我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Amazon Redshift 工作负载管理更好地管理您的工作负载
借助
Amazon Redshift
在 Amazon Redshift 中,您可以
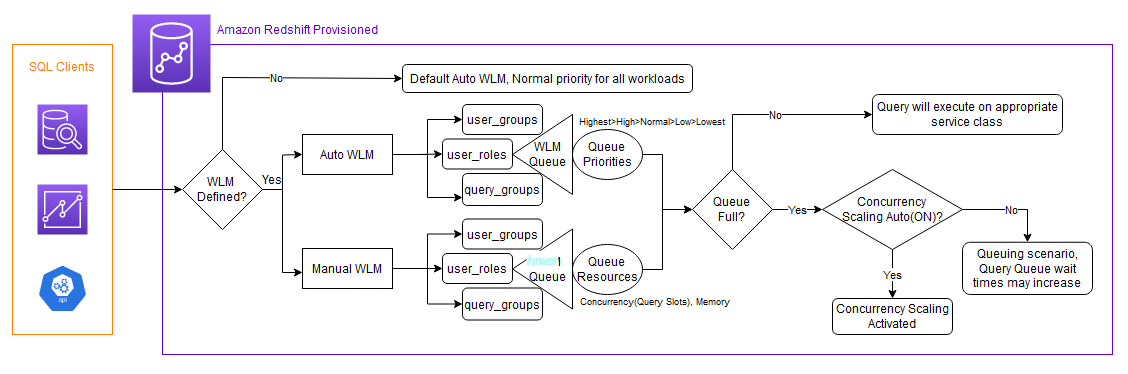
这篇文章提供了企业分析工作负载的示例,并分享了常见的挑战以及使用 WLM 缓解这些挑战的方法。我们将指导您了解常见的 WLM 模式以及如何将它们与您的数据仓库配置关联起来。我们还将介绍如何为 WLM 队列分配用户角色以及如何使用 WLM 查询见解来优化配置。
用例概述
ExampleCorp 是一家使用亚马逊 Redshift 对其数据平台和分析进行现代化改造的企业。他们有各种各样的工作负载,用户来自不同的部门和角色。服务级别性能要求因工作负载的性质和访问数据集的用户角色而异。ExampleCorp 希望使用 WLM 队列管理亚马逊 Redshift 上的资源和优先级。
下图说明了 ExampleCorp 中的用户角色和访问权限。
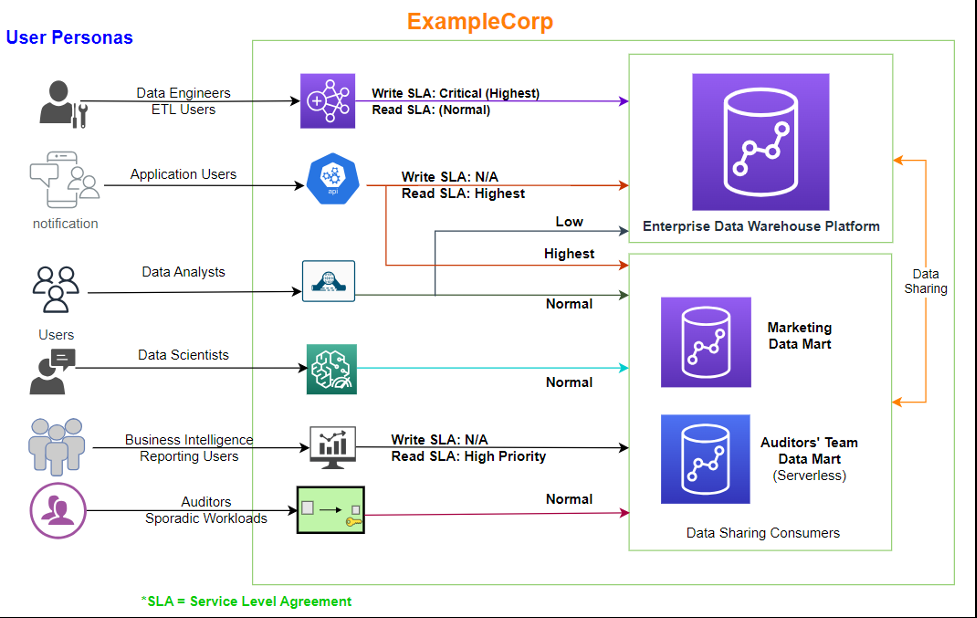
exampleCorp 有多个 Redshift 集群。在这篇文章中,我们重点介绍以下内容:
-
企业数据仓库 (EDW) 平台
— 它包含所有写入工作负载,以及一些通过
Redshift Dat a API 运行读取的应用程序。 多个消费者集群使用 Redshift 数据共享功能访问来自 EDW 集群的企业标准化数据,以运行下游报告、仪表板和其他分析工作负载。 - 营销数据集市 — 它在一天中的特定时间提供可预测的提取、转换和加载 (ETL) 和商业智能 (BI) 工作负载。集群管理员了解按工作负载类型划分的确切资源需求。
- 审计师数据集市 — 每天仅使用几个小时来运行预定报告。
ExampleCorp 希望使用 WLM 更好地管理他们的工作负载。
解决方案概述
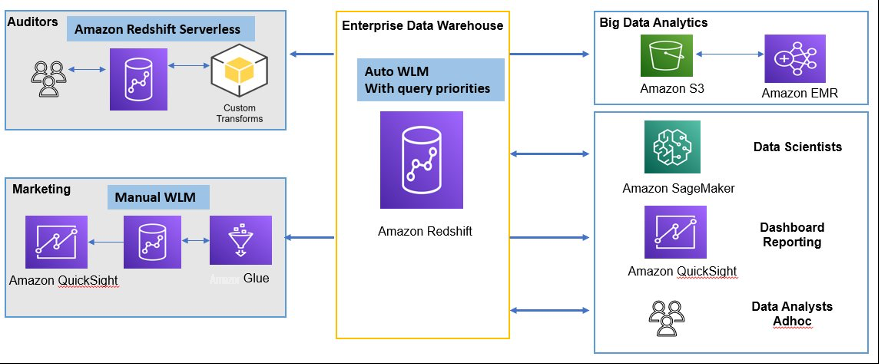
正如我们在上一节中所讨论的那样,ExampleCorp 有多个 Redshift 数据仓库:一个企业数据仓库和两个下游 Redshift 数据仓库。每个数据仓库都有不同的工作负载、SLA 和并发性要求。
数据库管理员 (DBA) 将根据其用例在每个 Redshift 数据仓库上实施相应的 WLM 策略。在这篇文章中,我们使用以下示例:
- 企业数据仓库演示了具有查询优先级的 Auto WLM
- 营销数据集群演示了手动 WLM
-
审计团队很少使用数据集市来处理零星的工作负载;他们使用不需要工作负载管理的 Amazon Redshift
