我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
监控 Valkey 版 Amazon ElastiCache 的服务器端延迟
Amazon ElastiCache 是 Valkey 和 Redis 操作系统兼容的内存缓存,可为实时应用程序提供微秒级延迟。ElastiCache 通常用于要求苛刻的工作负载和延迟敏感型用例,例如缓存、游戏排行榜、媒体流和会话存储,其中每微秒都很重要。
现代应用程序是作为一组微服务构建的,一个组件的延迟会影响整个系统的性能。监控延迟对于保持优秀性能、增强用户体验和保持系统可靠性至关重要。在这篇文章中,我们将探讨如何有效监控您自行设计(基于节点)的 ElastiCache 集群的延迟、检测异常和解决高延迟问题。
监控 Amazon ElastiCache 中的延迟
为了实现稳定的性能,您应该监控端到端的客户端延迟,测量 Valkey 客户端和 ElastiCache 引擎之间的往返延迟。这有助于识别堆栈中的瓶颈。如果您在集群上观察到较高的端到端延迟,则延迟可能是由于服务器端、客户端的操作造成的,或者归因于网络延迟的增加。下图说明了从客户端测量的往返延迟与服务器端延迟之间的区别。
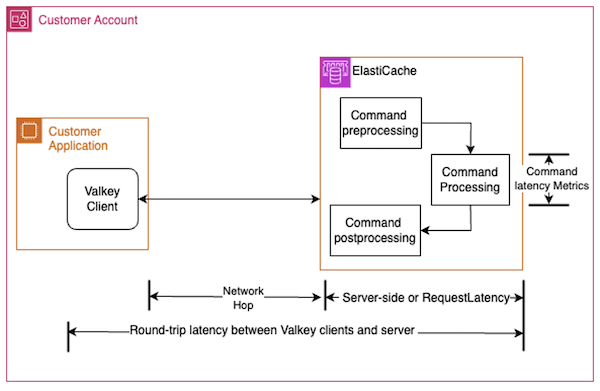
为了观察服务器端延迟,我们引入了 SuccessfulRequestLatency 和 SuccessfulWriteRequestLatency CloudWatch 指标,这些指标以微秒为单位精确衡量了 ElastiCache for Valkey 引擎响应成功执行的请求所花费的时间。这些新指标可在适用于 Valkey 的 ElastiCache 7.2 版或自主设计集群的更新版本中获得。这些指标每分钟为每个节点计算和发布一次。您可以使用各种 CloudWatch 统计数据聚合指定时间段内的指标数据点,例如平均值、总和、最小值、最大值、样本数以及介于 p0 和 p100 之间的任何百分位数。样本数仅包括由 ElastiCache 服务器成功执行的命令。此外,该ErrorCount指标是未能执行的命令的总数。
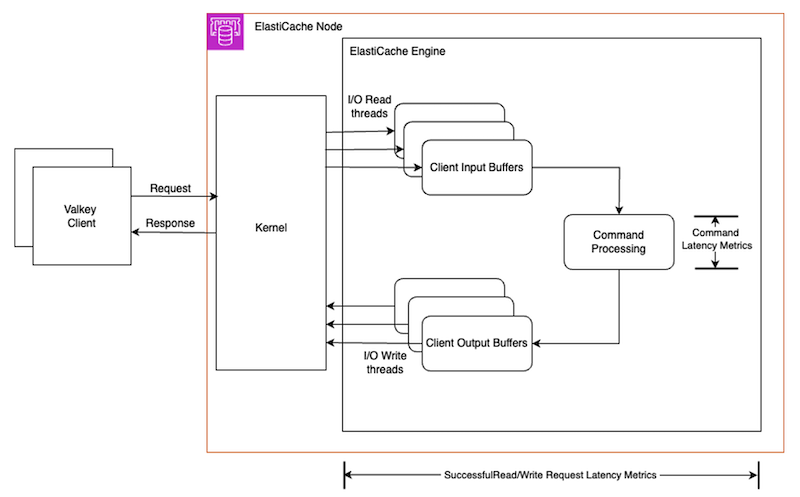
SuccessfulReadRequestLatency和SuccessfulWriteRequestLatency指标衡量命令处理各个阶段的延迟,包括适用于 Valkey 的 ElastiCache 引擎中的预处理、命令执行和后处理阶段。ElastiCache 引擎使用增强型 I/O 线程来处理来自并发客户端连接的网络 I/O。然后将这些命令排成队列,由主线程按顺序执行。响应通过 I/O 写入线程发送回客户端,如下图所示。请求延迟指标记录了在这些不同阶段完全处理请求所花费的时间。现有的特定命令延迟指标,例如GetTypeCmdsLatency和SetTypeCmdsLatency仅衡量执行核心命令逻辑所花费的 CPU 时间。
在使用 ElastiCache 集群对应用程序的性能问题进行故障排除时,SuccessfulReadRequestLatency和SuccessfulWriteRequestLatency指标非常有用。在本节中,我们将举例说明如何使用这些指标。
