在这篇文章中,我们将向您展示在将文档数据从
亚马逊简单存储服务(Amazon S3) 迁移到亚马逊 DynamoD
B
时,如何使用 A
WS Glu
e 对 JS
ON 文档进行垂直分区。 您可以将此技术用于其他数据源,包括关系数据库和 NoSQL 数据库。DynamoDB 可以存储和检索任意数量的数据,但单个项目的大小上限为 400 KB。一些现实世界的用例,例如文档处理,需要处理较大的单个项目。
您可以使用垂直分区来处理大于 400 KB 的文档。垂直分区有助于取消嵌套文档,使其更易于引用和索引。
在 Amazon DynamoDB 中使用垂直分区来高效扩展数据
,详细解释了垂直分区。
DynamoDB 是一个完全托管的、无服务器的键值 NoSQL 数据库,旨在运行任何规模的高性能应用程序。由于 DynamoDB 允许灵活的架构,因此除了每个项目的关键属性外,数据属性集可以是统一的,也可以是离散的。DynamoDB 最适合在线事务处理 (OLTP) 工作负载,在这些工作负载中,大多数访问模式都是事先知道的。在某些用例中,可能需要更改密钥架构或密钥属性,例如访问模式随时间推移而发生的变化或跨数据库迁移。
亚马逊云科技 Glue 是一项无服务器数据集成服务,可为您提供全方位的工具,以适合您的应用程序的规模执行 ETL(提取、转换和加载)。您可以使用 亚马逊云科技 Glue 来执行 DynamoDB 数据转换和迁移。亚马逊云科技 Glue 支持托管在 亚马逊云科技 或本地的各种
关系和非关系数据库
。它支持 DynamoDB 作为 ETL 管道的源和目的地。
示例来源:亚马逊 S3 数据架构
在我们的示例用例中,订单数据存储在 S3 文件夹中的 JSON 文件中。每个订单都使用
订单编号进行唯一标识, 并包含诸如 配送地址 、 创建时间戳、 发票编号
、发
货
编号和
is_
co
d 等元数据属性 ,以及订购的产品列表
以及每种产品的元数据。在 S3 存储桶中存储数据时,请遵循
S3 安全最佳实践指南
。
以下代码段显示了 JSON 文件中的几条示例订单记录:
{
"delivery_address":
{
"door":"0265",
"pin":"05759",
"city":"Reyes",
"street":689,
"state":"DE"
},
"creation_timestamp":"2022-07-09T20:48:01Z",
"invoice_id":"inv#9678394201",
"itemlist":[
{
"date_added":"2022-08-13T11:33:39Z",
"prod_price":557,
"prod_quant":15,
"prod_code":"p#2724097",
"seller_id":"s#1472462"
},
{
"date_added":"2022-08-13T11:33:39Z",
"prod_price":216,
"prod_quant":14,
"prod_code":"p#2591306",
"seller_id":"s#5190537"
},
{
"date_added":"2022-08-13T11:33:39Z",
"prod_price":567,
"prod_quant":14,
"prod_code":"p#259494",
"seller_id":"s#1508727"
},
{
"date_added":"2022-08-13T11:33:39Z",
"prod_price":542,
"prod_quant":1,
"prod_code":"p#6450941",
"seller_id":"s#1519549"
}
],
"shipment_id":"ship#1525362",
"is_cod":false,
"order_id":"8e4a7443-8b62-4971-bdd6-3eb01f976fec"
}
{
"delivery_address":
{
"door":"10029",
"pin":"50490",
"city":"Robin",
"street":692,
"state":"MA"
},
"creation_timestamp":"2022-06-20T11:54:11Z",
"invoice_id":"inv#4908812754",
"itemlist":[
{
"date_added":"2022-08-11T23:01:38Z",
"prod_price":454,
"prod_quant":4,
"prod_code":"p#7038559",
"seller_id":"s#4682806"
},
{
"date_added":"2022-08-11T23:01:38Z",
"prod_price":531,
"prod_quant":11,
"prod_code":"p#3193192",
"seller_id":"s#5023003"
},
{
"date_added":"2022-08-11T23:01:38Z",
"prod_price":481,
"prod_quant":14,
"prod_code":"p#1564684",
"seller_id":"s#1542781"
}
],
"shipment_id":"ship#753007",
"is_cod":true,
"order_id":"d1b6fc59-0a77-4f02-a199-83d64888a110"
}
...
