我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 DMS 将微软 SQL Server 迁移到 Babelfish for Aurora PostgreSQL
在这篇文章中,我们将介绍如何使用
使用 Microsoft SQL Server 的客户可能希望迁移到 PostgreSQL 等开源数据库;但是,迁移应用程序本身所需的巨大努力,包括重写与数据库交互的应用程序代码,可能会成为现代化的障碍。
有了
数据迁移选项
Babelfish 附带了一个名为
有关运行 Babelfish Compass 报告并在目标 Babelfish 实例上创建对象的其他步骤的详细信息,请参阅使用 Babelfish
在 Babelfish 上创建架构后,你可以使用以下选项将数据从 SQL Server 迁移到 Babelfish for Aurora PostgreSQL 数据库:
-
使用以 Babelfish 终端节点作为目标的 亚马逊云科技 DM S 进行迁
移 — 在这种方法中,将 Aurora 集群的 Babelfish 终端节点设置为 Aurora 集群的 亚马逊云科技 数据库迁移服务 (亚马逊云科技 DMS)。Babelfish 端点支持 Babelfish for Aurora PostgreSQL 兼容版本 13.6(Babelfish 版本 1.2.0)或更高版本,截至撰写本文时,它仅支持满负载迁移;因此,它主要适用于可以支持延长停机时间的数据库。 -
使用亚马逊 Aurora PostgreSQL 终端节点作为目标进行迁移(最短的停机时间)
— 在这种方法中,Amazon Aurora 集群的写入端节点被配置为 亚马逊云科技 DMS 的目标终端节点,并将数据直接迁移到 PostgreSQL 表中。此方法支持 “仅限满载” 和 “满载” 和 CDC(
更改数据捕获 )任务。使用满载任务和 CDC 任务允许您在最短的停机时间内进行迁移。 -
使用 SQL Server 工具导出和导入
-
您可以使用
