我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
监控和优化适用于 Apache Spark 的 亚马逊云科技 Glue 的成本
我们从客户那里得到的最常见问题之一是如何有效监控和优化 亚马逊云科技 Glue for Spark 的成本。亚马逊云科技 Glue 的功能和定价选项的多样性使您可以灵活地有效管理数据工作负载的成本,同时还能根据业务需求保持性能和容量。尽管 亚马逊云科技 Glue 工作负载的成本优化的基本过程保持不变,但您可以监控任务运行并分析成本和使用情况,以节省开支,并采取措施对代码或配置进行改进。
在这篇文章中,我们演示了一种战术方法,通过在 亚马逊云科技 Glue 工作负载之上进行监控和优化技术,帮助您管理和降低成本。
监控适用于 Apache Spark 的 亚马逊云科技 Glue 的总体成本
适用于 Apache Spark 的 Aws Glue 根据数据处理单元 (DPU) 的数量按小时收费,以 1 秒为增量收费,最少 1 分钟。在
亚马逊云科技 Cost Explorer
在
- 在成本管理器控制台上,创建新的成本和使用情况报告。
- 对于 “ 服务 ” ,选择 Glu e 。
-
对于
使用类型
,选择以下选项:为标准作业
-
选择
-etl-DPU-hour(DPU-hour)
。
为 Flex
-
作业选择
-etl-Flex-DPU-Hour (DPU-
Hour)。 -
选择
-glueInteractivesSession-DPU-Hour(DPU-Hour)进行交互
式会话。
-
选择
-etl-DPU-hour(DPU-hour)
- 选择 “ 应用 ” 。

要了解更多信息,请参阅
监控单个作业运行成本
本节介绍了一种在适用于 Apache Spark 的 亚马逊云科技 Glue 上监控单个任务运行成本的方法。有两种选择可以实现此目的。
亚马逊云科技 Glue Studio 监控页面
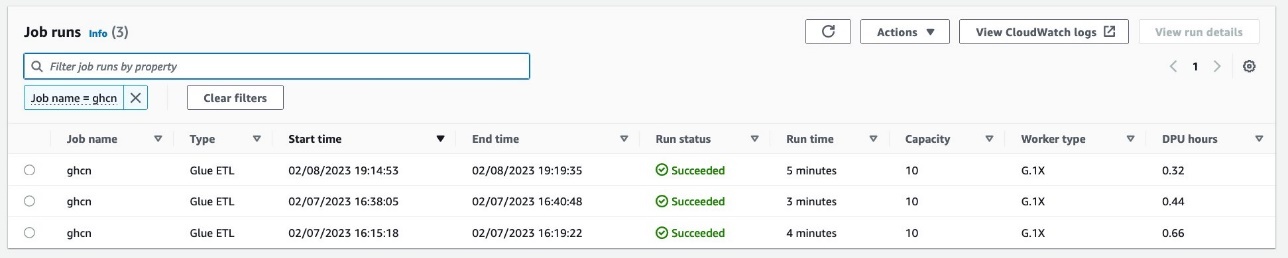
在 亚马逊云科技 Glue Studio 的 监控 页面上,您可以监控您在特定任务运行上花费的 DPU 时长。以下屏幕截图显示了处理相同数据集的三次作业运行;第一次作业运行花费了 0.66 个 DPU 小时,第二次运行花费了 0.44 个 DPU 小时。使用 Flex 的第三个只用了 0.32 个 DPU 小时。
getJobRun 和 getJobruns API
可以通过 亚马逊云科技 API 检索每次任务运行的 DPU 小时值。
对于自动扩展任务和 Flex 作业,getJobR
un 和 getJob
runs API
响应中提供字段 dpusEc
onds:
dpusEconds 字段返回 1137.0。这意味着 0.32 个 DPU 小时数,可以用
1137.0
/(60*60) =0.32 来计算。
对于其他没有自动缩放的标准作业,
dpusEconds
字段不可用 :
对于这些作业,您可以按
执行时间*最大容量/ (60*60) 计算 DPU 工时
。 然后你每小时获得
157*10/ (60*
60) =0.44 的 DPU。 请注意,亚马逊云科技 Glue 2.0 及更高版本的最低账单为 1 分钟。
亚马逊云科技 CloudFormation 模板
由于可以通过 getJobRu
n 和 GetJob
runs
API 检索 DPU 时长,因此您可以将其与亚马逊 CloudWatch 等其他服务集成, 以监控 DPU 使用时长
为了帮助您快速进行配置,我们提供了一
CloudFormation 模板生成以下资源:
-
亚马逊云科技 身份和访问管理 (IAM) 角色 - Lambda 函数
- EventBridge 规则
要创建资源,请完成以下步骤:
- 登录 亚马逊云科技 CloudFormation 控制台。
-
选择启动堆栈:

