我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
介绍亚马逊 CloudWatch 网络监控器
亚马逊云科技刚刚宣布发布一项新的互联网监控服务,即A
Internet Monitor 根据您在 亚马逊云科技 上的工作负载足迹量身定制,提供对互联网测量结果的持续可观测性,例如可用性和性能。您可以使用 Internet Monitor 深入了解一段时间内的平均互联网性能指标,以及按位置和互联网服务提供商 (ISP) 划分的问题(事件)。使用 Internet Monitor,您可以轻松识别哪些事件正在影响由
Internet Monitor 在您的用户和应用程序之间架起互联网网络路径,从而创建完整的 CloudWatch 堆栈:
-
用户体验 —
CloudWatch 合成器 和 CloudWatch 真实用户监控 (RUM) - 互联网健康 — 互联网监视器
-
应用程序堆栈运行状况 — CloudWatch ServiceLens 和 A WS X-R -
资源运行状况 —
CloudWatch 指标 和云 观日志
互联网监视器组件
在我们向您展示互联网监视器的工作原理之前,让我们定义一些核心组件和概念。
- 监视器 :监视器是您的配置的容器,用于定义要监控的资源。
- 运行状况事件 :当 Internet Monitor 检测到您的流量性能明显下降时,它会创建运行状况事件。每个健康事件都包含有关受影响的客户位置和网络提供商 (ISP) 的信息。
- 性能和可用性分数(运行状况分数) :分别对应用程序未出现性能或可用性下降的流量百分比的统计估计值。这些分数也可以作为 CloudWatch 指标提供。
- CloudWatch 日志 :对于您的客户特定的位置和网络提供商,Internet Monitor 会向 CloudWatch Logs 发布测量结果,包括性能和可用性分数、传输的字节数和往返时间 (RTT)。