SQL Server 集成服务 (SSIS) 以及支持 BabelFish 的数据库作为数据迁移目标,但它必须是自托管的或托管在亚马逊弹性计算云 (Amazon EC2) 实例上。亚马逊云科技 架构转换工具 (亚马逊云科技 SCT) 可以将 SSIS 包转换为亚马逊云科技 Glue,以便在 Babel fish 2.4 及更高版本中提供云原生支持。 -
使用 适用于 Babelfish 2.1.0 及更高版本的
SSMS 导入/导出向导
。此
工具可通过 SSMS 使用 ,但也可以作为独立工具使用。 -
BCP 实用程序
— Babelfish 现在支持使用 BCP 客户端进行数据迁移,而 bcp
实用程序 现在支持-E 标志(用于标识列)和-b 标志(用于批量插入)。
-
您可以使用
这种使用导出/导入工具的迁移策略是手动的,主要适用于可以承受长时间停机时间的小型数据库。
解决方案概述
为了在最大限度地减少停机时间的情况下将数据库从 SQL Server 迁移到 Babelfish for Aurora PostgreSQL,我们使用带有 Amazon Aurora 写入器端点的 亚马逊云科技 DMS,并在满载后使用 CDC 进行持续复制。在这篇文章中,我们使用了 GitHub 上提供的
下图说明了我们的解决方案架构。
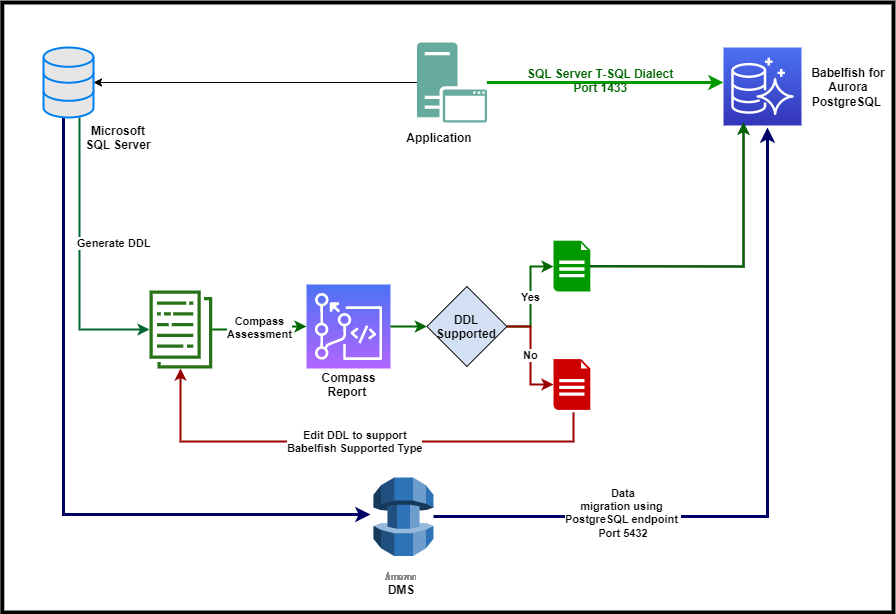
这篇文章中的步骤用于将 SQL Server 迁移到 Babelfish for Aurora PostgreSQL,但你可以使用相同的步骤迁移到自我管理的 Babelfish 实例。以下是 Babelfish 迁移过程的概述:
-
导出要从 SQL Server 迁移的数据库的数据定义语言 (DDL)。有关详细步骤,请参阅
使用 Babel fish 从 SQL Server 迁移到亚马逊 Aurora 。 -
运行
Babelfish Compass 工具 ,确定该应用程序是否包含 Babelfish 目前不支持的任何 SQL 功能。 - 查看 Babelfish Compass 评估报告,重写或删除任何不支持的 SQL 功能(这可能是一个迭代过程,具体取决于您的应用程序)。
