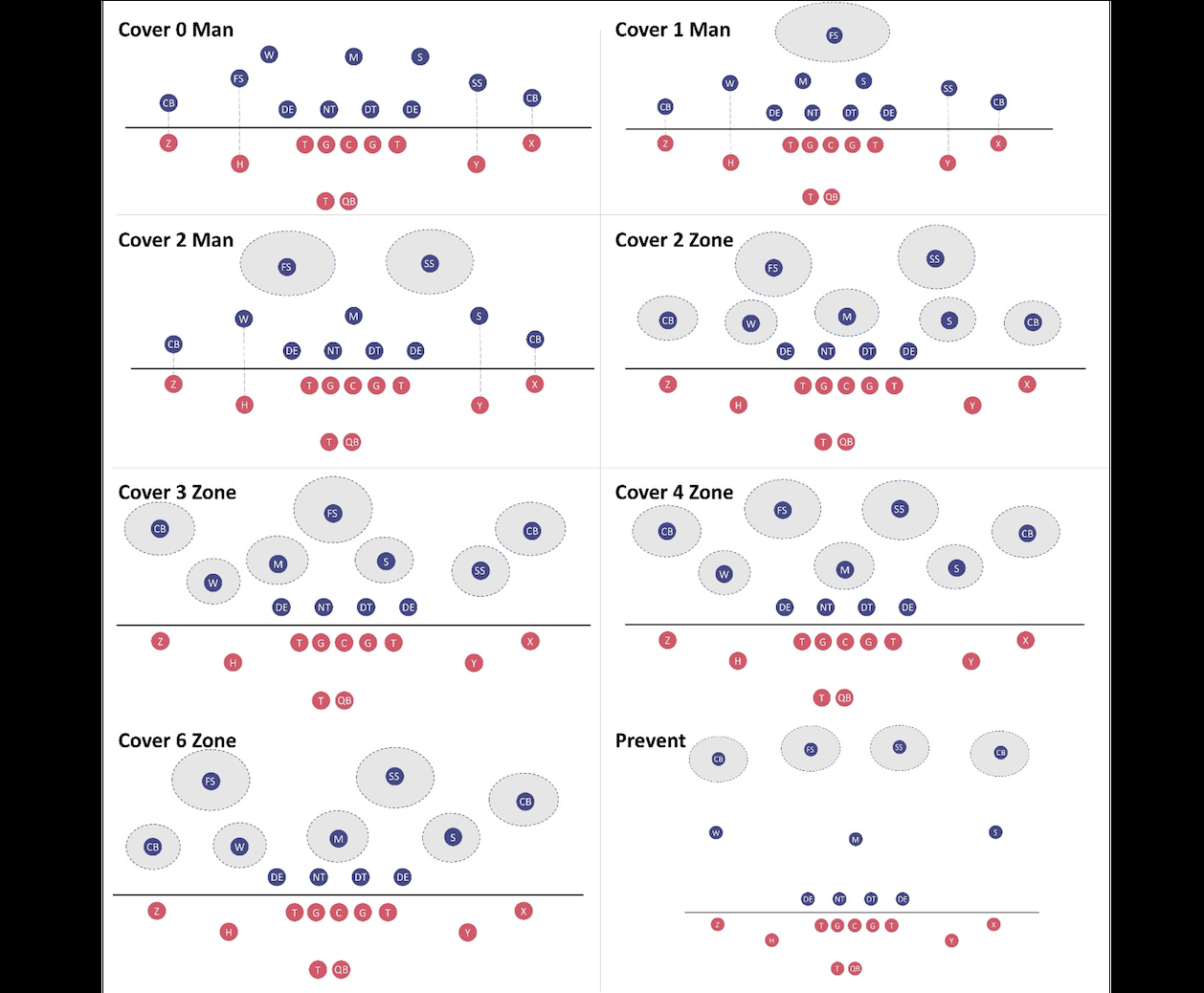
我们将防守覆盖分类定义为多职业分类任务,包括三种类型的人员覆盖(每位防守球员覆盖特定的进攻球员)和五种类型的区域覆盖(每位防守球员覆盖场上的特定区域)。下图直观地描绘了这八个职业:封面 0 人、封面 1 人、掩护 2 人、掩护 2 区域、掩护 3 区域、掩护 4 区域、掩护 6 区域和防御(也包括区域覆盖范围)。蓝色圆圈表示在特定类型的掩护中布局的防守球员;红色圆圈表示进攻型球员。本文末尾的附录中提供了玩家首字母缩略词的完整列表。
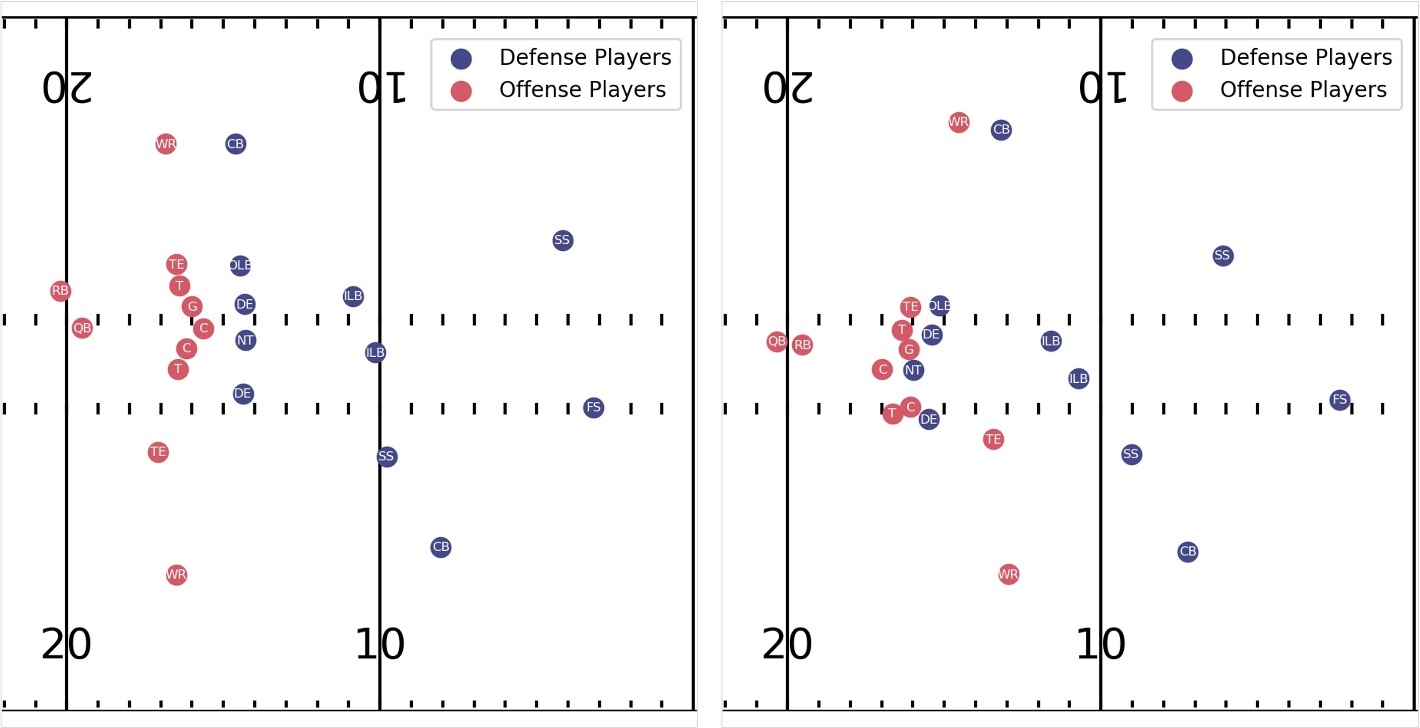
以下可视化显示了一场示例比赛,其中所有进攻和防守球员在比赛开始时(左)和同一场比赛的中间(右)的位置。为了正确识别掩护,必须考虑一段时间内的大量信息,包括防守者在快照前的排队方式以及球被抢断后对进攻球员移动的调整。这给模型带来了捕捉玩家之间的时空动作和互动的挑战,通常是微妙的动作和互动。
我们的合作伙伴关系面临的另一个关键挑战是部署的保险计划存在固有的模糊性。除了八种众所周知的保险计划外,我们还发现了对更具体的覆盖范围的调整,这会导致手工制图和模型分类的八个通用类别之间存在模棱两可之处。我们使用改进的训练策略和模型解释来应对这些挑战。我们在下一节中详细描述了我们的方法。
可解释的覆盖范围分类框架
我们在下图中说明了我们的整体框架,玩家追踪数据和覆盖标签的输入从图的顶部开始。
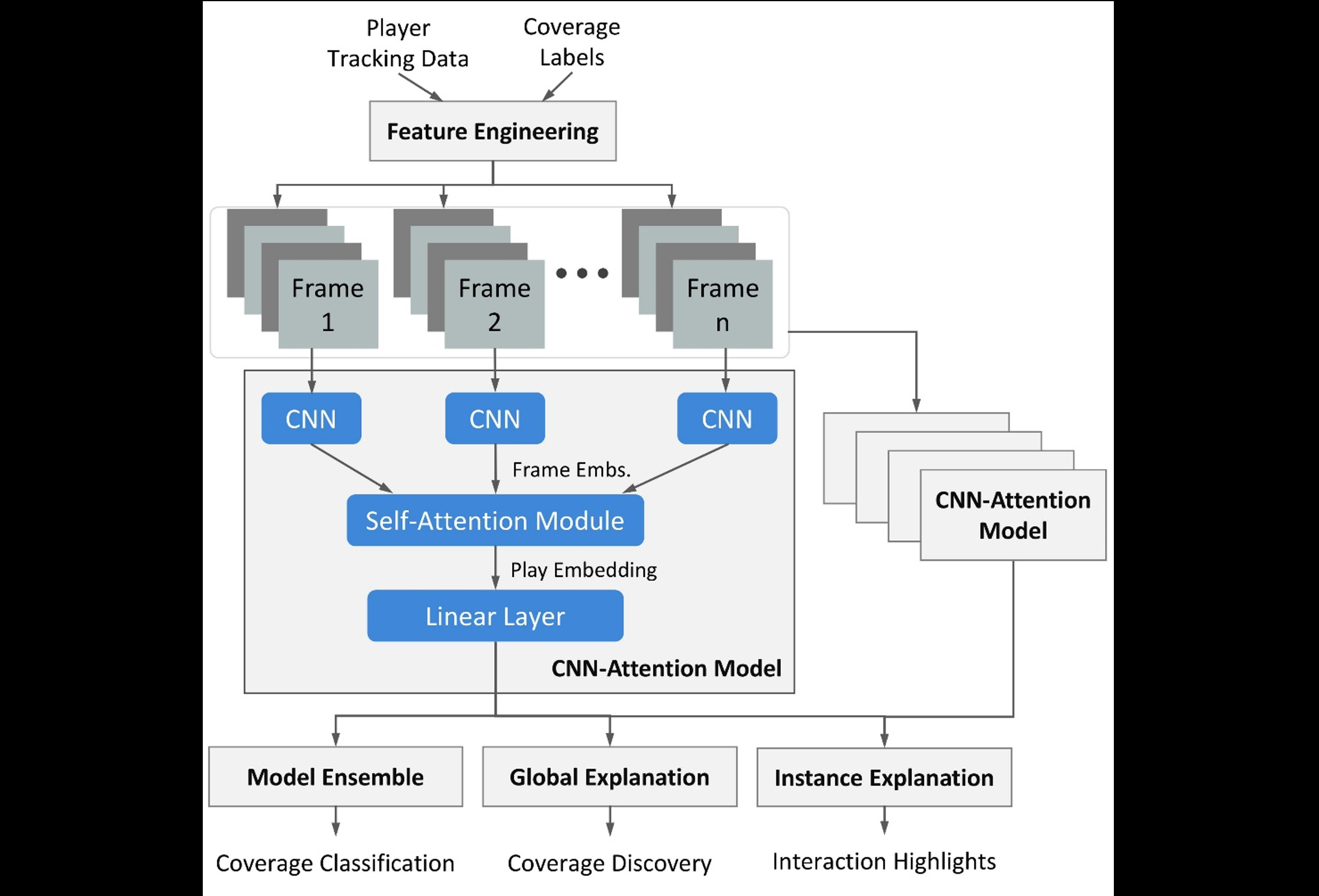
功能工程
游戏跟踪数据以每秒 10 帧的速度捕获,包括玩家的位置、速度、加速度和方向。我们的特征工程将游戏特征序列构造为模型消化的输入。对于给定框架,我们的功能受到 2020 年 Big Data Bowl Kaggle Zoo 解决方案的启发(G
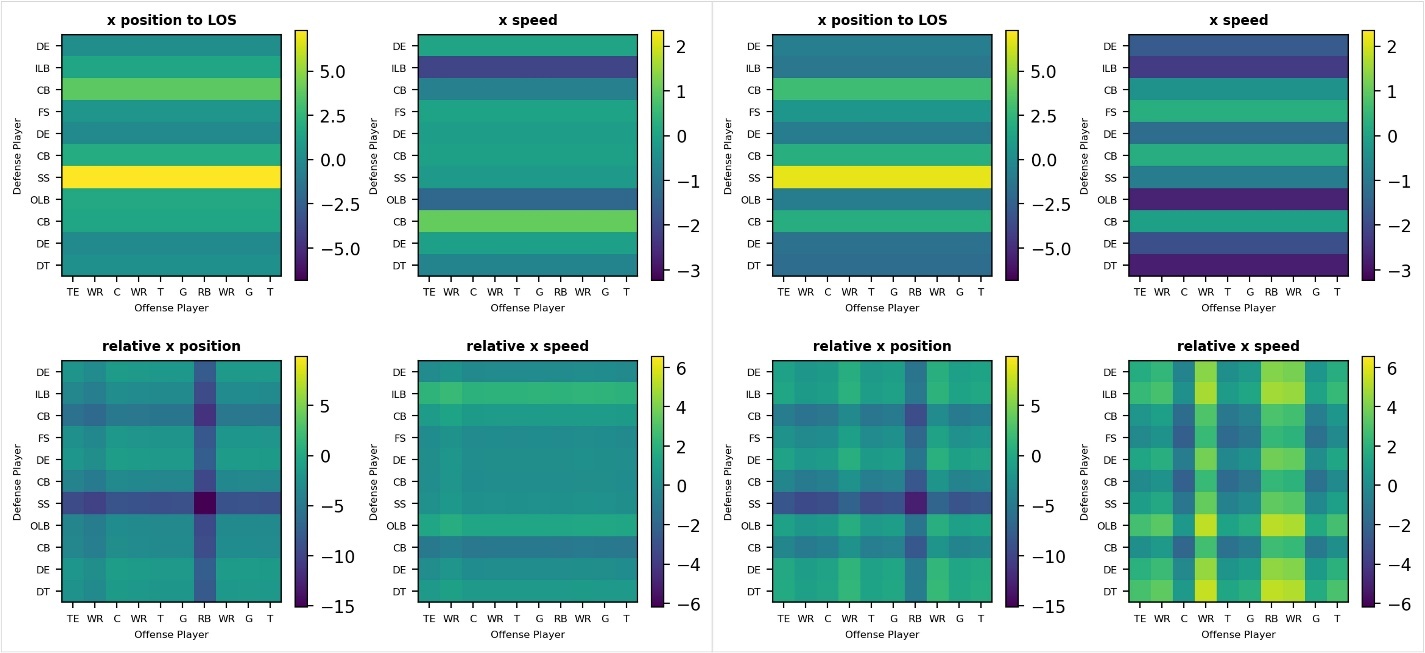
下图显示了这些功能如何随着时间的推移而演变,这与示例剧本的两张快照相对应。为了清晰起见,在提取的所有特征中,我们只显示了四个特征。图中的 “LOS” 代表混战线,x 轴表示足球场右边的水平方向。注意由颜色栏指示的特征值是如何随着时间的推移而演变的,与玩家的动作相对应。我们总共构造了两组功能,如下所示:
- 防守者特征包括防守者的位置、速度、加速度和方向,位于 x 轴(足球场右侧的水平方向)和 y 轴(通往足球场顶部的垂直方向)