它是如何工作的
Internet Monitor 利用 亚马逊云科技 已经在不同的 亚马逊云科技 区域和边缘站点之间收集的数据,以及您的客户访问您的应用程序终端节点的网络之间的数据。这些连接数据由 亚马逊云科技 内部使用,用于主动检测互联网上的连接问题,然后采取措施改善客户体验。
对于每个 亚马逊云科技 区域,我们都知道互联网的哪些部分与该地区通信,因此我们可以积极监控它们。我们同时使用网络和更高级别的协议探测器,包括入站和出站。我们以这些性能和可用性衡量标准为基准,计算健康分数,以提高您在不同地理位置的最终用户遇到重大问题时的认识。创建监控器时,Internet Monitor 会根据您的资源创建流量配置文件,描述用户位置和每个监控器的流量百分比。然后,您的流量概况将与 亚马逊云科技 基准性能配置文件叠加,我们据此计算性能和可用性分数,显示与基准相比的预计降幅。
Internet Monitor 还通过显示使用不同 亚马逊云科技 服务或重新路由流量的性能指标,为缩短第一字节时间 (TTFB) 提供见解和建议。这可以帮助您了解如何通过使用 Amazon CloudFront 或通过不同的 亚马逊云科技 区域重新路由您的工作负载流量来改善用户体验。
对健康事件发出警报
创建监控器后,您可以通过多种方式收到有关 Internet Monitor 运行状况事件的警报。例如,您的选择可能取决于您的筛选要求、历史记录类型以及触发警报时的操作。健康事件警报选项包括:
-
CloudWatch 警报 ,基于互联网监控事件指标的性能和可用性分数 - CloudWatch 警报,基于使用 CloudWatch 日志中的指标筛选器生成的指标
-
亚马逊 Ev entBridge 规则,用于筛选 Internet Mon itor 生成的健康事件
