文本和
语义搜索
引擎的兴起使电子商务和零售企业更容易为消费者进行搜索。由统一文本和图像提供支持的搜索引擎可以为搜索解决方案提供额外的灵活性。您可以同时使用文本和图像作为查询。例如,你的笔记本电脑中有一个包含数百张全家福的文件夹。你想快速找到一张你和你最好的朋友在你老房子的游泳池前拍的照片。你可以使用 “两个人站在游泳池前” 之类的对话语言作为查询,在统一的文本和图像搜索引擎中进行搜索。您无需在图片标题中使用正确的关键字即可执行查询。
亚马逊 OpenSearch
S ervice 现在支持
k-nn 索引的余弦
相似度指标。余弦相似度测量两个向量之间角度的余弦值,其中余弦角越小表示向量之间的相似度越高。利用余弦相似度,您可以测量两个向量之间的方向,这使其成为某些特定的语义搜索应用程序的不错选择。
对比语言图像预训练 (CLIP)
是一种对各种图像和文本对进行训练的神经网络。CLIP 神经网络能够将图像和文本投影到同一个
潜在空间
中 ,这意味着可以使用相似度衡量标准(例如余弦相似度)对它们进行比较。您可以使用 CLIP 将产品的图像或描述
编码
为
嵌
入内容,然后将其存储到 OpenSearch Service K-nn 索引中。然后,您的客户可以查询索引以检索他们感兴趣的产品。
你可以使用带有
亚马逊 S
ageMaker 的 CLIP 来进行编码。 Ama@@
zon SageMaker 无服务器
推理是一项专门构建的推理服务,可轻松部署和扩展机器学习 (ML) 模型。借助 SageMaker,您可以为开发和测试部署无服务器,然后在进入生产环境 时转向
实时推理
。SageMaker 无服务器可在空闲时间将基础架构缩减到 0,从而帮助您节省成本。这非常适合构建 POC,因为在开发周期之间会有很长的空闲时间。您也可以使用
亚马逊 SageMaker 批量 转换从大型
数据集中获得推论。
在这篇文章中,我们将演示如何使用带有 SageMaker 和 OpenSearch Service 的 CLIP 来构建搜索应用程序。该代码是开源的,托管在
GitHub
上 。
解决方案概述
OpenSearch 服务提供文本匹配和嵌入 k-nn 搜索。我们在这个解决方案中使用嵌入 k-nn 搜索。您可以使用图像和文本作为查询,从库存中搜索商品。实现这个统一的图像和文本搜索应用程序包括两个阶段:
-
k-nn 参考索引
— 在此阶段,您将通过 CLIP 模型传递一组语料库文档或产品图像,将其编码为嵌入式。文本和图像嵌入分别是语料库或图像的数字表示。你将这些嵌入保存到 OpenSearch 服务中的 k-nn 索引中。支持 k-nn 的概念是,嵌入空间中近距离存在相似的数据点。例如,文本 “一朵红花”、文本 “玫瑰” 和红玫瑰的图像是相似的,因此这些文本和图像嵌入在嵌入空间中彼此接近。
-
k-nn 索引查询
-这是应用程序的推理阶段。在此阶段,您将通过深度学习模型 (CLIP) 提交文本搜索查询或图像搜索查询,以将其编码为嵌入。然后,你使用这些嵌入来查询存储在 OpenSearch 服务中的参考 k-nn 索引。k-nn 索引从嵌入空间返回相似的嵌入。例如,如果你传递 “一朵红花” 的文本,它会将红玫瑰图像的嵌入作为相似项目返回。
下图说明了解决方案架构。
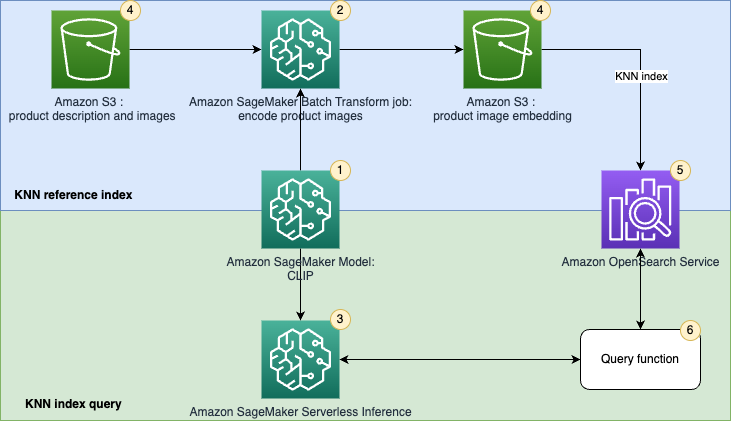
工作流程步骤如下:
-
使用预训练的
CLIP 模型 创建 SageMaker
模型,用于批量和实时推理。
-
使用 SageMaker 批量转换作业生成产品图像的嵌入内容。
-
使用 SageMaker 无服务器推断将查询图像和文本实时编码为嵌入内容。
-
使用
Amazon Simple Storage Servic e (Amazon S3) 存储
SageMaker 批量转换作业生成的原始文本(产品描述)、图像(产品图片)和图像嵌入。
-
使用 OpenSearch 服务作为搜索引擎来存储嵌入和查找相似的嵌入。
-