您可以
下载此示例数据
,用于本文中描述的解决方案。
目标 DynamoDB 密钥架构
订单数据的常见访问模式是获取订单中产品的产品详细信息或查找包含特定产品的不同订单。目标是使
prod_cod e 属性可编
入索引,这是嵌套 JSON 结构的一部分。作为垂直分区的一部分,我们可以将单个订单文档分解为多个项目,每个项目对应
项目列表
中的一个产品 ,以及一个元数据项目。元数据项包含订单特定的信息,例如
配送地址 、
创建时间戳等。
我们使用排序键属性
SK
来模拟这种一对多关系。使用通用属性名称(例如
SK
)使我们能够使用相同的属性来存储有关不同实体的信息。
因此,订单的理想目标 DynamoDB 项目应与下图 1 中的项目类似,其中每个条目的
order_ id
相同,但每个条目都有唯一的 SK 值。
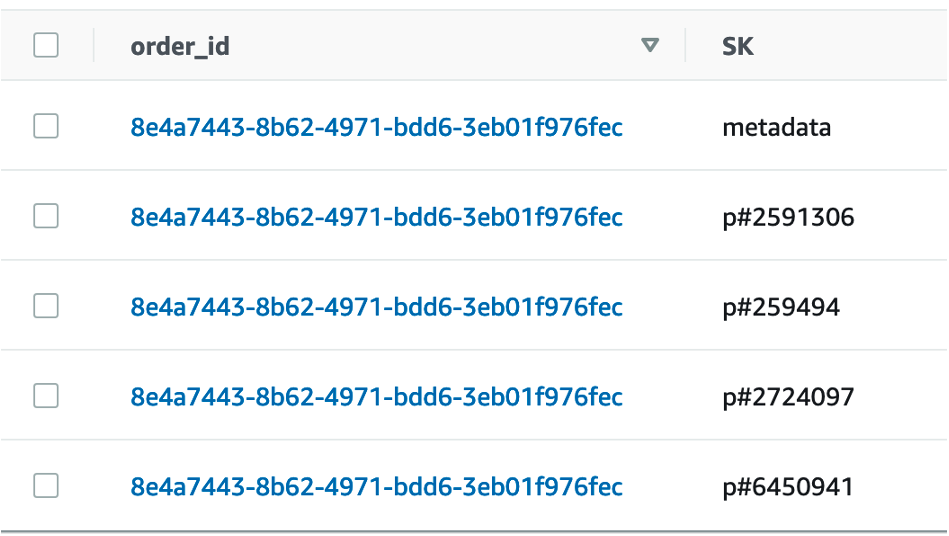
图 1:显示垂直分区订单数据示例的屏幕截图
让我们看看如何使用 亚马逊云科技 Glue 实现这一目标。
解决方案概述
要使用 亚马逊云科技 Glue 将数据从亚马逊 S3 迁移到 DynamoDB,请使用以下步骤:
-
设置 亚马逊云科技 Glue 爬虫来读取 S3 数据。
-
创建 亚马逊云科技 Glue ETL 任务以执行以下功能:
-
从 S3 读取数据。
-
根据目标架构实现垂直分区。
-
将数据写入 DynamoDB 表。
下面的图 2 说明了这种架构。

图 2:将数据从 S3 迁移到 DynamoDB 的架构
先决条件
确保您拥有一个具有相应权限
的 亚马逊云科技 身份和访问管理 (IAM )
角色,可以附加到 亚马逊云科技 Glue 爬虫和 ETL 任务。有关更多信息,请参阅
爬虫先决条件
、
为 亚马逊云科技 Glue 设置 IAM 权限 、在 亚马逊云科技 G
l
u e 中 设置加密以及 亚马逊云科技
IAM 中的 安全最佳实践
。此外,请确保您的输入数据存储在 S3 存储桶中。您可以使用下载的样本数据作为本练习的输入。
设置 亚马逊云科技 Glue 爬虫来读取亚马逊 S3 数据
亚马逊云科技 Glue 爬虫
在 亚马逊云科技 Glue 数据目录中 填充表格,然后 亚马逊云科技 Glue ETL 任务使用这些表作为源和目标。此示例的来源是 S3 存储桶。
设置和运行 亚马逊云科技 Glue 爬虫
-
在适用
于 亚马逊云科技 Glue 的 亚马逊云科技 管理控制台
的左侧菜单上,选择
爬虫
。
-
在 “
爬虫
” 页面上,选择 “
创建爬虫
”。这将启动一系列提示您输入爬虫详细信息的页面。
-
在 “
名称
” 字段中,输入一个唯一的名称,然后选择 “
下一步
” 。
-
在
选择数据源和分类器
页面上,选择
添加数据存储
并保留其余字段的默认值。
-
现在将爬虫指向 S3 数据。在
添加数据存储
页面上,选择
Amazon S3 数据存储
。本教程不使用连接,因此,如果
连接
字段可见,请将其留空。
-
在
S3 路径
字段中,输入爬虫可以找到文档数据的路径。选择 “
添加 S3 数据源
” ,然后选择 “
下一步
” 。
-
选择有权访问数据存储和在数据目录中创建对象的现有 IAM 角色,或者选择
创建新的 IAM 角色 。IAM 角色
名称以 awsGlueServiceRole-开头,然后在字段中输入角色名称的最后一部分。输入角色名称,然后选择 Ne
xt
。
注意:
要创建 IAM 角色,您的 亚马逊云科技 用户必须拥有 CreateRole、createPolicy 和 AttachrolePolicy 权限。该向导创建了一个名为 awsGlueserviceRole-[名称] 的 IAM 角色,将 亚马逊云科技 托管策略 awsGlueserviceRole 附加到该角色,并添加一个允许读取爬虫中提供的 S3 位置的内联策略。
-
从下拉列表中选择新创建的角色,然后选择
Next
。
-
在
设置输出和调度
页面上,选择
添加数据库
以创建数据库。在弹出窗口中,输入数据库的名称,然后选择 “
创建数据库
” 。返回 Crawler 创建页面,从 T
arget 数据库
的下拉列表中选择新创建的数据库。对于 Crawler 计划 中的
频率
,选择 “
按需
” ,对其余选项使用默认值,然后选择 “
下一步
”。
-
验证您在 “
查看并创建
” 页面中所做的选择。如果发现任何错误,可以选择 “返