当您需要更多指标来在应用程序控制面板中更精细地跟踪用户体验指标时,CloudWatch 警报非常有用。如果您在用户遇到影响但不会导致 Internet Monitor 创建健康事件时需要警报,也可以选择使用警报。EventBridge 允许您为 Internet Monitor 生成的事件创建事件驱动的自动响应。
先决条件
在以下部分中,我们假设您熟悉基本的 亚马逊云科技 网络服务,例如 VPC 和 CloudFront 分配。我们还假设你熟悉设置 WorkSpaces 目录。我们不会重点定义每项服务,但会概述将它们与 Internet Monitor 一起使用所需的步骤。您可以在相应的
互联网监视器设置
让我们考虑一个用例,即您在
您只需创建监控器并添加资源即可开始使用 Internet Monitor,然后配置 CloudWatch 警报以通知您运行状况事件。
监控 EC2 托管的 Web 应用程序
步骤 1:在 CloudWatch 互联网监控器中创建监控器
要创建监控器,请在 CloudWatch 控制台的互联网监控器页面上,选择 创建监控器 。输入显示器的名称,然后选择 添加资源 。在我们的示例中,我们将添加一个 VPC,因为我们有一个 EC2 托管的 Web 应用程序。在资源页面上,选择 VPC,然后选择 添加 。选择 “ 下一步 ” ,查看配置,然后选择 “ 创建监视器 ” 。显示器需要几分钟才能激活。
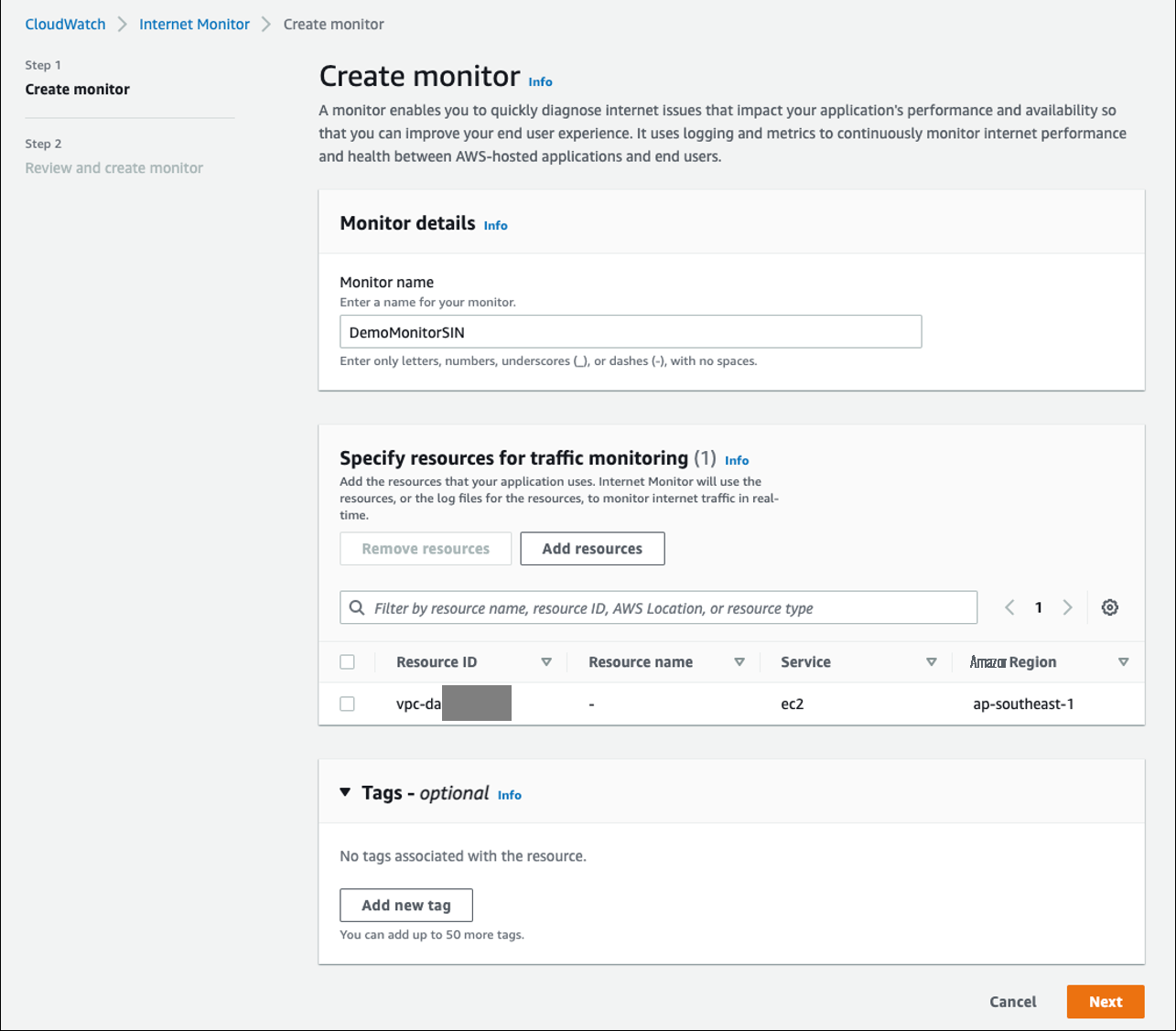
图 1 — 在互联网监控器控制台中创建监视器
根据您的工作负载及其监控需求,您可能需要在 Internet Monitor 中为不同的资源组创建单独的监视器。在我们的例子中,我们将为 WorkSpaces 目录创建一个单独的监视器。
步骤 2:警报配置示例
为了提醒,我们将使用亚马逊 EventBridge。根据我们的示例应用程序要求和用户群,我们将定义可用性分数的阈值为50%,性能分数的阈值定义为50%,并将受影响的总流量指定为至少占流量的1%。我们的 EventBridge 规则将创建日志,然后向符合上述条件的事件向 SNS 队列发送通知。(此处的值仅用作示例。您应该将阈值设置为对您的应用程序和业务有意义的级别。)