Serverles s
下图说明了解决方案架构。
先决条件
在开始使用此解决方案之前,您需要满足以下条件:
- 一个 亚马逊云科技 账户
- 亚马逊 Redshift 的管理权限
在解决 ExampleCorp 的问题陈述之前,让我们先了解一些基本概念。首先,如何在自动和手动 WLM 之间做出选择。
自动与手动 WLM 的对比
Amazon Redshift WLM 使您能够灵活地管理工作负载中的优先级,以满足 SLA。对于您配置的 Redshift 数据仓库,Amazon Redshift 支持自动 WLM 或手动 WLM。下图说明了每个选项的队列。
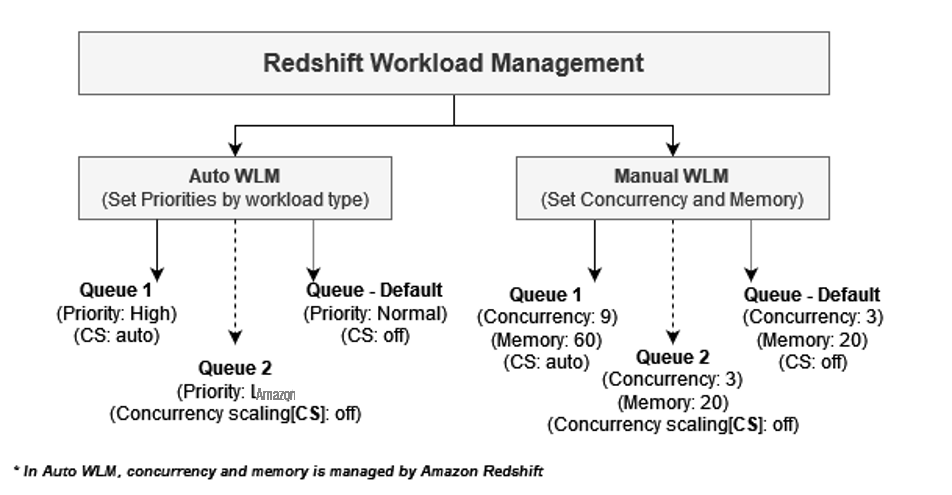
Auto WLM 确定查询所需的资源量,并根据工作负载调整并发性。当系统中存在需要大量资源的查询(例如,大型表之间的哈希联接)时,并发性会降低。有关更多信息,请参阅
使用手动 WLM,您可以管理查询并发和内存分配,而自动 WLM 则由 Amazon Redshift 自动管理。您可以为 ETL、BI 和即席等不同的工作负载配置单独的 WLM 队列,并自定义资源分配。有关更多信息,请参阅
当您的工作负载模式可预测时,或者需要根据一天中的时间限制某些类型的查询(例如在工作时间限制摄取)时,请手动使用。如果您需要保证多个工作负载能够同时运行,则可以为每个工作负载定义插槽。
现在您已经选择了自动或手动 WLM,让我们来探索 WLM 参数和属性。
静态与动态属性
Redshift 数据仓库的 WLM 配置是使用数据库配置属性下的参数组设置的。
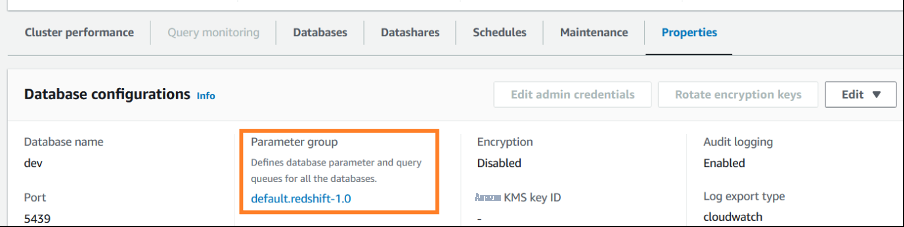
参数组 WLM 设置要么是 动态 的,要么是 静态 的。您可以在不重新启动集群的情况下将动态属性应用于数据库,但是静态属性需要重启集群才能使更改生效。下表总结了不同 WLM 属性的静态和动态要求。
| WLM Property | Automatic WLM | Manual WLM |
| Query groups | Dynamic | Static |
| Query group wildcard | Dynamic | Static |
| User groups | Dynamic | Static |
| User group wildcard | Dynamic | Static |
| User roles | Dynamic | Static |
| User role wildcard | Dynamic | Static |
| Concurrency on main | Not applicable | Dynamic |