回
” 返回 到之前的页面并进行更改。查看完信息后,选择 “
创建爬虫
”。
-
当爬虫页面顶部附近的横幅显示爬虫已创建时,选择
Run
Crawler。 横幅更改为显示
Crawler 成功启动
和
正在运行
您的爬虫的 消息。
片刻之后,你可以选择 “
刷新
” 图标来查看爬虫的当前状态。当搜寻器完成时,会出现一个新的横幅,描述爬虫所做的更改。
-
在左侧导航栏
的数据目录
下 和
数据库
下方 ,选择
表
。在这里,您可以查看爬虫创建的表。选择表名以查看表设置、参数和属性。在此视图中向下滚动以查看架构,即有关表的列和数据类型的信息。
这篇文章的搜寻器创建了一个表,其架构如图 3 所示,如下所示。
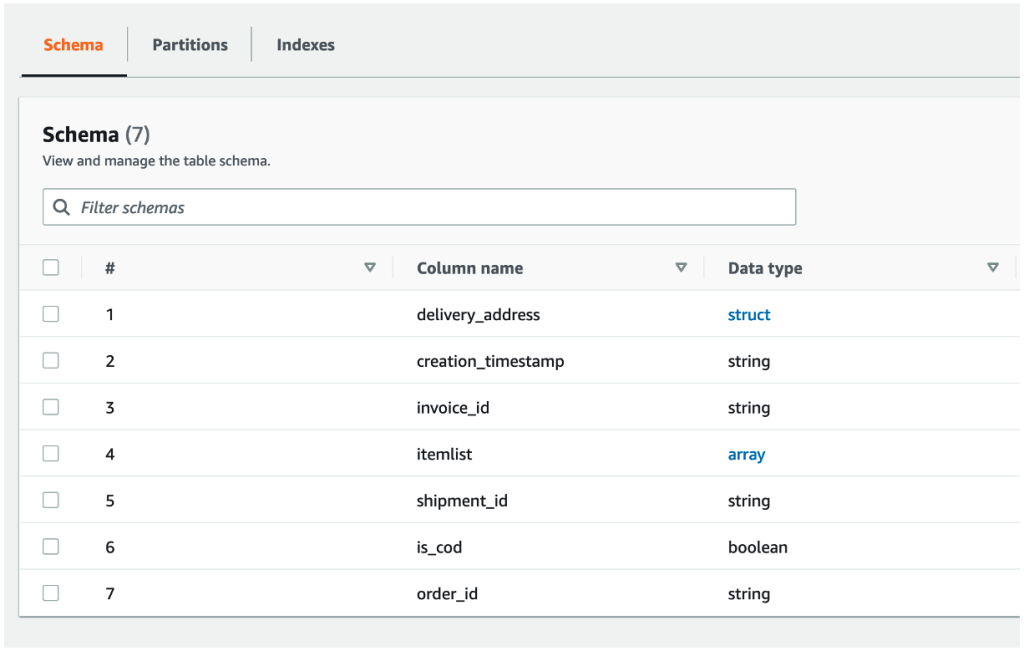
图 3:爬虫创建的表的架构
您也可以参考本
教程
来创建爬虫。有关设置爬虫的更多详细信息,请参阅在
亚马逊云科技 Glue 控制台上 使用爬虫
。
创建 亚马逊云科技 Glue ETL 任务
Glue ETL 作业用于实现文档数据的垂直分区,以及使用目标架构将数据写入 DynamoDB。
创建 亚马逊云科技 Glue ETL 任务
-
在 亚马逊云科技 Glue 控制台上,选择导航窗格 中的
任务
。
图 4:从导航窗格中选择 Jobs
-
选择
Spark 脚本编辑器
。
-
选择 “
创建
” 。
图 5:创建 Spark 脚本
以下部分介绍如何构建 ETL 作业的脚本。
从亚马逊 S3 读取数据
从以下几行代码开始,从 S3 读取数据。提供诸如数据目录中的数据库名称和表名之类的参数(数据库和表是由 Glue Crawler 在前面的步骤中创建的)。以下代码使用来自 S3 的数据创建了一个名为
DynamicF r
ame 的结构。
# Reading nested JSON data from Amazon S3 bucket
read_s3_orders_nested_json = glueContext.create_dynamic_frame.from_catalog(
database="orders-nested",
table_name="s3_orders_nested_json",
transformation_ctx="read_s3_orders_nested_json")
根据已确定的目标架构实现垂直分区
在此示例中,您使用名为 relationaliz
e 的函数 来实现
垂直分区。关系化函数将嵌套结构展平,并将动态帧分解为多个动态帧:一个代表根元素,多个帧分别代表一个嵌套元素。关系化转换后,根元素和嵌套元素是分开的。要将嵌套元素与根元素关联回来,可以使用 Spark 的联接函数。
注意:
联接函数适用于 DataFrame,这就是为什么代码包括从 DynamicFrame 到 DataFrame 的转换。
此外,你可以使用自定义 Python 函数在 DynamicFrame 中引入新的属性或列。此示例中的数据没有带有值元数据的 SK 属性,元数据代表订单元数据。因此,您可以使用名为 add_sort_key
_col 的自定义函数为 SK 属性添加
一列。您也可以将 d
elivery_
address 属性重新格式化为字符串。
最后,使用
ApplyMapping
在目标 DynamoDB 项目中定义属性。
# Add new column
def add_sort_key_col(r):
r["SK"] = "metadata"
return r
add_column_to_s3_orders_nested_json = Map.apply(
frame=read_s3_orders_nested_json, f=add_sort_key_col)
# Uses transform relationalize which flattens a nested schema in a DynamicFrame
relationalized_json = add_column_to_s3_orders_nested_json.relationalize(
root_table_name="root", staging_path=args["TempDir"])
root_dyf = relationalized_json.select('root')