要配置事件过滤器,请在 亚马逊云科技 管理控制台中导航到 Amazon EventBridge。选择 创建 EventBridge 规则 ,然后输入相关的名称和描述。使用 默认事件总线 作为规则,对于事件源,选择 其他 。跳过示例事件配置,然后在 “ 创建” 方法 中选择 “ 自定义模式 ” 。例如,我们输入了以下内容:
接下来,我们将为事件配置两个目标:一个新的
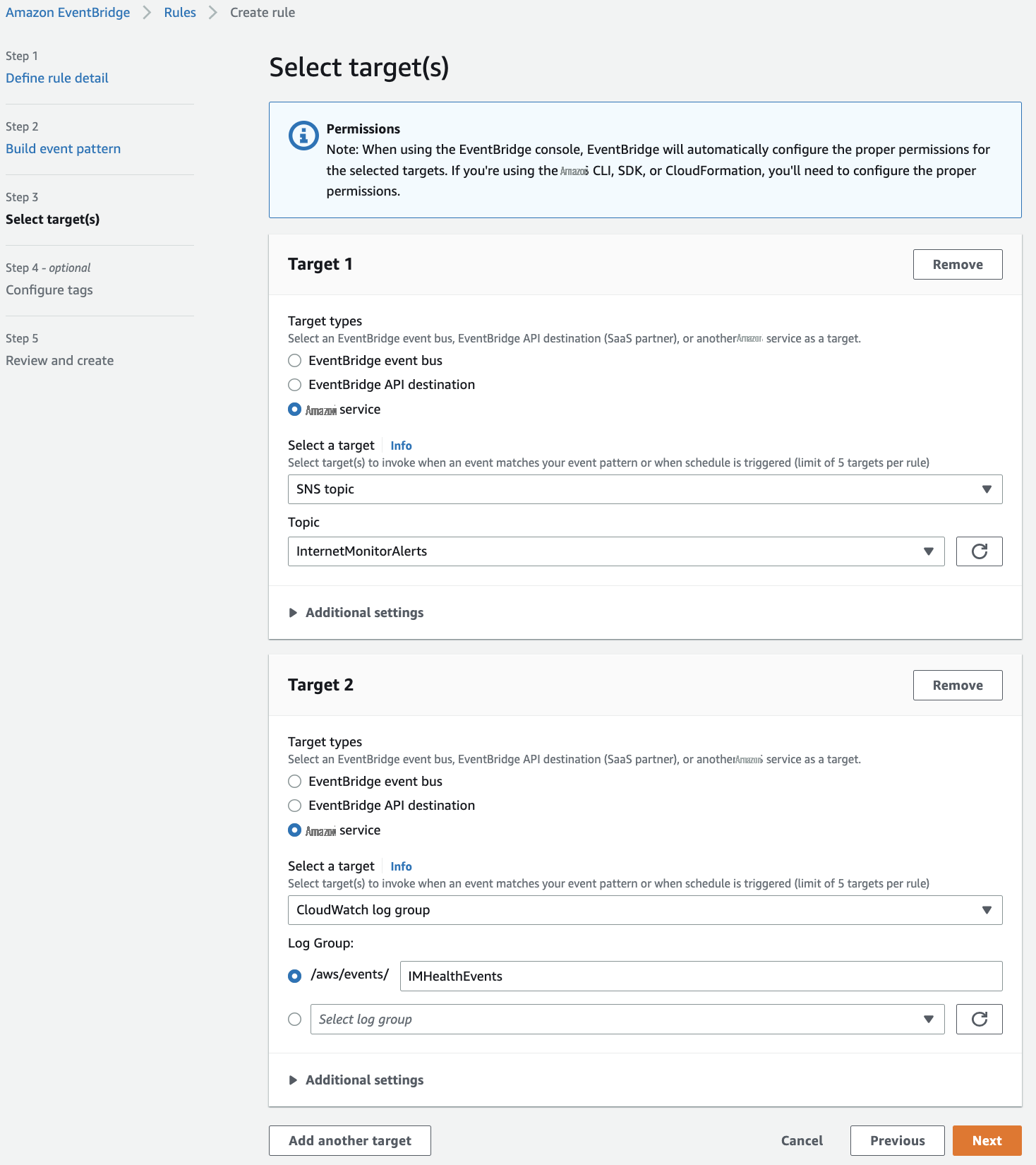
图 2 — 配置 EventBridge 规则目标
监控 Amazon WorkSpaces 目录资源
步骤 1:为 WorkSpaces 目录创建监视器
我们将遵循之前完成的相同步骤,为 WorkSpaces 目录资源创建监视器。如果某些资源类型具有相似的监控要求,则可以选择将资源分组到单个监视器中。但是,无法将 WorkSpaces 目录添加到 Internet Monitor 中的 VPC 同一个显示器中,因此我们将创建一个新的监视器。
步骤 2:警报配置示例
对于使用 WorkSpaces 目录的客户来说,一个关键指标是往返时间 (RTT)。当 RTT 大于 100 毫秒时,它会影响最终用户的性能体验。对于我们的用例,我们将创建一个自定义指标,仅向北美最终用户显示 RTT。执行此操作的步骤如下:
a) 根据客户端位置筛选互联网监控器事件日志。
b) 为互联网监控事件日志创建自定义 CloudWatch 指标过滤器。
c) 根据自定义指标配置警报。
让我们更详细地看一下配置流程。
a) 根据客户端位置过滤 Internet Monitor 事件日志

图 3 — JSON 格式的互联网监视器事件日志示例
