由于全球变暖,地球不断变化的气候增加了发生干旱的风险。自1880年以来,全球气温上升了1.01°C。自1993年以来,海平面上升了102.5毫米。自2002年以来,南极洲的陆地冰盖以每年1510亿公吨的速度消失。2022年,地球大气中的二氧化碳含量超过百万分之400,比1750年增加了50%。尽管这些数字似乎与我们的日常生活相去甚远,但在过去的一万年中,地球一直在以前所未有的速度变暖 [1]。
在这篇文章中,我们使用亚马逊 SageMaker 中的新地理空间功能来监测米德湖气候变化造成的干旱。米德湖是美国最大的水库。它为内华达州、亚利桑那州和加利福尼亚州的2500万人提供水 [2]。研究表明,米德湖的水位处于1937年以来的最低水平 [3]。我们使用SageMaker中的地理空间功能通过卫星图像来测量米德湖水位的变化。
数据存取
SageMaker 中的新地理空间功能可轻松访问地理空间数据,例如 Sentinel-2 和 Landsat 8。内置的地理空间数据集访问功能可节省从各种数据提供商和供应商收集数据所浪费的数周精力。
首先,我们将按照亚马逊 SageMaker 地理空间功能入
门中概述的步骤使用带有 SageMaker 地理空间图像的亚马逊 SageMaker Studio 笔记本电脑。
我们使用带有 SageMaker 地理空间图像的 SageMaker Studio 笔记本进行分析。
这篇文章中使用的笔记本可以在
亚马逊 sagemaker 示例 GitHub 存储库
中找到。SageMaker 地理空间使数据查询变得非常简单。我们将使用以下代码来指定卫星数据的位置和时间范围。
在下面的代码片段中,我们首先定义了一个围绕米
德湖区域的边界框的 AreaoFinterest
(AOI)。我们使用
时间范围过滤器来选择 202
1 年 1 月 至 2022 年 7 月的数据。但是,我们正在研究的区域可能会被云层遮住。为了获得大部分无云图像,我们通过将云覆盖率的上限设置为 1% 来选择图像子集。
import boto3
import sagemaker
import sagemaker_geospatial_map
session = boto3.Session()
execution_role = sagemaker.get_execution_role()
sg_client = session.client(service_name="sagemaker-geospatial")
search_rdc_args = {
"Arn": "arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8", # sentinel-2 L2A COG
"RasterDataCollectionQuery": {
"AreaOfInterest": {
"AreaOfInterestGeometry": {
"PolygonGeometry": {
"Coordinates": [
[
[-114.529, 36.142],
[-114.373, 36.142],
[-114.373, 36.411],
[-114.529, 36.411],
[-114.529, 36.142],
]
]
}
} # data location
},
"TimeRangeFilter": {
"StartTime": "2021-01-01T00:00:00Z",
"EndTime": "2022-07-10T23:59:59Z",
}, # timeframe
"PropertyFilters": {
"Properties": [{"Property": {"EoCloudCover": {"LowerBound": 0, "UpperBound": 1}}}],
"LogicalOperator": "AND",
},
"BandFilter": ["visual"],
},
}
tci_urls = []
data_manifests = []
while search_rdc_args.get("NextToken", True):
search_result = sg_client.search_raster_data_collection(**search_rdc_args)
if search_result.get("NextToken"):
data_manifests.append(search_result)
for item in search_result["Items"]:
tci_url = item["Assets"]["visual"]["Href"]
print(tci_url)
tci_urls.append(tci_url)
search_rdc_args["NextToken"] = search_result.get("NextToken")
模型推断
在我们识别出数据之后,下一步是从卫星图像中提取水体。通常,我们需要从头开始训练土地覆盖分割模型,以识别地球表面不同类别的物理物质,例如水体、植被、雪等。从头开始训练模型既耗时又昂贵。它涉及数据标签、模型训练和部署。SageMaker 地理空间功能提供了预先训练的土地覆盖分割模型。这个土地覆盖分割模型可以通过简单的 API 调用来运行。
SageMaker 不会将数据下载到本地计算机进行推断,而是为您完成所有繁重的工作。我们只需在地球观测作业(EOJ)中指定数据配置和模型配置即可。SageMaker 会自动下载并预处理 EOJ 的卫星图像数据,使其做好推断准备。接下来,SageMaker 会自动为 EOJ 运行模型推断。根据工作负载(通过模型推断运行的图像数量),EOJ 可能需要几分钟到几小时才能完成。你可以使用