| Concurrency Scaling mode | Dynamic | Dynamic |
| Enable short query acceleration | Not applicable | Dynamic |
| Maximum runtime for short queries | Dynamic | Dynamic |
| Percent of memory to use | Not applicable | Dynamic |
| Timeout | Not applicable | Dynamic |
| Priority | Dynamic | Not applicable |
| Adding or removing queues | Dynamic | Static |
请注意以下几点:
- 参数组参数和 WLM 从手动切换到自动或反之亦然是静态属性,因此需要重启集群。
- 对于 WLM 属性 main 上的并发、使用的内存百分比和超时(对于手动 WLM 来说是动态的),更改仅适用于值更改后提交的新查询,而不适用于当前正在运行的查询。
- 我们将在本文后面讨论的查询监控规则是动态的,不需要重启集群。
在下一节中,我们将讨论服务类的概念,即向哪个队列提交查询以及为什么。
服务等级
无论您使用自动还是手动 WLM,提交的用户查询都会通过以下机制之一进入预期的 WLM 队列:
-
用户组 — WLM 队列直接映射到将出现在 pg_
group 表中的
Redshift 群组 。 -
查询组 — 队列分配基于 qu
er y_ group 标签。例如,同一报告用户提交的仪表板可以按名称或部门具有不同的优先级。 -
User_Roles(最新添加) — 队列是根据
Red shift 角色 分配的。
从元数据的角度来看,WLM 队列被定义为
| ID | Service class |
| 1–4 | Reserved for system use. |
| 5 | Used by the superuser queue. |
| 6–13 | Used by manual WLM queues that are defined in the WLM configuration. |
| 14 | Used by short query acceleration. |
| 15 | Reserved for maintenance activities run by Amazon Redshift. |
| 100–107 |
Used by automatic WLM queue when
auto_wlm
is true.