假设您在使用 ElastiCache 集群将数据写入应用程序时观察到较高的写入延迟。我们建议检查该SuccessfulWriteRequestLatency指标,该指标提供了在 1 分钟的时间间隔内处理所有成功执行的写入请求所花费的时间。如果您观察到客户端延迟增加,但SuccessfulWriteRequestLatency指标没有相应增加,那么这很好地表明 Valkey 引擎的 ElastiCache 不太可能成为高延迟的主要原因。在这种情况下,检查内存、CPU 和网络利用率等客户端资源以诊断原因。如果SuccessfulWriteRequestLatency指标的值有所增加,那么我们建议按照下一节中的步骤对问题进行故障排除。
对于大多数用例,我们建议您监控SuccessfulReadRequestLatency和SuccessfulWriteRequestLatency指标的 p50 统计信息。如果您的应用程序对尾部延迟敏感,我们建议您监控 p99 或 p99.99 统计信息。
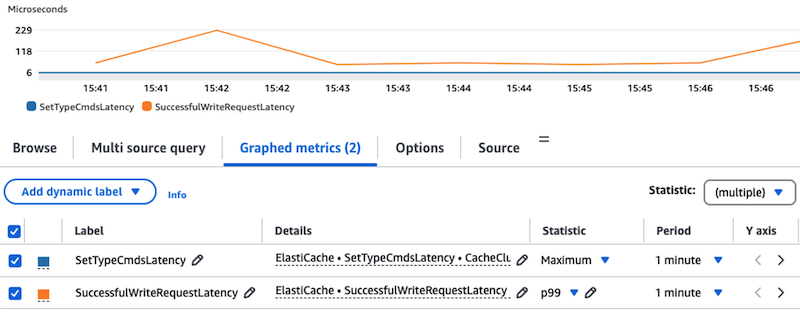
以下屏幕截图显示了 1 分钟时间段内 ElastiCache for Valkey 集群的最大SuccessfulWriteRequestLatency指标统计数据和 p99 以微秒为单位的指标统计数据的比较。SetTypeCmdsLatency我们注意到,在世界标准时间 15:41 到 15:43 之间,执行大量写入请求所花费的时间会增加,因为这些请求排队等待主线程按顺序执行,而执行SetTypeCmdsLatency指标所代表的命令所花费的 CPU 时间保持稳定。
解决 ElastiCache 中的高延迟
要解决您为 Valkey 集群自行设计(基于节点)的 ElastiCache 中的高读/写延迟问题,请检查集群的以下方面。
长时间运行的命令
适用于 Valkey 引擎的开源 Valkey 和 ElastiCache 在单个线程中运行命令。如果您的应用程序在大型数据结构(例如HGETALL或SUNION)上运行昂贵的命令,则这些命令的执行速度缓慢可能会导致来自其他客户端的后续请求需要等待,从而增加应用程序延迟。
现有的特定命令延迟指标(例如GetTypeCmdsLatency和SetTypeCmdsLatency)仅衡量执行核心命令逻辑所花费的 CPU 时间,并不反映命令等待优先排序的持续时间。但是,SuccessfulWriteRequestLatency和SuccessfulReadRequestLatency指标包括服务器端的整体延迟,包括从套接字读取所需的时间、排队时间、命令处理以及写回套接字所花费的时间。如果其 p99/p100 统计值很高(可能相对于GetTypeCmdsLatency或SetTypeCmdsLatency),您可以使用 Valkey SLOWLOG 命令或调查流式传输到 ElastiCache 日志传输目标的集群的统计值,以帮助确定哪些命令需要更长的时间才能完成。Valkey SLOWLOG 包含有关超过指定运行时间的查询的详细信息,该运行时仅包括命令处理时间。如果SLOWLOG中没有异常,则表示服务器端延迟出现峰值,这是由于命令处理延迟之外的因素造成的。
排队时间
适用于 Valkey 的 ElastiCache 积极管理客户流量,以保持优秀性能和复制可靠性。当发送到节点的命令多于 ElastiCache 引擎可以处理的命令时,高流量就会受到限制,流量管理活动指标也表明了这一点。如果该TrafficManagementActive指标保持活跃状态且延迟指标在很长一段时间内保持较高水平,则评估集群以确定是否需要向上扩展或向外扩展。有时,暂时的流量突增也可能导致排队时间过长,从而导致尾部延迟过长。
内存利用率
