我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 SageMaker 提高 Llama 2 模型的吞吐量性能
在机器学习 (ML) 的广泛采用方面,我们正处于激动人心的转折点,我们相信生成式人工智能将重塑大多数客户体验和应用程序。生成式 AI 可以创造新的内容和想法,包括对话、故事、图像、视频和音乐。与大多数 AI 一样,生成式 AI 由 ML 模型提供支持,机器学习模型是根据大量数据进行训练的超大型模型,通常被称为基础模型 (FM)。FM 基于变压器。由于模型庞大,变形金刚在生成长文本序列时速度缓慢且消耗大量内存。用于生成文本序列的大型语言模型 (LLM) 需要大量的计算能力,并且难以访问可用的高带宽内存 (HBM) 和计算容量。这是因为很大一部分可用内存带宽是由加载模型的参数和
总体而言,法学硕士的生成式推断面临三个主要挑战(根据
- 由于解码过程中的大量模型参数和瞬态状态,会占用大量内存。这些参数通常会超过单个加速器芯片的内存。注意键值缓存也需要大量内存。
- 低并行性会增加延迟,尤其是在内存占用量大的情况下,每一步都需要传输大量数据才能将参数和缓存加载到计算内核中。这导致满足延迟目标所需的总内存带宽很高。
- 注意力机制的计算相对于序列长度的二次缩放加剧了延迟和计算挑战。
批处理是应对这些挑战的技术之一。批处理是指将多个输入序列一起发送到 LLM,从而优化 LLM 推理性能的过程。这种方法有助于提高吞吐量,因为不需要为每个输入序列加载模型参数。这些参数可以加载一次并用于处理多个输入序列。批处理可以高效地利用加速器的 HBM 带宽,从而提高计算利用率、提高吞吐量和进行具有成本效益的推理。
这篇文章探讨了在 LLM 中使用批处理技术实现并行生成推断的最大吞吐量的技术。我们将讨论不同的批处理方法,以减少内存占用,提高并行性,并缓解注意力的二次扩展,从而提高吞吐量。目标是充分使用 HBM 和加速器等硬件来克服内存、I/O 和计算方面的瓶颈。然后,我们将重点介绍
大型语言模型 (LLM) 的推理