使用查询函数协调对查询的编码并执行 k-nn 搜索。
我们使用
亚马逊 SageMaker
Studio
笔记本电脑(未显示在图中)作为集成开发环境 (IDE) 来开发解决方案。
设置解决方案资源
要设置解决方案,请完成以下步骤:
-
创建 SageMaker 域和用户个人资料。有关说明,请参阅使用快速设置
登录 Amazon SageMaker 域名的
第 5 步。
-
创建 OpenSearch 服务域。有关说明,请参阅
创建和管理亚马逊 OpenSearch 服务 域名
。
您也可以按照
GitHub 的说明
使用
亚马逊云科技 CloudFormation
模板 来创建域。
您可以使用您的 VPC 中的
接口终端节点
将 Studio 从
亚马逊虚拟私有云
(亚马逊 VPC) 连接到 Amazon S3,而不是通过互联网进行连接。通过使用接口 VPC 终端节点(接口终端节点),您的 VPC 和 Studio 之间的通信完全安全地在 亚马逊云科技 网络内进行。您的 Studio 笔记本电脑可以通过私有 VPC 连接到 OpenSearch 服务,以确保安全通信。
OpenSearch 服务域提供静态数据加密,这是一项安全功能,有助于防止未经授权访问您的数据。节点到节点加密在 OpenSearch 服务的默认功能之上提供了额外的安全层。除非您指定不同的加密选项,否则 Amazon S3 会自动对每个新对象应用服务器端加密 (SSE-S3)。
在 OpenSearch Service 域中,您可以附加基于身份的策略,定义谁可以访问服务、他们可以执行哪些操作以及他们可以在哪些资源上执行这些操作(如果适用)。
将图像和文本对编码为嵌入
本节讨论如何将图像和文本编码为嵌入。这包括准备数据、创建 SageMaker 模型以及使用该模型执行批量转换。
数据概述和准备
你可以使用带有 Python 3(数据科学)内核的 SageMaker Studio 笔记本电脑来运行示例代码。
在这篇文章中,我们使用了
亚马逊伯克利对象数据集
。该数据集是 147,702 个产品列表的集合,其中包含多语言元数据和 398,212 张独特的目录图片。我们仅使用美国英语的商品图片和商品名称。出于演示目的,我们使用了大约 1,600 种产品。有关此数据集的更多详细信息,请参阅
自述文件
。该数据集托管在公共 S3 存储桶中。
有 16 个文件包含亚马逊产品的商品描述和元数据,格式为 listings/metadata
/listings
_ .json.gz。 我们在这个演示中使用了第一个元数据文件。
你使用
熊猫
加载元数据,然后从数据框中选择标题为美国英语的产品。Pandas 是一个建立在 Python 编程语言之上的开源数据分析和操作工具。您可以使用名为 ma
in_image_id 的属性 来识别图像
。参见以下代码:
meta = pd.read_json("s3://amazon-berkeley-objects/listings/metadata/listings_0.json.gz", lines=True)
def func_(x):
us_texts = [item["value"] for item in x if item["language_tag"] == "en_US"]
return us_texts[0] if us_texts else None
meta = meta.assign(item_name_in_en_us=meta.item_name.apply(func_))
meta = meta[~meta.item_name_in_en_us.isna()][["item_id", "item_name_in_en_us", "main_image_id"]]
print(f"#products with US English title: {len(meta)}")
meta.head()
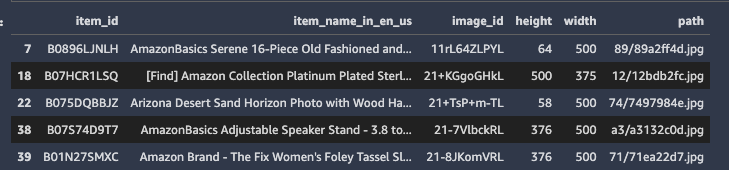