-
在启
用 Babelfish 功能的情况下创建 亚马逊 Aurora PostgreSQL 集群 。 - 使用任何 SQL Server 客户端工具,使用 Babelfish 终端节点连接到 Amazon Aurora 集群。
- 在指定的 T-SQL 数据库中运行 DDL 来创建对象。
-
创建 A
WS DMS 实例 。 - 创建源端点以连接到 SQL Server。
-
将目标引擎端点创建为兼容 Amazon Aurora PostgreSQL 的版本并使用数据库 babelfish_db。(注意:请勿指定 SQL Server 中使用的数据库名称;我们稍后会指定。)有关更多详细信息,请参阅使用 PostgreSQL 数据库作为 亚马逊云科技 DMS 目标 。 -
指定使用
session_replication_role 的设置, 如使用 PostgreSQL 数据库作为 Aurora Postgres 中 参数组的 亚马逊云科技 数据库迁移服务 目标中所 指定的设置。这是防止外键约束和触发器被触发所必需的。 -
创建 A
WS DMS 复制任务 。 - 添加转换规则并启动迁移任务。
-
重新排序序列 。 - 验证数据。
- 重新配置您的客户端应用程序以连接到 Babelfish 端点而不是您的 SQL Server 数据库。
- 根据需要修改您的应用程序并重新测试。
- 测试和迭代,直到迁移的应用程序的功能正确。
- 执行切换。
先决条件
要部署此解决方案,您需要设置以下先决条件:
- SQL 服务器管理工作室 (SSMS)
- SQL 服务器作为源
- Babelfish 指南针
-
一个 亚马逊云科技 DMS
复制实例 -
适用于 Aurora 的 Babelfish PostgreSQL -
示例数据库 已下载,其中填充了表
此外,我们假设已使用 Compass 工具提取、分析和修改了 DDL。有关说明,请参阅
你应该使用最新版本的 Babelfish、
对于当前版本;不支持身份和时间戳数据类型