自回归解码是像 GPT 这样的语言模型每次生成一个标记的文本输出的过程。它涉及以递归方式将生成的令牌作为输入序列的一部分反馈到模型中,以预测后续令牌。步骤如下:
- 该模型接收序列中先前的令牌作为输入。第一步,这是用户提供的起始提示。
- 该模型预测下一个代币的词汇分布情况。
-
选择预测概率最高的代币并将其附加到输出序列中。步骤 2 和 3 是
解码 的一部分。在撰写本文时,最主要的解码方法是贪婪搜索、光束搜索、对比搜索和采 样。 - 此新标记将添加到输入序列中,用于下一个解码步骤。
- 模型遍历这些步骤,每步生成一个新标记,直到生成序列末尾标记或达到所需的输出长度。
为 LLM 提供模型服务
LLM 的模型服务是指接收输入请求以生成文本、进行推断并将结果返回给请求应用程序的过程。以下是模型服务涉及的关键概念:
- 客户端生成多个推理请求,每个请求由令牌序列或输入提示组成
-
请求由推理服务器接收(例如, djl Serving、TorchServe 、 Triton 或 Hugging Fac e T GI) -
推理服务器对推理请求进行批处理,并将批处理调度到执行引擎,该引擎包括模型分区库(例如 Transform ers-NeuronX 、 ate 或DeepSpeed 、 AccelerFast erTransformer ) ,用于在生成语言模型上运行前向传递(预测输出令牌序列) - 执行引擎生成响应令牌并将响应发送回推理服务器
- 推理服务器使用生成的结果回复客户端

当推理服务器在请求级别与执行引擎交互时,请求级调度会面临挑战,例如每个请求都使用 Python 进程,这需要单独的模型副本,这会受到内存限制。例如,如下图所示,您只能在总加速器设备内存为 96 GB 的机器学习 (ML) 实例上加载大小为 80 GB 的模型的单个副本。如果您想同时处理其他请求,则需要加载整个模型的额外副本。这不是内存,而且不具成本效益。

现在我们已经了解了请求级调度带来的挑战,让我们来看看可以帮助优化吞吐量的不同批处理技术。
批处理技巧
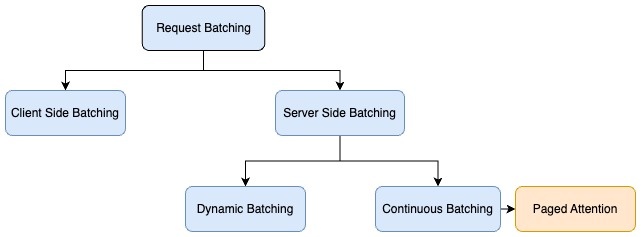