|
对于手动 WLM,您基于
用户组
、
查询
组或 用户
角色
定义的 WLM 队列属于服务类别 ID 6—13 ,对于自动 WLM, 属于服务类别 ID 为 100—107。
使用
Query_group
,您可以强制查询进入服务类别 5 并在超级用户队列中运行(前提是您是授权的超级用户),如以下代码所示:
有关如何将查询分配给特定服务类的更多详细信息,请参阅
短查询加速 (SQA) 队列(服务类别 14)优先于运行时间较长的查询。如果启用 SQA,则可以减少专用于运行短查询的 WLM 队列。此外,长时间运行的查询无需与队列中插槽的短查询相抗衡,因此您可以将 WLM 队列配置为使用更少的
默认情况下,在默认参数组和所有新参数组中启用 SQA。SQA 最多可以有六个查询的并发性。
既然您已经了解了查询是如何提交给服务类的,那么了解避免失控查询和针对意外事件启动操作的方法非常重要。
查询监控规则
您可以使用 Amazon Redshift
Redshift 集群会自动收集查询监控指标。您可以查询系统视图
SVL_QUERY_METRICS_SUMMARY 以帮助确定
定义 QMR 的阈值。然后根据以下属性创建 QMR:
- 查询运行时间,以秒为单位
- 查询返回行数
- SQL 语句的 CPU 时间
有关 QMR 的完整列表,请参阅

创建示例参数组
在我们的 exampleCorp 用例中,我们演示了预配置 Redshift 数据仓库的自动和手动 WLM,并分享了 WLM 的无服务器视角。
以下
![]()
使用自动 WLM 的企业数据仓库 Redshift 集群
对于 EDW 集群,我们使用自动 WLM。
要配置服务类别,我们要查看所有三个选项:
用户角色 、 用户
组和查询组
。
下面简要介绍如何在 WLM 队列中进行设置,然后将其用于查询。
在 Amazon Redshift 控制台上, 在导航窗格的 配置 下,选择 工作负载 管理。 您可以创建新的参数组或修改您创建的现有参数组。选择参数组以编辑其队列。总会有一个默认队列(如果定义了多个队列,则为最后一个队列),对于没有路由到任何特定队列的查询,这是一个包罗万象。
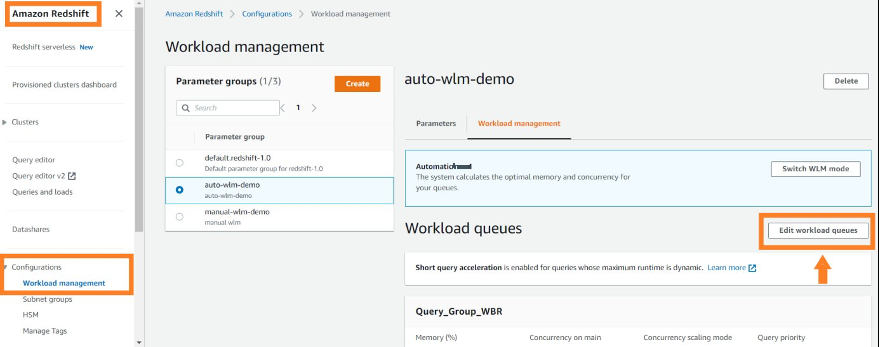
WLM 中的用户角色
