我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
提高在亚马逊 S3 数据湖上构建的 Apache Iceberg 表的运营效率
在这篇文章中,我们将向您展示如何提高基于
优化数据湖存储
在 Amazon S3 上构建现代数据湖的主要优势之一是,它可以在不影响性能的情况下降低成本。您可以将 Amazon S3 生命周期配置和 Amazon S3 对象标记与 Apache Iceberg 表一起使用,以优化整体数据湖存储的成本。Amazon S3 生命周期配置是一组规则,用于定义 Amazon S3 对一组对象应用的操作。有两种类型的操作:
- 过渡操作 -这些操作定义对象何时过渡到其他存储类别;例如,亚马逊 S3 标准存储到 Amazon S3 Glacier。
- 过期操作 -这些操作定义对象何时过期。Amazon S3 代表您删除过期的对象。
Amazon S3 使用对象标签对存储进行分类,其中每个标签都是一个键值对。从 Apache Iceberg 的角度来看,它支持自定义 Amazon S3 对象
s3.delete.tags
配置属性,对象在删除之前会使用配置的键值对进行标记。如果将目录属性
s3.delete-enab
led 设置 为
false
,则不会从 Amazon S3 中硬删除对象。预计这将与 Amazon S3 删除标签结合使用,因此使用 Ama
t rue
。
这篇文章中的示例笔记本显示了 Apache Iceberg 表的 S3 对象标记和生命周期规则的实现示例,以优化存储成本。
实现业务连续性
Amazon S3 让任何开发人员都能访问与亚马逊运行自己的全球网站网络相同的高度可扩展、可靠、快速、廉价的数据存储基础设施。Amazon S3 的设计耐久性为 99.999999999%(11 9),S3 标准版的可用性设计为 99.99%,标准版 — IA 的可用性设计为 99.9%。不过,为了使您的数据湖工作负载在不太可能出现的中断情况下保持高度可用,您可以将 S3 数据复制到另一个 亚马逊云科技 区域作为备份。由于 S3 数据位于多个区域,您可以使用 S3 多区域接入点作为解决方案来访问来自备份区域的数据。借
提高亚马逊 S3 的性能和吞吐量
Amazon S3 支持的请求速率为存储桶中每个前缀每秒 3,500 个 PUT/COPY/POST/DELETE 请求或每秒 5,500 个 GET/HEAD 请求。创建前缀时,此请求速率的资源不会自动分配。取而代之的是,随着前缀请求速率的逐渐提高,Amazon S3 会自动扩展以处理增加的请求速率。对于某些需要突然提高前缀中对象的请求速率的工作负载,Amazon S3 可能会返回 503 个 Slow Down 错误,也称为