配置源数据库
您首先需要配置源数据库以进行持续复制。有关说明,请参阅
- 在 SSMS 上,选择(右键单击) 复制 ,然后选择 配置分发 。
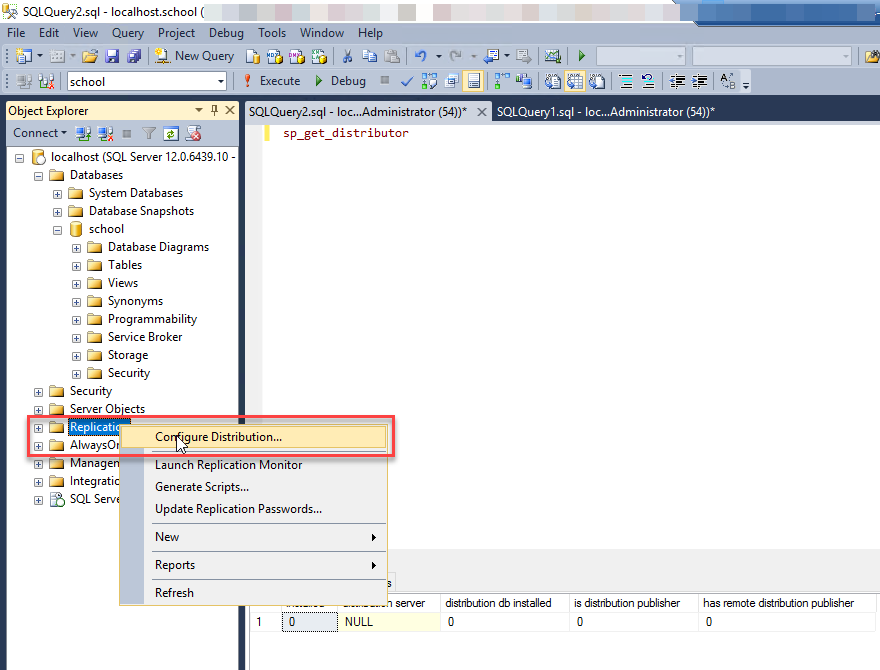
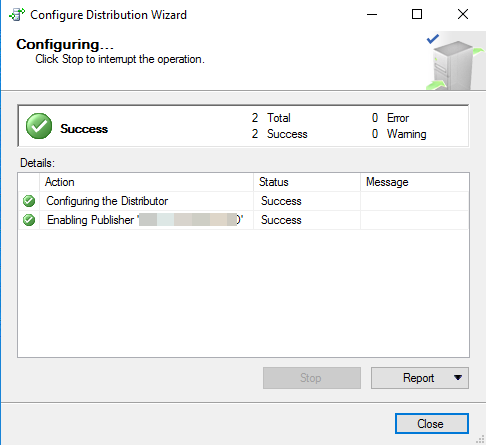
- 配置完成后,选择 “ 关闭 ” 。
配置源端点
现在,您可以创建源端点来连接源数据库。
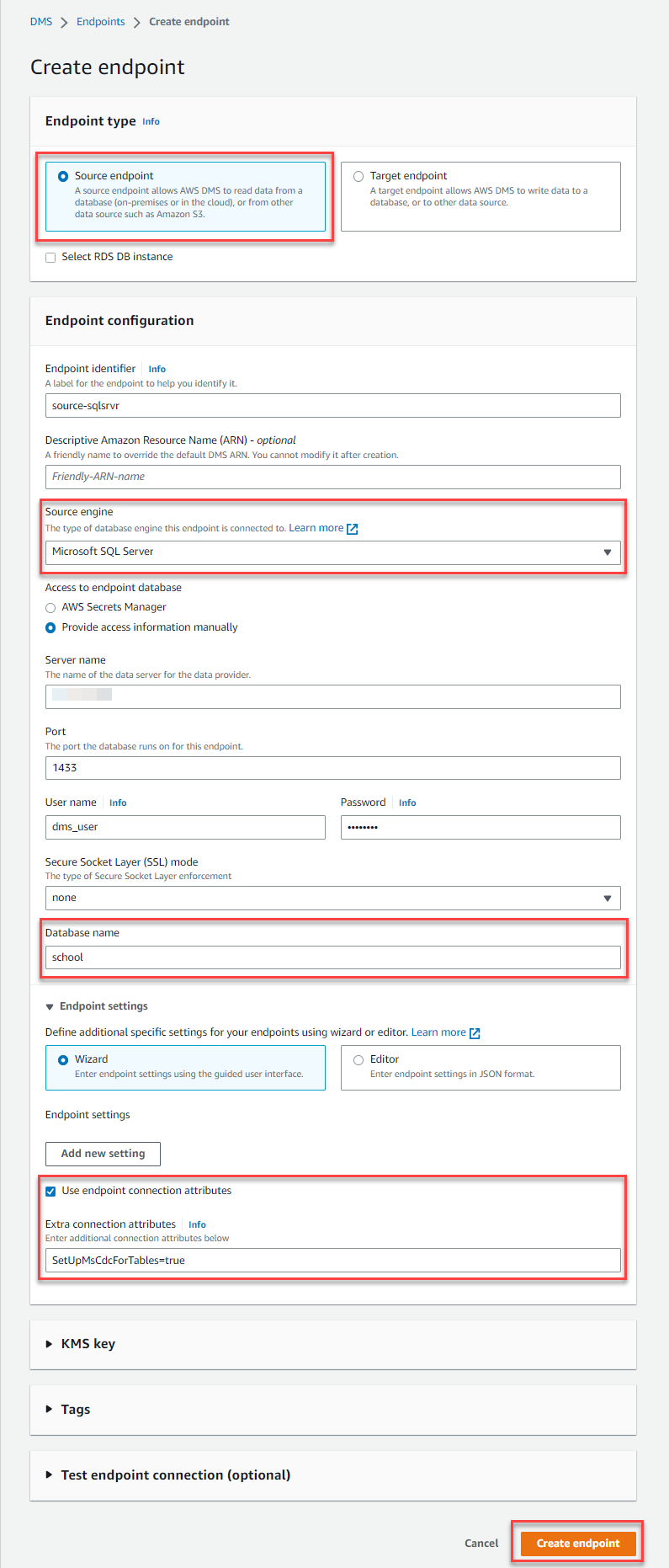
- 在 亚马逊云科技 DMS 控制台上, 在导航窗格中选择 终端节点 。
- 选择 创建端点 。
- 对于 端点类型 ,选择 源端点 。
- 对于 端点标识符 ,输入相应的名称。
- 对于 源引擎, 选择 微软 SQL 服务器 。
- 提供源服务器的服务器名称或 IP 地址、SQL Server 端口以及用于连接到源数据库的用户名和密码。
- 在 数据库名称 中 ,输入相应的名称(此职位为学校)。
- 展开 端点设置 并选择 使用端点连接属性 。
-
创建连接属性
setupmscdcfortables=True以自动为您的数据库设置 CDC。 - 选择 创建端点 。
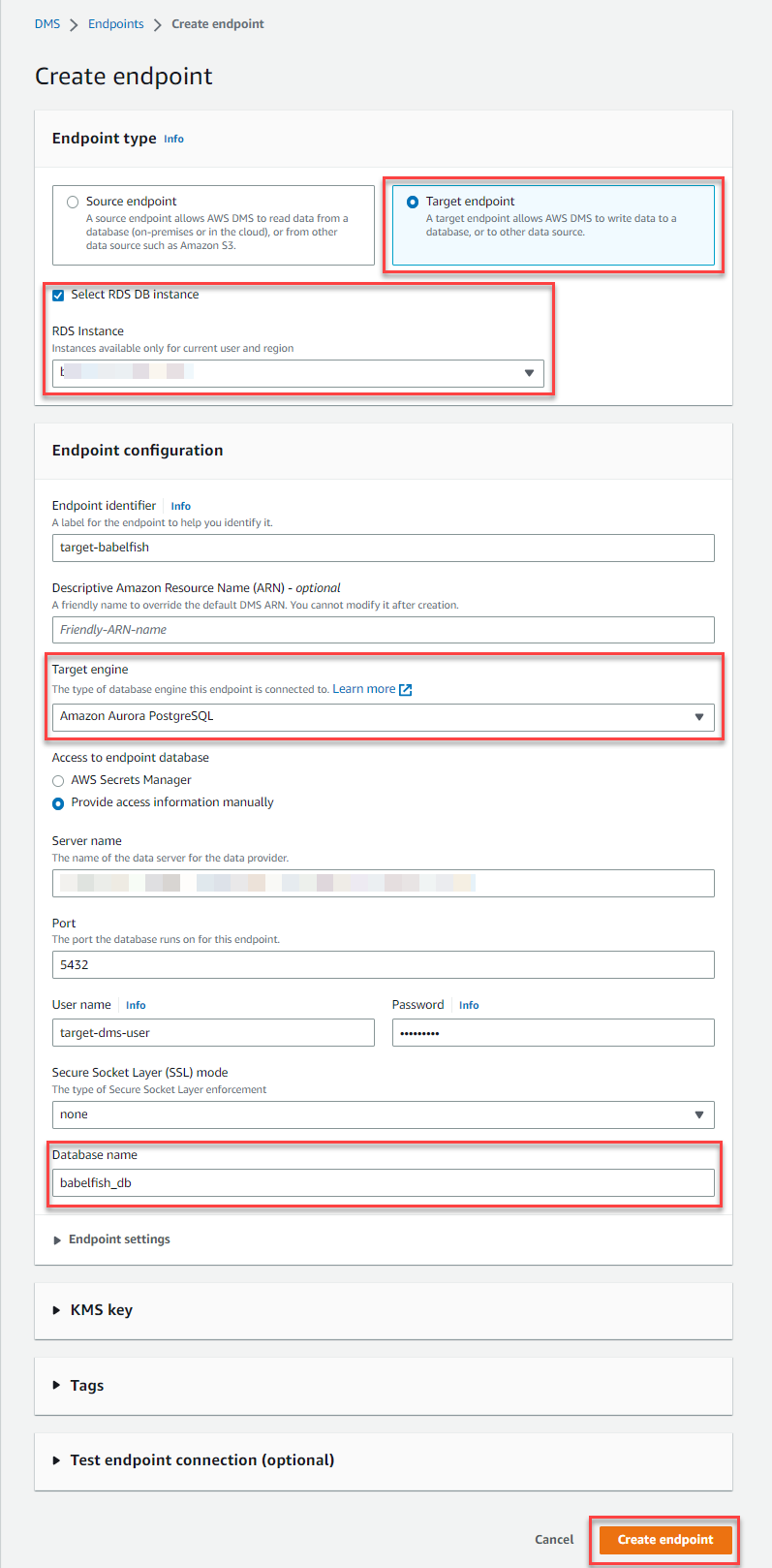
配置目标端点
接下来,我们创建目标端点。
- 在 亚马逊云科技 DMS 控制台上, 在导航窗格中选择 终端节点 。
- 选择 创建端点 。
- 选择 目标端点 。
- 选择 选择 RDS 数据库实例 ,然后选择 Babelfish 集群。
- 对于 端点标识符 ,输入适当的名称或保留为默认值。
- 对于 目标引擎 ,选择 亚马逊 Aurora PostgreSQL 。
-
如果你没有使用
亚马逊云科技 Secrets Manager ,请手动输入访问信息。 -
对于 数据库名称 ,对于最高 AWS DMS 3.4.7 的 DMS 版本,请输入 babelfish_db。