随着 WLM 队列中引入用户角色,现在您可以通过向不同的队列添加不同的角色来管理工作负载。这可以帮助您根据用户拥有的角色确定查询的优先级。当用户运行查询时,WLM 将检查该用户的角色是否已添加到任何工作负载队列中,并将查询分配给第一个匹配队列。要将角色添加到 WLM 队列中,您可以转到 WLM 页面,创建或修改现有的工作负载队列,在队列中添加用户的角色,然后选择 匹配通配符 来添加以通配符 形式匹配的角色。
有关如何从群组转换为角色的更多信息,请参阅
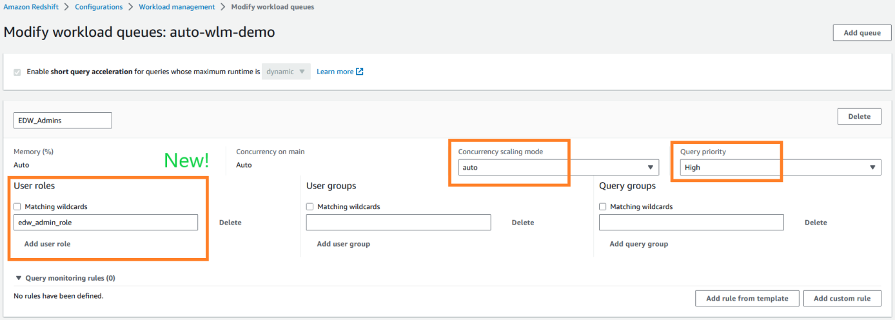
在以下示例中,我们创建了 WLM 队列
edw_admins,它使用在 Amazon Redshift 中 创建的 edw
_admin_role 来提交
该队列中的工作负载。
edw_admins
队列是使用高优先级和自动并发扩展模式创建的。
用户组
群组是所有被授予与群组关联权限的用户的集合。您可以使用群组来简化权限管理,只需授予一次权限即可。如果群组成员被添加或删除,则无需在用户级别对其进行管理。例如,您可以为销售、管理和支持创建不同的组,并向每个组中的用户授予他们工作所需的数据的适当访问权限。
您可以授予或撤消
ETL、数据分析师或 BI 或决策支持系统可以使用用户组来更好地管理和隔离其工作负载。
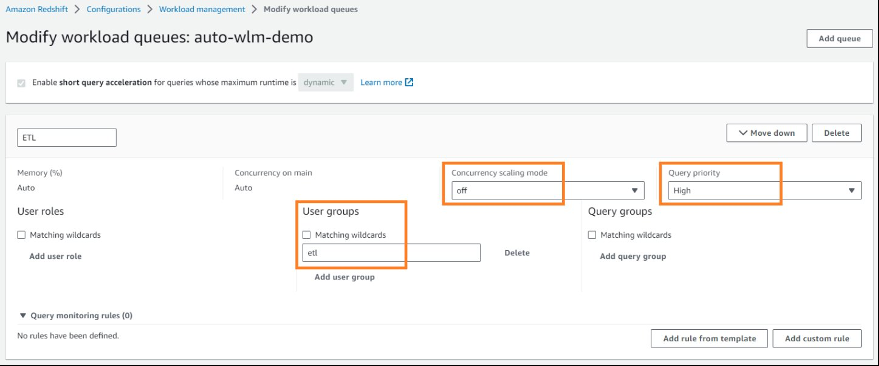
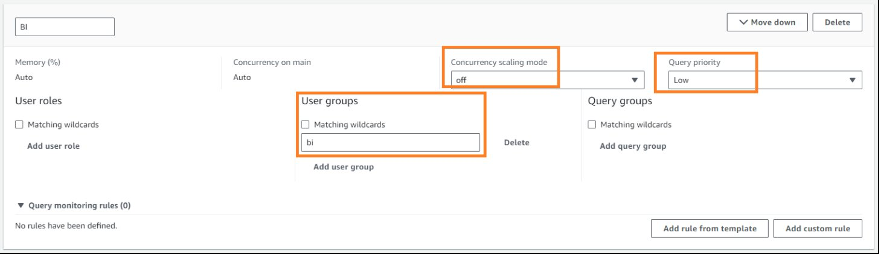
在我们的示例中,ETL WLM 队列查询将使用用户组 etl 运行。
数据分析师组 (BI) WLM 队列查询将使用 bi 用户组运行。
选择 “
添加队列
” 以添加一个新队列,该队列将用于
user_gro
ups ,在本例中为 ETL。如果您希望将它们作为通配符(包含这些关键字的字符串)进行匹配,请选择
匹配通配符
。您可以自定义其他选项,例如查询优先级和并发缩放,如本文前面所述。选择 “
保存
” 以完成此队列设置。
在以下示例中,我们为 ETL 和 BI 创建了两个不同的 WLM 队列。ETL 队列的优先级较高,并发扩展模式已关闭,而 BI 队列的优先级较低,并发扩展模式已关闭。
使用以下代码创建包含多个用户的群组:
查询群组
Query_Gro
ups 是用于在同一会话中运行的查询的标签。可以将这些视为标签,您可能希望使用这些标签来识别具有唯一可识别性的用例的查询。在我们的示例用例中,数据分析师或商业智能或决策支持系统可以使用
query_groups
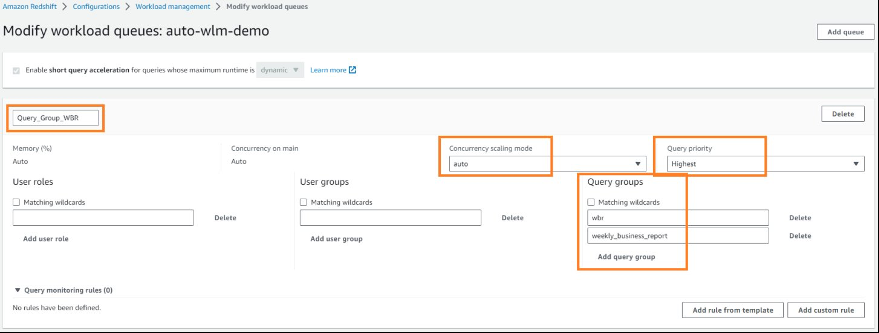