S3 限制
。它在执行此操作的同时在后台进行扩展以处理增加的请求速率。此外,如果超过了支持的请求速率,则最佳做法是跨多个
jectStoreLocationProvider 功能来显著减少工程工作量,该 功能会在您指定的 S3 对象
路径中添加 S3 哈希 [0*7FFFFF] 前缀。
默认情况下,Iceberg 使用 Hive 存储布局,但你可以将其切换为使用 ObjectStoreLocationProvider 。
默认情况下,此选项未启用,因此可以灵活选择要添加哈希前缀的位置。
使用
这可确保写入 Amazon S3 的文件均等地分布在 S3 存储桶中的多个前缀中,从而最大限度地减少限制错误。在以下示例中,我们将
ObjectStoreLocationProvid
er ,将为每个存储的文件生成确定性哈希值,并在使用参数
write.data.path(写入.object-storage-storage-pat
h 适用于 Iceberg 0.12 及以下版本的存储路径)指定的 S3 文件夹后面添加一个子文件夹。
write.data.path
值设置为
s3://my-table-data-bucket
,Iceberg 生成的 S3 哈希前缀将附加在此位置之后:
您的 S3 文件将按照 MURMUR3 S3 哈希前缀排列,如下所示:
使用 Iceberg
ObjectStoreLocation Provider
并不是避免 S3 503 错误的万无一失的机制。您仍然需要设置适当的 EMRFS 重试次数以提供额外的弹性。您可以通过增加默认指数退避重试策略的最大重试限制或启用和配置加法增加/乘法减少 (AIMD) 重试策略来调整重试策略。亚马逊 EMR 版本 6.4.0 及更高版本支持 AIMD。有关更多信息,请参阅使用
在以下部分中,我们将提供这些用例的示例。
存储成本优化
在此示例中,我们使用了 Iceberg 的
此示例在 EMR 版本 emr-6.10.0 集群上演示,该集群安装了应用程序 Hadoop 3.3.3、Jupyter Enterprise Gateway 2.6.0 和 Spark 3.3.1。这些示例在连接到 EMR 集群的 Jupyter 笔记本电脑环境上运行。要了解有关如何使用 Iceberg 创建 EMR 集群和使用亚马逊 EMR Studio 的更多信息,请分别参阅将