数据框中有 1,639 个产品。接下来,将商品名称与相应的商品图片关联起来。
图像/元数据/images.csv.gz 包含图像元数据
。
此文件是一个 gzip 压缩的 CSV 文件,包含以下各列:
image_id
、
高度 、 宽度和路径
。
您可以读取元数据文件,然后将其与项目元数据合并。参见以下代码:
image_meta = pd.read_csv("s3://amazon-berkeley-objects/images/metadata/images.csv.gz")
dataset = meta.merge(image_meta, left_on="main_image_id", right_on="image_id")
dataset.head()
你可以使用 SageMaker Studio 笔记本 Python 3 内核内置
PIL 库
来查看数据集中的示例图像:
from sagemaker.s3 import S3Downloader as s3down
from pathlib import Path
from PIL import Image
def get_image_from_item_id(item_id = "B0896LJNLH", return_image=True):
s3_data_root = "s3://amazon-berkeley-objects/images/small/"
item_idx = dataset.query(f"item_id == '{item_id}'").index[0]
s3_path = dataset.iloc[item_idx].path
local_data_root = f'./data/images'
local_file_name = Path(s3_path).name
s3down.download(f'{s3_data_root}{s3_path}', local_data_root)
local_image_path = f"{local_data_root}/{local_file_name}"
if return_image:
img = Image.open(local_image_path)
return img, dataset.iloc[item_idx].item_name_in_en_us
else:
return local_image_path, dataset.iloc[item_idx].item_name_in_en_us
image, item_name = get_image_from_item_id()
print(item_name)
image

模型准备
接下来,使用预训练的
CLIP 模型创建 SageMaker 模型
。第一步是下载预训练的模型加权文件,将其放入
model.tar.gz
文件中,然后将其上传到 S3 存储桶。预训练模型的路径可以在 CL
IP
存储库中找到。 在本演示中,我们使用了预训练的 R
esnet-50
(RN50) 模型。参见以下代码:
%%writefile build_model_tar.sh
#!/bin/bash
MODEL_NAME=RN50.pt
MODEL_NAME_URL=https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt
BUILD_ROOT=/tmp/model_path
S3_PATH=s3://<your-bucket>/<your-prefix-for-model>/model.tar.gz
rm -rf $BUILD_ROOT
mkdir $BUILD_ROOT
cd $BUILD_ROOT && curl -o $BUILD_ROOT/$MODEL_NAME $MODEL_NAME_URL
cd $BUILD_ROOT && tar -czvf model.tar.gz .