来更好地管理和隔离其工作负载。以我们的示例为例,每周业务报告可以使用
query_group
标签 wbr 运行。可以使用
query_group of marketing 运行来自市场营销部门的查询
。
使用
您可以对运行的每个查询应用单独的标签来唯一标识查询,而无需查找其 ID。
STV_INFLIGHT 表 以及 SVL_Q
LOG
视
图的结果。
选择 “
添加队列
” 以添加一个新队列,您将用于
如果您希望将它们作为通配符(包含这些关键字的字符串)进行匹配,请选择
匹配通配符
。您可以自定义其他选项,例如查询优先级和并发扩展选项,如本文前面所述。选择 “
保存
” 以保存此队列设置。
query_groups,在本例中为
business_report。
wbr 或 w
eekly_
现在让我们看看如何强制查询使用刚才创建的
query_gro
ups 队列。
通过将查询分配给相应的查询组,可以在运行时将查询分配给队列。使用 SET 命令启动查询组:
在您重置查询组或结束当前登录会话 之前,按照 SET 命令执行的查询将转到
WLM 队列 query_group_WBR
。
您指定的查询组标签必须包含在当前 WLM 配置中;否则,SET
query_group 命令对查询
队列没有影响。
有关更多
query_group
s 示例,请参阅
使用手动 WLM 营销 Redshift 集群
扩展了 ExampleCorp 的营销 Redshift 集群用例,该集群提供两种类型的工作负载:
- 在上午 7:00 至上午 9:00 之间运行 ETL 2 小时
- 在一天中的剩余时间内运行 BI 报告和仪表板
如果您的工作负载如此明确,并且您的使用范围可以通过设计进行自定义,则可能需要考虑使用
在本例 中,让我们
为了最好地利用资源,我们在 ETL 的开头使用
如果您要使用 Auto WLM,则可以通过动态更改 ETL 和 BI 队列的查询优先级来实现。
默认情况下,当您选择 “ 创建” 时 ,创建 的 WLM 将为 “自动 WLM”。您可以通过选择切换 WLM 模式 切换到手动 WLM 。 切换 WLM 模式后,选择 编辑工作负载队列 。
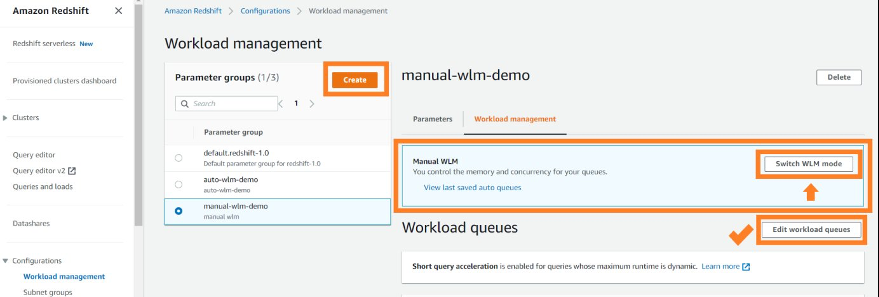
这将打开 “ 修改工作负载队列 ” 页面,您可以在其中创建 ETL 和 BI WLM 队列。
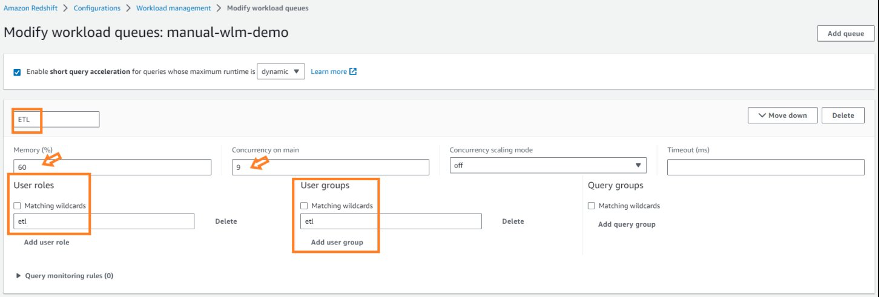