在内存压力下,适用于 Valkey 的 ElastiCache 节点使用的内存可能超过可用实例内存。在这种情况下,Valkey 会将数据从内存交换到磁盘,为传入的写入操作腾出空间。要确定节点是否承受内存压力,请查看该FreeableMemory指标是低还是SwapUsage大于FreeableMemory。节点上的高交换活动会导致较高的请求延迟。如果节点由于内存压力而进行交换,则向上扩展到更大的节点类型或通过添加分片进行横向扩展。您还应确保集群上有足够的内存来应对流量突增。
数据分层
适用于 Valkey 的 ElastiCache 将数据分层作为性价比选项提供,适用于数据在内存和本地固态硬盘之间进行分层的 Valkey 工作负载。数据分层非常适合定期访问其总数据集的 20% 的工作负载,以及在访问固态硬盘数据时可以容忍额外延迟的应用程序。
指标BytesReadFromDisk和BytesWrittenToDisk表示从 SSD 层读取和写入的数据量,可以与SuccessfulWriteRequestLatency和SuccessfulReadRequestLatency指标结合使用,以确定与分层操作相关的吞吐量。例如,如果SuccessfulReadRequestLatency和BytesReadFromDisk指标的值很高,则可能表明访问固态硬盘的频率更高,您可以向上扩展到更大的节点类型,也可以通过添加分片来向外扩展,以便有更多的 RAM 可用于为您的活动数据集提供服务。
Valkey 的水平缩放
通过对 ElastiCache 使用在线重新分片和分片再平衡,您可以在不停机的情况下动态扩展集群。这意味着,即使在扩展或再平衡过程中,您的集群也可以继续为请求提供服务。如果您的集群容量接近其容量,则会限制客户端写入请求以允许扩展操作继续进行,这会增加请求处理时间。这种延迟也反映在新的指标中。建议遵循在线集群大小调整的优秀实践,例如在非高峰时段启动重新分片,并避免在扩展期间使用昂贵的命令。
客户机连接数量增加
适用于 Valkey 的 ElastiCache 节点可以支持多达 65,000 个客户端连接。大量并发连接会显著增加 CPU 使用率,从而导致较高的应用程序延迟。为了减少这种开销,我们建议遵循优秀实践,例如使用连接池或重复使用现有的 Valkey 连接。
结论
根据所需的粒度级别,可以通过多种方式测量适用于 Valkey 的 ElastiCache 实例的延迟。从客户端监控端到端延迟有助于识别数据路径中的问题,而请求延迟指标则捕获命令处理的各个阶段(包括命令预处理、命令执行和命令后处理)所花费的时间。
新的请求延迟指标可以更精确地衡量适用于 Valkey 引擎的 ElastiCache 响应请求所花费的时间。在这篇文章中,我们讨论了一些场景,在这些场景中,这些延迟指标可以帮助解决您的 ElastiCache 集群中的延迟峰值。使用这篇文章中的详细信息,您可以检测、诊断和维护 Valkey 集群的 ElastiCache 的运行状况。在我们的文档中详细了解本文中讨论的指标。
作者简介
 Yasha Jayaprakash 是亚马逊云科技的软件开发经理,在领导开发团队提供高质量、可扩展的软件解决方案方面有着深厚的背景。她专注于协调技术战略与创新,致力于提供有影响力的、以客户为中心的解决方案。
Yasha Jayaprakash 是亚马逊云科技的软件开发经理,在领导开发团队提供高质量、可扩展的软件解决方案方面有着深厚的背景。她专注于协调技术战略与创新,致力于提供有影响力的、以客户为中心的解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。