get_earth_observation_
job 函数监控作业状态。
# Perform land cover segmentation on images returned from the sentinel dataset.
eoj_input_config = {
"RasterDataCollectionQuery": {
"RasterDataCollectionArn": "arn:aws:sagemaker-geospatial:us-west-2:378778860802:raster-data-collection/public/nmqj48dcu3g7ayw8",
"AreaOfInterest": {
"AreaOfInterestGeometry": {
"PolygonGeometry": {
"Coordinates": [
[
[-114.529, 36.142],
[-114.373, 36.142],
[-114.373, 36.411],
[-114.529, 36.411],
[-114.529, 36.142],
]
]
}
}
},
"TimeRangeFilter": {
"StartTime": "2021-01-01T00:00:00Z",
"EndTime": "2022-07-10T23:59:59Z",
},
"PropertyFilters": {
"Properties": [{"Property": {"EoCloudCover": {"LowerBound": 0, "UpperBound": 1}}}],
"LogicalOperator": "AND",
},
}
}
eoj_config = {"LandCoverSegmentationConfig": {}}
response = sg_client.start_earth_observation_job(
Name="lake-mead-landcover",
InputConfig=eoj_input_config,
JobConfig=eoj_config,
ExecutionRoleArn=execution_role,
)
# Monitor the EOJ status.
eoj_arn = response["Arn"]
job_details = sg_client.get_earth_observation_job(Arn=eoj_arn)
{k: v for k, v in job_details.items() if k in ["Arn", "Status", "DurationInSeconds"]}
可视化结果
现在我们已经进行了模型推断,让我们目视检查结果。我们将模型推断结果叠加在输入的卫星图像上。我们使用预先与 SageMaker 集成的 Foursquare Studio 工具来可视化这些结果。首先,我们使用 SageMaker 地理空间功能创建地图实例,以可视化输入图像和模型预测:
# Creates an instance of the map to add EOJ input/ouput layer.
map = sagemaker_geospatial_map.create_map({"is_raster": True})
map.set_sagemaker_geospatial_client(sg_client)
# Render the map.
map.render()
交互式地图准备就绪后,我们可以将输入图像和模型输出渲染为地图层,而无需下载数据。此外,我们可以给每个图层一个标签,并使用
timeRangeFilter
选择特定日期的数据:
# Visualize AOI
config = {"label": "Lake Mead AOI"}
aoi_layer = map.visualize_eoj_aoi(Arn=eoj_arn, config=config)
# Visualize input.
time_range_filter = {
"start_date": "2022-07-01T00:00:00Z",
"end_date": "2022-07-10T23:59:59Z",
}
config = {"label": "Input"}
input_layer = map.visualize_eoj_input(
Arn=eoj_arn, config=config, time_range_filter=time_range_filter
)