对于 DMS 版本 3.5.1 及更高版本,在 Postgres 目标端点额外连接属性中,设置 databasemode=babelFish 和 babelfishdatabasename=School - 选择 创建端点 。
创建并运行迁移任务
现在我们可以创建 亚马逊云科技 DMS 迁移任务。
- 在 亚马逊云科技 DMS 控制台上,选择导航窗格 中的 数据库迁移任务 。
- 选择 “ 创建任务 ” 。
- 在 任务标识符 中 ,输入一个名称。
- 指定您的复制实例、源终端节点和目标终端节点。
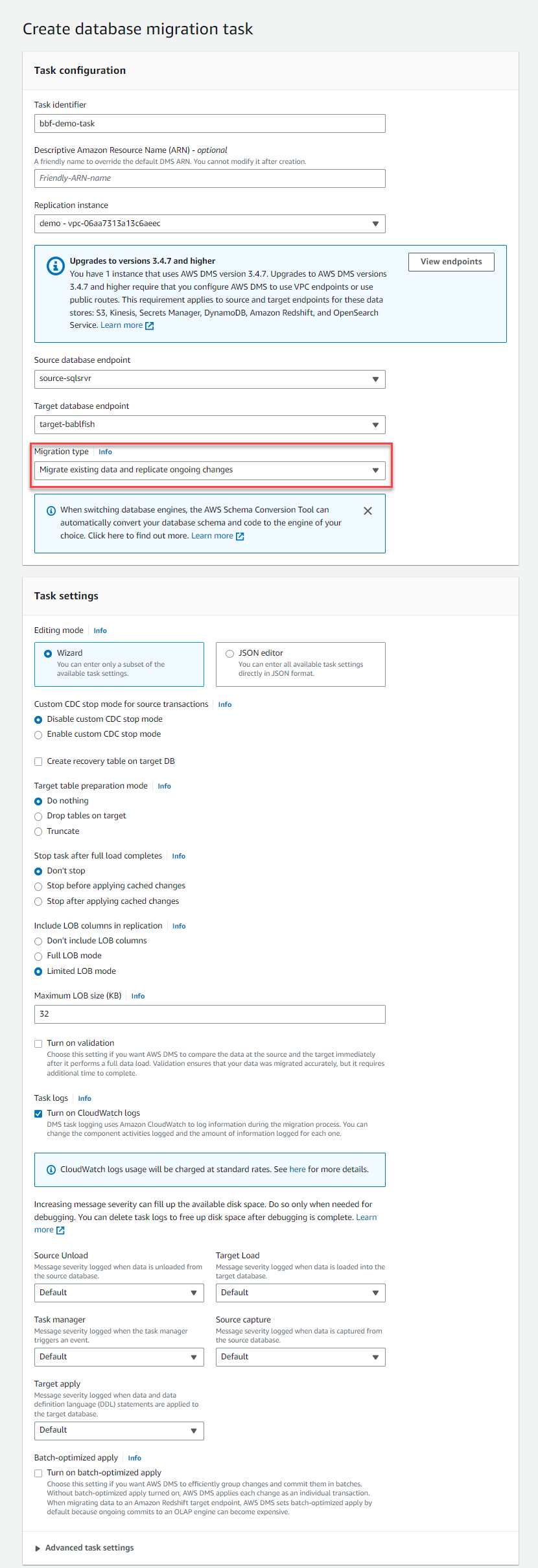
- 对于 迁移类型 ,选择 迁移现有数据并复制正在进行的更改 以迁移整个数据库并复制正在进行的更改,从而最大限度地减少停机时间。
- 对于 T arget 表准备模式 ,选择 “ 什么都不 做 ” 。
- 使用 “复制持续更改” 选项时,亚马逊云科技 DMS 提供 2 种用于迁移 LOB 对象的设置,LOB 模式决定如何处理 LOB:
完整 LOB 模式 -在完整 LOB 模式下,无论大小如何,亚马逊云科技 DMS 都会将所有 LOB 从源迁移到目标。在此配置中,亚马逊云科技 DMS 没有关于预期的最大 LOB 大小的信息。因此,LOB 是逐一迁移的。 完整 LOB 模式 为移动表中的所有 LOB 数据提供了便利,但该过程可能会对性能产生重大影响。
受限 LOB 模式 -在受限 LOB 模式下,您可以设置让 亚马逊云科技 DMS 接受的最大 LOB 大小。这使得 亚马逊云科技 DMS 能够预分配内存并批量加载 LOB 数据。超过最大 LOB 大小的 LOB 将被截断,并向日志文件发出警告。在受限 LOB 模式下,与完整 LOB 模式相比,您可以获得显著的性能。我们建议您尽可能使用有限的 LOB 模式。建议的最大值为 102400 KB (100 MB)。
在某些情况下, 完整 LOB 模式 可能会导致表格错误。如果发生这种情况,请为加载失败的表创建单独的任务。然后使用 受限 LOB 模式 为 最大 LOB 大小 (KB ) 指定相应的值。
连接到源 SQL Server 实例,然后运行以下脚本来确定最大日志大小:-
