我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Intuitivo 使用 亚马逊云科技 Inferentia 和 PyTorch 在节省人工智能/机器学习成本的同时实现更高的吞吐量
这是人工智能创始人兼总监何塞·贝尼特斯和Intuitivo基础设施主管Mattias Ponchon的客座文章。
零售创新的先驱Intuitivo正在利用其基于云的人工智能和机器学习 (AI/ML) 交易处理系统彻底改变购物。这项突破性技术使我们能够同时运营数百万个自主购买点 (A-POP),从而改变客户的购物方式。我们的解决方案超越了传统的自动售货机和替代方案,具有经济优势,其成本便宜十倍,易于设置且无需维护。由于 A
不断变化的零售格局和对A-POP的需求
零售格局正在迅速发展,消费者期望获得与数字购物时相同的易于使用和顺畅的体验。为了有效地弥合数字世界和现实世界之间的鸿沟,满足客户不断变化的需求和期望,需要采用变革性的方法。在 Intuitivo,我们相信零售业的未来在于创建高度个性化、人工智能驱动和计算机视觉驱动的自主购买点 (A-POP)。这项技术创新使产品触手可及。它不仅使客户最喜欢的商品触手可及,而且还为他们提供了无缝的购物体验,无需排长队或复杂的交易处理系统。我们很高兴引领零售业这个激动人心的新时代。
借助我们的尖端技术,零售商可以快速高效地部署数千个 A-pop。对于零售商来说,规模一直是一项艰巨的挑战,这主要是由于与扩展传统自动售货机或其他解决方案相关的物流和维护复杂性。但是,我们基于摄像头的解决方案无需重量传感器、RFID 或其他高成本传感器,无需维护,而且便宜得多。这使零售商能够高效地建立数千个 A-pop,为客户提供无与伦比的购物体验,同时为零售商提供具有成本效益和可扩展的解决方案。

使用云推理进行实时产品识别
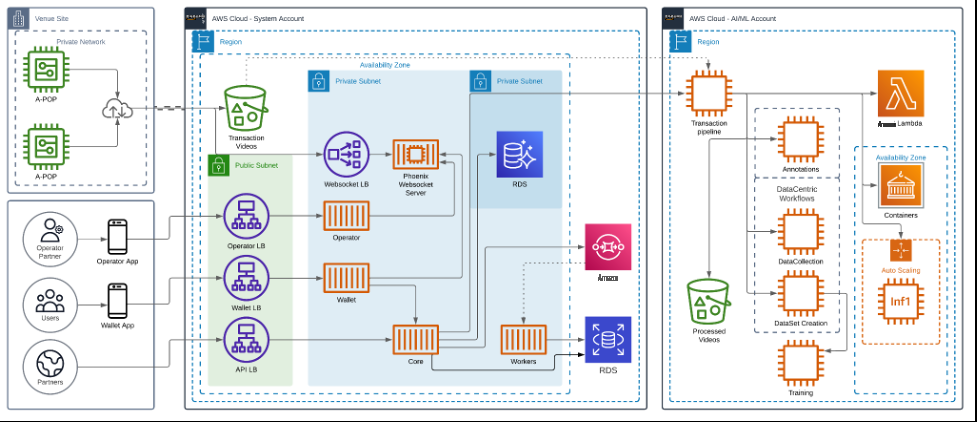
在设计基于摄像头的产品识别和支付系统时,我们遇到了一个决定,即应该在边缘还是在云端完成。在考虑了几种架构之后,我们设计了一个将交易视频上传到云端进行处理的系统。
我们的最终用户通过扫描 A-POP 的二维码开始交易,这会触发 A-POP 解锁,然后客户拿到他们想要的东西然后出发。这些交易的预处理视频将上传到云端。我们基于人工智能的交易管道会自动处理这些视频,并相应地向客户的账户收费。
下图显示了我们解决方案的架构。
使用 亚马逊云科技 Inferentia 解锁高性能且具有成本效益的推断
随着零售商寻求扩大运营规模,A-pop的成本成为一个考虑因素。同时,为最终用户提供无缝的实时购物体验至关重要。我们的 AI/ML 研究团队专注于为我们的系统确定最佳的计算机视觉 (CV) 模型。我们现在面临的挑战是如何同时优化 AI/ML 操作以提高性能和成本。