- 防守-进攻相对特征由相同属性构成,但计算为防守型和进攻型球员之间的差异
CNN 模块
我们利用卷积神经网络 (CNN) 对复杂的玩家互动进行建模,类似于开源足球(
时态建模
在仅持续几秒钟的短暂播放时间内,它包含丰富的时间动态作为识别覆盖范围的关键指标。Zoo 解决方案中使用的基于帧的 CNN 建模(
模型集合和标签平滑处理
八种保险计划之间的模糊性及其分布的不平衡使得明确区分保险范围具有挑战性。在模型训练期间,我们利用模型集来应对这些挑战。我们的研究发现,基于投票的合奏是最简单的集合方法之一,其表现实际上优于更复杂的方法。在这种方法中,每个基础模型都具有相同的 CNN 注意力架构,并且独立于不同的随机种子进行训练。最终分类取所有基本模型输出的平均值。
我们进一步整合了标签平滑处理(
定量评估
我们使用2018—2020赛季数据进行模型训练和验证,使用2021赛季数据进行模型评估。每个赛季包含大约 17,000 场比赛。我们进行五重交叉验证以在训练期间选择最佳模型,并进行超参数优化以选择多模型架构和训练参数的最佳设置。
为了评估模型性能,我们计算了覆盖精度、F1 分数、top-2 精度以及更容易的人与区域任务的准确性。
| Model | Test Accuracy 8 Coverages (%) | Top-2 Accuracy 8 Coverages (%) | F1 Score 8 Coverages | Test Accuracy Man vs. Zone (%) |
| Baseline: Zoo model | 68.8±0.4 | 87.7±0.1 | 65.8±0.4 | 88.4±0.4 |
| CNN-LSTM | 86.5±0.1 | 93.9±0.1 | 84.9±0.2 | 94.6±0.2 |
| CNN-attention | 87.7±0.2 | 94.7±0.2 | 85.9±0.2 | 94.6±0.2 |
| Ours: Ensemble of 5 CNN-attention models | 88.9±0.1 | 97.6±0.1 | 87.4±0.2 | 95.4±0.1 |
我们观察到,加入时态建模模块可以显著改善基于单帧的基线 Zoo 模型。与CNN-LSTM模型的强大基线相比,我们提出的建模组件,包括自我注意力模块、模型集合和标签平滑相结合,可以显著提高性能。如评估措施所示,最终模型性能良好。此外,我们还发现前2名精度非常高,与前1名精度存在显著差距。这可以归因于覆盖范围的含糊性:当顶级分类不正确时,第二个猜测通常与人工注释相匹配。