# Visualize output, EOJ needs to be in completed status.
time_range_filter = {
"start_date": "2022-07-01T00:00:00Z",
"end_date": "2022-07-10T23:59:59Z",
}
config = {"preset": "singleBand", "band_name": "mask"}
output_layer = map.visualize_eoj_output(
Arn=eoj_arn, config=config, time_range_filter=time_range_filter
)
我们可以通过更改输出图层的不透明度来验证标记为水的区域(下图中的亮黄色)是否与米德湖中的水体准确对应。
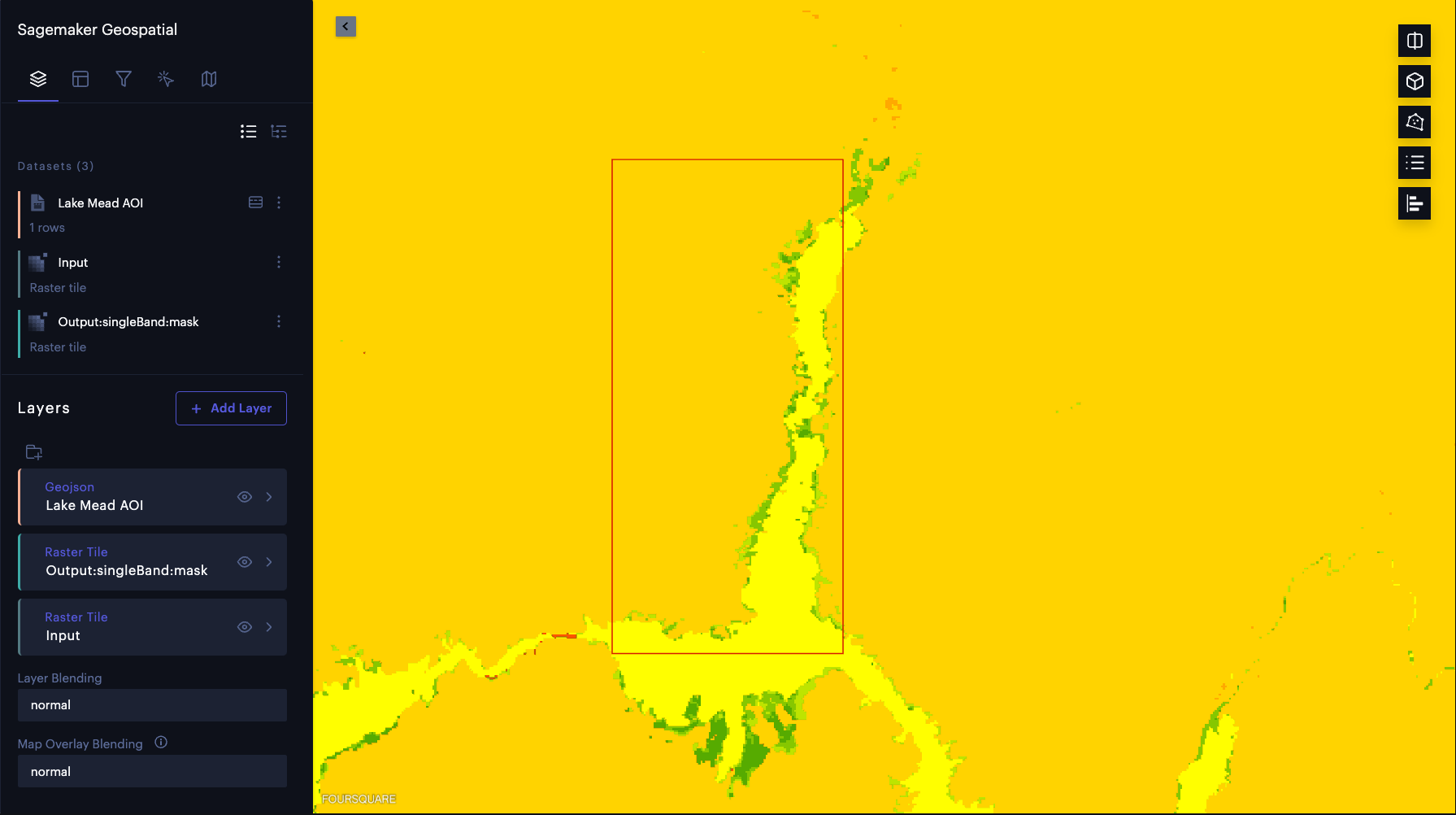
帖子分析
接下来,我们使用
export_earth_observation_job 函数将
EOJ 结果导出到亚马逊简单存储服务(亚马逊 S3)存储桶。然后,我们对 Amazon S3 中的数据进行后续分析,以计算水面积。导出功能可以方便地在团队之间共享结果。SageMaker 还简化了数据集管理。我们可以简单地使用作业 ARN 共享 EOJ 结果,而不必在 S3 存储桶中搜寻数千个文件。每个 EOJ 都将成为数据目录中的资产,因为结果可以按作业 ARN 分组。
sagemaker_session = sagemaker.Session()
s3_bucket_name = sagemaker_session.default_bucket() # Replace with your own bucket if needed
s3_bucket = session.resource("s3").Bucket(s3_bucket_name)
prefix = "eoj_lakemead" # Replace with the S3 prefix desired
export_bucket_and_key = f"s3://{s3_bucket_name}/{prefix}/"
eoj_output_config = {"S3Data": {"S3Uri": export_bucket_and_key}}
export_response = sg_client.export_earth_observation_job(
Arn=eoj_arn,
ExecutionRoleArn=execution_role,
OutputConfig=eoj_output_config,
ExportSourceImages=False,
)
接下来,我们分析米德湖水位的变化。我们将土地覆盖掩码下载到本地实例,以使用开源库计算水面积。SageMaker 以云端优化的 GeoTIFF (COG) 格式保存模型输出。在此示例中,我们使用 Tiffile 包将这些掩码作为 NumPy 数组加载。SageMaker
Geospatial 1.0
内核还包括其他广泛使用的库,例如 GDAL 和 Rasterio。
土地覆盖掩码中的每个像素的值介于 0-11 之间。每个值对应于一类特定的土地覆被。Water 的等级索引为 6。我们可以使用这个类索引来提取水面罩。首先,我们计算标记为水的像素数量。接下来,我们将该数字乘以每个像素覆盖的面积,得出水的表面积。
根据波段的不同,Sentinel-2 L2A 图像的空间分辨率为 10
m 、20 m
或 60
m
。
将所有波段缩减采样至 60 米的空间分辨率,用于土地覆被分割模型推断。
因此,土地覆盖掩膜中的每个像素代表的地面面积为 3600
m
2
,即 0.0036 km 2。
import os
from glob import glob
import cv2
import numpy as np
import tifffile
import matplotlib.pyplot as plt
from urllib.parse import urlparse
from botocore import UNSIGNED
from botocore.config import Config
# Download land cover masks
mask_dir = "./masks/lake_mead"
os.makedirs(mask_dir, exist_ok=True)
image_paths = []
for s3_object in s3_bucket.objects.filter(Prefix=prefix).all():
path, filename = os.path.split(s3_object.key)
if "output" in path:
mask_name = mask_dir + "/" + filename
s3_bucket.download_file(s3_object.key, mask_name)
print("Downloaded mask: " + mask_name)
# Download source images for visualization
for tci_url in tci_urls:
url_parts = urlparse(tci_url)
img_id = url_parts.path.split("/")[-2]
tci_download_path = image_dir + "/" + img_id + "_TCI.tif"
cogs_bucket = session.resource(
"s3", config=Config(signature_version=UNSIGNED, region_name="us-west-2")
).Bucket(url_parts.hostname.split(".")[0])
cogs_bucket.download_file(url_parts.path[1:], tci_download_path)
print("Downloaded image: " + img_id)
print("Downloads complete.")
image_files = glob("images/lake_mead/*.tif")
mask_files = glob("masks/lake_mead/*.tif")
image_files.sort(key=lambda x: x.split("SQA_")[1])
mask_files.sort(key=lambda x: x.split("SQA_")[1])
overlay_dir = "./masks/lake_mead_overlay"
os.makedirs(overlay_dir, exist_ok=True)
lake_areas = []
mask_dates = []
for image_file, mask_file in zip(image_files, mask_files):
image_id = image_file.split("/")[-1].split("_TCI")[0]
mask_id = mask_file.split("/")[-1].split(".tif")[0]
mask_date = mask_id.split("_")[2]
mask_dates.append(mask_date)
assert image_id == mask_id
image = tifffile.imread(image_file)
image_ds = cv2.resize(image, (1830, 1830), interpolation=cv2.INTER_LINEAR)
mask = tifffile.imread(mask_file)
water_mask = np.isin(mask, [6]).astype(np.uint8) # water has a class index 6
lake_mask = water_mask[1000:, :1100]
lake_area = lake_mask.sum() * 60 * 60 / (1000 * 1000) # calculate the surface area
lake_areas.append(lake_area)
contour, _ = cv2.findContours(water_mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
combined = cv2.drawContours(image_ds, contour, -1, (255, 0, 0), 4)
lake_crop = combined[1000:, :1100]
cv2.putText(lake_crop, f"{mask_date}", (10,50), cv2.FONT_HERSHEY_SIMPLEX, 1.5, (0, 0, 0), 3, cv2.LINE_AA)
cv2.putText(lake_crop, f"{lake_area} [sq km]", (10,100), cv2.FONT_HERSHEY_SIMPLEX, 1.5, (0, 0, 0), 3, cv2.LINE_AA)
overlay_file = overlay_dir + '/' + mask_date + '.png'
cv2.imwrite(overlay_file, cv2.cvtColor(lake_crop, cv2.COLOR_RGB2BGR))