- 选择 “ 下一步 ” 。
- 选择 “ 下一步 ” 。
- 在下一页上,选择 “ 下一步 ” 。
- 查看最后一页上的详细信息,然后选择 “ 我承认 亚马逊云科技 CloudFormation 可能会创建 IAM 资源 ”。
- 选择 创建堆栈 。
创建堆栈最多可能需要 3 分钟。
在您完成堆栈创建后,当 亚马逊云科技 Glue 任务完成时,以下 DpuHours 指标将在 CloudWatch 的 Glue 命名空间下发布:
- 汇总指标 — Dimension= [jobType、GlueVersion、ExecutionClass]
- 每份工作指标 — 维度= [jobName,jobrunid=全部]
- 每项作业运行指标 — Dimension= [jobName,jobrunid]
汇总指标和每项任务指标如以下屏幕截图所示。

每个数据点代表每个作业运行的 dpuHours,因此 CloudWatch 指标的有效统计数据为 SUM。借助 CloudWatch 指标,您可以详细了解 DPU 时长。
优化成本的选项
本节介绍在适用于 Apache Spark 的 亚马逊云科技 Glue 上优化成本的关键选项:
- 升级到最新版本
- 自动缩放
- 屈伸
- 适当设置作业的超时时间
- 互动会议
- 适用于直播工作的较小员工类型
我们将深入研究各个选项。
升级到最新版本
让 亚马逊云科技 Glue 任务运行在最新版本上使您能够利用 亚马逊云科技 Glue 提供的最新功能和改进以及 Apache Spark 等支持引擎的升级版本。例如,亚马逊云科技 Glue 4.0 包含经过优化的新版 Apache Spark 3.3.0 运行环境,增加了对内置熊猫 API 的支持以及对 Apache Hudi、Apache Iceberg 和 Delta Lake 格式的原生支持,从而为你提供了更多分析和存储数据的选项。它还包括一款全新的高性能
自动缩放
降低成本最常见的挑战之一是确定合适的资源来运行作业。用户倾向于为避免资源相关问题而过度配置员工,但是其中一部分DPU未被使用,这不必要地增加了成本。从 亚马逊云科技 Glue 3.0 版开始,亚马逊云科技 Glue 自动扩展可帮助您根据工作负载动态地向上和向下扩展批处理任务和流式处理任务的资源。Auto Scaling 减少了优化工作人员数量的需求,以避免为工作过度配置资源或为闲置员工付费。
要在 亚马逊云科技 Glue Studio 上启用自动扩展,请转到您的 亚马逊云科技 Glue 任务的 “任务详情 ” 选项卡,然后选择 “ 自动扩展工作人员数量 ” 。

你可以在
屈伸
对于不需要快速任务启动时间或有能力在出现故障时重新运行作业的非紧急数据集成工作负载,
要在 亚马逊云科技 Glue Studio 上启用 Flex,请转到 任务的 “任务详情 ” 选项卡,然后选择 “ 弹性执行 ” 。

您可以在
互动会议
创建 亚马逊云科技 Glue 任务的开发人员的一种常见做法是,每次修改代码时都会多次运行同一个作业。但是,这可能不具有成本效益,具体取决于分配给该作业的工作人员数量和运行该作业的次数。此外,这种方法可能会减慢开发时间,因为你必须等到每个作业运行完成。为了解决这个问题,我们在 2022 年发布了 亚马逊云科技 Glue
适当设置作业的超时时间
由于配置问题、脚本编码错误或数据异常,有时 亚马逊云科技 Glue 任务可能需要很长时间或难以处理数据,并且可能导致意外收费。亚马逊云科技 Glue 使您能够为任何任务设置超时值。默认情况下,亚马逊云科技 Glue 任务配置为 48 小时作为超时值,但您可以指定任何超时时间。我们建议您确定作业的平均运行时间,并在此基础上设置适当的超时时间。这样,您可以控制每次作业运行的成本,防止意外收费,并尽早发现与作业相关的任何问题。
要更改 亚马逊云科技 Glue Studio 上的超时值,请转到 任务的 “任务详情 ” 选项卡,然后输入 任务超时 值 。