使用上面的值来指定最大 LOB 大小。
- 将剩余值保留为默认值。
- 选择 “ 打开 CloudWatch 日志 ” 以启用日志记录并保持默认的日志记录级别。
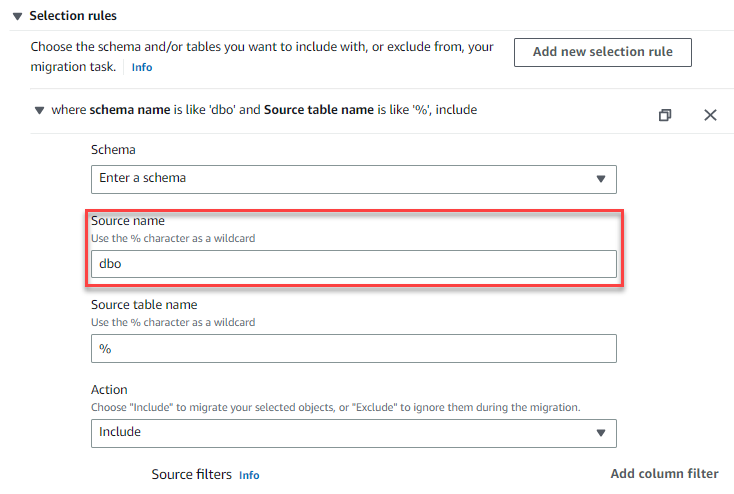
- 在 表映射 部分中,展开 选择规则 。
-
创建规则以包含
dbo架构中的所有表。
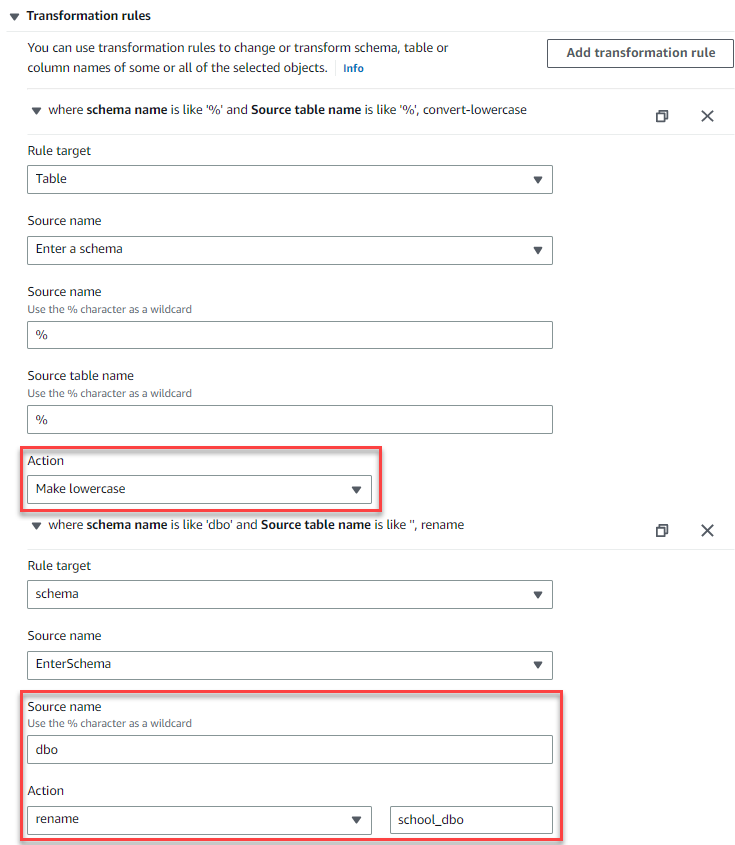
-
添加两条转换规则以与 Babelfish 中的架构映射保持一致(如果您使用的是
单数据库迁移模式 ,则可以跳过步骤 b):将- 所有表 重命名为小写。
-
将架构从
dbo 重命名为 sch。ool_dbo
- 将其余选项保留为默认值,然后选择 创建任务 以启动任务。
- 在任务详细信息页面上,导航到 表统计 信息 选项卡以监控迁移情况。
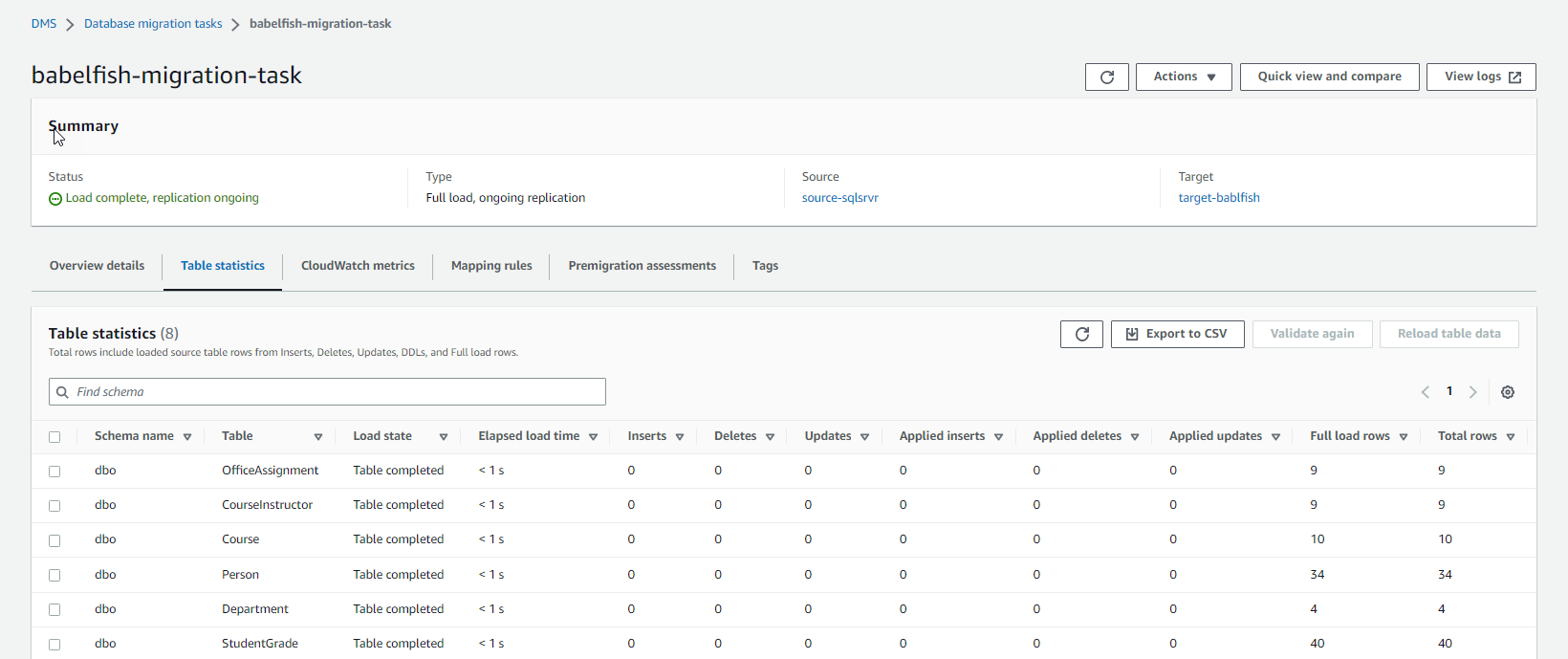
测试正在进行的复制
亚马逊云科技 DMS 任务完成满载后,通过在源数据库中插入更多行来测试正在进行的复制。然后监控 亚马逊云科技 DMS 任务并验证目标 Babelfish 数据库中的数据。
-
在源数据库中运行以下插入查询;在这篇文章中,我们使用的是来自学校数据库的 DDL, 该数据库 在 Person 表中有一个标识列表示 personid 列
在 SQL Server 源数据库上插入成功,但在 CDC 阶段在 亚马逊云科技 DMS 中插入失败,并显示错误:
“错误:无法在 “personid” 列中插入非默认值
;”
Babelfish 3.1.0 亚马逊 Aurora Postgres 15.2 不支持复制身份列。要修复此问题,请在目标 Babelfish 数据库中将该表创建为串行数据类型。
这篇文章的限制部分讨论了目标 Babelfish Endpoint 上的表定义没有将标识列更新为序列时的限制。
在 Babelfish 中创建表时,请更改以下列定义。
在 SQL 服务器上:
To Serial on Babelfish:
- 在 亚马逊云科技 DMS 任务上重新启动任务或重新加载表。
- 监控 亚马逊云科技 DMS 任务并检查表中是否有 Person。
插入和应用的插入应显示 2,总行数也将增加 2。
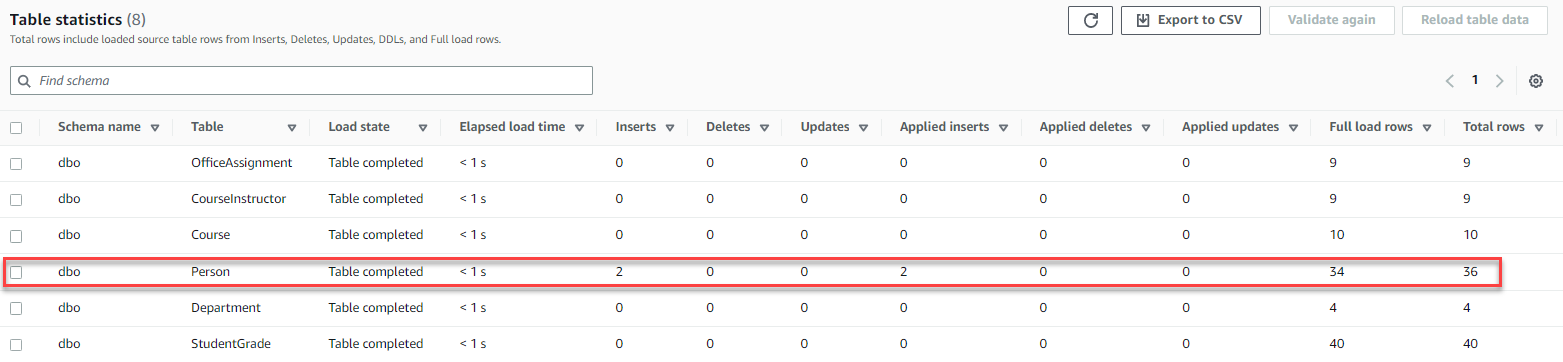
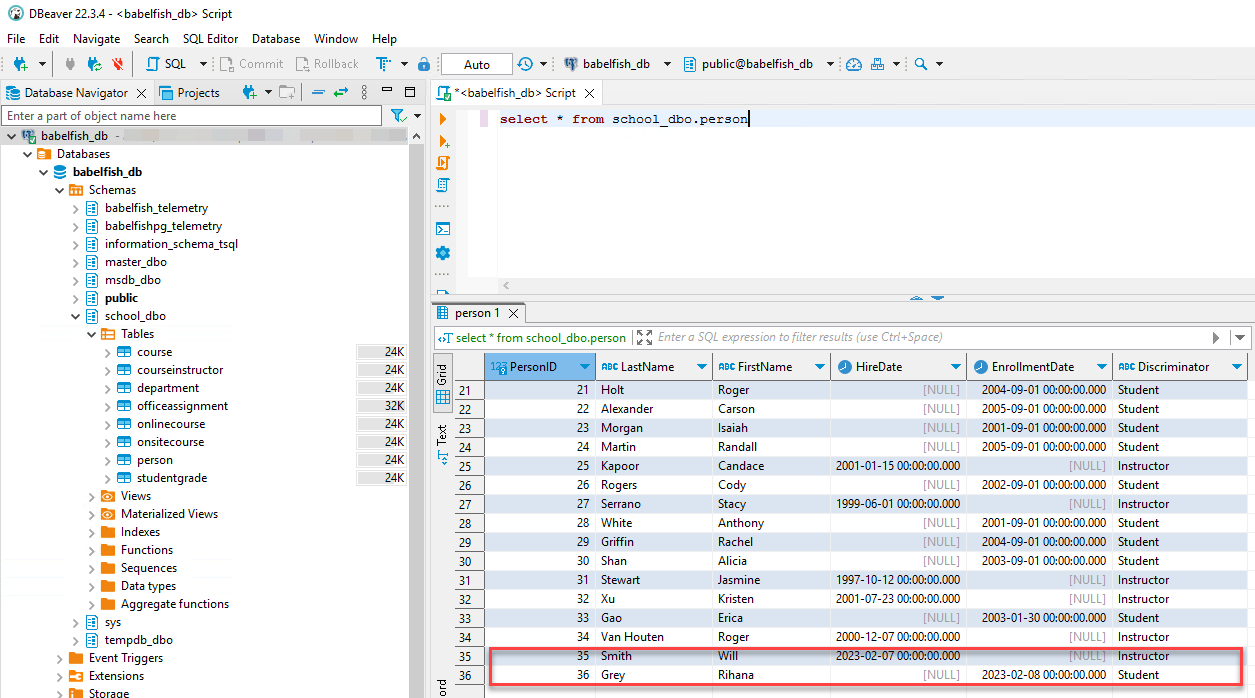
- 连接到目标 Babelfish 集群并查询 Person 表以验证插入的行。
重置序列
在将应用程序更改为使用 Babelfish 端点之前,必须运行以下脚本来重新设置序列以确保在切换窗口期间更新序列的正确值;
使用 SQL Server 客户端连接到 Amazon Aurora 集群的 Babelfish 端点,然后运行以下查询生成 SQL 来更新序列值:
根据前面查询的结果,将其作为新查询在 SQL Server 客户端中重新运行。
确认源和目标处于同步状态后,您可以切换并开始使用 Amazon Aurora 集群。
局限性
我们使用 Babelfish for Aurora PostgreSQL 15.2 和 亚马逊云科技 DMS 3.4.7 撰写了这篇文章。目前的一些限制是:
- Babelfish 仅支持使用 BYTEA 数据类型迁移 Amazon Aurora PostgreSQL 15.2 及更高版本的二进制、VARBINARY 和图像数据类型。
- 如果您使用 PostgreSQL 目标端点为从 SQL Server 向 Babelfish 的持续复制创建迁移任务,则需要将串行数据类型分配给任何使用身份列的表
- 在某些情况下。完整 LOB 模式可能会导致表迁移错误,建议对这些特定表使用受限 LOB 模式。
- Babelfish 终端节点不支持 亚马逊云科技 DMS 数据验证。
- 由于精度差异,某些数据类型(例如日期时间)对 Postgres 终端节点的 亚马逊云科技 DMS 数据验证可能会失败。
有关更多信息,请参阅 — 将
清理
为避免产生不必要的费用,请删除您在本文中创建的资源。请参阅以下说明:
-
