我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 CloudWatch 异常检测警报监控负载均衡器
负载均衡器是分布式软件服务架构中的关键组件。
由于在服务堆栈中处于较高水平,负载均衡器发出的指标为服务运行状况、服务性能和端到端网络性能提供了关键而独特的见解。监控这些指标可以让人们了解服务堆栈和网络中的多种事件。这种可见性可以快速发现和缓解事故,而不是长时间停机。
这篇文章首先简要概述了
tcp_target_reset_Count
, 以及为什么不能使用使用静态阈值的传统
然后简要介绍了 CloudWatch 异常检测警报,然后深入探讨如何将其用于监控 TCP_Target_Reset_Count。
最后,我们重点介绍了这种监测可能有用的某些情况。
NLB TCP 重置计数指标
目标或客户端 的
TCP 重置标志
TCP 连接中的每个数据包都包含一个 TCP 标头。每个标头都包含一个名为 “重置” (RST) 标志。将此位设置为 0 没有任何效果,但是将其设置为 1 会向接收方表明不应再使用给定的 TCP 连接。重置会立即关闭 TCP 连接。
tcp_target_reset_Count、tcp_client_reset_Count 和 tcp_elb_reset_Count
TCP_target_reset_Count 是 CloudWatch 中发布
的 ELB 指标。这将监控从目标(Amazon EC2 主机)发送到客户端的重置 (RST) 数据包总数。重置数据包是没有负载且在 TCP 标头标志中设置 了
RST
位的数据包。这些重置由
目标 生成 并由
负载均衡器转发。
总
和 是该指标最有用的统计数据。
同样,NLB 还会发布与负载均衡器本身生成的重置(
tcp_elb_reset_Count)和客户端(tcp_client_reset_Count)生成的重置
相对应的指标。
对于由 NLB 和底层计算(例如 Amazon EC2 主机)组成的通用系统,TCP 连接是短暂的(由生存时间 (TTL) 配置表示)。因此,由于 TCP 连接持续打开和关闭,这些重置指标的基准值预计将大于 1(在给定时间段内)。
当目标、客户端或负载均衡器关闭的连接数超过平时时,这些重置指标可能会达到峰值。可能发生这种情况的某些情况:
-
“客户端 → NLB → 目标” 通信中断或延迟
