我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 Kinesis Data Streams,LaunchDarkly 从每天摄入 1 TB 到 100 TB 的旅程
这篇文章是与LaunchDarkly的软件架构师迈克·佐恩共同撰写的,他是主要作者。
问题陈述
LaunchDarkly的使命是通过帮助公司更快地创新、无所畏惧地部署以及使每个版本都成为杰作,从根本上改变公司交付软件的方式。借助 LaunchDarkly,我们允许客户在需要时进行部署,在准备就绪时发布,并完全控制代码以快速发布、降低风险并节省夜间和周末的时间。
2017 年,事件采集平台由一组 Web 服务器组成,这些服务器会将事件写入多个数据库,如下所示,这些数据库存储事件数据以支持 LaunchDarkly 产品的多项功能。这些功能使LaunchDarkly的客户能够全面了解某项功能在一段时间内的表现,通过实验优化功能,并快速验证其实施情况。不幸的是,所有支持这些功能的数据库写入都是在这些 Web 服务器上的单个进程中执行的,因此,如果这些数据库中的任何一个出现可用性问题,事件将在内存中排队,直到该进程耗尽内存并崩溃。由于将使用同一个数据库从每个 Web 服务器写入数据,因此所有服务器最终都会耗尽内存并崩溃。在数据库可用性问题得到纠正之前,这个周期会重演。在此期间,SDK 发送的所有事件数据永久丢失。
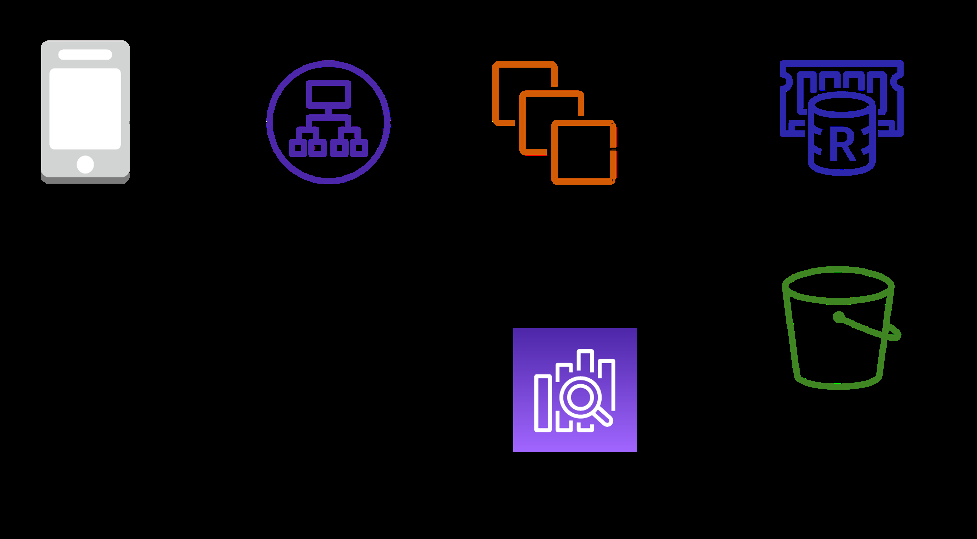
当前的系统可以容忍某些数据丢失,因为使用这些数据的应用程序有限。但是新功能和工作流程对防止数据丢失有更严格的要求。
我们决定探索替代方案,使所有消费者都具有隔离的容错能力,因此每个消费者在出现任何问题时都相互独立。我们构建了一个事件驱动的管道,该管道将高度耐用、可扩展,还提供数据重播功能。结果,我们从每天摄取大约 1 TB 的数据扩展到现在的超过 100 TB 的数据。
解决方案
下图说明了我们的更新设计。为了支持新的用例,我们在架构中添加了

该设计包含以下关键组成部分
- 使用 LaunchDarkly SDK 评估功能标志的移动客户端
- 应用程序负载均衡器将流量分配到 Amazon EC2 节点
- 亚马逊 EC2 节点运行一个 go 应用程序,将流量写入亚马逊 Kinesis Data Streams
- 亚马逊 Kinesis Data Streams 可持久保存数据
- 亚马逊云科技 Lambda 将各种类型的数据写入数据库
- 亚马逊 OpenSearch Service 记录了有关用户的数据
- 亚马逊 ElastiCache 记录了有关旗帜状态的数据
- 亚马逊 Kinesis Firehose 批量标记评估数据并将其写入亚马逊 S3
- 亚马逊 S3 记录有关旗帜评估的数据
数据从 LaunchDarkly SDK 流入事件 API,后者由应用程序负载均衡器 (ALB) 提供支持。该ALB将流量路由到一组亚马逊 EC2 服务器。这些服务器将数据保存到亚马逊 Kinesis Data Streams。然后,Lambda 函数从 Amazon Kinesis Data Streams 中读取数据,这些函数将数据以不同的格式转换并写入多个数据库。该设计有一些对这个用例非常重要的属性。
- 耐久性
- 隔离