推理请求的批处理主要有两种类型:
- 客户端(静态) — 通常,当客户端向服务器发送请求时,服务器将默认按顺序处理每个请求,这对于吞吐量来说并不是最佳的。为了优化吞吐量,客户端对单个负载中的推理请求进行批处理,服务器实现预处理逻辑,将批次分解为多个请求,并分别对每个请求运行推理。在此选项中,客户端需要更改批处理代码,并且解决方案与批量大小紧密相关。
- 服务器端(动态) — 另一种批处理技术是使用推理来帮助在服务器端实现批处理。当独立的推理请求到达服务器时,推理服务器可以在服务器端将它们动态地分组成更大的批次。推理服务器可以管理批处理以满足指定的延迟目标,从而最大限度地提高吞吐量,同时保持在所需的延迟范围内。推理服务器会自动处理此问题,因此无需更改客户端代码。服务器端批处理包括不同的技术,用于进一步优化基于自动回归解码的生成语言模型的吞吐量。这些批处理技术包括动态批处理、连续批处理和 PageDattention (vLLM) 批处理。
动态批处理
动态批处理是指合并输入请求并将它们作为批处理发送在一起以进行推理。动态批处理是一种通用的服务器端批处理技术,适用于所有任务,包括计算机视觉 (CV)、自然语言处理 (NLP) 等。
- batch_siz e — 指批次的大小
- max_batch_delay — 指批量聚合的最大延迟
如果满足这两个阈值中的任何一个(达到最大批量大小或已完成等待期),则会准备一个新的批次并将其推送到模型中进行推理。下图显示了模型一起处理具有不同输入序列长度的请求的动态批处理。

尽管与不批处理相比,动态批处理最多可以将吞吐量提高四倍,但我们观察到,在这种情况下,GPU 利用率并不是最佳的,因为在所有请求都完成处理之前,系统无法接受另一批请求。
连续批处理
连续批处理是专用于文本生成的优化。它提高了吞吐量,并且不会牺牲第一个字节延迟的时间。连续批处理(也称为 迭代 批处理 或 滚动批处理 )可解决空闲 GPU 时间的挑战,并通过在批处理中持续推送新请求来进一步建立在动态批处理方法之上。下图显示了请求的连续批处理。请求 2 和请求 3 完成处理后,将调度另一组请求。

