我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
将亚马逊 CloudWatch 警报与亚马逊 CloudWatch 指标见解集成
实时警报对于主动了解系统何时无法按预期运行或采取自动纠正措施非常重要。警报使您有时间在问题导致停机之前进行调查和修复。但是,您想要应用警报的系统和指标并不总是那么简单。当警报应用于单一资源的单一指标(例如
关于 CloudWatch 指标见
借助 CloudWatch Metrics Insights,您可以轻松查询和分析指标,从而更好地了解基础设施和大规模应用程序的运行状况和性能。
虽然 Metrics Insights 附带标准 SQL 语言,但您也可以使用可视化查询生成器开始使用指标见解。查询生成器可帮助你在不知道 SQL 的情况下直观地构建查询。您可以直观地选择感兴趣的指标、命名空间和维度,控制台会根据选择自动构造 SQL 查询。
要开始使用 Metrics Insights,你可以按照文档
关于云观警报
当应用程序和基础设施指标超过静态或动态设定的阈值时,Amazon CloudWatch 警报用作提醒您或自动采取补救措施的手段。CloudWatch 警报可缩短检测、分类和诊断影响工作负载性能的问题的时间,从而帮助您提高基础设施监控效率。
要开始使用 CloudWatch 警报,你可以按照文档 “
常见用例
使用 Metrics Insights 查询创建的警报允许您同时监控多个资源。Metrics Insight 查询会自动包含与其定义相匹配的新资源。例如,您可以使用单个警报监控多个自动扩展组,而不必担心在向任何自动扩展组进行扩展操作时添加或删除实例。它消除了与创建和管理每个指标和每个资源的警报相关的无差别繁重工作。
您可以在此 处找到 M
我们的解决方案
我们将创建以下资源
-
2 个
自动扩展组 - 使用 Metrics Insights 查询提醒
启动 EC2 实例