模型解释和结果
为了阐明覆盖范围的模糊性并了解模型使用什么来得出给定结论,我们使用模型解释进行分析。它由两部分组成:全局解释,用于共同分析所有学习的嵌入,以及放大各个剧本以分析模型捕获的最重要信号的局部解释。
全球解释
在此阶段,我们将分析全球覆盖分类模型中学到的游戏嵌入信息,以发现任何需要手动审查的模式。
有些剧本混入了其他报道类型,如下图(右)所示。这些剧本可能会贴错标签,值得人工检查。我们设计了一个 K-Nearest Neighbors (KNN) 分类器来自动识别这些剧本并将其发送给专家审查。结果表明,其中大多数的标签确实不正确。
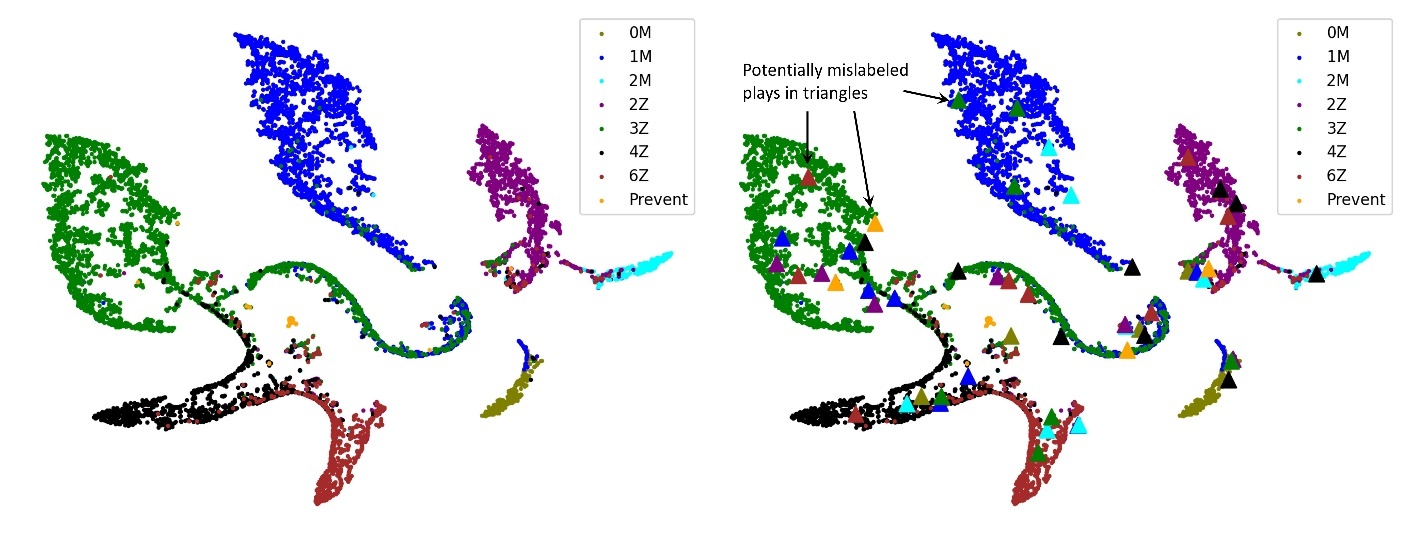
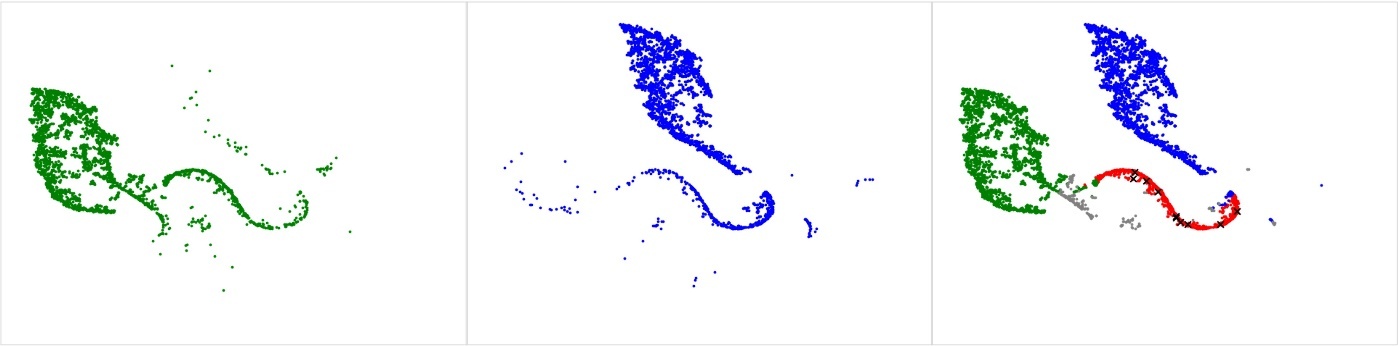
接下来,我们观察到覆盖类型之间有几个重叠区域,这在某些场景中表现出覆盖范围的模糊性。例如,在下图中,我们将封面 3 区域(左边的绿色群集)和 Cover 1 Man(中间的蓝色群集)分开。这是两种不同的单高覆盖概念,其主要区别在于人为覆盖率和区域覆盖率。我们设计了一种算法,可以自动将这两个类别之间的歧义识别为集群的重叠区域。结果可视化为下图中的红点,随机抽样的 10 场比赛标有黑色 “x” 以供手动查看。我们的分析表明,该地区的大多数游戏示例都涉及某种模式匹配。在这些比赛中,覆盖责任取决于进攻接球手路线的分布方式,调整可以使比赛看起来像区域和人员覆盖的混合体。我们确定的其中一项调整适用于掩护 3 区域,即一侧的角卫(CB)被锁定在人员覆盖范围内(“Man Everywhere He Goes” 或 MEG),而另一侧的角卫(CB)则是传统的区域掉落。
实例解释
在第二阶段,实例解释放大了感兴趣的个人游戏,并逐帧提取对已确定的覆盖方案贡献最大的玩家互动亮点。这是通过引导 GradCam 算法实现的(
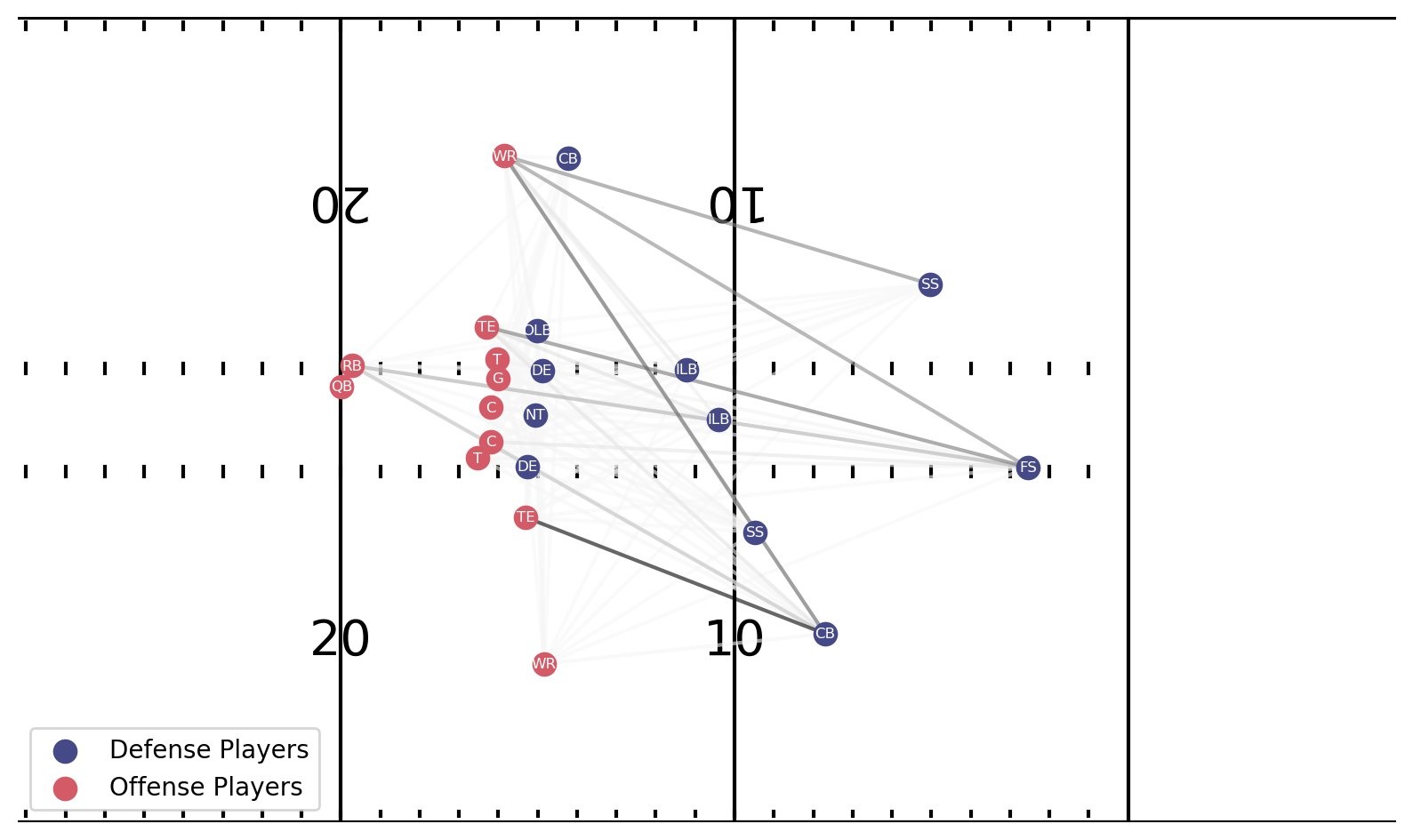
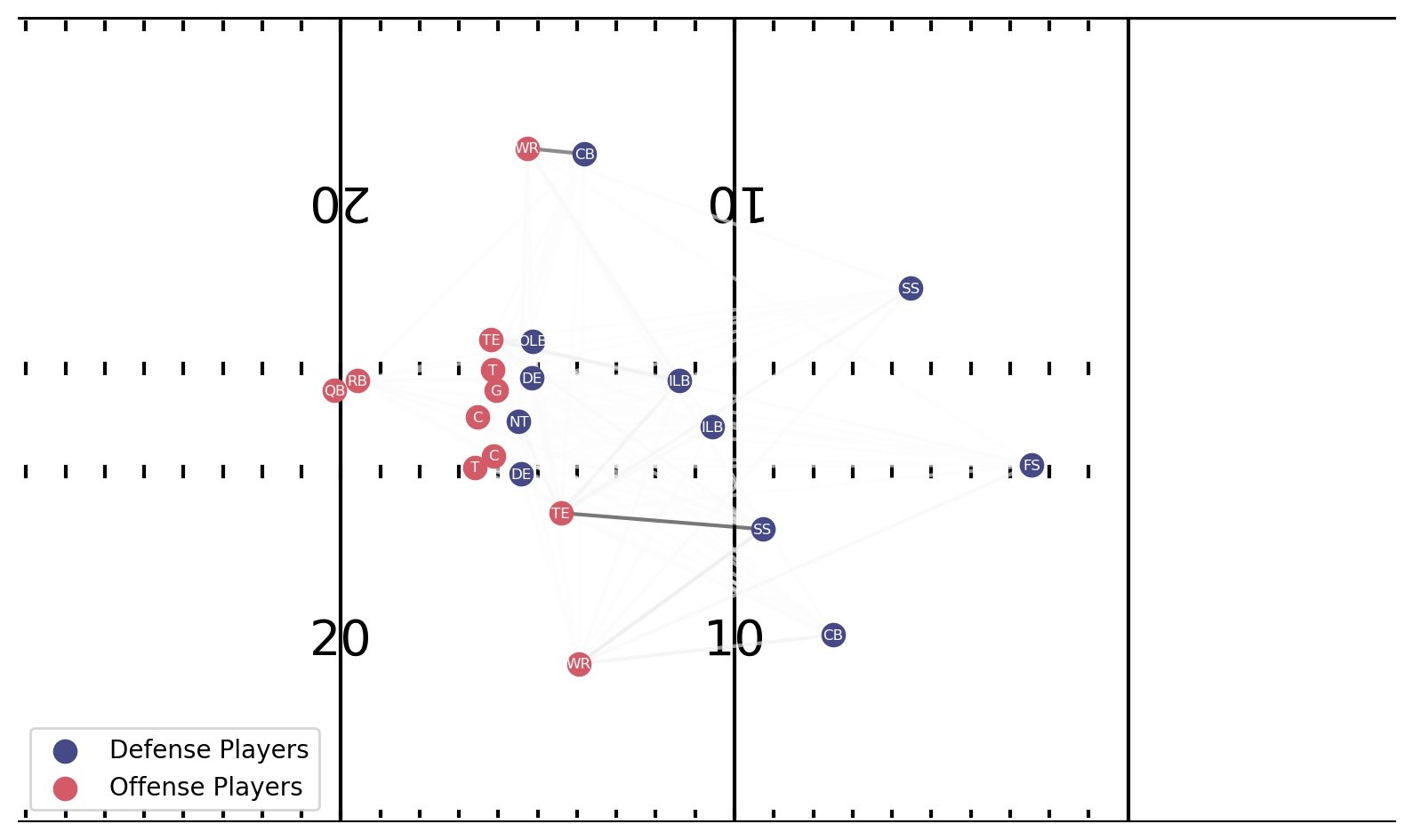
对于我们在文章开头说明的剧本,该模型预测封面3区的概率为44.5%,封面1人的概率为31.3%。我们为这两个类生成解释结果,如下图所示。线的厚度注释了有助于模型识别的相互作用强度。
Cover 3 Zone 解释的顶部情节是在球破裂之后出现的。进攻方右侧的 CB 拥有最强的互动线,因为他正面对 QB 并保持原位。他最后对准了身边的接球手,后者对他构成了深深的威胁。