write-tag-name=created,删除标签为 delete-tag-name=del
eted。
以下示例也可以在
在 Spark 会话上配置 Iceberg
使用
%%configure 魔法命令配置
你的 Spark 会话。您可以使用
在运行此步骤之前,使用命名惯例
/
使用您为测试此示例而创建的存储桶更新以下配置 中的iceberg-storage-blog
。请注意配置参数
s3.write.tags.write-tag-name 和 s3.delete.tags.delete-tag-name
,它们将使用相应的标签值
标记新的 S3 对象 和已删除的对象。
我们将在后续步骤中使用这些标签来实施 S3 生命周期策略,将对象过渡到成本较低的存储层或根据用例将其过期。
使用 Spark-SQL 创建 Apache Iceberg 表
现在,我们为
在下一步中,我们使用 Spark 操作在表中加载数据集。
将数据加载到 Iceberg 表中
在插入数据时,我们根据表定义按
review_dat
e 对数据进行分区。在你的 PySpark 笔记本中运行以下 Spark 命令:
在同一 Iceberg 表中插入一条记录,这样它就会使用当前
rev
iew_date 创建一个分区:
您可以通过查询 Iceberg 快照来检查在此追加操作之后是否创建了新快照:
您将看到类似于以下内容的输出,其中显示了对表执行的操作。
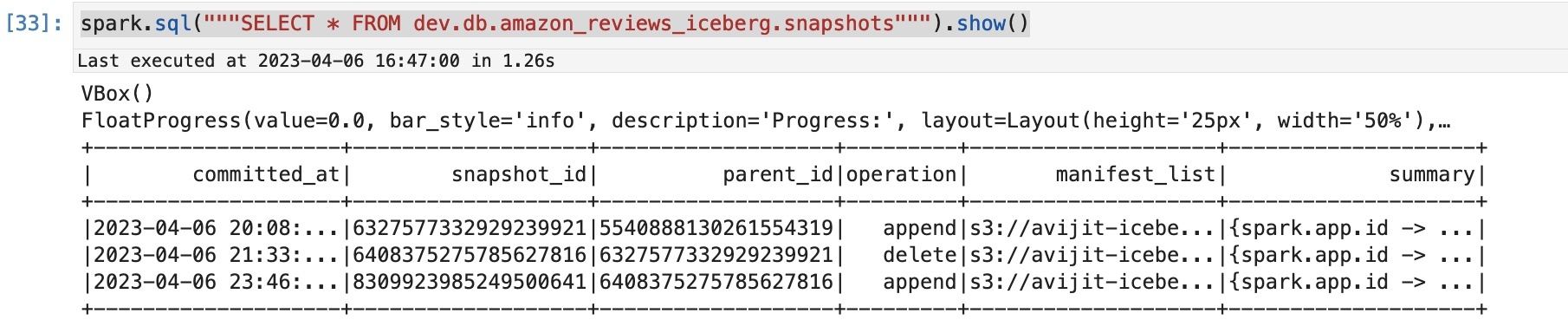
检查 S3 标签的填充情况
您可以使用
在亚马逊 S3 控制台上,查看 S3 文件夹
s3://your-iceberg-storage-blog/iceberg/db/amazon_reviews_iceberg/data/
并指向 review_date
_year=2023/
分区。然后检查该文件夹下的 Parquet 文件,以检查与 Parquet 格式的数据文件相关的标签。
在 亚马逊云科技 CLI 中运行以下命令,查看该标签是基于 Spark 配置创建的 spar
k.sql.catalog.dev.s3.write.tags.write-tag-nam
e”: “created”:
在此步骤中,我们从 Iceberg 表中删除一条记录,并使与已删除记录对应的快照过期。我们删除使用当前
review_d
ate 插入的新单条记录:
现在,我们可以检查是否创建了新的快照,并将该操作标记为
删除
:
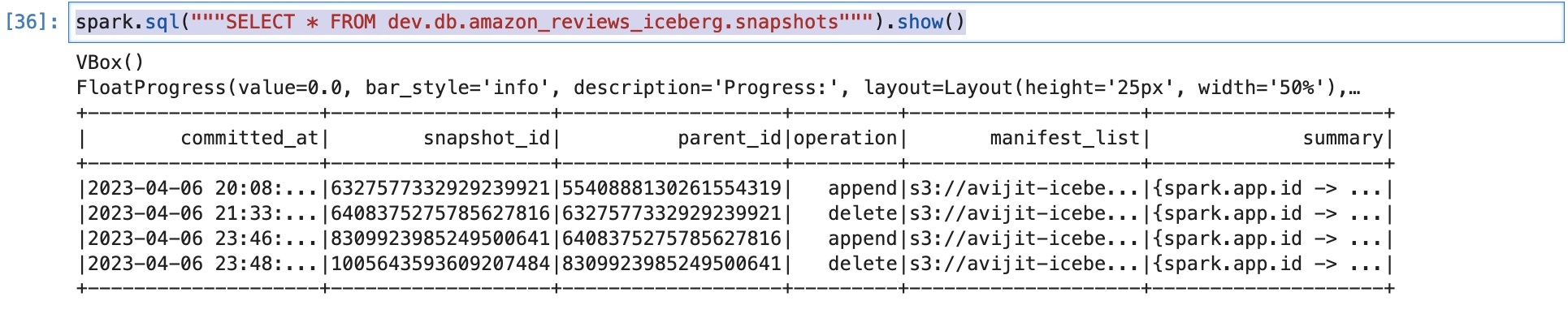
如果我们想在将来进行时空旅行并检查已删除的行,这很有用。在这种情况下,我们必须使用与删除的行 对应的
快照 ID
来查询表。但是,我们不在本文中讨论时空旅行。
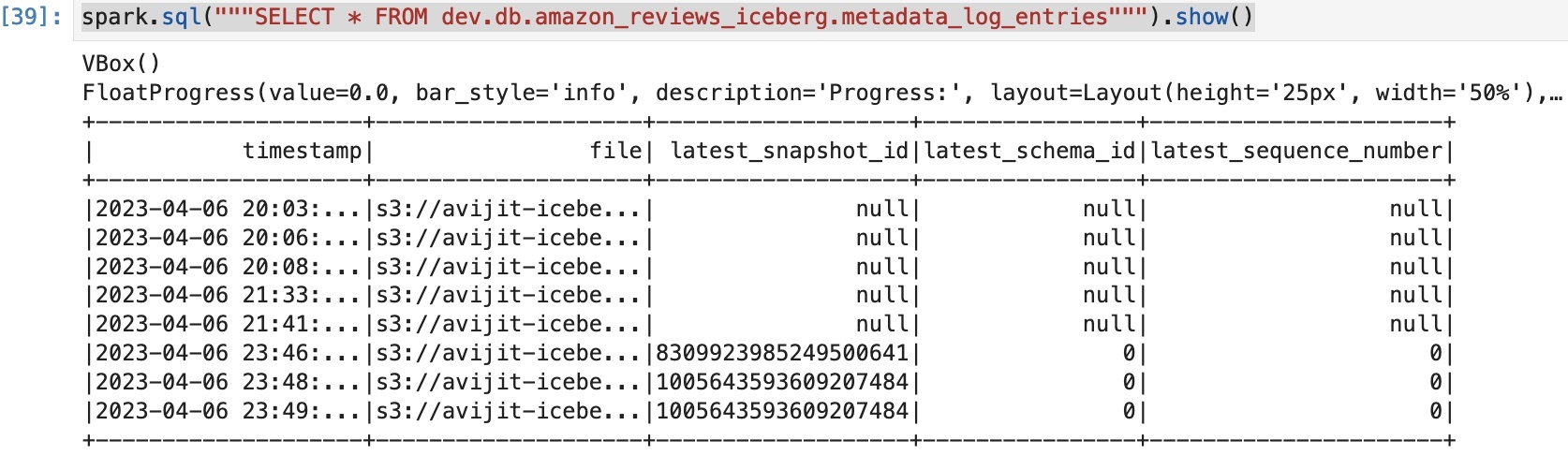
我们将表中的旧快照过期,只保留最后两个快照。您可以根据您的特定要求修改查询以保留快照:
如果我们对快照运行相同的查询,我们可以看到只有两个快照可用:

在 亚马逊云科技 CLI 中,你可以运行以下命令来查看标签是基于 Spark 配置 spar
k.sql.catalog.dev.s3 创建的。delete.tags.del
ete-tag-name”: “已删除”:
已过期的快照将最新的快照 ID 显示为
空
。
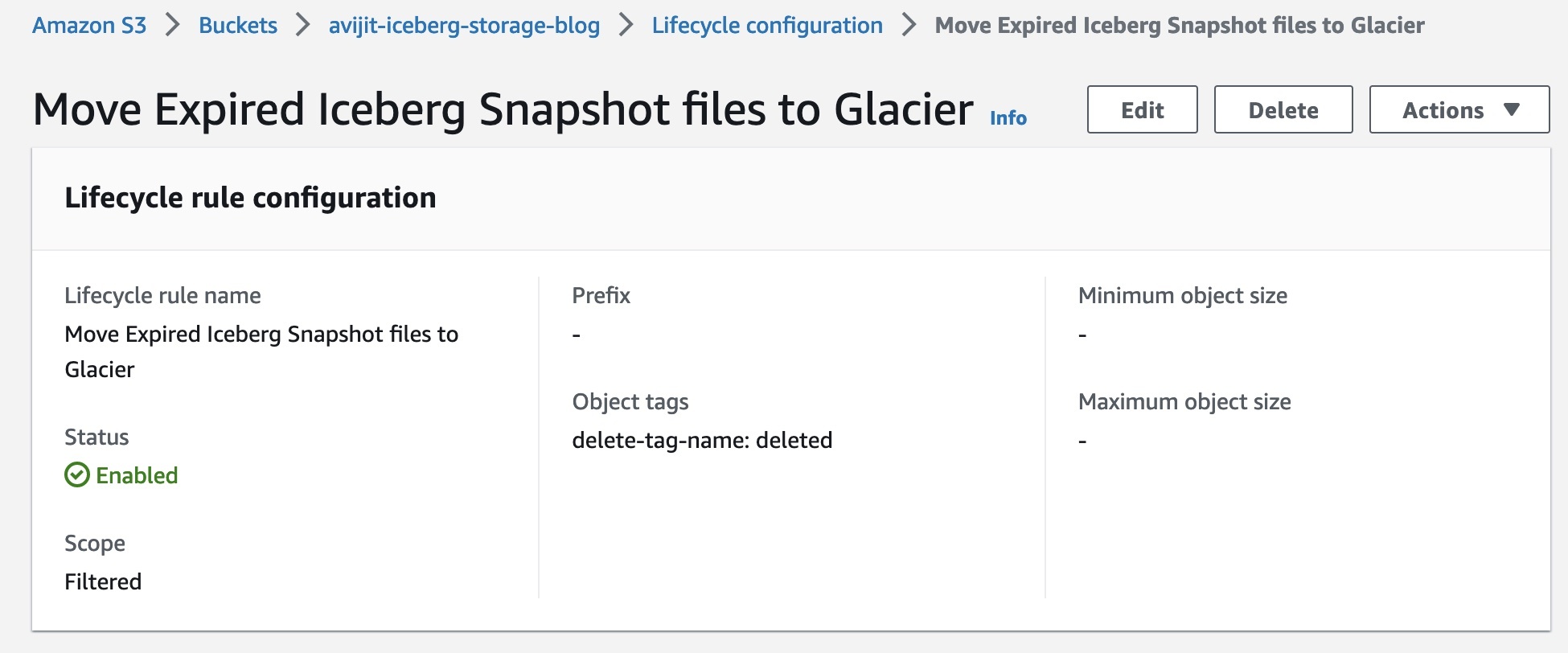
创建 S3 生命周期规则以将存储分区过渡到不同的存储层
为存储分区创建生命周期配置,将带有 delete-tag-name=deleted S3 标签的对象转移到 Glacier 即时检索类。Amazon S3 每天午夜世界协调时间 (UTC) 运行一次生命周期规则,新的生命周期规则可能需要长达 48 小时才能完成首次运行。Amazon S3 Glacier 非常适合存档需要立即访问的数据(以毫秒为单位进行检索)。使用 S3 Glacier 即时检索,每季度访问一次数据时,与使用 S3 标准不频繁访问(S3 标准-IA)存储类相比,您可以节省高达 68% 的存储成本。
当您想要访问数据时,可以
灾难恢复和业务连续性、跨账户和多区域访问数据湖的能力
由于 Iceberg 不支持相对路径,因此您可以通过指定存储桶 到
对于跨区域接入点,我们还需要将
如果将 Amazon S3 资源 ARN 作为 Amazon S3 操作的目标传入,而该操作的区域与配置客户端的区域不同,则必须将此标志设置为 “
启用 use-arn-region 的 目录属性设置为
调用。
t
rue,以使 S3FileIO 能够进行跨区域
true
” 以允许客户端对 ARN 中指定的区域进行跨区域调用,否则将引发异常。
但是,对于相同或多区域接入点,应将
use-arn-region-enabled 标志设置
为 “false”。
例如,要在 Spark 3.3 中使用具有多区域访问权限的 S3 接入点,您可以使用以下代码启动 Spark SQL 外壳:
在此示例中,亚马逊 S3 中的 my-b