aws s3 cp $BUILD_ROOT/model.tar.gz $S3_PATH
!bash build_model_tar.sh
然后,您需要为 CLIP 模型提供推理入口点脚本。CLIP 是使用
PyTorch
实现的 ,因此你可以使用
SageMaker
PyTorch 框架。 PyTorch 是一个开源机器学习框架,可加快从研究原型设计到生产部署的路径。有关使用 SageMaker 部署 PyTorch 模型的信息,请参阅
部署
PyTorch 模型。
推理代码接受两个环境变量:
MODEL_NAME 和 ENCODE_TYP
E。
这可以帮助我们轻松地在不同的 CLIP 模型之间切换。我们使用 EN
CODE_TYPE
来指定是要对图像还是文本片段进行编码。
在这里,你实现了
model_fn、 input_fn
、p redict_fn 和 output_fn 函数
,以覆盖默认的 PyTorch
推 理处理程序。
参见以下代码:
!mkdir -p code
%%writefile code/clip_inference.py
import io
import torch
import clip
from PIL import Image
import json
import logging
import sys
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.transforms import ToTensor
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
logger.addHandler(logging.StreamHandler(sys.stdout))
MODEL_NAME = os.environ.get("MODEL_NAME", "RN50.pt")
# ENCODE_TYPE could be IMAGE or TEXT
ENCODE_TYPE = os.environ.get("ENCODE_TYPE", "TEXT")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# defining model and loading weights to it.
def model_fn(model_dir):
model, preprocess = clip.load(os.path.join(model_dir, MODEL_NAME), device=device)
return {"model_obj": model, "preprocess_fn": preprocess}
def load_from_bytearray(request_body):
return image
# data loading
def input_fn(request_body, request_content_type):
assert request_content_type in (
"application/json",
"application/x-image",
), f"{request_content_type} is an unknown type."
if request_content_type == "application/json":
data = json.loads(request_body)["inputs"]
elif request_content_type == "application/x-image":
image_as_bytes = io.BytesIO(request_body)
data = Image.open(image_as_bytes)
return data
# inference
def predict_fn(input_object, model):
model_obj = model["model_obj"]
# for image preprocessing
preprocess_fn = model["preprocess_fn"]
assert ENCODE_TYPE in ("TEXT", "IMAGE"), f"{ENCODE_TYPE} is an unknown encode type."
# preprocessing
if ENCODE_TYPE == "TEXT":
input_ = clip.tokenize(input_object).to(device)
elif ENCODE_TYPE == "IMAGE":
input_ = preprocess_fn(input_object).unsqueeze(0).to(device)
# inference
with torch.no_grad():
if ENCODE_TYPE == "TEXT":
prediction = model_obj.encode_text(input_)
elif ENCODE_TYPE == "IMAGE":
prediction = model_obj.encode_image(input_)
return prediction