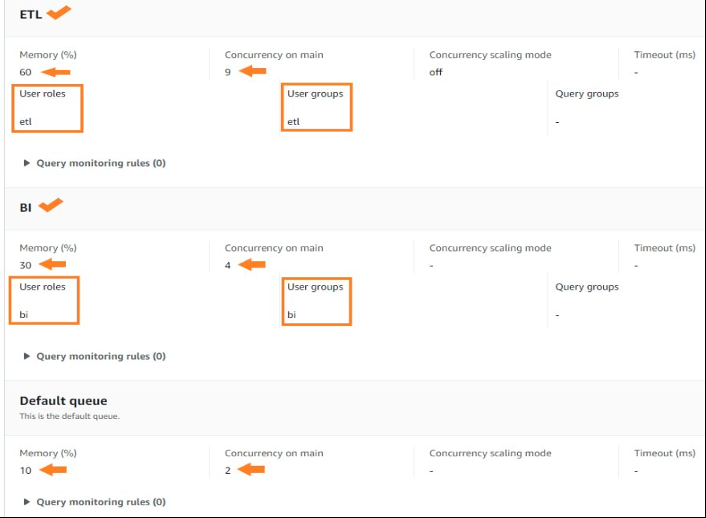
添加 ETL 和 BI 队列后,选择 保存。 你应该已经配置了以下内容:
- 一个 ETL 队列,内存分配为 60%,查询并发度为 9
- 一个 BI 队列,内存分配 30%,查询并发度为 4
- 内存分配为 10%、查询并发度为 2 的默认队列
您的 WLM 队列应显示其设置,如以下屏幕截图所示。
企业可能更愿意以自动方式完成这些步骤。对于营销数据集市用例,ETL 从上午 7:00 开始。ETL 流程的理想起点是找到一份能使您的 WLM 设置 ETL 队列友好的工作。以下是将并发和内存(均为手动 WLM 队列中的动态属性)修改为 ETL 友好型配置的方法:

前面的 亚马逊云科技 CLI 命令以编程方式设置您的 WLM 队列的配置,无需重启集群,因为更改的队列设置都是动态设置。
对于营销数据集市用例,在上午 9:00 或 ETL 结束时,您可以让任务运行 亚马逊云科技 CLI 命令,将 WLM 队列资源设置修改为双友好配置,如以下代码所示:

请注意,在手动 WLM 配置中,可以分配给队列的最大插槽为 50。但是,这并不意味着在自动 WLM 配置中,Redshift 集群总是同时运行 50 个查询。这可能会根据集群上的内存需求或其他类型的资源分配而变化。我们建议将您的手动 WLM 查询队列配置为总共 15 个或更少的查询槽。有关更多信息,请参阅
如果
审计员 Redshift 无服务器中使用 WLM 的 Redshift 数据仓库
审计员数据仓库的工作量在当月和季度末运行。对于这种周期性工作负载,无论从成本还是便于管理的角度来看,Redshift Serverless 都非常适合。Redshift Serverless 使用机器学习从您的工作负载中学习,以自动管理工作负载并自动扩展工作负载所需的计算。
在 Redshift 无服务器中,您可以设置使用量和查询限制。查询限制允许您设置 QMR。您可以选择 “
管理查询限制
” ,以便在查询超出性能边界时自动触发默认中止操作。有关更多信息,请参阅
![]()
有关 Redshift 无服务器中的其他详细限制,请参阅在
使用系统视图进行监控以获取运营指标
Amazon Redshift 中的系统视图用于监控工作负载性能。您可以使用
- 查看正在跟踪哪些查询以及工作负载管理器分配了哪些资源
- 查看查询已分配到哪个队列