要筛选 Internet Monitor 日志,我们将使用具有以下设置的 clientLocation .countryCode 字段:{$.clientLocation.crytco de=US || $.clientLocation.crycode=ca } 。 这使我们能够可视化美国或加拿大客户所在地的日志事件。
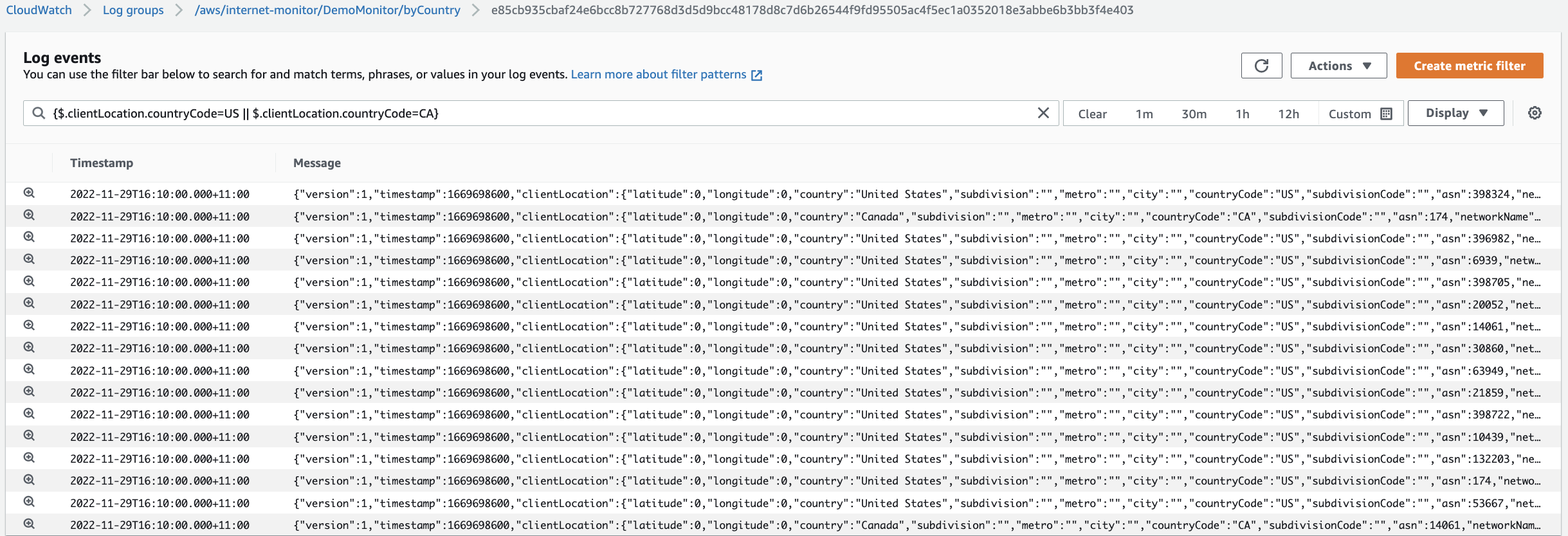 图 4 — Internet Monitor 日志流经过筛选,仅显示客户端位于北美的事件
图 4 — Internet Monitor 日志流经过筛选,仅显示客户端位于北美的事件
b) 为互联网监控事件日志创建 CloudWatch 指标过滤器
根据客户端位置筛选日志后,我们选择 创建指标筛选器 ,并配置筛选指标 名称和命名空间,以对相关的自定义指标进行分组。 在此示例中,我们基于第 90 个百分位数 (p90) RTT 值生成一个指标,即 InternetHealth.performance.roundtriptime.p90。 该指标的 p90 灵敏度使我们能够对使用平均值时会遗漏的异常情况发出警报,并避免触发频率过高。
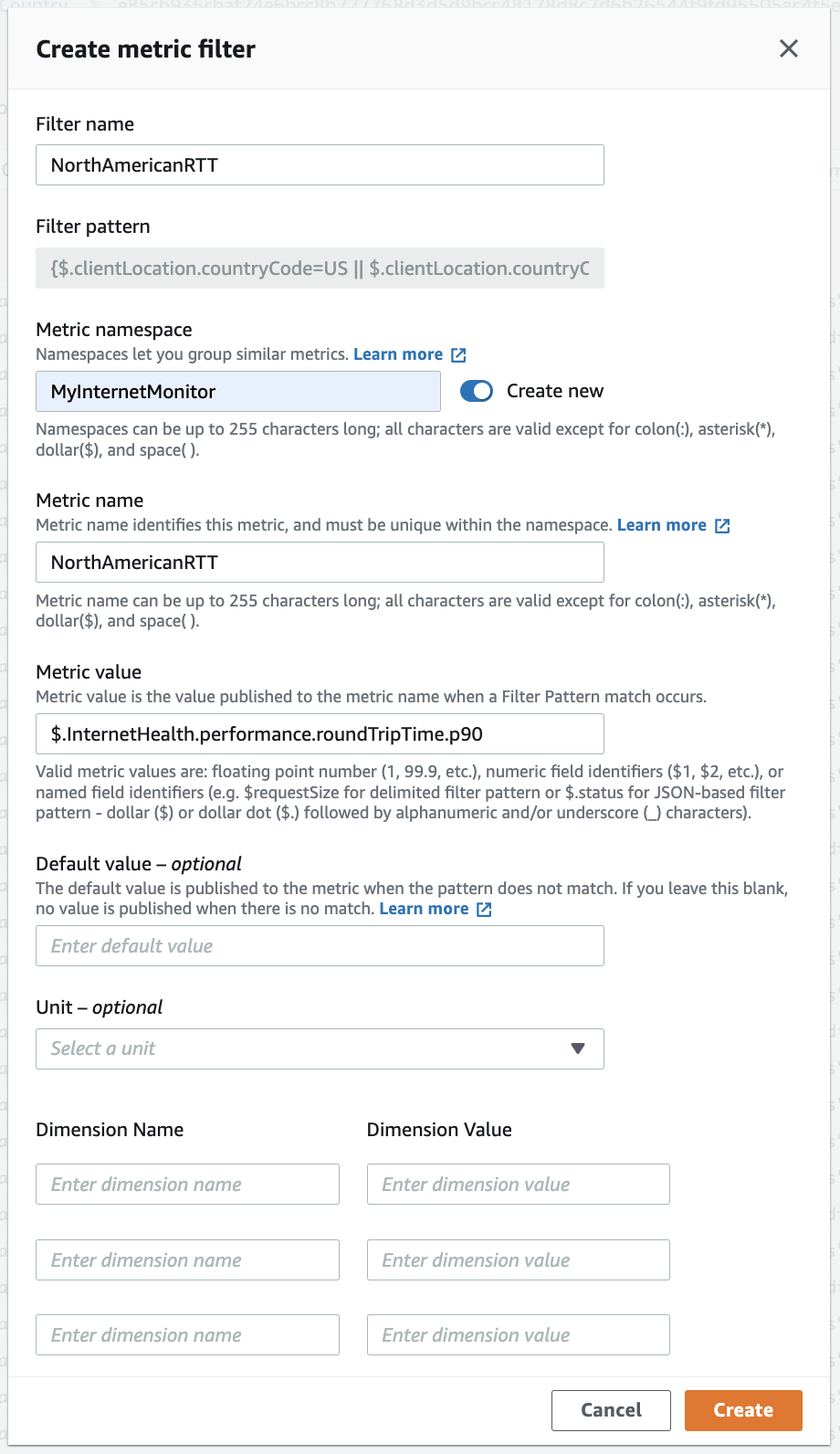
图 5 — 使用 CloudWatch Logs 控制台根据互联网监控日志事件创建指标筛选器
根据您的要求,您可以在配置中使用 p50、p90 或 p95。有关测量百分位数的更多详细信息,请参阅
c)。根据自定义指标配置警报
要根据我们的新指标创建警报,我们将使用 CloudWatch Alarms 控制台并为我们的监控器选择新创建的指标。例如,我们选择 100 毫秒作为 RTT 的阈值条件。您还可以创建使用异常检测而不是静态阈值的警报,以进行更准确的用户体验分析。有关异常检测的详细信息,请参阅
配置警报阈值条件后,我们选择要向其发送警报的 SNS 主题,然后创建警报,如下图所示。
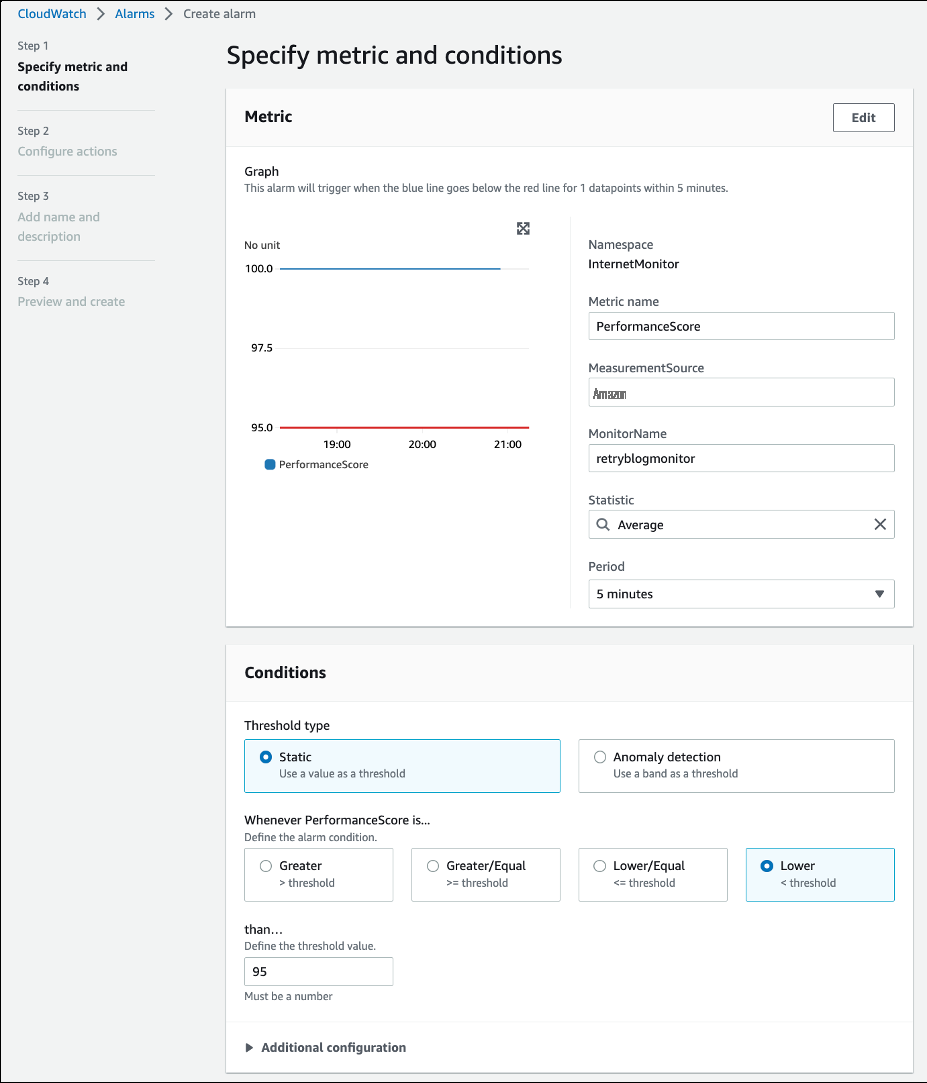