# Serialize the prediction result into the desired response content type
def output_fn(predictions, content_type):
assert content_type == "application/json"
res = predictions.cpu().numpy().tolist()
return json.dumps(res)
该解决方案在模型推断期间需要额外的 Python 包,因此您可以提供
requirements.txt
文件以允许 SageMaker 在托管模型时安装其他软件包:
%%writefile code/requirements.txt
ftfy
regex
tqdm
git+https://github.com/openai/CLIP.git
您可以使用
pytorchModel 类创建一个对象 来包含模型
对象的 Amazon S3 位置和推理入口点详细信息的信息。您可以使用该对象创建批量转换作业或将模型部署到端点以进行在线推理。参见以下代码:
from sagemaker.pytorch import PyTorchModel
from sagemaker import get_execution_role, Session
role = get_execution_role()
shared_params = dict(
entry_point="clip_inference.py",
source_dir="code",
role=role,
model_data="s3://<your-bucket>/<your-prefix-for-model>/model.tar.gz",
framework_version="1.9.0",
py_version="py38",
)
clip_image_model = PyTorchModel(
env={'MODEL_NAME': 'RN50.pt', "ENCODE_TYPE": "IMAGE"},
name="clip-image-model",
**shared_params
)
clip_text_model = PyTorchModel(
env={'MODEL_NAME': 'RN50.pt', "ENCODE_TYPE": "TEXT"},
name="clip-text-model",
**shared_params
)
批量转换以将项目图像编码为嵌入
接下来,我们使用 CLIP 模型将项目图像编码为嵌入,并使用 SageMaker 批量转换来运行批量推断。
在创建任务之前,使用以下代码片段将项目图像从 Amazon Berkeley 对象数据集公共 S3 存储桶复制到您自己的存储桶。操作时间不到 10 分钟。
from multiprocessing.pool import ThreadPool
import boto3
from tqdm import tqdm
from urllib.parse import urlparse
s3_sample_image_root = "s3://<your-bucket>/<your-prefix-for-sample-images>"
s3_data_root = "s3://amazon-berkeley-objects/images/small/"
client = boto3.client('s3')
def upload_(args):
client.copy_object(CopySource=args["source"], Bucket=args["target_bucket"], Key=args["target_key"])
arugments = []
for idx, record in dataset.iterrows():
argument = {}
argument["source"] = (s3_data_root + record.path)[5:]
argument["target_bucket"] = urlparse(s3_sample_image_root).netloc
argument["target_key"] = urlparse(s3_sample_image_root).path[1:] + record.path
arugments.append(argument)
with ThreadPool(4) as p:
r = list(tqdm(p.imap(upload_, arugments), total=len(dataset)))
接下来,您以批量方式对项目图像执行推断。SageMaker 批量转换作业使用 CLIP 模型对存储在输入 Amazon S3 位置中的所有图像进行编码,并将输出嵌入上传到输出 S3 文件夹。这项工作大约需要 10 分钟。
batch_input = s3_sample_image_root + "/"
output_path = f"s3://<your-bucket>/inference/output"
clip_image_transformer = clip_image_model.transformer(
instance_count=1,