警报是根据指标创建的,因此我们必须有一些指标才能开始。在这篇博客中,我们将演示使用指标洞察查询创建 CloudWatch 警报,该查询可以包含多个 EC2 实例。例如,我们将部署 2 个自动扩展组,但在实际场景中,可能是数百个自动扩展组或单个实例。
使用使用
使用指标洞察查询创建 CloudWatch 警报
我们将使用指标洞察查询演示 2 个警报。第一个警报将在所有 EC2 实例的平均 CPU 使用率超过 70% 时触发,第二个警报将在任何单个实例的 CPU 使用率超过 80% 时触发
-
在 亚马逊云科技 控制台中打开
云观察 。单击 CloudWatch 左侧 导航 中 “指标 ” 下的 “ 所有 指标
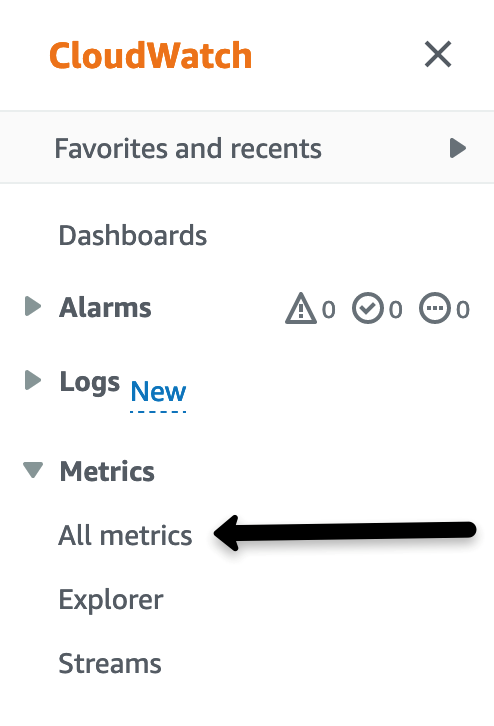
图 1。云监控控制台。
- 选择 “所有指标” 后,选择 “ 查询 ” 选项卡以显示 “ 指标见解” 查询生成器
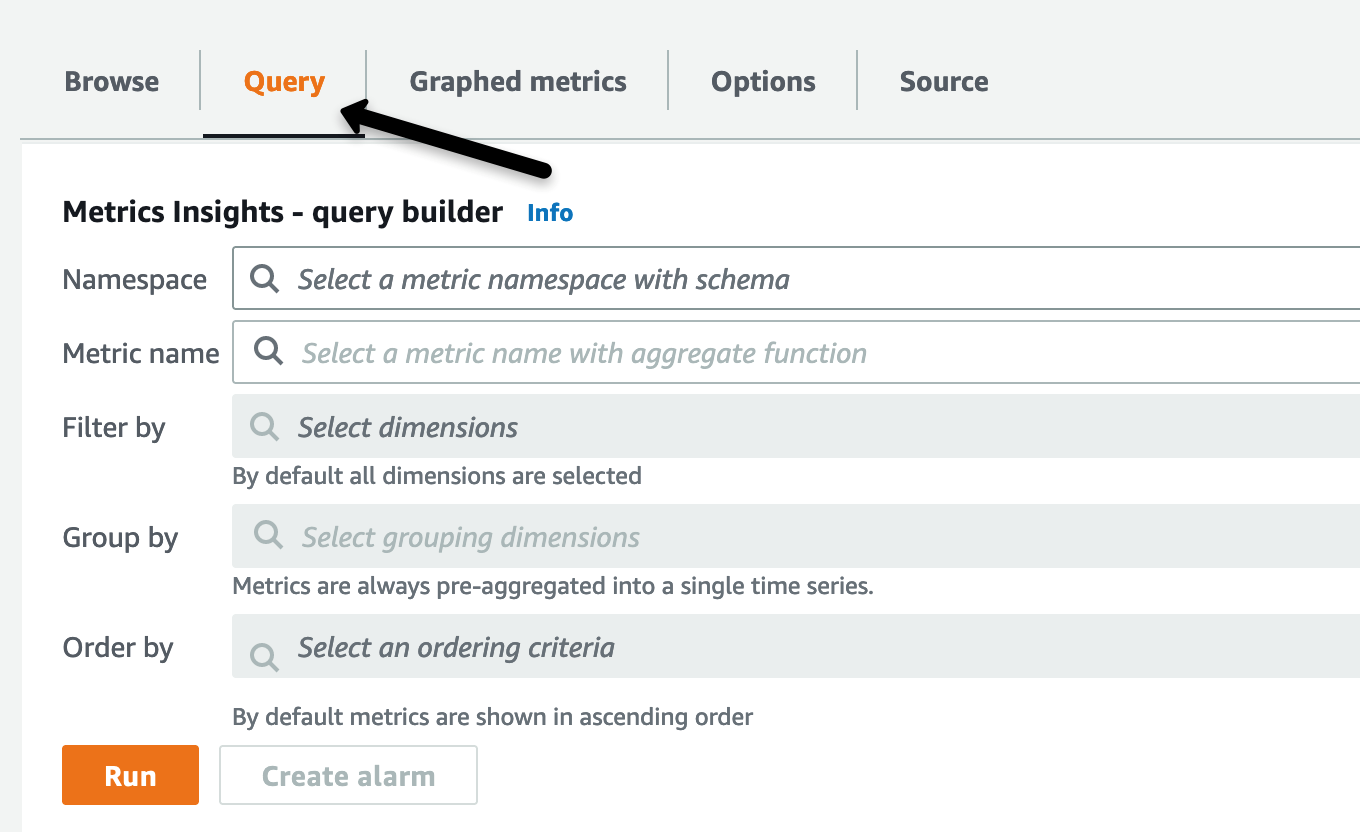
图 2。指标见解查询生成器。
图 2 显示了当你直观地选择命名空间和维度时,控制台如何根据你的选择自动为你构造 SQL 查询。您可以随时使用查询编辑器键入原始 SQL 查询,以更详细地深入研究和查明问题。