图 6 — 指定互联网监控指标并在 CloudWatch 警报控制台中配置阈值
分析互联网监控器事件
现在,假设您收到了一条警报,提示性能或可用性已降至您配置的阈值之一以下。要开始调查,请点击显示器的 Internet Monitor 控制台的 “ 概览 ” 选项卡。 概 述 选项卡显示受监控资源的可用性和性能分数,以及相关的活动运行状况事件。
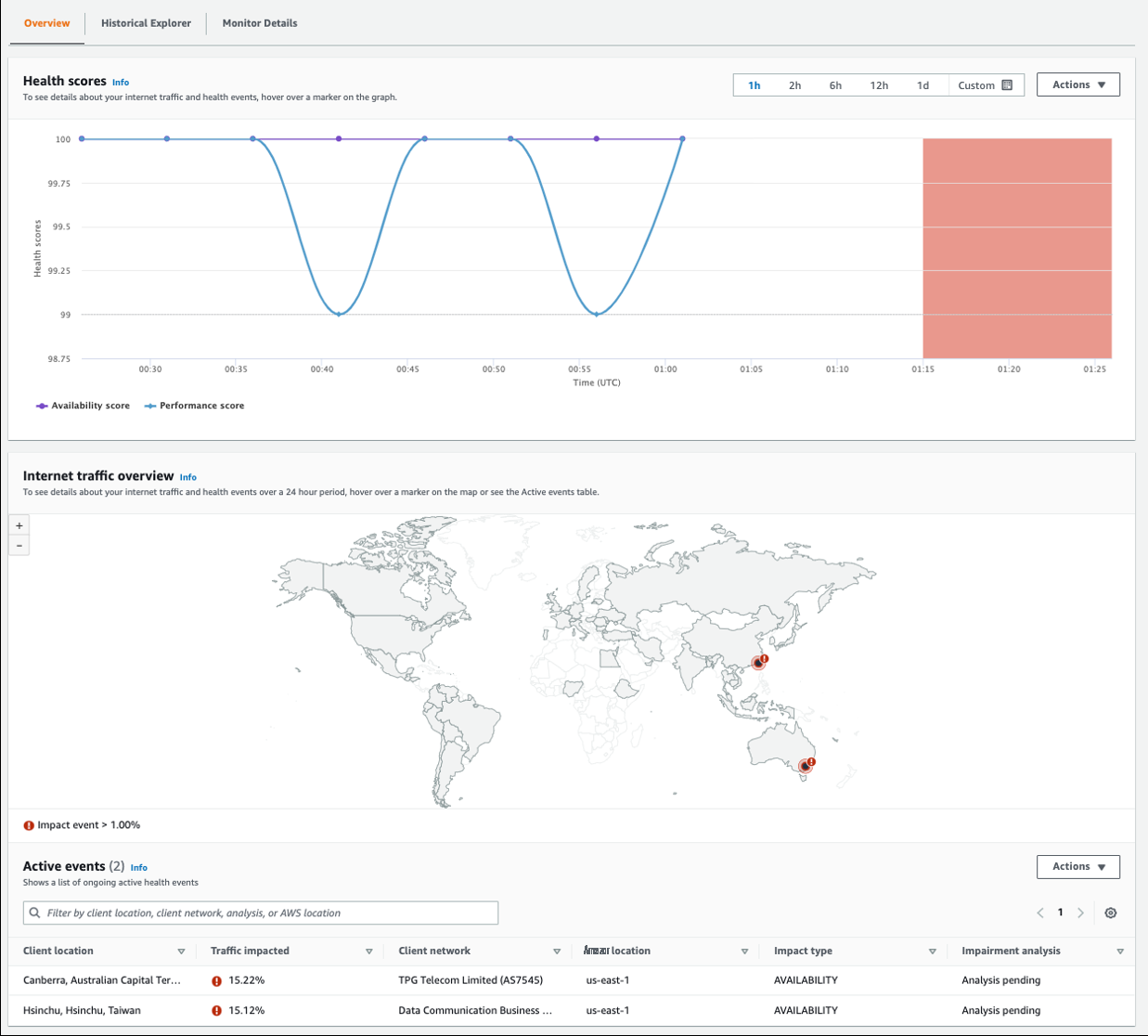
图 7 — Internet Monitor 控制台概述选项卡,其中包含健康评分和显示台湾和澳大利亚健康事件的地图
在此示例中,您可以看到一些健康事件影响了台湾和澳大利亚的用户。要查看有关健康事件的更多信息,您可以下载 CSV 或 JSON 格式的详细信息。选择 “ 操作 ” ,然后选择所需的格式。该文件包含您选择的时间段内的所有健康事件,您可以对其进行筛选,使其仅包含您感兴趣的事件。查看单个事件,您可以看到事件详细信息包含诸如客户端位置、网络服务提供商名称、ASN、受影响流量百分比等信息。以下是 JSON 格式的事件示例:
在这里,该地点有15.22%的客户受到影响,占当时使用该应用程序的所有客户的8.66%。
要更深入地了解用户体验,请导航到 “ 历史浏览器 ” 选项卡,以可视化按地理位置或网络提供商和时间范围筛选的更多绩效指标。
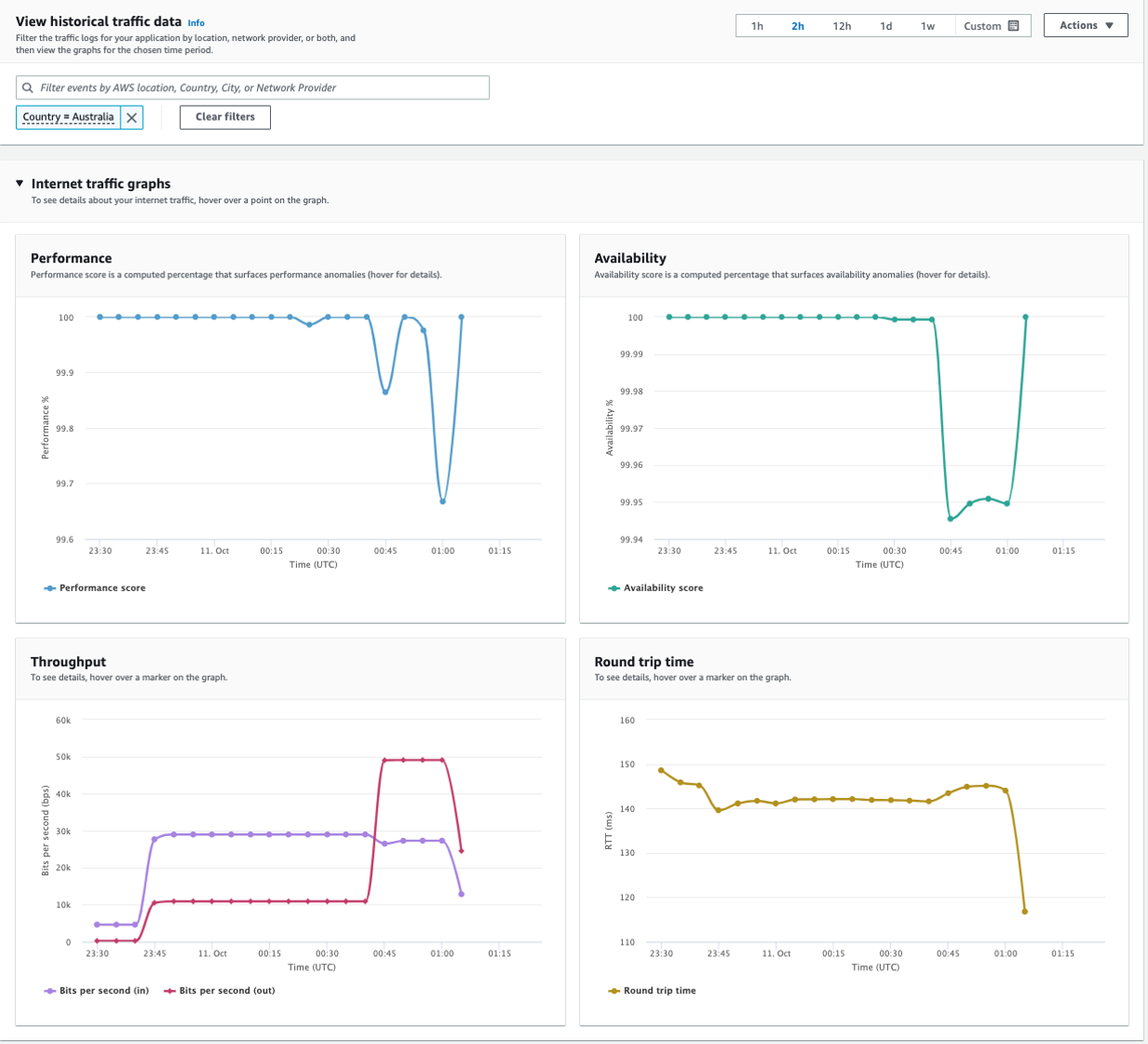
图 8 — 显示过滤到澳大利亚的互联网流量图表的 Internet Monitor 历史浏览器选项卡
使用 Internet Monitor 优化应用程序交付
对于像我们在此处探讨的那样的事件,这些事件似乎是由客户端网络提供商的问题引起的,你可以在短期内采取一些可能的措施:
- 如果您的应用程序已经从多个区域提供服务,则可以将受影响的流量转移到可通过不同的互联网路径到达的不同 亚马逊云科技 区域中的资源。