Cover 1 Man 解释的底部情节是在片刻之后出现的,因为游戏动作假冒正在发生。最强的互动之一是与进攻方左边的 CB,后者正在与 WR 一起掉落。播放画面显示,他一直盯着 QB,然后四处转动,与正在深度威胁他的 WR 一起奔跑。进攻方右侧的党卫军也与他身边的 TE 有着强烈的互动,因为当 TE 突破内部时,他开始洗牌。他最终跟着他穿过阵型,但是 TE 开始封锁他,这表明这场比赛很可能是跑步传球选项。这解释了模型分类的不确定性:TE 在设计上坚持使用 SS,从而在数据中造成偏差。
结论
亚马逊 ML 解决方案实验室和 NFL 的下一代统计团队共同开发了防守覆盖分类统计数据,该统计数据最近
该解决方案首次向游戏中的广播公司提供了实时防御报道的趋势和分裂。同样,该模型使美国国家橄榄球联盟能够改进对赛后结果的分析,更好地识别比赛前的关键对决。
如果您想获得帮助,加快机器学习的使用,请联系
附录
| Player position acronyms | |
| Defensive positions | |
| W | “Will” Linebacker, or the weak side LB |
| M | “Mike” Linebacker, or the middle LB |
| S | “Sam” Linebacker, or the strong side LB |
| CB | Cornerback |
| DE | Defensive End |
| DT | Defensive Tackle |
| NT | Nose Tackle |
| FS | Free Safety |
| SS | Strong Safety |
| S | Safety |
| LB | Linebacker |
| ILB | Inside Linebacker |
| OLB | Outside Linebacker |
| MLB | Middle Linebacker |
| Offensive positions | |
| X | Usually the number 1 wide receiver in an offense, they align on the LOS. In trips formations, this receiver is often aligned isolated on the backside. |