- 数据回放
当数据处理出现问题时,耐久性可以防止数据丢失。隔离可以防止其他数据使用者在一个消费者出现故障时失败。数据回放将使我们能够调试数据异常并对其进行追溯修复。
亚马逊 Kinesis Data Streams 满足这三个特性。写入亚马逊 Kinesis Data Streams 的数据将持续保存,直到数据从数据流中老化。Amazon Kinesis Data Streams 允许用户隔离:每个使用者保持自己的迭代器位置,因此使用者可以相互独立地处理来自流的数据。最后,亚马逊 Kinesis Data Streams 使数据重播成为可能,因为使用者可以将其分片迭代器位置设置为过去。例如,如果需要重放最后一小时的数据,则可以将消费者配置为从过去 1 小时开始读取。
考虑了其他一些技术,使我们能够实现这些设计特性。亚马逊简单通知服务 (Amazon SNS) 与亚马逊简单队列服务 (Amazon SQS) 相结合,将使系统具有耐用性和隔离性。数据回放不是开箱即用的,需要自定义实现才能支持此功能。
Apache Kafka也曾被考虑过,但尽管它满足了这些设计特性,但由于该团队之前没有使用Apache Kafka的经验,它没有被采用。Amazon Kinesis Data Streams 满足了这些设计特性,并且是完全托管的,因此无需担心缺乏运营专业知识。
亚马逊 Kinesis Data Streams 的实施深入探讨
在我们开始实施 Amazon Kinesis Data Streams 之前,在最初的概念验证阶段,我们了解到,尽管 Amazon Kinesis Data Streams 是完全托管的,但在大规模实施时,需要考虑一些方面。
- 成本
- 客户端错误处理
亚马逊 Kinesis Data Streams 的按需成本与流中输入的数据量成正比。但是,如果流量相对均匀且可预测,则预置吞吐量计费更经济。根据预置吞吐量计费,还将向客户收取上传有效负载的费用,这本质上是一项额外费用,尤其是在有大量小记录的情况下。由于 LaunchDarkly 的用例具有可预测的均匀流量,因此使用了预置吞吐量。但是,我们的记录大小很小(平均约为 100 字节),因此实施批处理以控制成本非常重要。
Kinesis Producer Library (KPL) 支持多种语言,如果你使用其中任何一种语言,你可以依靠它来高效地为你批处理记录。但是,由于 LaunchDarkly 将 Go 用于后端应用程序,因此我们有自定义代码,因为 KPL 不支持 Go 作为生产者。我们的解决方案是对数据进行批处理,使其接近 25 kB(输入有效载荷的大小)。我们通过使用协议缓冲区并在记录中将它们连接在一起来做到这一点。
当写入 Amazon Kinesis Data Streams 的应用程序无法成功写入数据时,就会发生客户端错误。尽量减少这些很重要,要实现这一目标,需要考虑几个因素。首先,设计应用程序,使最终写入路径中的故障模式尽可能少。在我们的应用程序中,我们对请求进行身份验证,检查某些功能标志的值,并将数据写入 Amazon Kinesis 数据流。我们优化了代码,在将数据写入 Amazon Kinesis Data Streams 之前不执行任何数据库查询或网络请求,以避免任何可能导致数据丢失的查询/调用失败。要实施的另一个步骤是增加 亚马逊云科技 SDK 中的重试次数(我们使用 10 次)。这样,如果向亚马逊 Kinesis Data Streams 写入数据时出现暂时性问题,则数据更有可能被保存。最后,如果你使用的是预配置的直播,那么粗粒度的速率限制很重要。有时,终端制作者会无意中配置一个 SDK,向我们的系统发送大量数据。在这些情况下,我们有速率限制器来防止单个租户消耗过多的预置容量。