instance_type="ml.c5.xlarge",
strategy="SingleRecord",
output_path=output_path,
)
clip_image_transformer.transform(
batch_input,
data_type="S3Prefix",
content_type="application/x-image",
wait=True,
)
将来自 Amazon S3 的嵌入数据加载到变量中,以便您稍后可以将数据提取到 OpenSearch 服务中:
embedding_root_path = "./data/embedding"
s3down.download(output_path, embedding_root_path)
embeddings = []
for idx, record in dataset.iterrows():
embedding_file = f"{embedding_root_path}/{record.path}.out"
embeddings.append(json.load(open(embedding_file))[0])
创建基于 ML 的统一搜索引擎
本节讨论如何创建使用带嵌入的 k-nn 搜索的搜索引擎。这包括配置 OpenSearch Service 集群、提取项目嵌入以及执行自由文本和图像搜索查询。
使用 k-nn 设置设置 OpenSearch 服务域
之前,你创建了一个 OpenSearch 集群。现在,你要创建一个索引来存储目录数据和嵌入。您可以使用以下配置配置索引设置以启用 k-nn 功能:
index_settings = {
"settings": {
"index.knn": True,
"index.knn.space_type": "cosinesimil"
},
"mappings": {
"properties": {
"embeddings": {
"type": "knn_vector",
"dimension": 1024 #Make sure this is the size of the embeddings you generated, for RN50, it is 1024
}
}
}
}
此示例使用
Python Elasticsearch 客户端
与 OpenSearch 集群进行通信并创建索引来托管您的数据。你可以在笔记本 中运行
%pip install elasticsearch
来安装库。参见以下代码:
import boto3
import json
from requests_aws4auth import AWS4Auth
from elasticsearch import Elasticsearch, RequestsHttpConnection
def get_es_client(host = "<your-opensearch-service-domain-url>",
port = 443,
region = "<your-region>",
index_name = "clip-index"):
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key,
credentials.secret_key,
region,
'es',
session_token=credentials.token)
headers = {"Content-Type": "application/json"}
es = Elasticsearch(hosts=[{'host': host, 'port': port}],
http_auth=awsauth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
timeout=60 # for connection timeout errors
)
return es
es = get_es_client()
es.indices.create(index=index_name, body=json.dumps(index_settings))
将图像嵌入数据提取到 OpenSearch 服务中
现在,您可以循环浏览数据集并将项目数据提取到集群中。此练习的数据采集应在 60 秒内完成。它还运行一个简单的查询来验证数据是否已成功导入索引。参见以下代码:
# ingest_data_into_es
for idx, record in tqdm(dataset.iterrows(), total=len(dataset)):
body = record[['item_name_in_en_us']].to_dict()
body['embeddings'] = embeddings[idx]
es.index(index=index_name, id=record.item_id, doc_type='_doc', body=body)
# Check that data is indeed in ES
res = es.search(
index=index_name, body={
"query": {
"match_all": {}
}},