| Y | Usually the starting tight end, this player will often align in-line and to the opposite side as the X. |
| Z | Usually more of a slot receiver, this player will often align off the line of scrimmage and on the same side of the field as the tight end. |
| H | Traditionally a fullback, this player is more often a third wide receiver or a second tight end in the modern league. They can align all over the formation, but are almost always off the line of scrimmage. Depending on the team, this player could also be designated as an F. |
| T | The featured running back. Other than empty formations, this player will align in the backfield and be a threat to receive the handoff. |
| QB | Quarterback |
| C | Center |
| G | Guard |
| RB | Running Back |
| FB | Fullback |
| WR | Wide Receiver |
| TE | Tight End |
| LG | Left Guard |
| RG | Right Guard |
| T | Tackle |
| LT | Left Tackle |
| RT | Right Tackle |
参考文献
-
Tej Seth,Ryan Weisman,“PFF 数据研究:每支球队的保险计划独特性以及这对教练变动意味着什么”,https://www.pff.com/news/nfl-pff-data-study-coverage-scheme-uniqueness-for-each-team-and-what-that-means-for-coaching-changes -
本·鲍德温。“计算机视觉,使用 Torch for R 的 NFL 球员追踪数据:使用 CNN 进行报道分类。”
https://www.opensourcefootball.com/posts/2021-05-31-computer-vision-in-r-using-torch/ -
德米特里·戈尔德耶夫,菲利普·辛格。“动物园解决方案第一名。”
https://www.kaggle.com/c/nfl-big-data-bowl-2020/discussion/119400 - Vaswani、Ashish、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Lukasz Kaiser 和 Illia Polosukhin。“你只需要注意力。” 神经信息处理系统的进展 30 (2017)。
-
杰伊·阿拉玛“插图变形金刚。”
https://jalammar.github.io/illustrated-transformer/ - 穆勒、拉斐尔、西蒙·科恩布利斯和杰弗里·欣顿。“标签平滑何时有用?。”神经信息处理系统的进展 32(2019)。
- 范德马顿、劳伦斯和杰弗里·欣顿。“使用 t-SNE 对数据进行可视化。” 《机器学习研究杂志》 第 9 期,第 11 期(2008 年)。
-
Selvaraju、Ramprasaath R.、Michael Cogswell、Abhishek Das、Ramakrishna Vedantam、Devi Parikh 和 Dhruv Batra。“Grad-cam:通过基于梯度的定位来自深度网络的视觉解释。”在
IEEE 计算机视觉国际会议 论文
集中 ,pp。
618-626 。2017。
作者简介
 H uan Song
是亚马逊机器学习解决方案实验室的应用科学家,在那里他致力于为来自不同垂直行业的高影响力客户用例提供定制机器学习解决方案。他的研究兴趣是图神经网络、计算机视觉、时间序列分析及其工业应用。
H uan Song
是亚马逊机器学习解决方案实验室的应用科学家,在那里他致力于为来自不同垂直行业的高影响力客户用例提供定制机器学习解决方案。他的研究兴趣是图神经网络、计算机视觉、时间序列分析及其工业应用。
 Mohamad Al Jazaery
是亚马逊机器学习解决方案实验室的应用科学家。他帮助 亚马逊云科技 客户识别和构建 ML 解决方案,以应对他们在物流、个性化和推荐、计算机视觉、欺诈预防、预测和供应链优化等领域的业务挑战。在加入 亚马逊云科技 之前,他获得了西弗吉尼亚大学的硕士学位,并在美的担任计算机视觉研究员。工作之余,他喜欢足球和电子游戏。