root_itemlist_dyf = relationalized_json.select('root_itemlist')
# Reformat the flattened delivery_address attribute to a string
def reformat_address(r):
r["delivery_address"] = (r["delivery_address.door"])+", "+str(r["delivery_address.street"])+", "+(r["delivery_address.city"])+", "+(r["delivery_address.state"])+", "+(r["delivery_address.pin"])
del r["delivery_address.door"]
del r["delivery_address.street"]
del r["delivery_address.city"]
del r["delivery_address.state"]
del r["delivery_address.pin"]
return r
root_dyf = Map.apply(frame = root_dyf, f = reformat_address)
# Convert to Spark Dataframe
root_df_jf = root_dyf.toDF()
root_itemlist_df = root_itemlist_dyf.toDF()
# Apply inner join
joined_df = root_df_jf.join(
root_itemlist_df,
root_df_jf.itemlist == root_itemlist_df.id,
how='inner')
# Converting back to DynamicFrame
joined_dyf = DynamicFrame.fromDF(joined_df, glueContext, "nested")
# Use transform applymapping - applies a mapping in a DynamicFrame. We use this to define relevant attributes for the individual products and order metadata.
root_dyf_applymapping = ApplyMapping.apply(
frame=root_dyf,
mappings=[
("order_id","string","order_id","string"),
("SK","string","SK","string"),
("creation_timestamp","string","creation_timestamp","string"),
("is_cod","boolean","is_cod","boolean"),
("delivery_address","string","delivery_address","string"),
("invoice_id","string","invoice_id","string"),
("shipment_id","string","shipment_id","string")],
transformation_ctx="root_dyf_applymapping")
joined_dyf_applymapping = ApplyMapping.apply(
frame=joined_dyf,
mappings=[
("order_id","string","order_id","string"),
("`itemlist.val.prod_code`","string","SK","string"),
("`itemlist.val.date_added`","string","date_added","string"),
("`itemlist.val.seller_id`","string","seller_id","string"),
("`itemlist.val.prod_price`","int","price","int"),
("`itemlist.val.prod_quant`","int","quantity","int")],