- 联系网络提供商,看看他们是否意识到这个问题,并正在研究解决方案。对于您所在地区以外的提供商来说,这可能不是一个选项。
- 更新您自己的状态页面或社交媒体,告知用户他们在某个地点遇到的问题是该地区的互联网性能造成的。
- 准备好客户支持,回答受影响客户的问题。
一种潜在的长期方法是改善最终用户的应用程序交付,例如,使用诸如Amazon CloudFront之类的服务,最大限度地减少客户流量所穿越的互联网路径。来自离您的用户最近的 亚马逊云科技 POP 以及您在 亚马逊云科技 区域中的源资源或终端节点的所有流量都将通过 亚马逊云科技 全球网络传输。
您可以使用 “ 流量洞察 ” 选项卡来探索提高不同位置的应用程序性能的方法,这些方法按可用性和性能分数或按首字节时间 (TTFB) 排序。您还可以使用地理或网络提供商过滤器来进一步研究特定区域的数据。
在 流量优化建议 下 ,如果您切换到使用 EC2 或 CloudFront 资源,或者将流量路由到其他 亚马逊云科技 区域或边缘站点,Internet Monitor 还会预测客户端位置和网络提供商的顶级组合。尝试不同的选项,看看哪个选项能为每种组合带来最佳结果。
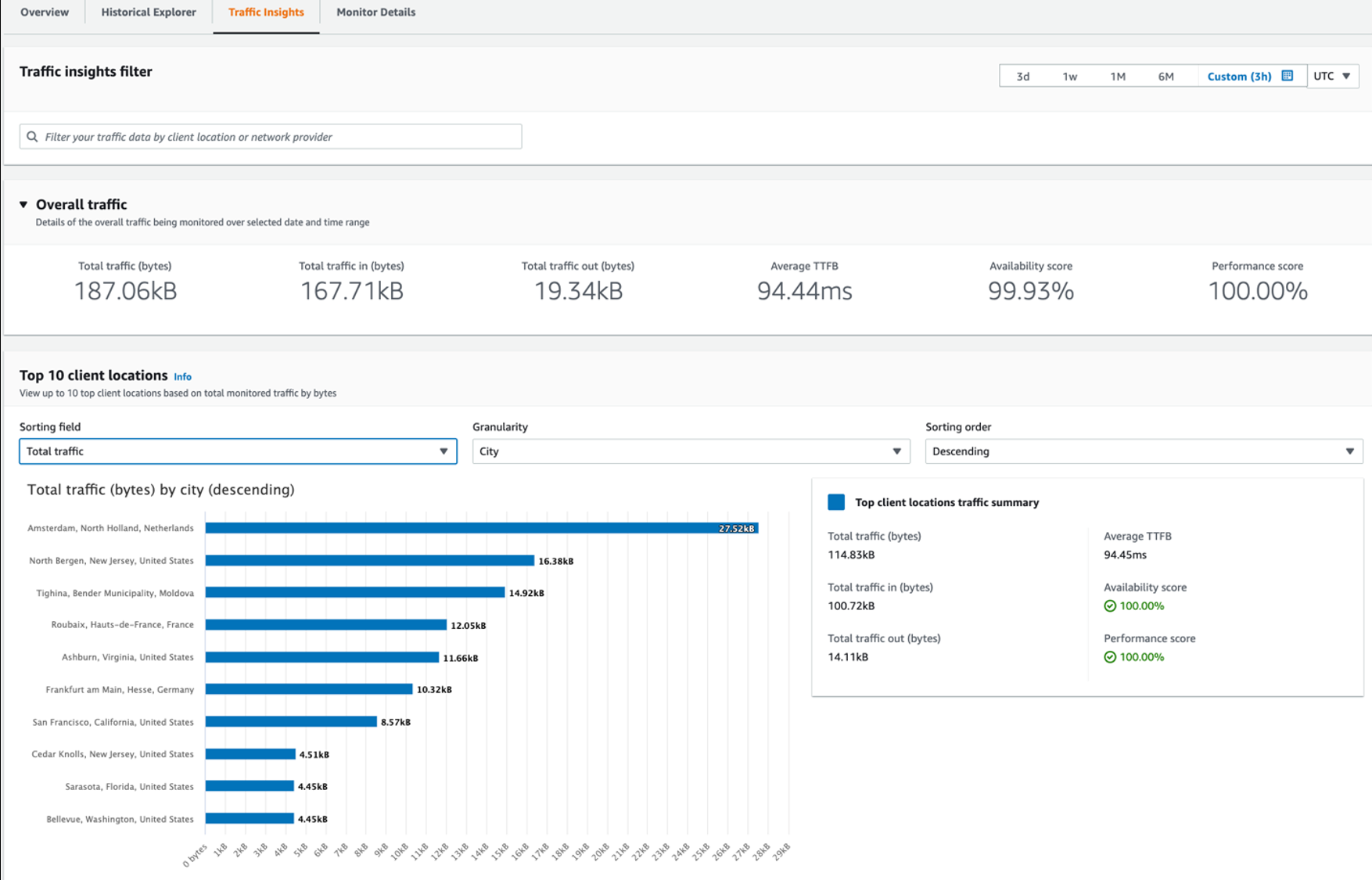
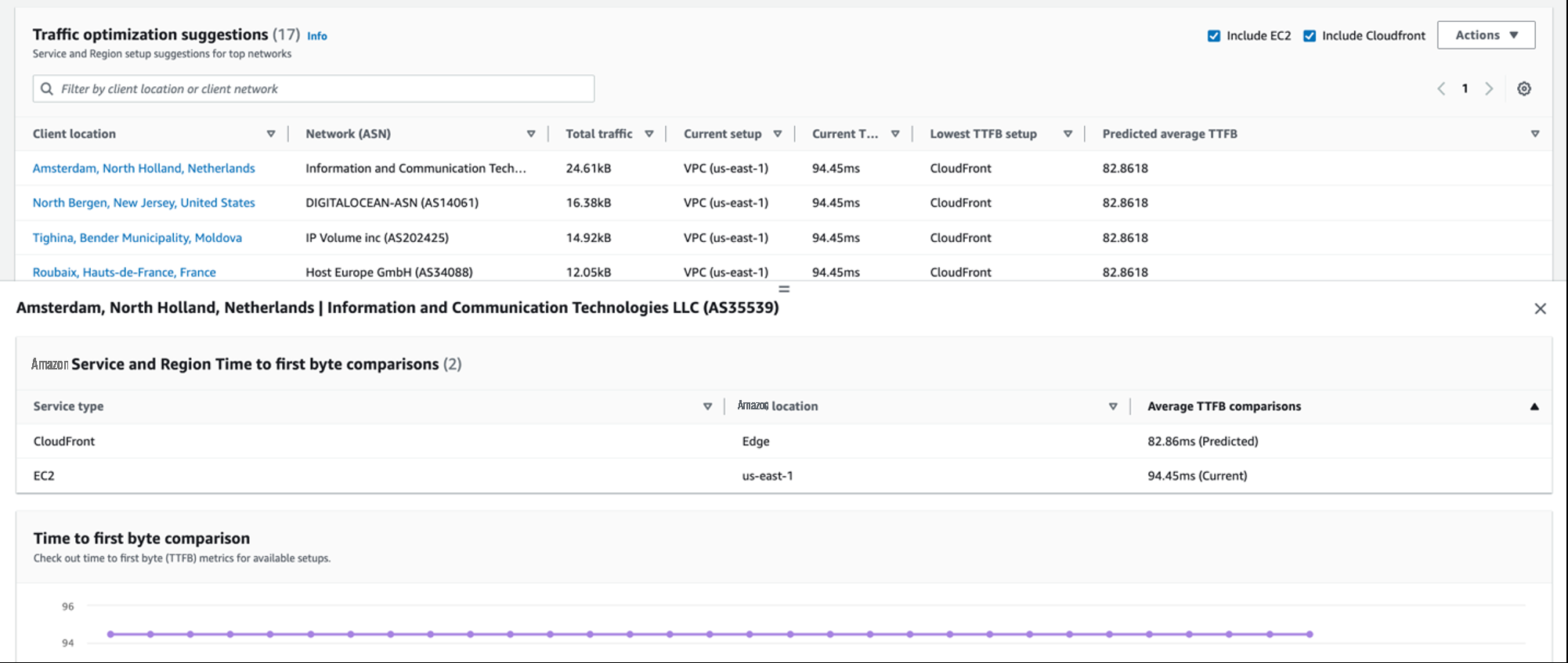
图 9 — Internet Monitor Traffic Insights 选项卡显示了按客户位置图和流量优化建议列出的总流量
环境清理
浏览完 Internet Monitor 的功能后,请务必清理测试环境并删除创建的资源。首先删除您的监控器,然后删除您创建的任何其他资源,包括:EventBridge 规则、CloudWatch 日志规则、警报、指标、日志组和 SNS 主题。
要知道的事情
- 如果您在单个 亚马逊云科技 区域有一组具有相似用户群的应用程序,请创建一个监控器来监控整个群组的总体用户体验。