Mohamad Al Jazaery
是亚马逊机器学习解决方案实验室的应用科学家。他帮助 亚马逊云科技 客户识别和构建 ML 解决方案,以应对他们在物流、个性化和推荐、计算机视觉、欺诈预防、预测和供应链优化等领域的业务挑战。在加入 亚马逊云科技 之前,他获得了西弗吉尼亚大学的硕士学位,并在美的担任计算机视觉研究员。工作之余,他喜欢足球和电子游戏。
 丁海波
是亚马逊机器学习解决方案实验室的资深应用科学家。他对深度学习和自然语言处理非常感兴趣。他的研究重点是开发新的可解释的机器学习模型,目标是使它们在解决现实问题时更加高效和值得信赖。他在犹他大学获得博士学位,在加入亚马逊之前,他曾在北美博世研究中心担任高级研究科学家。除了工作,他还喜欢远足、跑步和与家人共度时光。
丁海波
是亚马逊机器学习解决方案实验室的资深应用科学家。他对深度学习和自然语言处理非常感兴趣。他的研究重点是开发新的可解释的机器学习模型,目标是使它们在解决现实问题时更加高效和值得信赖。他在犹他大学获得博士学位,在加入亚马逊之前,他曾在北美博世研究中心担任高级研究科学家。除了工作,他还喜欢远足、跑步和与家人共度时光。
 Lin Lee Cheong
是 亚马逊云科技 亚马逊机器学习解决方案实验室团队的应用科学经理。她与战略性 亚马逊云科技 客户合作,探索和应用人工智能和机器学习来发现新见解并解决复杂问题。她获得了麻省理工学院的博士学位。工作之余,她喜欢阅读和远足。
Lin Lee Cheong
是 亚马逊云科技 亚马逊机器学习解决方案实验室团队的应用科学经理。她与战略性 亚马逊云科技 客户合作,探索和应用人工智能和机器学习来发现新见解并解决复杂问题。她获得了麻省理工学院的博士学位。工作之余,她喜欢阅读和远足。
 乔纳森·荣格
是美国国家橄榄球联盟的高级软件工程师。在过去的七年中,他一直在 Next Gen Stats 团队工作,帮助构建平台,从流式传输原始数据、构建微服务来处理数据,到构建暴露处理过的数据的 API。他曾与亚马逊机器学习解决方案实验室合作,为他们提供干净的数据供他们使用,并提供有关数据本身的领域知识。工作之余,他喜欢在洛杉矶骑自行车和在山脉徒步旅行。
乔纳森·荣格