transformation_ctx="joined_dyf_applymapping")
将数据写入 DynamoDB 表
创建一个 名为 orders_vertically_partitioned 的新 DynamoDB 表
, 其中分
片数据将由 Glue ETL 作业写入。在亚马逊 DynamoDB 中存储数据时,建议您
查看
Dyn amoDB 安全最佳实践。
该表的键架构是:
分区键:
order_id
(字符串类型)
排序键:
SK
(字符串类型的通用属性名称)
在 Glue ETL 作业脚本中,有一些具有预期目标架构的 DynamicFrame 结构。
使用
write_dynamic_frame 函数,并在 connection_
options 中提供 DynamoDB 表名称和写入吞吐量阈值作为参数。
dynamodb.throughput.write.percent 参数限制了该任务消耗的 DynamoDB 写入
容量单位。
# Writing to DynamoDB
root_dyf_write_sink_dynamodb = glueContext.write_dynamic_frame.from_options(
frame=root_dyf_applymapping,
connection_type="dynamodb",
connection_options={
"dynamodb.output.tableName": "orders_vertically_partitioned",
"dynamodb.throughput.write.percent": "1.0"})
joined_dyf_write_sink_dynamodb = glueContext.write_dynamic_frame.from_options(
frame=joined_dyf_applymapping,
connection_type="dynamodb",
connection_options={
"dynamodb.output.tableName": "orders_vertically_partitioned",
"dynamodb.throughput.write.percent": "1.0"})
示例脚本
以下代码显示了完整的脚本:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
args = getResolvedOptions(sys.argv, ['TempDir', 'JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Reading nested JSON data from Amazon S3 bucket
read_s3_orders_nested_json = glueContext.create_dynamic_frame.from_catalog(
database="orders-nested",
table_name="s3_orders_nested_json",
transformation_ctx="read_s3_orders_nested_json")
# Add new column
def add_sort_key_col(r):
r["SK"] = "metadata"
return r
add_column_to_s3_orders_nested_json = Map.apply(
frame=read_s3_orders_nested_json, f=add_sort_key_col)
# Uses transform relationalize which flattens a nested schema in a DynamicFrame
relationalized_json = add_column_to_s3_orders_nested_json.relationalize(
root_table_name="root", staging_path=args["TempDir"])
root_dyf = relationalized_json.select('root')
root_itemlist_dyf = relationalized_json.select('root_itemlist')