ucket1 和 my-buck et
2 存储 桶上的对象使用 arn: aws: s3:: 123456789012:accesspoint : mf
zwi23gn
jvgw.mrap 接入点进行所有亚马逊 S3 操作。
有关使用接入点的更多详细信息,请参阅将接
假设你的表路径在 mybucket1 下 ,因此区域
在调用 S3(GET/PUT)时,我们将
1 中的 mybucket1
和区域 中的
mybucket
2 在元数据文件中都有 mybucket
1 的路径。
mybucket1
引用替换为多区域接入点。
处理提高的 S3 请求速率
使用
问题在于,默认哈希算法生成的哈希值不超过整数
ObjectStoreLocationProvid
er (有关更多详细信息,请参阅
MAX_VAL
UE ,在 Java 中为 (2^31) -1。当将其转换为十六进制时,它会生成 0x7FFFFFF,因此第一个字符差异仅限于 [0-8]。根据Amazon S3
从
该位置提供商最近由亚马逊 EMR 通过 C
要使用,请确保
iceberg.enabled 分类设置为真,并将 wr ite.location-provider.im
pl 设置为 org.apache.iceberg.em
imizeds3LocationProvider。
r
.opt
以下是 Spark shell 命令的示例:
以下示例显示,当您在 Iceberg 表中启用对象存储时,它会在 S3 路径中直接在您在 DDL 中提供的位置之后添加哈希前缀。
定义表
write.object-storage.enable
d 参数并提供 S3 路径,之后您要使用 write.data.path(适用于 Iceberg 版本 0.13 及更高版本)或
write.object-storage.path
(适用于 Iceberg 版本 0.12 及以下)参数添加哈希前缀。
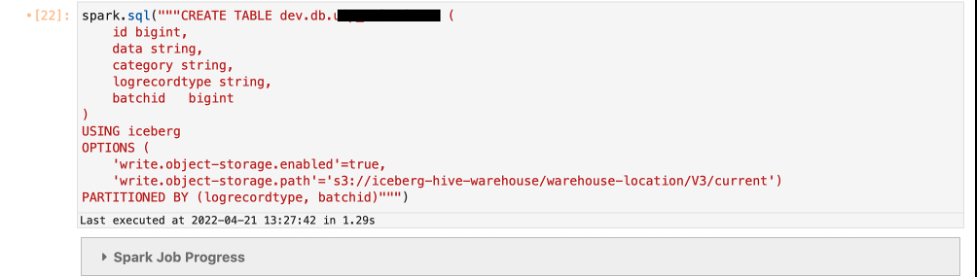
将数据插入到您创建的表中。

哈希前缀是在 DDL 中定义的 S3 路径中的 /current/ 前缀之后添加的。

清理
完成测试后,清理资源以避免任何经常性费用:
- 删除您为此测试创建的 S3 存储桶。
- 删除 EMR 集群。
- 停止并删除 EMR 笔记本实例。
结论
随着各公司继续在S3数据湖上的超大型数据集上使用Apache Iceberg开放表格式构建更新的交易数据湖用例,人们将越来越关注优化这些 PB 级生产环境以降低成本、提高效率和实现高可用性。这篇文章演示了提高在 亚马逊云科技 上运行的 Apache Iceberg 开放表格式的运营效率的机制。