- 对于第一个警报,将 命名空间 指定 为 亚马逊云科技/EC2 ,然后选择 每 实例指标。 在 “ 指标名称 ” 下 ,选择 AVG 函数,选择 CPU 利用率 ,然后单击 “运行”。
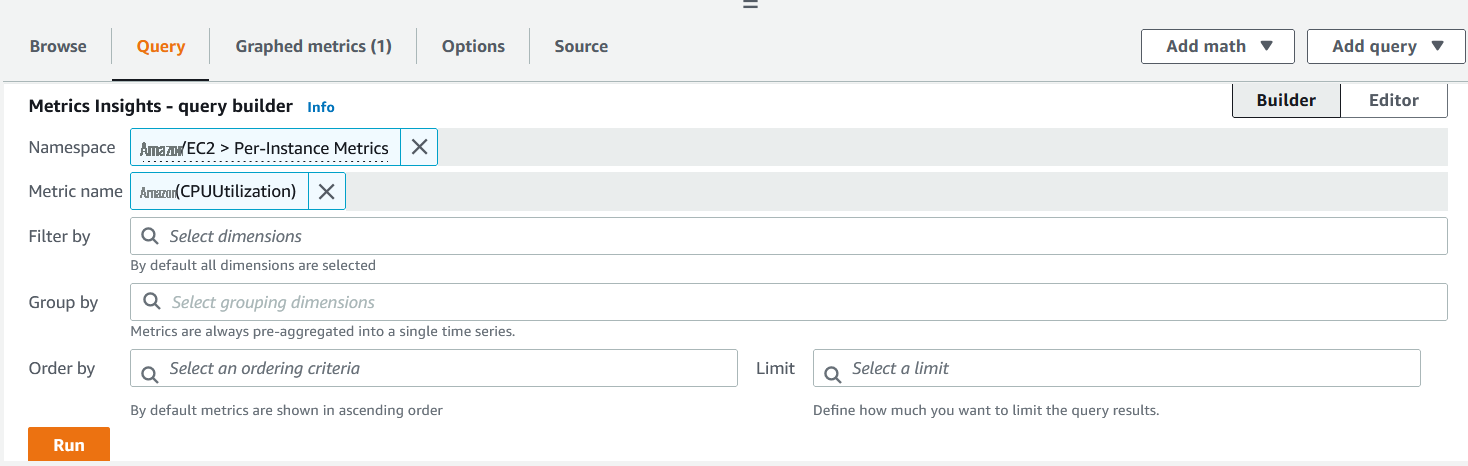
图 3。运行指标洞察查询。
除了 AVG 之外 ,还有其他函数,例如 总和 、 计数 、 最小 值 和最大值 , 可用于聚合指标。
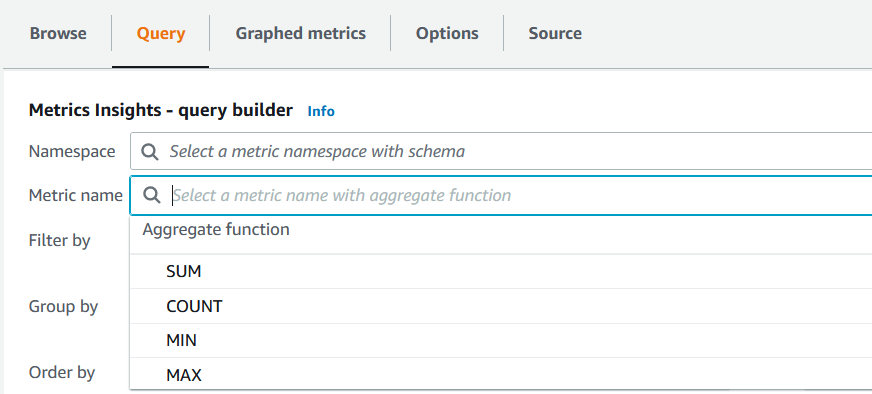
图 4。聚合函数。
- 单击 “ 运行 ” 后 ,您应该能够看到绘制的所有 EC2 实例的平均 CPU 使用率图表。点击 图表化指标 。
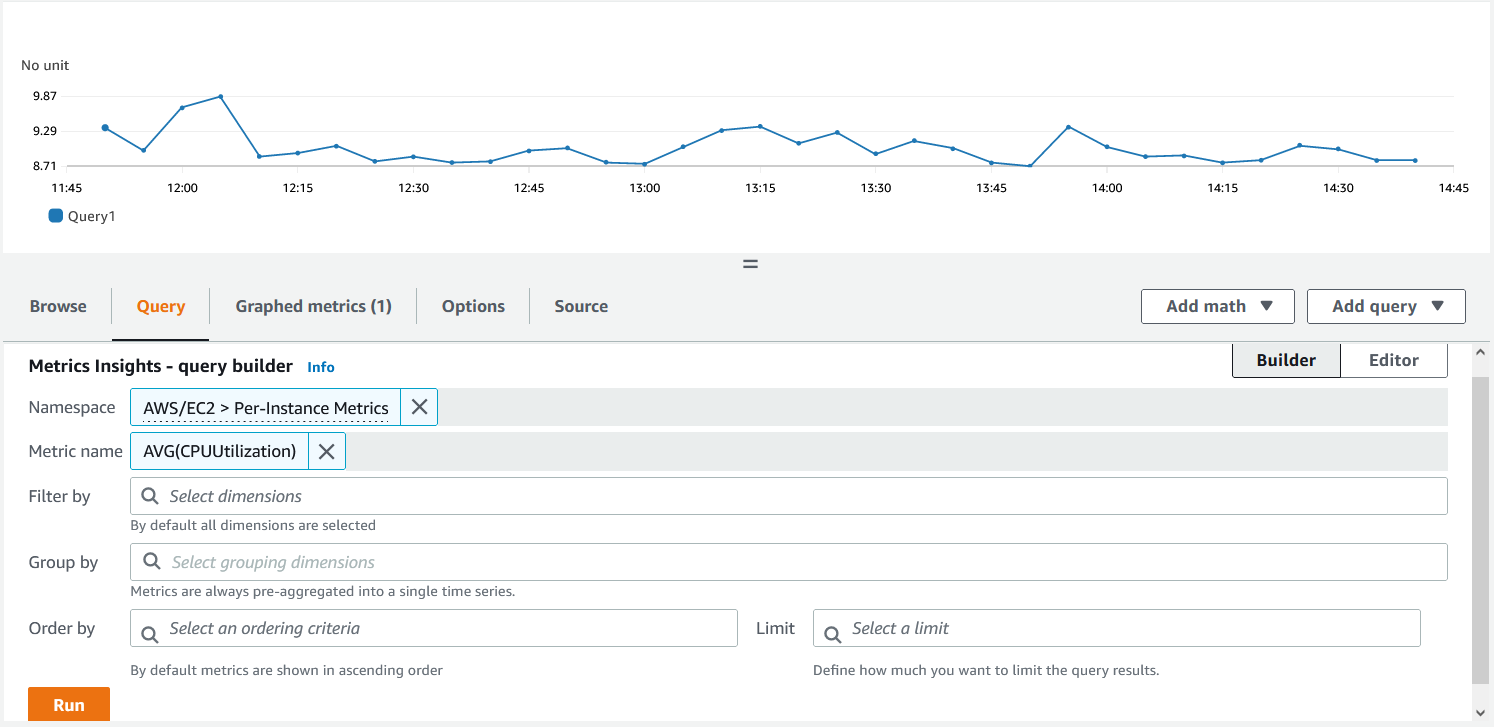
图 5。使用指标见解查询绘制图表。
- 在 “ 图表化指标 ” 下 ,您可以通过单击 “ 详细信息 ” 下黄色突出显示的部分来查看完整的 SQL 查询。单击 “ 操作 ” 下的警报图标(以橙色突出显示) 以创建警报