# Reformat the flattened delivery_address attribute to a string
def reformat_address(r):
r["delivery_address"] = (r["delivery_address.door"])+", "+str(r["delivery_address.street"])+", "+(r["delivery_address.city"])+", "+(r["delivery_address.state"])+", "+(r["delivery_address.pin"])
del r["delivery_address.door"]
del r["delivery_address.street"]
del r["delivery_address.city"]
del r["delivery_address.state"]
del r["delivery_address.pin"]
return r
root_dyf = Map.apply(frame = root_dyf, f = reformat_address)
# Convert to Spark Dataframe
root_df_jf = root_dyf.toDF()
root_itemlist_df = root_itemlist_dyf.toDF()
# Apply inner join
joined_df = root_df_jf.join(
root_itemlist_df,
root_df_jf.itemlist == root_itemlist_df.id,
how='inner')
# Converting back to DynamicFrame
joined_dyf = DynamicFrame.fromDF(joined_df, glueContext, "nested")
# Use transform applymapping - applies a mapping in a DynamicFrame. We use this to define relevant attributes for the individual products and order metadata.
root_dyf_applymapping = ApplyMapping.apply(
frame=root_dyf,
mappings=[
("order_id","string","order_id","string"),
("SK","string","SK","string"),
("creation_timestamp","string","creation_timestamp","string"),
("is_cod","boolean","is_cod","boolean"),
("delivery_address","string","delivery_address","string"),
("invoice_id","string","invoice_id","string"),
("shipment_id","string","shipment_id","string")],
transformation_ctx="root_dyf_applymapping")
joined_dyf_applymapping = ApplyMapping.apply(
frame=joined_dyf,
mappings=[
("order_id","string","order_id","string"),
("`itemlist.val.prod_code`","string","SK","string"),
("`itemlist.val.date_added`","string","date_added","string"),
("`itemlist.val.seller_id`","string","seller_id","string"),
("`itemlist.val.prod_price`","int","price","int"),
("`itemlist.val.prod_quant`","int","quantity","int")],