我们将模型部署在 由 Inferentia 提供支持
下面的代码片段显示了如何使用 Neuron 编译 YOLO 模型。该代码可与 PyTorch 无缝协作,诸如 torch.jit.trace () 和 neuron.trace () 之类的函数会记录模型在向前传递期间对示例输入的操作,以构建静态红外图。
我们将计算密集型模型迁移到 Inf1。通过使用 亚马逊云科技 Inferentia,我们实现了满足业务需求的吞吐量和性能。在 mLOP 生命周期中采用基于推理的 Inf1 实例是取得显著成绩的关键:
- 性能改进: 现在, 我们的大型计算机视觉模型的运行速度提高了五倍,达到每秒 120 帧 (FPS) 以上,从而为我们的客户提供了无缝的实时购物体验。此外,以这种帧速率进行处理的能力不仅提高了交易速度,还使我们能够向模型提供更多信息。数据输入的增加显著提高了我们模型中产品检测的准确性,进一步提高了我们购物系统的整体效率。
- 节省成本 :我们削减了推理成本。这极大地增强了支持我们的 A-pop 的架构设计。
使用 亚马逊云科技 Neuron SDK 可以轻松进行数据并行推断
为了提高推理工作负载的性能并从推理中获得最大性能,我们希望在推理加速器中使用所有可用的 NeuronCore。使用 Neuron SDK 的内置工具和 API,可以轻松实现这种性能。我们使用了
torch.neuron.dataParallel
() API。 我们目前使用的是 inf1.2xlarge,它有一个推理加速器和四个神经元加速器。因此,我们正在使用 t
orch.neuron.dataParallel ()
来充分利用 Inferentia 硬件并使用所有可用的 NeuronCore。此 Python 函数在 PyTorch 神经元 API 创建的模型上实现模块级别的数据并行性。数据并行性是一种跨多个设备或内核(用于推理的 NeuronCore)的并行化形式,称为节点。每个节点包含相同的模型和参数,但数据分布在不同的节点上。通过将数据分布在多个节点上,与顺序处理相比,数据并行性减少了大批量输入的总处理时间。数据并行性最适合具有大批量要求的延迟敏感型应用程序中的模型。
展望未来:利用基础模型和可扩展部署加速零售转型
当我们冒险进入未来时,基础模式对零售业的影响怎么强调都不为过。基础模型可以在产品标签方面产生显著的差异。在快节奏的零售环境中,快速准确地识别和分类不同产品的能力至关重要。借助基于变换器的现代模型,我们可以部署更多样化的模型,以更高的准确度满足更多的人工智能/机器学习需求,从而改善用户体验,而不必浪费时间和金钱从头开始训练模型。通过利用基础模型的力量,我们可以加快标签流程,使零售商能够更快、更高效地扩展其A-POP解决方案。