size=2)
assert len(res["hits"]["hits"]) > 0
执行实时查询
现在您已经有一个有效的 OpenSearch Service 索引,其中包含作为库存的项目图像的嵌入,让我们来看看如何为查询生成嵌入。您需要创建两个 SageMaker 端点来分别处理文本和图像嵌入。
您还可以创建两个函数来使用端点对图像和文本进行编码。对于
encode_text
函数,可以在项目名称 之前添加
此
项,以便将项目名称转换为用于项目描述的句子。
m@@
emory_size_in_mb 设置为 6 GB
,用于为 Transformer 和 ResNet 模型提供下划线。
参见以下代码:
text_predictor = clip_text_model.deploy(
instance_type='ml.c5.xlarge',
initial_instance_count=1,
serverless_inference_config=ServerlessInferenceConfig(memory_size_in_mb=6144),
serializer=JSONSerializer(),
deserializer=JSONDeserializer(),
wait=True
)
image_predictor = clip_image_model.deploy(
instance_type='ml.c5.xlarge',
initial_instance_count=1,
serverless_inference_config=ServerlessInferenceConfig(memory_size_in_mb=6144),
serializer=IdentitySerializer(content_type="application/x-image"),
deserializer=JSONDeserializer(),
wait=True
)
def encode_image(file_name="./data/images/0e9420c6.jpg"):
with open(file_name, "rb") as f:
payload = f.read()
payload = bytearray(payload)
res = image_predictor.predict(payload)
return res[0]
def encode_name(item_name):
res = text_predictor.predict({"inputs": [f"this is a {item_name}"]})
return res[0]
你可以先画出要使用的图片。
item_image_path, item_name = get_image_from_item_id(item_id = "B0896LJNLH", return_image=False)
feature_vector = encode_image(file_name=item_image_path)
print(feature_vector.shape)
Image.open(item_image_path)

让我们来看一个简单查询的结果。
从 OpenSearch 服务检索结果后,您将从 数据集中获得项目名称和图像的列表:
def search_products(embedding, k = 3):
body = {
"size": k,
"_source": {
"exclude": ["embeddings"],
},
"query": {
"knn": {
"embeddings": {
"vector": embedding,
"k": k,
}
}
},
}
res = es.search(index=index_name, body=body)
images = []
for hit in res["hits"]["hits"]:
id_ = hit["_id"]
image, item_name = get_image_from_item_id(id_)
image.name_and_score = f'{hit["_score"]}:{item_name}'
images.append(image)
return images
def display_images(
images: [PilImage],
columns=2, width=20, height=8, max_images=15,
label_wrap_length=50, label_font_size=8):
if not images:
print("No images to display.")
return
if len(images) > max_images:
print(f"Showing {max_images} images of {len(images)}:")
images=images[0:max_images]
height = max(height, int(len(images)/columns) * height)
plt.figure(figsize=(width, height))
for i, image in enumerate(images):