交互式会话还具有在会话上设置空闲超时值的相同功能。Spark ETL 会话的默认空闲超时值为 2880 分钟(48 小时)。要更改超时值,你可以使用
适用于直播工作的较小员工类型
实时处理数据是客户的常见用例,但有时这些流的数据量是零星的,而且数据量很少。对于这些工作负载,G.1X 和 G.2X 工作人员类型可能太大,特别是当我们考虑到流媒体作业可能需要全天候运行时。为了帮助您降低成本,我们在 2022 年发布了
要在 亚马逊云科技 Glue Studio 上选择 G.025X 工作人员类型,请转到任务的 “ 作业详情 ” 选项卡。对于 类型 ,选择 Spark Stre aming ,然后 为 工作人员 类型选择 G 0.25X 。

您可以在
性能调整以优化成本
性能调整在降低成本方面起着重要作用。性能调整的第一个操作是识别瓶颈。如果不测量性能和找出瓶颈,经济高效地进行优化是不现实的。
以下是优化成本的高级策略:
- 扩展集群容量
- 减少扫描的数据量
- 并行处理任务
- 优化洗牌
- 克服数据偏差
- 加快查询规划
在这篇文章中,我们将讨论减少扫描的数据量和并行处理任务的技术。
减少扫描的数据量:启用作业书签
减少扫描的数据量:分区修剪
如果事先对输入数据进行了分区,则可以通过修剪分区来减少数据扫描量。
对于 亚马逊云科技 Glue DynamicFrame,设置
push_down_predicate (和 Cat
itionPredicate),如以下代码所示。要了解更多信息,请参阅在
alogPar
t
对于 Spark DataFrame(或 Spark SQL),设置一个 where 或 filter 子句来修剪分区:
并行化任务:并行化 JDBC 读取
来自 JDBC 源的并发读取次数由配置决定。请注意,默认情况下,单个 JDBC 连接将通过 SE
LE
CT 查询从源读取所有数据。
亚马逊云科技 Glue DynamicFrame 和 Spark DataFrame 都支持通过拆分数据集来对多个任务进行并行数据扫描。
对于 AWS Glue DynamicFrame,设置
要了解更多信息,请参阅并行
哈希域 或哈希表达
式和
哈希
分区。
在
对于 Spark DataFrame,设置
分区数 、 分区
列
、下限和上限。
结论
在这篇文章中,我们讨论了在适用于 Apache Spark 的 亚马逊云科技 Glue 上监控和优化成本的方法。使用这些技术,您可以有效监控和优化 亚马逊云科技 Glue for Spark 的成本。
如果您有意见或反馈,请在评论中留言。
附录:亚马逊 CloudWatch 收费
当您将亚马逊 CloudWatch 与 亚马逊云科技 Glue 任务一起使用时,您需要按标准费率收取 CloudWatch 指标和 CloudWatch Logs 的费用。在
-
任务指标 :启用任务指标并创建 CloudWatch 自定义指标时,您会产生额外费用。 -
应用程序日志 :在 CloudWatch 日志
组 /aws-glue/jobs/output 和/aws-glue/jobs/error 中汇总应用程序日志需要支付额外费用。 -
持续日志记录 :启用持续日志记录 并且 CloudWatch 日志事件在 CloudWatch 日志组 /aws-glue/jobs/logs-v2 中发出,则会产生额外费用。
当您想要优化与 Glue 任务相关的 CloudWatch 费用时,首先应在 亚马逊云科技 Cost Explorer 中看到明细信息。
优化 CloudWatch 指标的成本
为了减少指标费用,您可以禁用工作指标。请注意,这篇文章中提供的CloudFormation模板创建了自定义指标,您还会因此产生额外费用。
优化 CloudWatch 日志的成本
CloudWatch Logs 的定价主要定义为摄取和存档存储。
要减少日志提取的费用,您可以执行以下操作:
-
减少作业脚本中不需要的日志记录,例如
print ()、df.show ()和自定义记录器调用 - 配置 标准日志过滤器 而不是 不配置过滤器
-
避免将生产作业的日志级别设置 为
DEBUG
要降低日志存档存储费用,您可以为日志组配置保留期。要了解更多信息,请参阅
作者简介

 关山 则隆
是 亚马逊云科技 Glue 团队的首席大数据架构师。他负责构建软件工件以帮助客户。在业余时间,他喜欢骑着新的公路自行车骑自行车。
关山 则隆
是 亚马逊云科技 Glue 团队的首席大数据架构师。他负责构建软件工件以帮助客户。在业余时间,他喜欢骑着新的公路自行车骑自行车。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。