是美国国家橄榄球联盟的高级软件工程师。在过去的七年中,他一直在 Next Gen Stats 团队工作,帮助构建平台,从流式传输原始数据、构建微服务来处理数据,到构建暴露处理过的数据的 API。他曾与亚马逊机器学习解决方案实验室合作,为他们提供干净的数据供他们使用,并提供有关数据本身的领域知识。工作之余,他喜欢在洛杉矶骑自行车和在山脉徒步旅行。
 迈克·班
德 是美国国家橄榄球联盟下一代统计研究与分析的高级经理。自2018年加入球队以来,他一直负责为球迷、NFL广播合作伙伴和32家俱乐部构思、开发和传播从球员追踪数据中获得的关键统计数据和见解。迈克拥有芝加哥大学分析学硕士学位、佛罗里达大学体育管理学士学位以及明尼苏达维京人队球探部门和佛罗里达鳄鱼足球招募部门的经验,为球队带来了丰富的知识和经验。
迈克·班
德 是美国国家橄榄球联盟下一代统计研究与分析的高级经理。自2018年加入球队以来,他一直负责为球迷、NFL广播合作伙伴和32家俱乐部构思、开发和传播从球员追踪数据中获得的关键统计数据和见解。迈克拥有芝加哥大学分析学硕士学位、佛罗里达大学体育管理学士学位以及明尼苏达维京人队球探部门和佛罗里达鳄鱼足球招募部门的经验,为球队带来了丰富的知识和经验。
 迈克尔·奇
是美国国家橄榄球联盟的高级技术总监,负责监督下一代统计和数据工程。他拥有伊利诺伊大学厄巴纳香槟分校的数学和计算机科学学位。迈克尔于 2007 年首次加入 NFL,主要专注于足球统计的技术和平台。在业余时间,他喜欢在户外与家人共度时光。
迈克尔·奇
是美国国家橄榄球联盟的高级技术总监,负责监督下一代统计和数据工程。他拥有伊利诺伊大学厄巴纳香槟分校的数学和计算机科学学位。迈克尔于 2007 年首次加入 NFL,主要专注于足球统计的技术和平台。在业余时间,他喜欢在户外与家人共度时光。
 汤普森·布利斯
是美国国家橄榄球联盟的足球运营经理、数据科学家。他于 2020 年 2 月开始在 NFL 担任数据科学家,并于 2021 年 12 月晋升为现任职位。他于 2019 年 12 月在纽约市哥伦比亚大学完成了数据科学硕士学位。2018 年,他在威斯康星大学麦迪逊分校获得物理学和天文学理学学士学位,辅修数学和计算机科学。
汤普森·布利斯
是美国国家橄榄球联盟的足球运营经理、数据科学家。他于 2020 年 2 月开始在 NFL 担任数据科学家,并于 2021 年 12 月晋升为现任职位。他于 2019 年 12 月在纽约市哥伦比亚大学完成了数据科学硕士学位。2018 年,他在威斯康星大学麦迪逊分校获得物理学和天文学理学学士学位,辅修数学和计算机科学。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。