plt.subplot(int(len(images) / columns + 1), columns, i + 1)
plt.imshow(image)
if hasattr(image, 'name_and_score'):
plt.title(image.name_and_score, fontsize=label_font_size);
images = search_products(feature_vector)
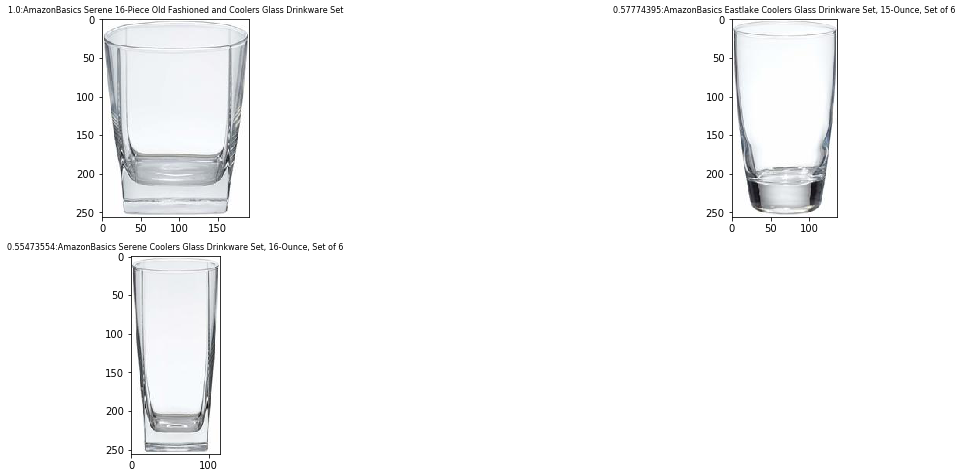
第一项的分数为 1.0,因为这两张图片是相同的。其他物品是 OpenSearch 服务索引中不同类型的眼镜。
你也可以使用文本来查询索引:
feature_vector = encode_name("drinkware glass")
images = search_products(feature_vector)
display_images(images)
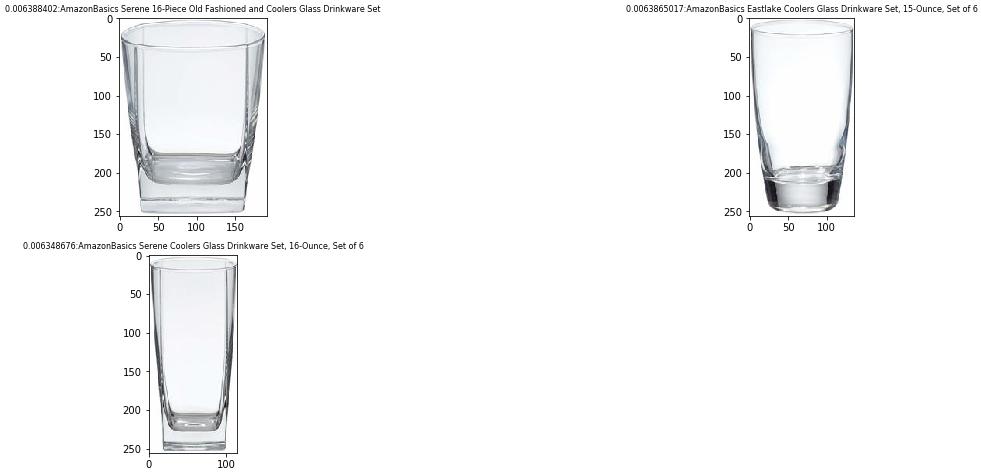
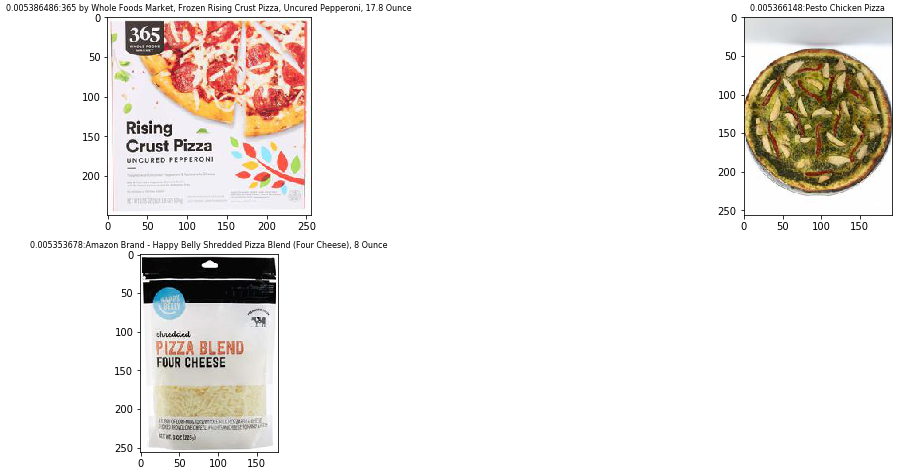
你现在可以从索引中得到三张水杯的照片。您可以使用 CLIP 编码器在同一个潜在空间内找到图像和文本。另一个例子是在索引中搜索 “披萨” 一词:
feature_vector = encode_name("pizza")
images = search_products(feature_vector)
display_images(images)
清理
无服务器推理采用按使用量付费模式,对于不频繁或不可预测的流量模式,是一种经济实惠的选择。如果你有严格的
服务级别协议 (SLA)
,或者不能容忍冷启动,那么实时端点是更好的选择。使用
多模型
或
多容器
端点为部署大量模型提供可扩展且经济实惠的解决方案。有关更多信息,请参阅
亚马逊 SageMaker 定价
。
我们建议在不再需要无服务器端点时将其删除。完成本练习后,您可以通过以下步骤删除资源(您可以从
亚马逊云科技 管理控制台 中删除这些资源,也可以使用 亚马逊云科技
开发工具包或 SageMaker SDK 删除这些资源):
-
删除您创建的终端节点。
-
或者,删除注册的模型。
-
(可选)删除 SageMaker 执行角色。
-
(可选)清空并删除 S3 存储桶。
摘要
在这篇文章中,我们演示了如何使用 SageMaker 和 OpenSearch Service k-nn 索引功能创建 k-nn 搜索应用程序。我们使用了
OpenAI
实现中的预训练的 CLIP 模型。
该帖子的 OpenSearch 服务提取实现仅用于原型设计。如果您想将数据从 Amazon S3 大规模提取到 OpenS
earch 服务中,则可以启动具有相应实例类型和实例数的 Amazon SageMaker
Processing 任务。有关另一种可扩展的嵌入式摄取解决方案,请参阅
诺华股份公司使用亚马逊 OpenSearch Service K-Nearest Neighbor (KNN) 和亚马逊 SageMaker 为搜索和推荐提供支持(第 3/4
部分)。
CLIP 提供
零镜头
功能,这使得直接采用预训练模型成为可能,而无需使用
迁移学习
来微调模型。这简化了 CLIP 模型的应用。如果您有成对的产品图片和描述性文本,则可以使用迁移学习使用自己的数据对模型进行微调,以进一步提高模型性能。有关更多信息,请参阅
从自然语言监督中 学习可转移的视觉模型
和 CL
IP GitHub 存储库故事
。
作者简介
 Kevin Du
是 亚马逊云科技 的高级数据实验室架构师,致力于帮助客户加快机器学习 (ML) 产品和 mLOPs 平台的开发。凭借为初创企业和企业开发支持机器学习的产品的十多年的经验,他的工作重点是帮助客户简化机器学习解决方案的生产。在业余时间,凯文喜欢做饭和看篮球。
Kevin Du
是 亚马逊云科技 的高级数据实验室架构师,致力于帮助客户加快机器学习 (ML) 产品和 mLOPs 平台的开发。凭借为初创企业和企业开发支持机器学习的产品的十多年的经验,他的工作重点是帮助客户简化机器学习解决方案的生产。在业余时间,凯文喜欢做饭和看篮球。
 Ananya Roy
是一名高级数据实验室架构师,专门研究人工智能和机器学习,现居澳大利亚悉尼。她一直在与各种客户合作,提供架构指导,并通过数据实验室的参与帮助他们提供有效的人工智能/机器学习解决方案。在加入 亚马逊云科技 之前,她曾担任高级数据科学家,负责电信、银行和金融科技等不同行业的大规模机器学习模型。她在人工智能/机器学习方面的经验使她能够为复杂的业务问题提供有效的解决方案,她热衷于利用尖端技术帮助团队实现目标。
Ananya Roy
是一名高级数据实验室架构师,专门研究人工智能和机器学习,现居澳大利亚悉尼。她一直在与各种客户合作,提供架构指导,并通过数据实验室的参与帮助他们提供有效的人工智能/机器学习解决方案。在加入 亚马逊云科技 之前,她曾担任高级数据科学家,负责电信、银行和金融科技等不同行业的大规模机器学习模型。她在人工智能/机器学习方面的经验使她能够为复杂的业务问题提供有效的解决方案,她热衷于利用尖端技术帮助团队实现目标。