我们已经开始实现 Segment Anything
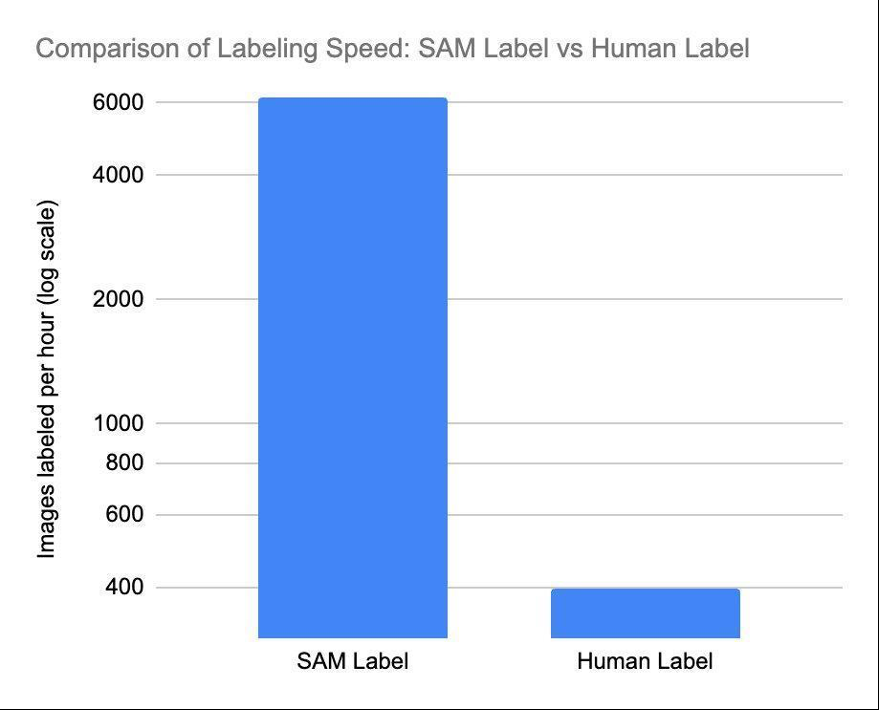
我们的产品和人工智能/机器学习研究团队很高兴能站在这一转型的最前沿。与 亚马逊云科技 的持续合作关系以及我们在基础设施中使用 Inferentia 将确保我们能够经济高效地部署这些基础模型。作为早期采用者,我们正在使用基于 亚马逊云科技 Inferentia 2 的新实例。Inf2 实例专为当今的生成式 AI 和大型语言模型 (LLM) 推理加速而构建,可提供更高的性能和更低的成本。Inf2将使我们能够让零售商在不花很多钱的情况下利用人工智能驱动技术的优势,最终使零售格局更具创新性、效率和以客户为中心。
随着我们继续将更多模型迁移到Inferentia和Inferentia2,包括基于变形金刚的基础模型,我们相信,我们与亚马逊云科技的联盟将使我们能够与值得信赖的云提供商一起成长和创新。我们将共同重塑零售业的未来,使其更智能、更快速,更适应消费者不断变化的需求。
结论
在本次技术探讨中,我们重点介绍了我们使用 亚马逊云科技 Inferentia 的创新型 AI/ML 交易处理系统的转型之旅。与之前的解决方案相比,这种合作关系使处理速度提高了五倍,推理成本也惊人地降低了95%。它通过促进实时、无缝的购物体验改变了零售业的当前方式。
如果您有兴趣进一步了解 Inferentia 如何帮助您在优化推理应用程序性能的同时节省成本,请访问 Amazon EC2 In
作者简介
Matias Ponchon 是 In tuitivo 的基础设施主管。他擅长架构安全而强大的应用程序。凭借在金融科技和区块链公司的丰富经验,加上他的战略思维,帮助他设计创新的解决方案。他坚定地致力于追求卓越,这就是为什么他始终如一地提供弹性解决方案,突破可能性的界限。
何塞·贝尼特斯 是Intuit ivo的创始人兼人工智能总监,专门从事计算机视觉应用程序的开发和实施。他领导着一支才华横溢的机器学习团队,营造一个充满创新、创造力和尖端技术的环境。2022 年,何塞被《麻省理工学院技术评论》评为 “35岁以下的创新者”,这证明了他在该领域的开创性贡献。这种奉献精神不仅限于荣誉,还延伸到他开展的每个项目,体现了他对卓越和创新的不懈承诺。
Diwakar Bansal 是一名 亚马逊云科技 高级专家,专注于人工智能和机器学习加速计算服务的业务开发和上市工作。此前,迪瓦卡尔曾领导物联网、边缘计算和自动驾驶技术产品的产品定义、全球业务开发和营销,重点是将人工智能和机器学习引入这些领域。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。