以下交互式图表深入探讨了连续批处理的工作原理。

(友情提供:
你可以使用一种强大的技术来提高 LLM 和文本生成的效率:缓存一些注意力矩阵。这意味着提示的第一轮与随后的向前传递不同。在第一轮中,你必须计算整个注意力矩阵,而后续只需要你计算新的代币注意力。 在 整个代码库中,第一阶段称为 预填充 ,而后续阶段称为 解码。 因为预填比解码要昂贵得多,所以我们不想一直这样做,但是当前正在运行的查询可能正在进行解码。如果我们想像前面解释的那样使用连续批处理,我们需要在某个时候运行预填以创建加入解码组所需的注意力矩阵。
通过有效利用空闲 GPU,与不进行批处理相比,该技术可以将吞吐量提高多达 20 倍。
您可以在 LMI 容器的 s
erving.properties
中微调以下参数以使用连续批处理:
-
引擎
— 代码的运行时引擎。
值包括使用Python、DeepSpeed、FasterTransform和 MP IMPI启用连续批处理。 -
rolling_batch — 使用支持的策略之一启用迭代级批
处理。
值包括我们使用自动、调度器和 lmi-dist。lmi-dist为 Llama 2 开启连续批处理。 - max_rolling_batch_siz e — 限制连续批次中的并发请求数。默认为 32。
-
max_rolling_batch_prefill_tokens — 限制
用于缓存的代币数量。这需要根据批量大小和输入序列长度进行调整,以避免 GPU 内存不足。它仅在 roll
ing_batch=lmi-dist 时才支持。我们的建议是根据并发请求数 x 存储每个请求的输入令牌和输出令牌所需的内存来设置值。
以下是用于配置连续批处理的 s
erving.properties
的示例代码:
页面关注批处理
在自回归解码过程中,LLM 的所有输入令牌都会生成注意力键和值张量,这些张量保存在GPU内存中以生成下一个令牌。这些缓存的键和值张量通常被称为
KV 缓存 或 注意力缓
存
。根据论文