# Plot water surface area vs. time.
plt.figure(figsize=(20,10))
plt.title('Lake Mead surface area for the 2021.02 - 2022.07 period.', fontsize=20)
plt.xticks(rotation=45)
plt.ylabel('Water surface area [sq km]', fontsize=14)
plt.plot(mask_dates, lake_areas, marker='o')
plt.grid('on')
plt.ylim(240, 320)
for i, v in enumerate(lake_areas):
plt.text(i, v+2, "%d" %v, ha='center')
plt.show()
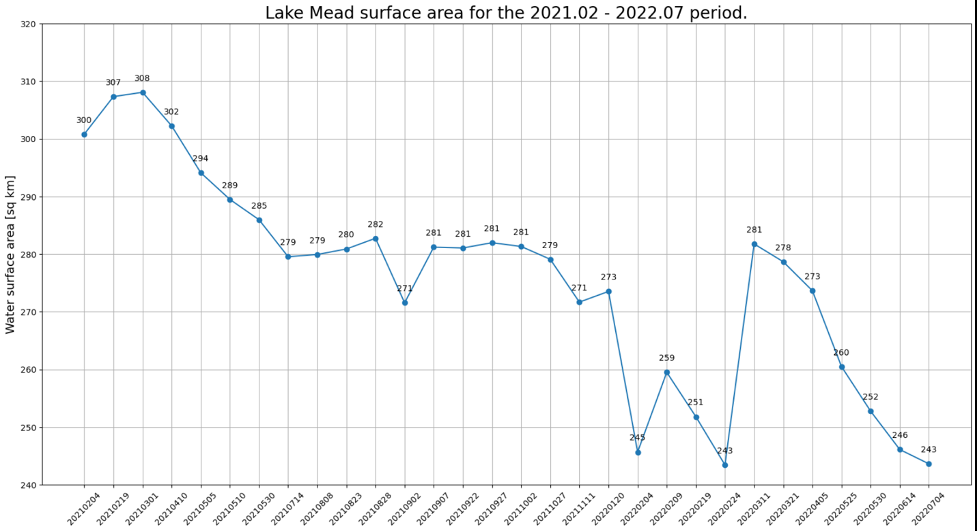
我们在下图中绘制了随时间推移的水面积。在2021年2月至2022年7月之间,水面面积明显减少。
在不到2年的时间里,米德湖的表面积从超过300
千
米
2
减少 到不到250平方
千米
,相对变化为18%。
import imageio.v2 as imageio
from IPython.display import HTML
frames = []
filenames = glob('./masks/lake_mead_overlay/*.png')
filenames.sort()
for filename in filenames:
frames.append(imageio.imread(filename))
imageio.mimsave('lake_mead.gif', frames, duration=1)
HTML('<img src="./lake_mead.gif">')
我们还可以提取湖泊的边界并将其叠加在卫星图像上,以更好地可视化湖泊海岸线的变化。如以下动画所示,在过去的两年中,北部和东南部的海岸线已经缩小。在某些月份中,表面积同比减少了20%以上。
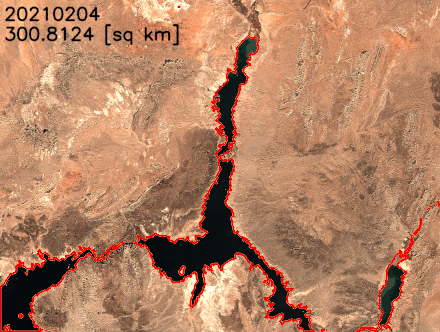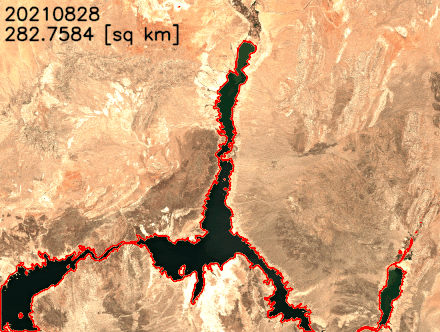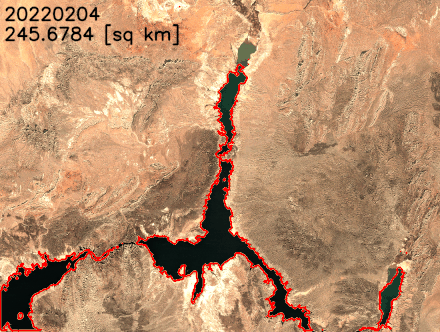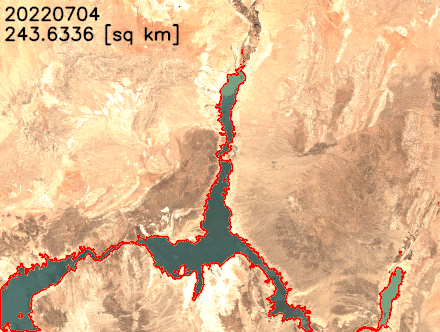
结论