- 查看工作负载管理器当前正在跟踪的查询的状态
您可以下载
结论
在这篇文章中,我们介绍了自动 WLM 和手动 WLM 模式的真实示例。我们引入了对 WLM 队列的用户角色分配,并对系统视图和表格进行了共享查询,以收集有关您的 WLM 配置的操作见解。我们鼓励您探索使用 Redshift 用户角色进行工作负载管理。使用
作者简介
 Rohit Vashshtha
是总部位于德克萨斯州达拉斯的 亚马逊云科技 高级分析专家解决方案架构师。他在设计、构建、领导和维护大数据平台方面拥有超过 17 年的经验。Rohit 使用广泛的 亚马逊云科技 服务帮助客户实现分析工作负载的现代化,并确保客户以最高的安全性和数据治理获得最佳的性价比。
Rohit Vashshtha
是总部位于德克萨斯州达拉斯的 亚马逊云科技 高级分析专家解决方案架构师。他在设计、构建、领导和维护大数据平台方面拥有超过 17 年的经验。Rohit 使用广泛的 亚马逊云科技 服务帮助客户实现分析工作负载的现代化,并确保客户以最高的安全性和数据治理获得最佳的性价比。
 Harshida Patel
是 亚马逊云科技 的首席专业人士。
Harshida Patel
是 亚马逊云科技 的首席专业人士。
 Nita Shah
是总部位于纽约的 亚马逊云科技 的分析专家解决方案架构师。她构建数据仓库解决方案已有 20 多年,专门研究亚马逊 Redshift。她专注于帮助客户设计和构建架构良好的企业级分析和决策支持平台。
Nita Shah
是总部位于纽约的 亚马逊云科技 的分析专家解决方案架构师。她构建数据仓库解决方案已有 20 多年,专门研究亚马逊 Redshift。她专注于帮助客户设计和构建架构良好的企业级分析和决策支持平台。
 季燕珠
是亚马逊 Redshift 团队的产品经理。她在行业领先的数据产品和平台的产品愿景和策略方面拥有丰富的经验。她在使用网络开发、系统设计、数据库和分布式编程技术构建大量软件产品方面具有出色的技能。在她的个人生活中,燕珠喜欢绘画、摄影和打网球。
季燕珠
是亚马逊 Redshift 团队的产品经理。她在行业领先的数据产品和平台的产品愿景和策略方面拥有丰富的经验。她在使用网络开发、系统设计、数据库和分布式编程技术构建大量软件产品方面具有出色的技能。在她的个人生活中,燕珠喜欢绘画、摄影和打网球。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。