PageDattion是加州大学伯克利分校开发的一种新的优化算法,它通过在固定大小的页面或块中分配内存来允许注意力缓存(KV 缓存)不连续地进行,从而改进了连续批处理过程。这受到操作系统使用的虚拟内存和分页概念的启发。
根据vLLM的论文,每个代币序列的注意力缓存被分成区块,并通过区块表映射到物理区块。在计算注意力的过程中,PageDattention 内核可以使用方块表高效地从物理内存中提取区块。这可以显著减少内存浪费,并允许更大的批处理大小、提高 GPU 利用率和更高的吞吐量。下图说明了如何将注意力缓存划分为不连续的页面。

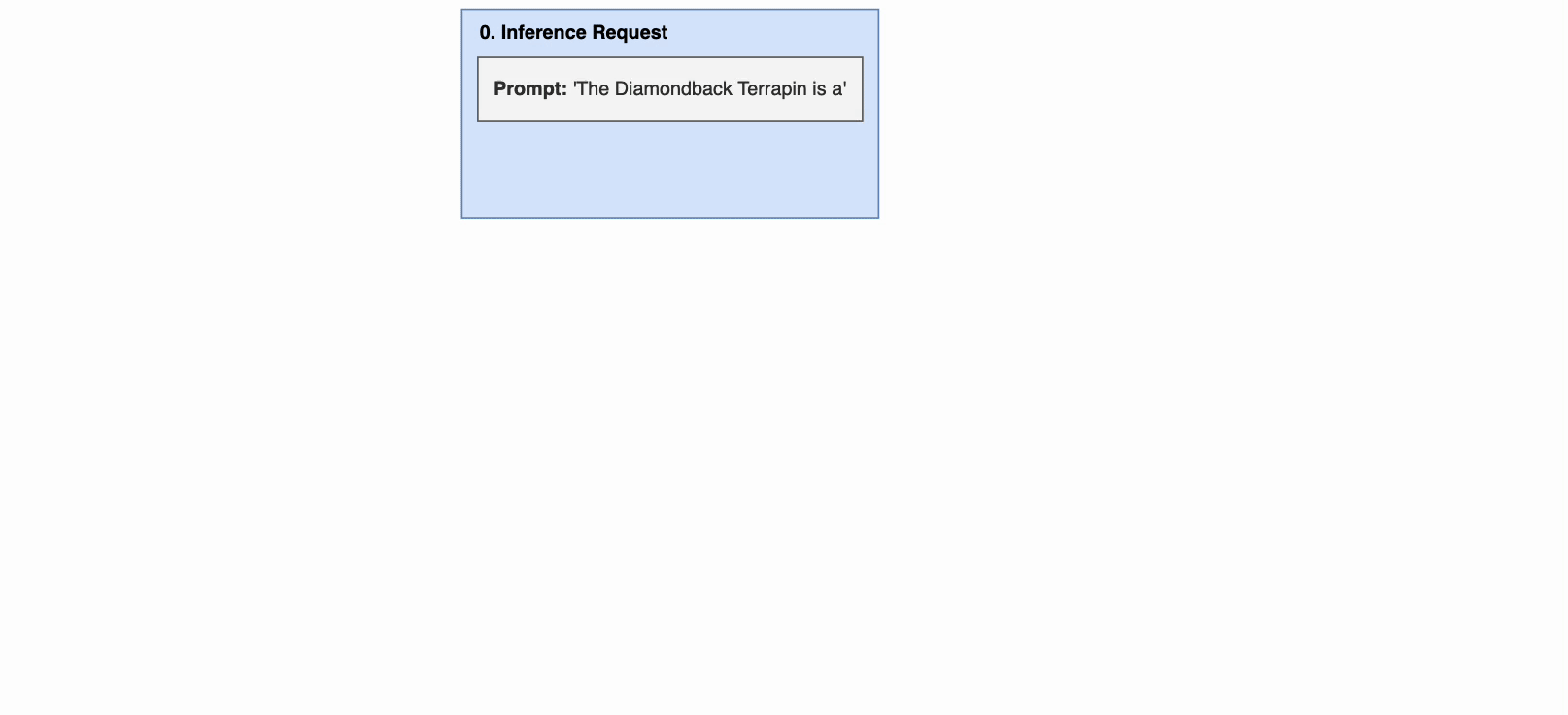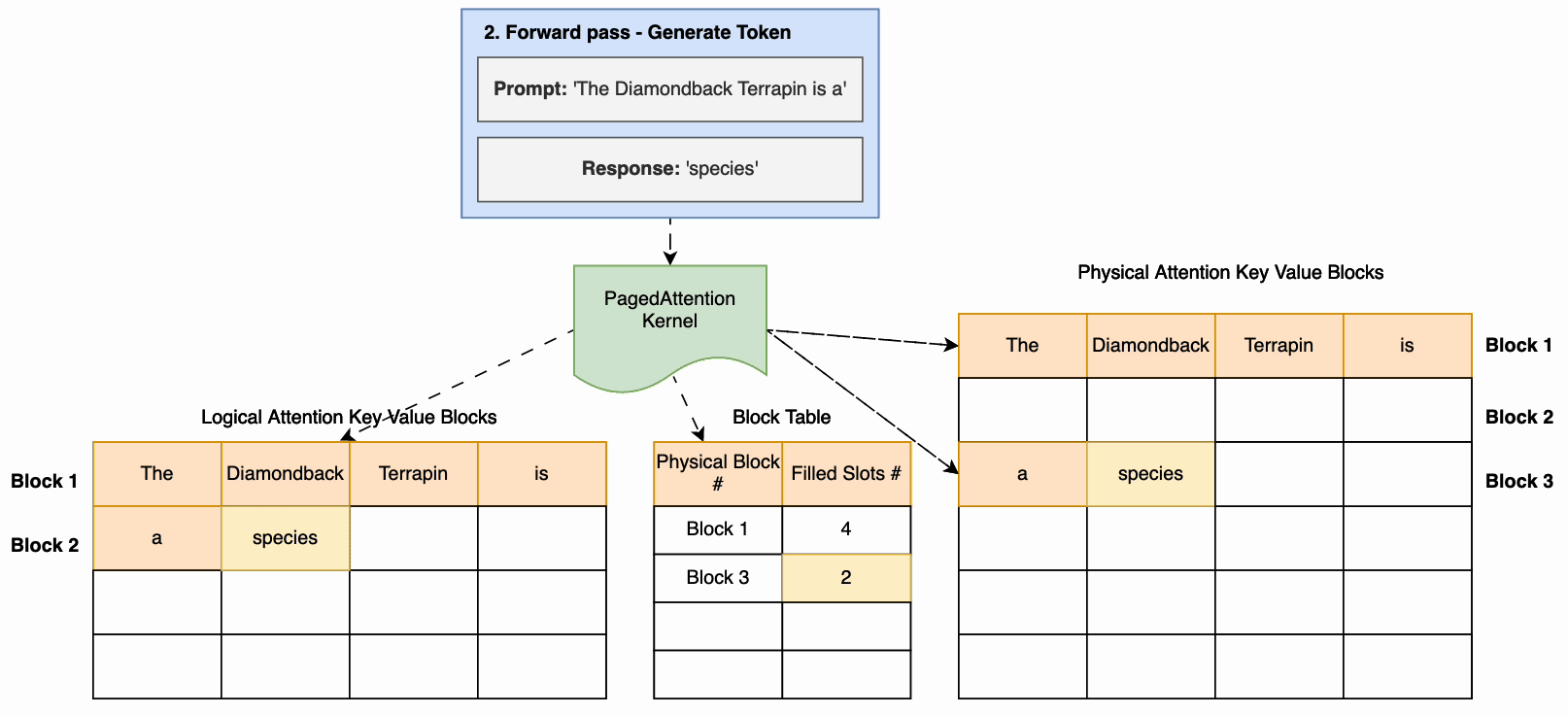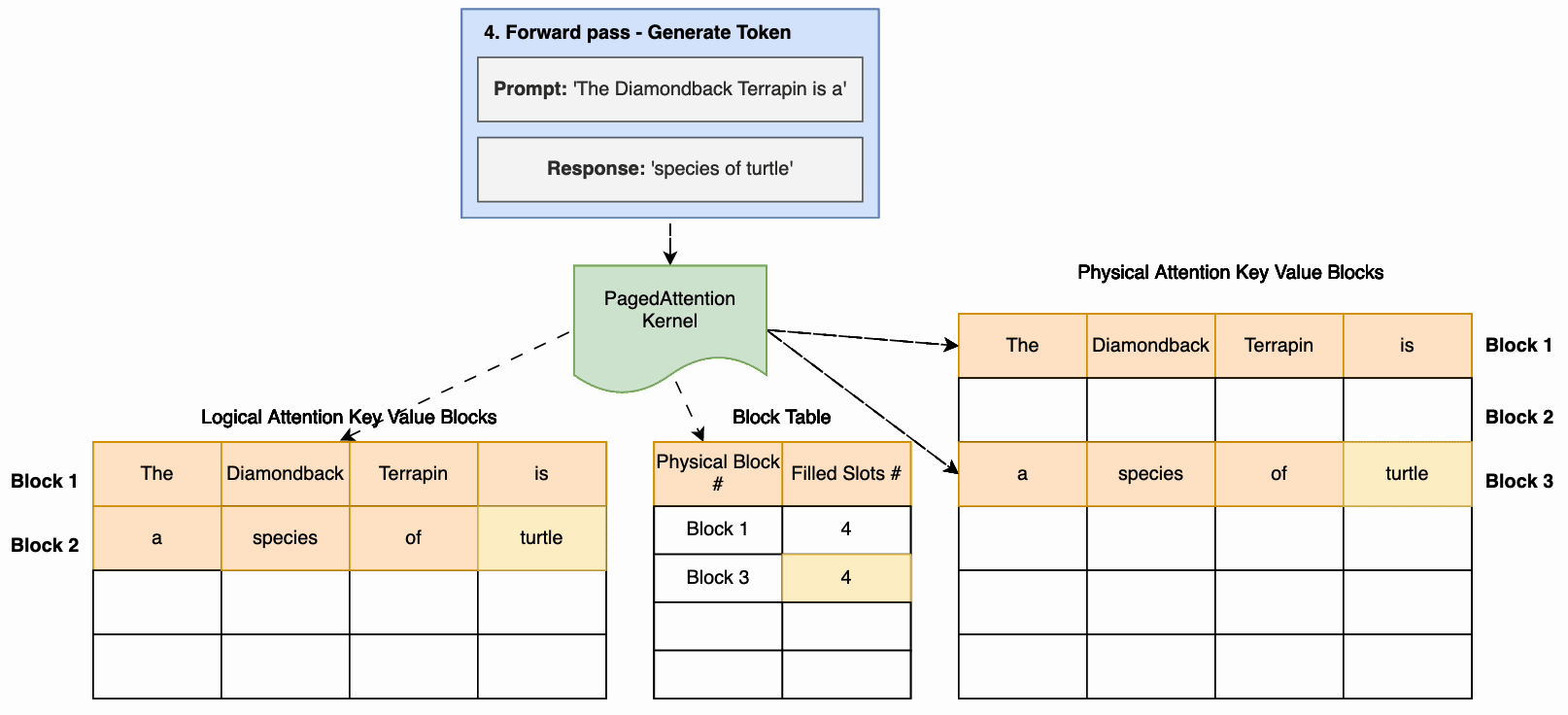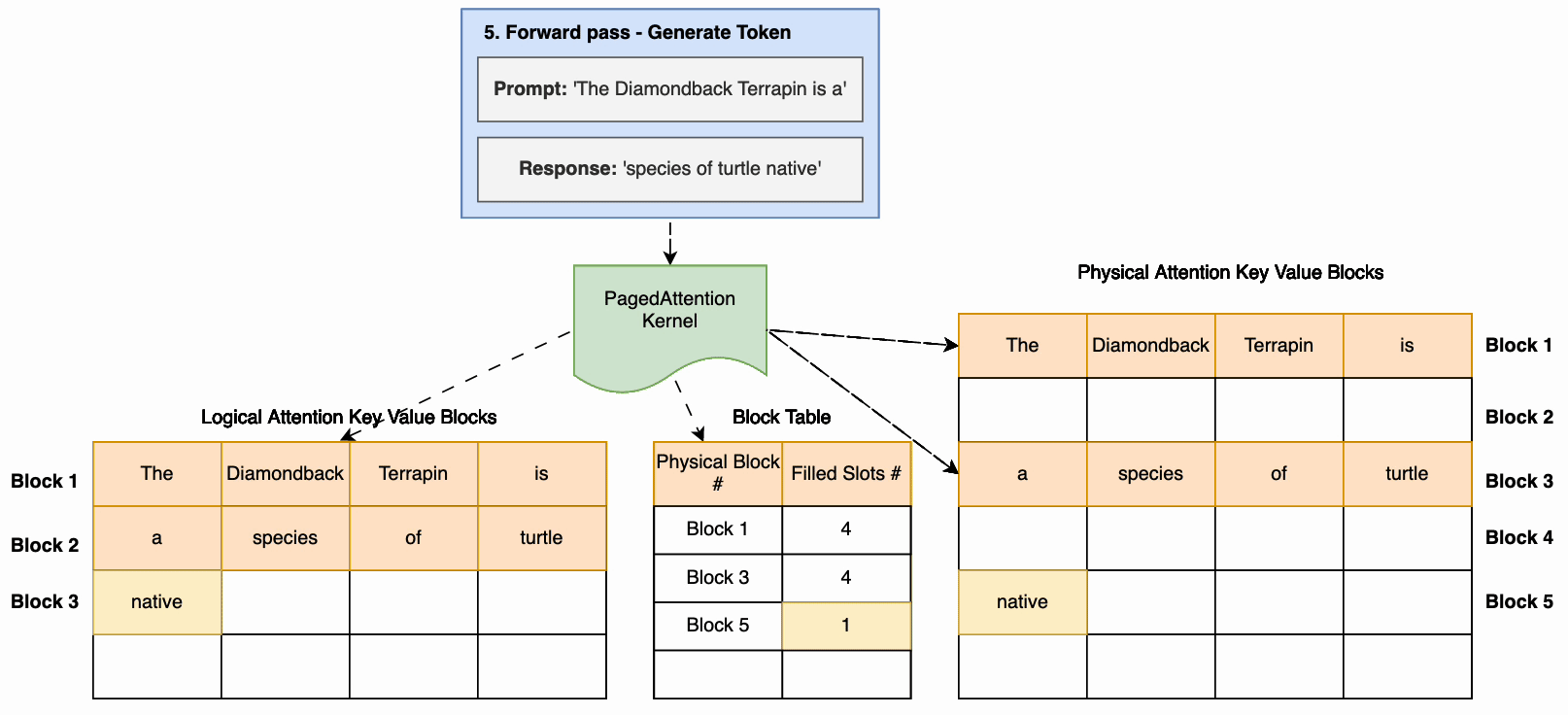
下图显示了使用 pageDattence 的推理示例。关键步骤是:
- 收到推理请求时会提示输入。
- 在预填阶段,计算注意力,将键值存储在非连续的物理内存中并映射到逻辑键值块。此映射存储在区块表中。
- 输入提示通过模型(向前传递)运行以生成第一个响应令牌。在生成响应令牌期间,使用预填阶段的注意力缓存。
- 在随后的代币生成过程中,如果当前的物理区块已满,则会以不连续的方式分配额外的内存,从而允许即时分配。
PageDattention 有助于实现接近最佳的内存使用率并减少内存浪费。这允许将更多请求批处理在一起,从而显著提高推理吞吐量。
以下代码是在 SageMaker 上的 LMI 容器中配置 PageDattence 批处理 的示例 s
erving.prop
erties:
何时使用哪种批处理技术
下图汇总了服务器端批处理技术以及 SageMaker 上 LMI 中的 s
erving.properties
示例。
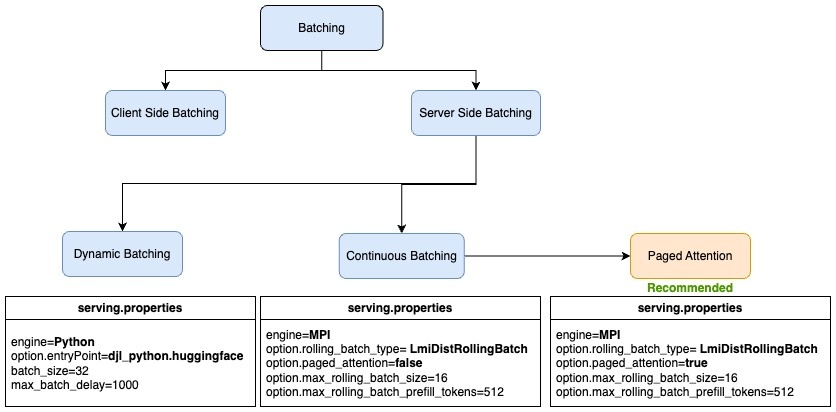
下表总结了不同的批处理技术及其用例。