要了解有关 Apache Iceberg 的更多信息并为您的交易数据湖用例实现这种开放表格式,请参阅以下资源:
-
Apache Iceberg 表格规格 -
亚马逊 EMR 上的 Apache Iceberg 支持 -
使用安装了 Iceberg 的集群
作者简介
 Avijit Goswami
是 亚马逊云科技 的首席解决方案架构师,专门研究数据和分析。他支持 亚马逊云科技 战略客户使用 亚马逊云科技 托管服务和开源解决方案在 亚马逊云科技 上构建高性能、安全和可扩展的数据湖解决方案。工作之余,Avijit 喜欢旅行、在旧金山湾区步道上徒步旅行、观看体育赛事和听音乐。
Avijit Goswami
是 亚马逊云科技 的首席解决方案架构师,专门研究数据和分析。他支持 亚马逊云科技 战略客户使用 亚马逊云科技 托管服务和开源解决方案在 亚马逊云科技 上构建高性能、安全和可扩展的数据湖解决方案。工作之余,Avijit 喜欢旅行、在旧金山湾区步道上徒步旅行、观看体育赛事和听音乐。
 Rajarshi Sarkar
是亚马逊 EMR/Athena 的软件开发工程师。他致力于开发亚马逊 EMR/Athena 的前沿功能,还参与了 Apache Iceberg 和 Trino 等开源项目。在业余时间,他喜欢旅行、看电影和和朋友一起出去玩。
Rajarshi Sarkar
是亚马逊 EMR/Athena 的软件开发工程师。他致力于开发亚马逊 EMR/Athena 的前沿功能,还参与了 Apache Iceberg 和 Trino 等开源项目。在业余时间,他喜欢旅行、看电影和和朋友一起出去玩。
 普拉尚特·辛格
是 亚马逊云科技 的软件开发工程师。他对数据库和数据仓库引擎感兴趣,并曾在 EMR 上优化 Apache Spark 性能。他是 Apache Spark 和 Apache Iceberg 等开源项目的积极贡献者。在空闲时间,他喜欢探索新地方、食物和徒步旅行。
普拉尚特·辛格
是 亚马逊云科技 的软件开发工程师。他对数据库和数据仓库引擎感兴趣,并曾在 EMR 上优化 Apache Spark 性能。他是 Apache Spark 和 Apache Iceberg 等开源项目的积极贡献者。在空闲时间,他喜欢探索新地方、食物和徒步旅行。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。