删除 Aurora 数据库集群和数据库实例 -
终止您的实例
摘要
在这篇文章中,我们展示了如何使用兼容亚马逊 Aurora PostgreSQL 的版本作为目标引擎,使用适用于 Aurora PostgreSQL 的 Babelfish 从源 SQL Server 数据库进行持续迁移。你可以使用带有 PostgreSQL 目标终端节点的 亚马逊云科技 DMS 将你的 SQL 服务器数据库迁移到 Babelfish for Aurora PostgreSQL,同时最大限度地减少停机时间
在您的 亚马逊云科技 账户中试用此解决方案,如果您有任何意见或问题,请将其留在评论部分。
作者简介
 Roneel Kumar
是亚马逊网络服务高级数据库专家解决方案架构师,专门研究关系数据库引擎。他为 APJ 地区的客户提供技术援助、运营和数据库实践。
Roneel Kumar
是亚马逊网络服务高级数据库专家解决方案架构师,专门研究关系数据库引擎。他为 APJ 地区的客户提供技术援助、运营和数据库实践。
 塔兰吉特·辛格
是 亚马逊云科技 专业服务的数据库迁移专家。他与客户紧密合作,提供技术援助,帮助他们将现有数据库迁移到 亚马逊云科技 Cloud 并对其进行现代化改造。
塔兰吉特·辛格
是 亚马逊云科技 专业服务的数据库迁移专家。他与客户紧密合作,提供技术援助,帮助他们将现有数据库迁移到 亚马逊云科技 Cloud 并对其进行现代化改造。
 Sandeep Rajain
是一名数据库专家解决方案架构师,对关系和非关系型 亚马逊云科技 云数据库和用于将数据库迁移到云端的服务有着浓厚的兴趣和专业知识。他与组织合作,帮助他们使用 亚马逊云科技 服务制定数据策略并实现数据库现代化。
Sandeep Rajain
是一名数据库专家解决方案架构师,对关系和非关系型 亚马逊云科技 云数据库和用于将数据库迁移到云端的服务有着浓厚的兴趣和专业知识。他与组织合作,帮助他们使用 亚马逊云科技 服务制定数据策略并实现数据库现代化。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。