| PagedAttention Batching | Continuous Batching | Dynamic Batching | Client-side Batching | No Batch | |
| How it works | Always merge new requests at the token level along with paged blocks and do batch inference. | Always merge new request at the token level and do batch inference. | Merge the new request at the request level; can delay for a few milliseconds to form a batch. | Client is responsible for batching multiple inference requests in the same payload before sending it to the inference server. | When a request arrives, run the inference immediately. |
| When it works the best |
This is the recommended approach for the
|
Concurrent requests coming at different times with the same decoding strategy. It’s suitable for throughput-optimized workloads. It’s applicable to only text-generation models. | Concurrent requests coming at different times with the same decoding strategy. It’s suitable for response time-sensitive workloads needing higher throughput. It’s applicable to CV, NLP, and other types of models. | It’s suitable for offline inference use cases that don’t have latency constraints for maximizing the throughput. | Infrequent inference requests or inference requests with different decoding strategies. It’s suitable for workloads with strict response time latency needs. |
SageMaker 上大型生成模型不同批处理技术的吞吐量比较
我们使用
我们使用了三种不同长度的输入提示进行性能测试。在连续批处理和 PageDattention 批处理中,三个输入提示的输出标记长度分别设置为 64、128 和 256。对于动态批处理,我们使用了 128 个令牌的一致输出令牌长度。我们为测试部署了 SageMaker 端点,其实例类型为 ml.g5.24xlarge。下表包含性能基准测试的结果。
| Model | Batching Strategy | Requests per Second on ml.g5.24xlarge |
| LLaMA2-7b | Dynamic Batching | 3.24 |
| LLaMA2-7b | Continuous Batching | 6.92 |
| LLaMA2-7b | PagedAttention Batching | 7.41 |
我们发现,与使用 LMI 容器在 SageMaker 上对 Llama2-7B 模型进行动态批处理相比,使用 PageDattention 批处理的吞吐量增加了大约 2.3 倍。
结论