transformation_ctx="joined_dyf_applymapping")
# Writing to DynamoDB
root_dyf_write_sink_dynamodb = glueContext.write_dynamic_frame.from_options(
frame=root_dyf_applymapping,
connection_type="dynamodb",
connection_options={
"dynamodb.output.tableName": "orders_vertically_partitioned",
"dynamodb.throughput.write.percent": "1.0"})
joined_dyf_write_sink_dynamodb = glueContext.write_dynamic_frame.from_options(
frame=joined_dyf_applymapping,
connection_type="dynamodb",
connection_options={
"dynamodb.output.tableName": "orders_vertically_partitioned",
"dynamodb.throughput.write.percent": "1.0"})
job.commit()
脚本成功运行后,您可以验证数据是否已在 DynamoDB 中垂直分片。每个
order_id
的商品集合 包含商品列表中每种产品的订单元数据和元数据。
现在可以使用 SK 属性对
prod_co
de 值进行索引。
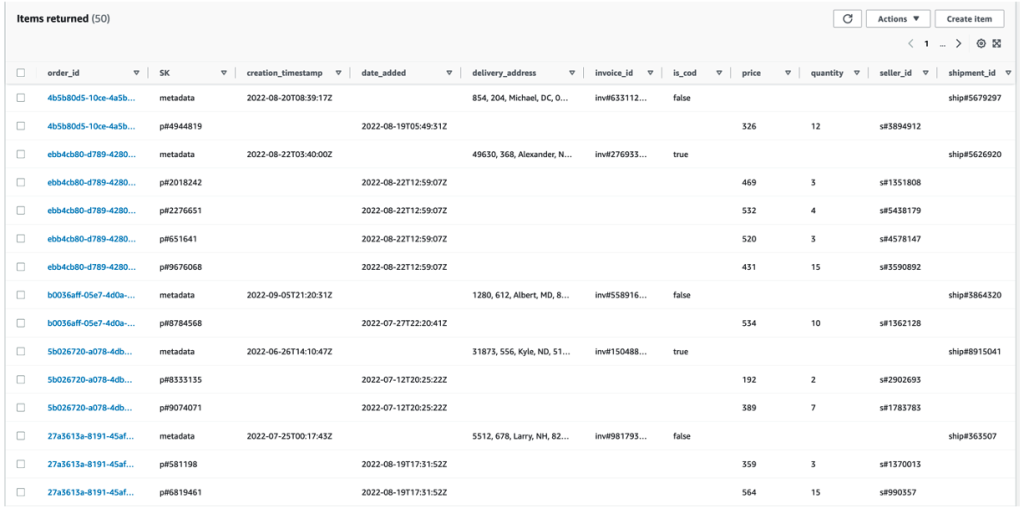
图 6:显示已加载和垂直分区的数据的表格
性能注意事项
Glue ETL 作业的运行时间取决于输入文档的数量和大小以及作业工作人员的数量和类型。对于输入数据量发生显著变化的用例,使用
亚马逊云科技 Glue Auto Scaling
会很有帮助, 因为它会根据作业运行中每个阶段的并行度来处理计算扩展。对于以增量方式接收 Amazon S3 输入数据(例如,每天)
的工作负载, 可以考虑使用任务书签
仅处理新的未处理数据。
您还可以根据要求配置
dynamodb.throughput.write.percent 的值,以控制此 ET L 任务消耗的 DynamoDB 写入
容量。此属性的默认值为 0.5。您可以在
亚马逊云科技 Glue 开发者
指南中找到有关 DynamoDB 参数的更多详细信息。
清理
如果您不再需要 Amazon S3 数据和 DynamoDB 表,请在完成本练习后将其删除,以避免不必要的成本。如果不需要,也可以删除 Glue 作业和 Crawler,但如果不运行,它们不会产生额外费用。
结论
在这篇文章中,您学习了如何使用 亚马逊云科技 Glue 对存储在 DynamoDB 中的 JSON 文档数据进行垂直分区。在将数据加载到目标数据库之前,可以在迁移期间使用此技术对数据执行其他转换,例如串联属性或展平嵌套属性。
有关其他资源,请参阅以下内容:
-
读取或写入亚马逊 DynamoDB 时,如何优化我的 亚马逊云科技 Glue ETL 工作负载?
-
使用 DynamoDB 作为 Glue 的接收器。
-
使用 亚马逊云科技 Glue 关系化转换简化嵌套 JSON 的查询
-
监控 亚马逊云科技 Glu
e 任务
-
在 亚马逊云科技 Glue 上使用自动扩展
-
亚马逊云科技 Glue 自动扩展简介
如果您有任何问题或反馈,请发表评论。
作者简介
 Juhi Patil
是一位驻伦敦的 DynamoDB 专业解决方案架构师,具有大数据技术背景。在她目前的职位上,她帮助客户设计、评估和优化他们基于 DynamoDB 的解决方案。
Juhi Patil
是一位驻伦敦的 DynamoDB 专业解决方案架构师,具有大数据技术背景。在她目前的职位上,她帮助客户设计、评估和优化他们基于 DynamoDB 的解决方案。
 穆罕默德法希姆·帕森
是班加罗尔的高级云支持工程师。他在分析、数据仓库和分布式系统方面拥有超过 13 年的经验。他热衷于评估新技术并帮助客户提供创新的解决方案。
穆罕默德法希姆·帕森
是班加罗尔的高级云支持工程师。他在分析、数据仓库和分布式系统方面拥有超过 13 年的经验。他热衷于评估新技术并帮助客户提供创新的解决方案。