图 6。绘制指标的图表。
- 接下来,在 创建警报 页面上,您可以配置 指标评估 的时间段 和警报的阈值。为指标设置阈值后,页面上会显示一条代表阈值的红线。
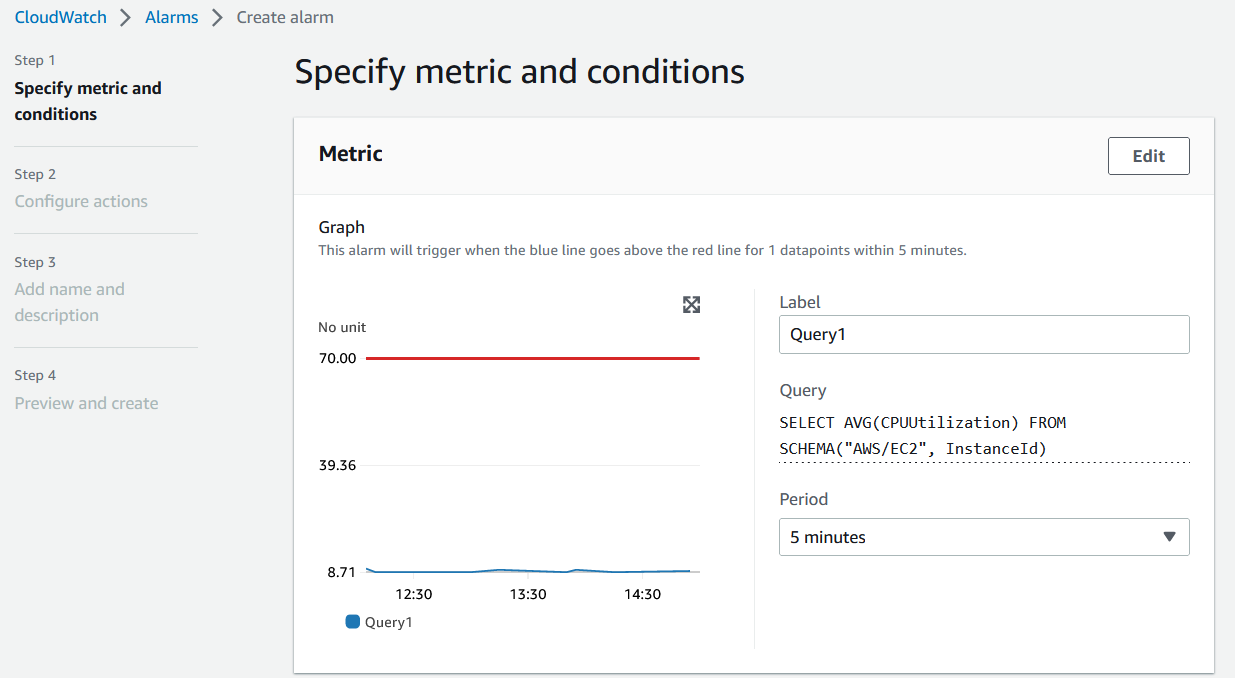
图 7。创建警报。
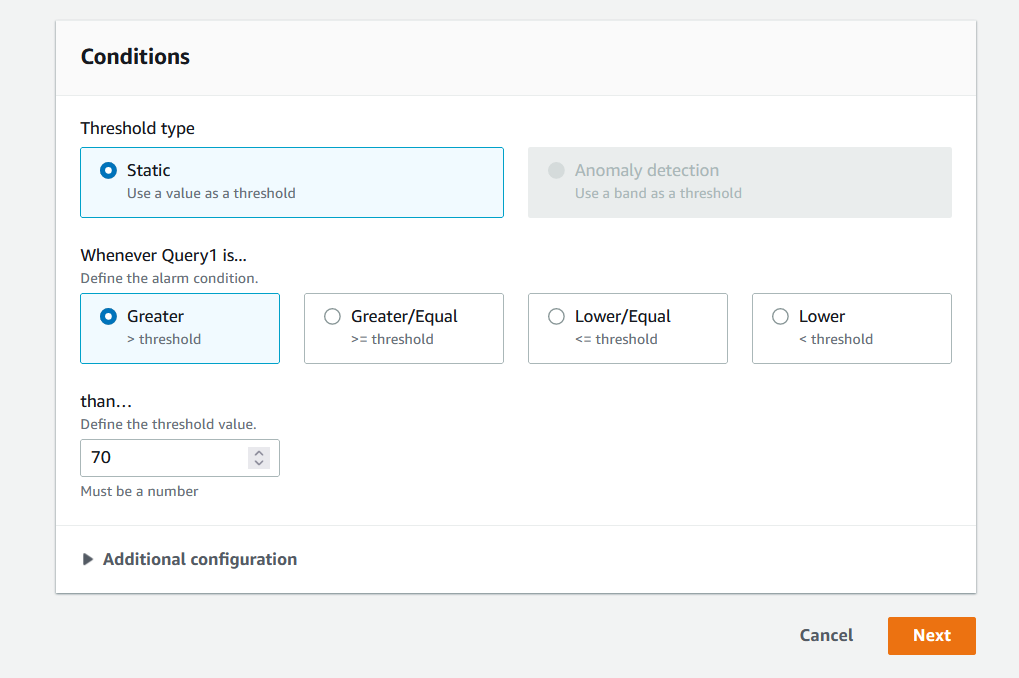
图 8。指定警报条件。
您也可以单击 “ 查询 ” 并查看完整的查询。当查询很长且跨越多行时,这很有用。
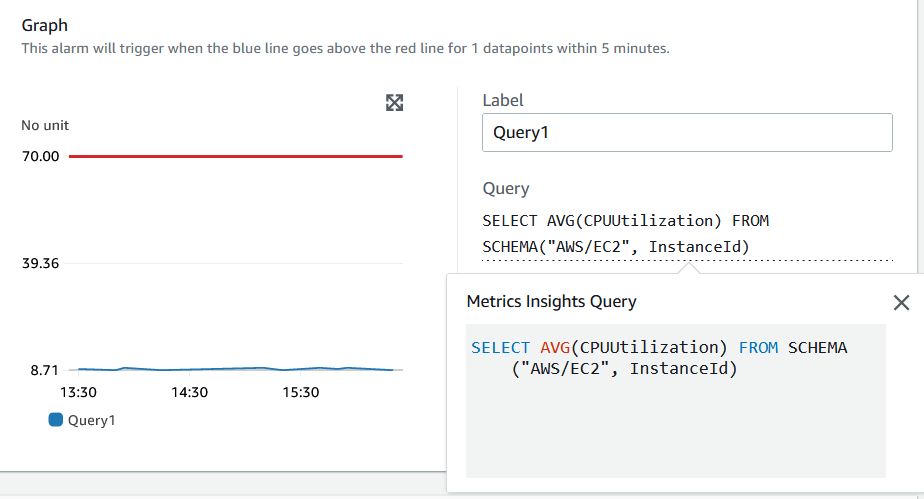
图 9。在创建警报页面上完成查询。
- 在 “ 配置操作 ” 页面上,可以添加通知的 SNS 主题,然后单击 “下一步”
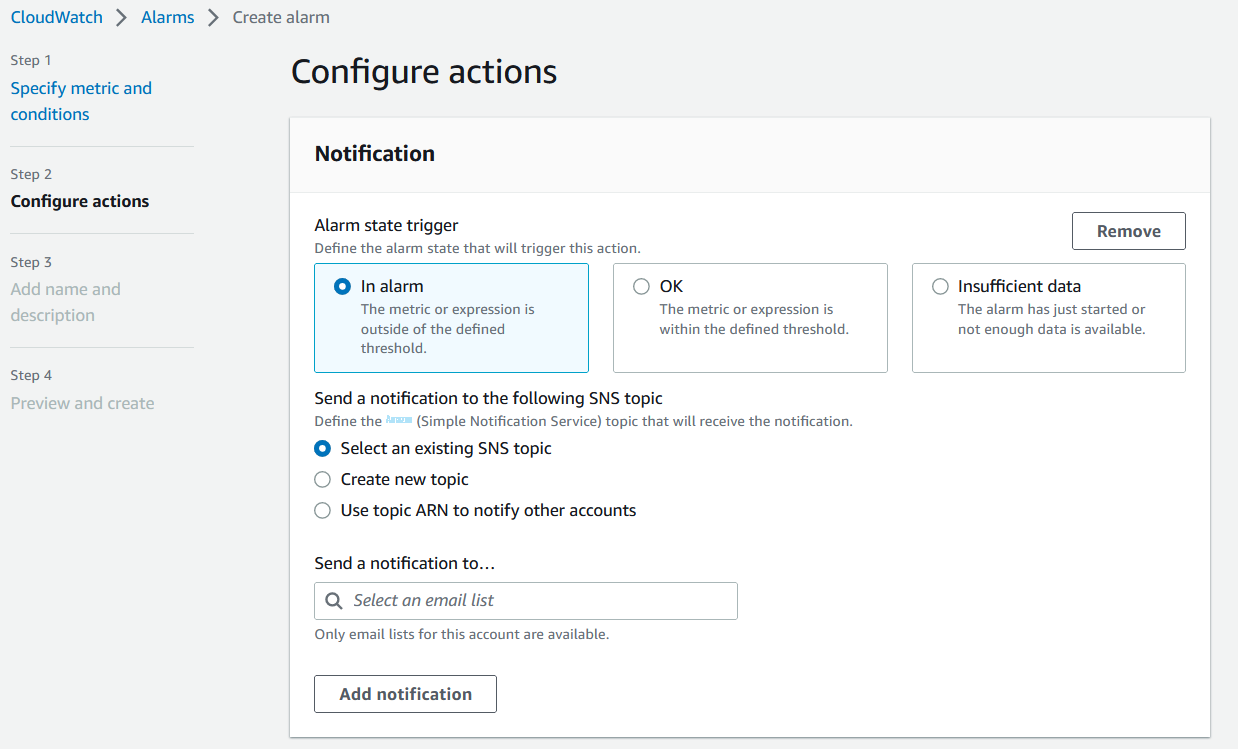
图 10。配置警报操作。
- 在下一页上,您可以为警报添加有意义的名称和描述。