在这篇文章中,我们解释了用于 LLM 推理的不同批处理技术以及它如何帮助提高吞吐量。我们展示了内存优化技术如何通过使用连续批处理和 PageDattention 批处理来提高硬件效率,并提供比动态批处理更高的吞吐量值。与使用 LMI 容器在 SageMaker 上对 Llama2-7B 模型进行动态批处理相比,我们看到,使用 PageDattention 批处理的吞吐量增加了大约 2.3 倍。你可以在
作者简介
 Gagan Singh
是 亚马逊云科技 的高级技术客户经理,他在那里与数字原生初创公司合作,为他们的商业成功铺平道路。由于在推动机器学习计划方面占有一席之地,他利用了亚马逊 SageMaker,特别强调深度学习和生成式人工智能解决方案。在空闲时间,加根在喜马拉雅山脉的小径上徒步旅行并沉浸在各种音乐流派中找到了慰藉。
Gagan Singh
是 亚马逊云科技 的高级技术客户经理,他在那里与数字原生初创公司合作,为他们的商业成功铺平道路。由于在推动机器学习计划方面占有一席之地,他利用了亚马逊 SageMaker,特别强调深度学习和生成式人工智能解决方案。在空闲时间,加根在喜马拉雅山脉的小径上徒步旅行并沉浸在各种音乐流派中找到了慰藉。
 达瓦尔·帕特尔
是 亚马逊云科技 的首席机器学习架构师。他曾与从大型企业到中型初创企业等组织合作,研究与分布式计算和人工智能有关的问题。他专注于深度学习,包括自然语言处理和计算机视觉领域。他帮助客户在 SageMaker 上实现高性能模型推断。
达瓦尔·帕特尔
是 亚马逊云科技 的首席机器学习架构师。他曾与从大型企业到中型初创企业等组织合作,研究与分布式计算和人工智能有关的问题。他专注于深度学习,包括自然语言处理和计算机视觉领域。他帮助客户在 SageMaker 上实现高性能模型推断。
 Venugopal Pai
是 亚马逊云科技 的解决方案架构师。他住在印度班加罗尔,帮助数字原生客户在 亚马逊云科技 上扩展和优化其应用程序。
Venugopal Pai
是 亚马逊云科技 的解决方案架构师。他住在印度班加罗尔,帮助数字原生客户在 亚马逊云科技 上扩展和优化其应用程序。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。