在我们弄清楚如何解决所有这些问题之后,我们开始分两个阶段迁移到新架构。
首先是将我们的数据发送到亚马逊 Kinesis Data Streams。第二是将消费类工作负载从亚马逊 EC2 服务器转移到 亚马逊云科技 Lambda。在这两个阶段,我们使用了
第一阶段,即向亚马逊 Kinesis Data Streams 发送数据,进展非常顺利。批处理机制按预期运行,我们的吞吐量也符合预期。我们没想到的一件事是,从我们的虚拟私有云 (VPC) 传输数据的成本会增加。默认情况下,您的亚马逊 Kinesis Data Streams 流量将通过您的 VPC 的网络地址转换 (NAT) 网关。费用基于流经NAT网关的数据量。为了降低这些成本,对设计进行了优化,以便在托管 Amazon EC2 应用程序的每个可用区中配置 亚马逊云科技 私有链接终端节点。这种设计优化最大限度地降低了数据传输成本。
第二阶段,即将工作负载转移到 亚马逊云科技 Lambda,进展不太顺利。事实证明,将工作负载的并发性从数十台服务器急剧更改为数百个 Lambda 执行上下文可能会产生一些意想不到的后果。在 Amazon EC2 中,我们汇总了每台主机上的标志评估数据,并每分钟将一个文件刷新到 Amazon S3 一次。在 亚马逊云科技 Lambda 中,由于并发性增加,这种聚合的效率降低了大约 20 倍。为了克服下游数据处理系统无法处理的文件过多的问题,我们使用了亚马逊 Kinesis Data Firehose。我们用它自动将数据批处理到 Amazon S3 中的文件中。将该服务集成到架构中后,我们便能够将全部工作负载迁移到 亚马逊云科技 Lambda。
根据LaunchDarkly的经验,Amazon Kinesis Data Streams是事件数据处理用例的不错选择。一旦事件在 Amazon Kinesis Data Streams 中得到持久保存,就可以轻松创建直播使用者,并为您管理事件保留。如果你正在考虑使用亚马逊 Kinesis Data Streams,那么在实施中应该考虑一些事项。
- 配置 亚马逊云科技 私有链接终端节点以降低数据传输成本。
- 使用 KPL 或实现自己的记录批处理,使有效载荷接近 25 kB。
- 使用速率限制来确保不超过预置容量(如果您不使用按需流)。
- 增加重试次数以确保写入数据。
结论
该系统已经投入生产了3年多,我们对此感到非常满意。它已从 2018 年的每天摄取大约 1 TB 扩展到现在的每天超过 100 TB。通过这种增长,该系统已被证明是可靠、高性能和具有成本效益的。该系统保持了 99.99% 的可用性和 99.99999% 的数据持久性。端到端处理时间在 30 秒以内。随着使用量的增加,成本也有所增加,但这完全在我们的预算之内。
我们希望这篇文章能够指导您在
作者简介


*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。