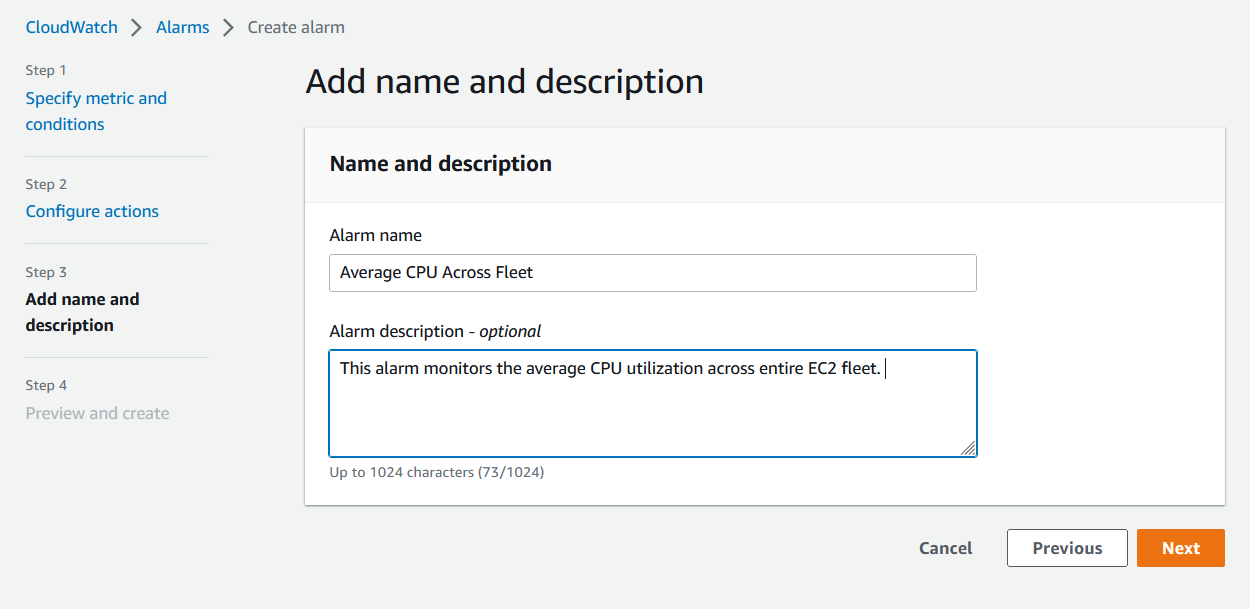
图 11。提供警报名称和描述。
- 最后 ,选择 “ 下一步 ” 查看警报设置,然后单击 “ 创建警报 ” 以完成警报创建。
- 要为 “任何 CPU 使用率超过 80%” 创建第二个警报,您可以通过添加按 实例 ID 分 组 和按 最大值排序 () 函数 DESC(降 序 )来更改步骤 4 中使用的查询。此查询将返回每个实例的时间序列数据,按 CPU 使用率降序排序。
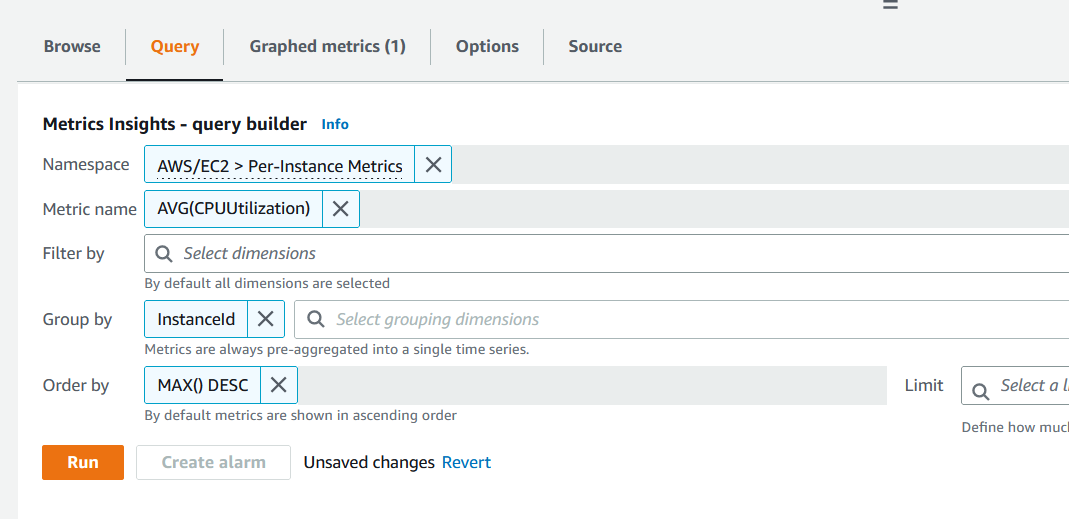
图 12。按查询运行分组。
- 单击 “ 运行 ” 后 ,您会注意到返回了多个时间序列,并且为每个实例绘制了一个单独的图形。

图 13。多个时间序列。
- 目前,多个时间序列不支持警报,因此您需要使用指标数学函数来获取单个时间序列。单击 “ 图表化指标 ” 选项卡。在 图形化指标 中 ,点击添加数学(以橙色突出显示)、 所有函数 , 然后选择 第一个 函数(以黄色突出显示)。此函数将返回所有时间序列数据中的第一个时间序列。