我们已经目睹了气候变化对米德湖海岸线缩小的影响。SageMaker 现在支持地理空间机器学习 (ML),使数据科学家和机器学习工程师能够更轻松地使用地理空间数据构建、训练和部署模型。在这篇文章中,我们展示了如何使用 SageMaker 地理空间 AI/ML 服务采集数据、进行分析和可视化变化。你可以在
亚马逊 sagemaker 示例 GitHub 存储库
中找到这篇文章的代码。查看
亚马逊 SageMaker 地理空间
功能以了解详情。
参考文献
[1]
https://climate.nasa.gov/
[2]
https://www.nps.gov/lake/learn/nature/overview-of-lake-mead.htm
[3]
https://earthobservatory.nasa.gov/images/150111/lake-mead-keeps-dropping
作者简介
周雄
是 亚马逊云科技 的高级应用科学家。他领导亚马逊 SageMaker 地理空间能力的科学小组。他目前的研究领域包括计算机视觉和高效模型训练。在业余时间,他喜欢跑步、打篮球和与家人共度时光。
Anirudh Viswanathan
是 SageMaker 地理空间机器学习团队技术外部服务高级产品经理。他拥有卡内基梅隆大学机器人学硕士学位和沃顿商学院工商管理硕士学位,并被任命为40多项专利的发明人。他喜欢长跑、参观美术馆和百老汇演出。
特伦顿·利普斯科姆
是首席工程师,也是为SageMaker添加地理空间功能的团队的一员。他曾参与人体循环解决方案,负责SageMaker Ground Truth、增强人工智能和亚马逊 Mechanical Turk 等服务。
施行健
是一位资深应用科学家,也是为 SageMaker 添加地理空间功能的团队的一员。他还在研究地球科学和多模态AutoML的深度学习。
李二然 是亚马
逊 亚马逊云科技 AI 人类在环服务的应用科学经理。他的研究兴趣是三维深度学习以及视觉和语言表现学习。此前,他是 Alexa AI 的资深科学家、Scale AI 的机器学习负责人和 Pony.ai 的首席科学家。在此之前,他曾在Uber ATG的感知团队和优步的机器学习平台团队工作,致力于自动驾驶、机器学习系统和人工智能战略计划的机器学习。他的职业生涯始于贝尔实验室,曾是哥伦比亚大学的兼职教授。他在ICML'17和ICCV'19上共同教授教程,并在Neurips、ICML、CVPR、ICCV共同组织了多个研讨会,内容涉及自动驾驶的机器学习、三维视觉和机器人、机器学习系统和对抗性机器学习。他在康奈尔大学拥有计算机科学博士学位。他是 ACM 研究员和 IEEE 研究员。