- 互联网监控器中的单个监视器可以监视多个区域中的资源。
- 如果您添加 VPC 和 CloudFront 发行版,则无法将 WorkSpaces 目录添加到同一个显示器中。
-
Internet Monitor 需按照 CloudWatch 对指标、日志以及创建的任何仪表板、警报或见解收取常规费用。详细信息可在
CloudWatch 定价页面 上找到。 - 对 Internet Monitor 的 亚马逊云科技 CloudFormation 支持将很快推出。
-
互联网监控目前在
20 个 亚马逊云科技 地区 可用 。
结论
在这篇博客文章中,我们介绍了 Amazon CloudWatch Internet Monitor,这是一项新服务,使用 亚马逊云科技 从其全球网络足迹中捕获的连接数据,让您可以了解面向互联网的应用程序的性能。Internet Monitor 使用您原本不会意识到的影响最终用户体验的因素,帮助您做出更明智的决策,从而优化工作负载部署策略。要了解有关 Internet Monitor 的更多信息,请访问
作者简介

亚历山德拉·希德斯
Alexandra Huides 是亚马逊网络服务战略账户的首席网络专家解决方案架构师。她专注于帮助客户为高度可扩展和弹性强的 亚马逊云科技 环境构建和开发网络架构。Alex 还是 亚马逊云科技 的公开演讲者,她专注于帮助客户采用 IPv6 和设计高度可扩展的网络架构。工作之余,她喜欢帆船,尤其是双体船、旅行、发现新文化和阅读。

托尼·霍克
Tony 是一名来自澳大利亚堪培拉的网络专业技术客户经理。自 2016 年以来,Tony 一直在为澳大利亚、新西兰和东盟所有行业的 亚马逊云科技 客户提供支持。在加入 亚马逊云科技 之前,Tony 在企业和高等教育领域设计并运营了大型局域网/广域网。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。