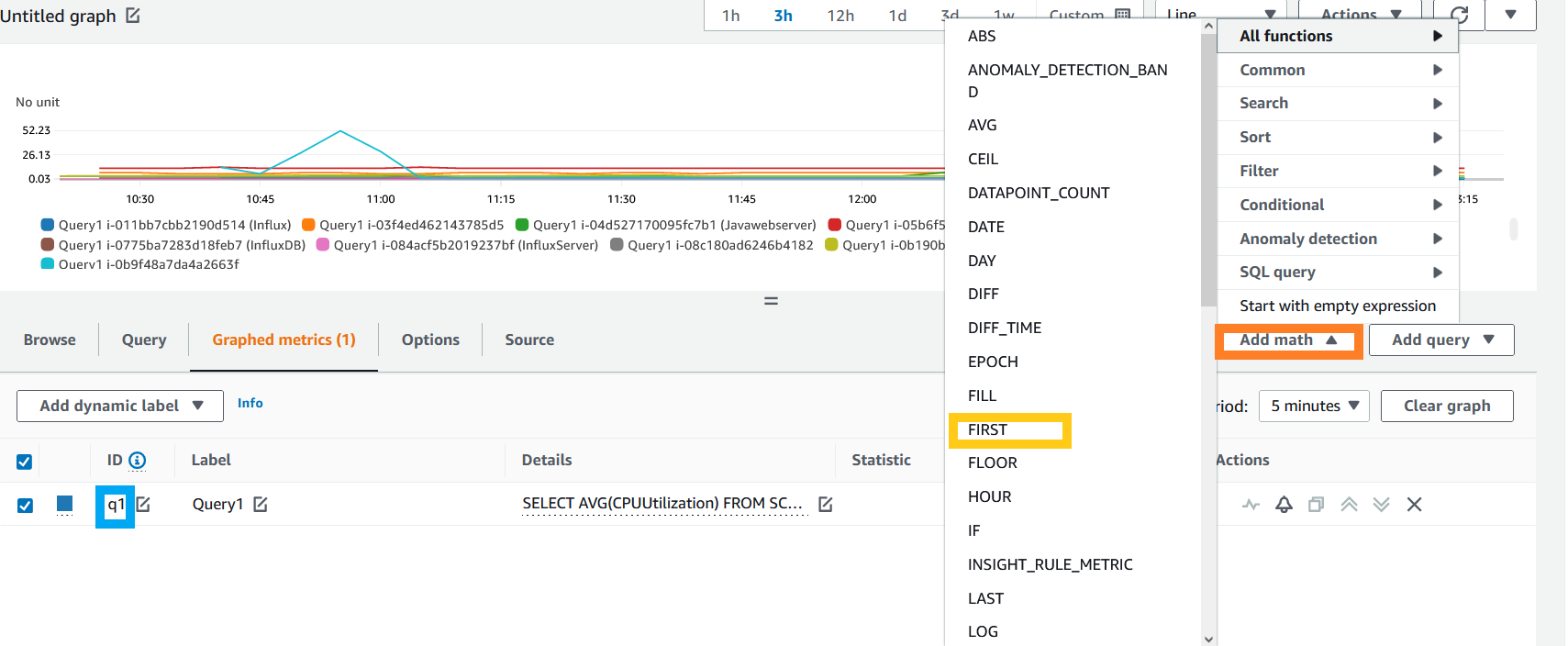
图 14。添加指标数学函数。
另请注意我们的指标洞察查询 q1 的标签(以蓝色突出显示)。我们将使用它来衡量数学的 FIRST 函数。
- 更新指标数学函数定义,然后单击 A pply 。
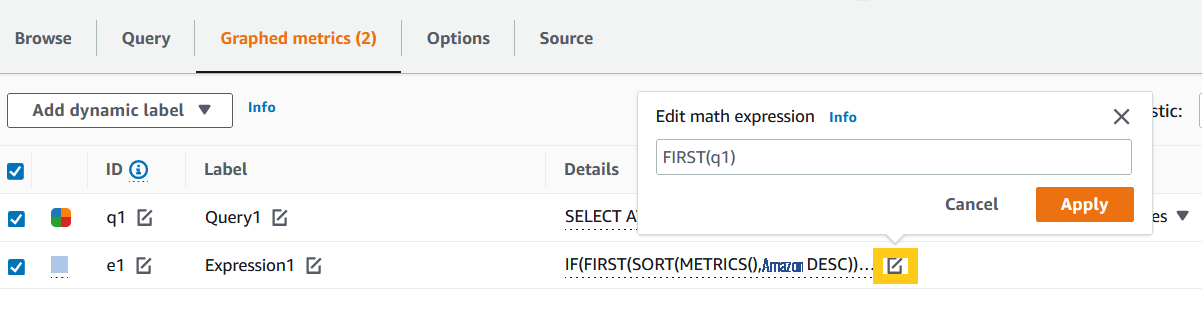
图 15。用于生成单个时间序列的度量数学函数。
- 取消选中 Metrics Insight 查询的复选框,然后点击指标数学函数旁边的警报图标。这将带您进入 创建警报 页面,在该页面中,您可以按照与以前相同的流程配置警报阈值,选择 SNS 主题,然后创建警报。

图 16。使用指标数学创建警报。
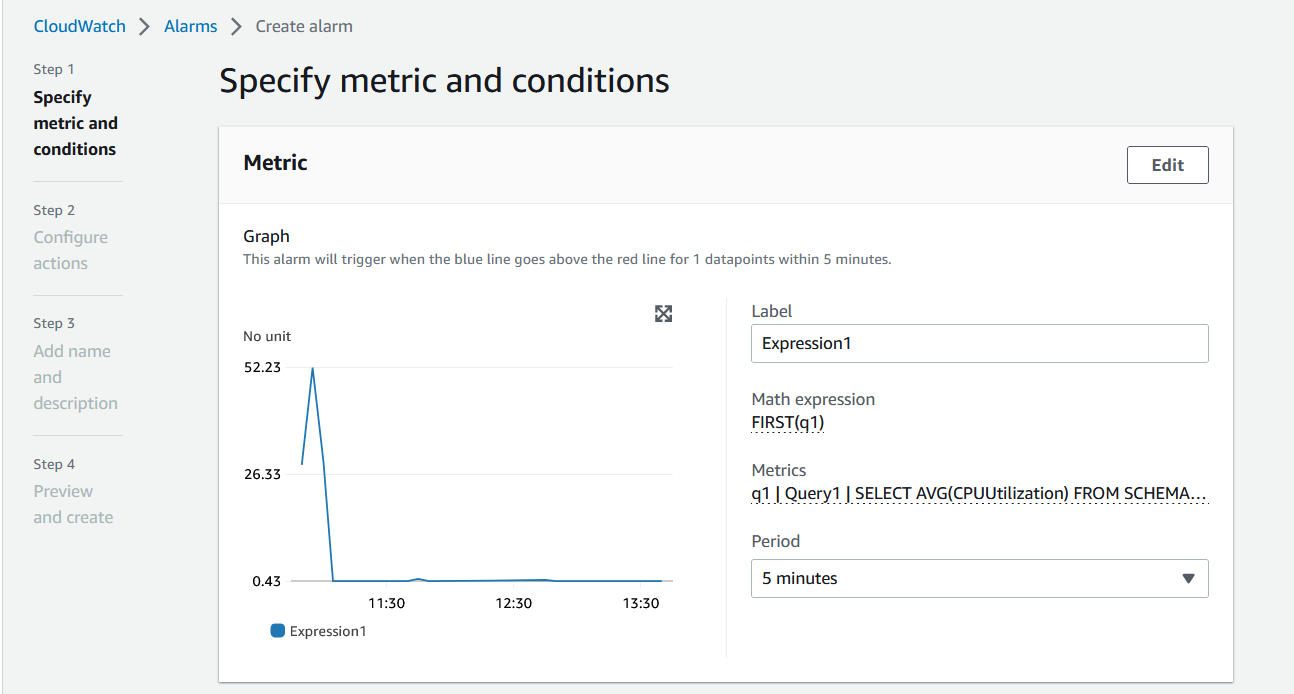
图 17。指定警报条件。
现在,您已经使用 Metrics Insights 查询创建了警报,它将自动包含单独部署甚至作为自动扩展组的一部分部署的任何新 EC2 实例的指标。
现在您已经安装了警报,您可以为实例生成负载并查看这些警报的运行情况。
警报后该怎么做
如果整个队列的平均 CPU 使用率突破阈值,您可以调查是否存在/存在任何特定的实例/实例导致该阈值。你可以使用指标洞察来获取这些信息。
如果单个实例的 CPU 使用率超过阈值,则可以使用 Metrics Insights 来识别实例 ID 并对其进行进一步的故障排除。识别实例 ID 的步骤也可以使用
定价
标准的
清理
为避免您的账户产生费用,请删除您创建的资源。
-
删除 CloudWatch 警报:请参阅有关
编辑或删除 CloudWatch 警报的 文档 -
删除自动扩展组:请参阅 “
删除您的自动扩展基础架构” 的文档
结论
这篇文章演示了如何利用 Metrics Insights 查询来创建动态警报,该警报可以同时监控多个资源,而无需对每个资源进行配置。
作者简介:
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。