例如,网络问题导致目标、NLB 或客户端无法成功地相互通信。这将导致重置指标的下降,持续到潜在问题的持续时间。这种情况表示服务出现全部或部分中断(例如客户端 4xx 错误激增),应采取相应的警报和缓解措施。 -
在底层目标上部署代码
这会导致重置指标激增,因为目标将在关闭应用程序并开始部署之前发送重置数据包。这是预期的行为,不是问题。
监控 TCP 重置计数指标
如前所述,NLB 重置计数指标可以突出客户端 → NLB → 目标通信中的关键问题。这可能会导致错误增加和不利的客户体验。对这些 NLB 重置计数指标进行准确警报可以通知服务所有者并使他们能够激活缓解策略。
静态阈值警报
传统的
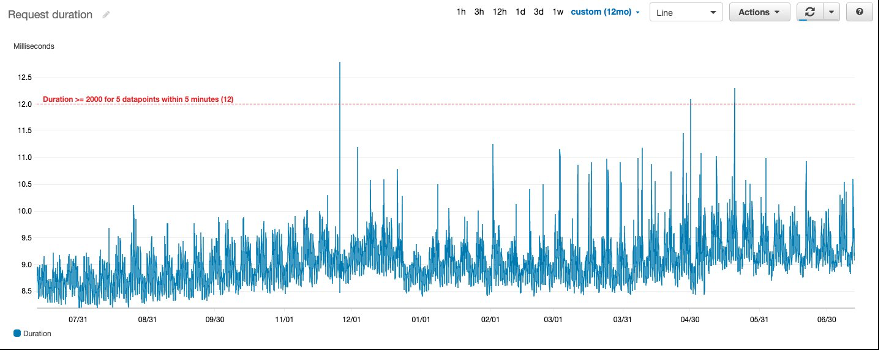
图 1。请求持续时间的静态阈值警报
对于 静态 阈值不能代表系统正常运行条件的指标,这种警报策略将失败。如果指标 的安全值 (表示正常运行条件)经常变化,就会出现这种情况。例如,阈值取决于每日流量模式或自动扩展服务队列的规模。
重置计数指标(
tcp_target_reset_C
ount)属于此类别。根据定义,该指标的阈值取决于基础机群中的主机数量(以及其他因素)。
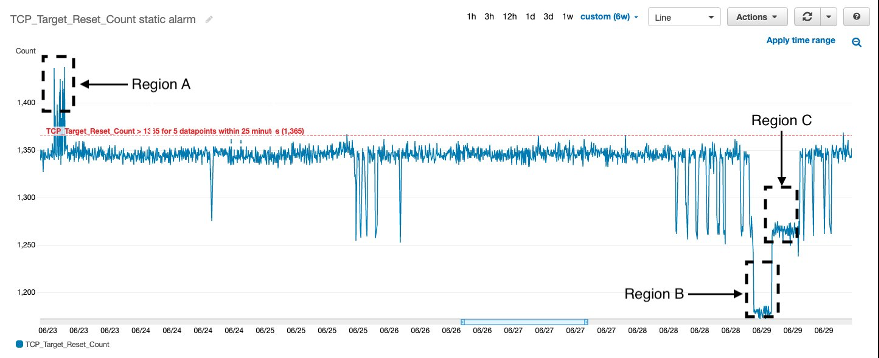
图 2。静态阈值警报和
T
CP_target_Reset_Count
例如,在上图中,显示了连续六天
TCP_Target_Reset_
Count 的 CloudWatch 快照。
区域 A
和
区域 B
表示系统存在异常(RST 计数不规则的峰值或下降),而 区域 C 处于健康状态。
警报阈值 1365 足以检测 区域 A 中的峰值 ,但该值无法捕捉 区域 B 中显示的下限。一种可能的解决方案是创建另一个单独的警报,该警报在阈值降至新的较低阈值1200时触发。但是,这两个警报都是静态的,无法适应影响因素(例如主机数量)的变化。
前面的示例是一个小快照(六天),在较长的时间段(月)内,该指标可能会有更多的变化。因此,TCP 重置指标无法通过静态阈值进行监控 。
CloudWatch 异常检测警报
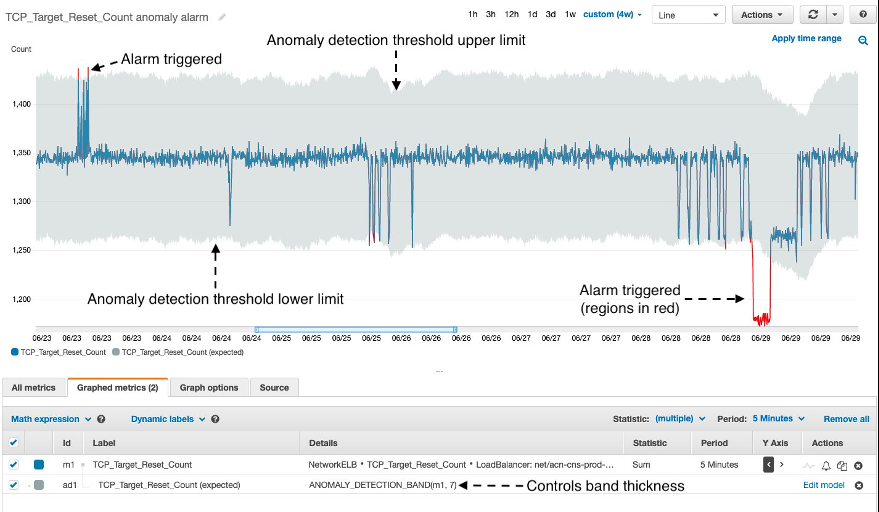
图 3。
异常检测警报和 TCP_target_Reset_Count
在上图中,CloudWatch 异常检测警报用于监控 TCP_Target_Reset_Count。
异常检测动态阈值由灰色波段表示,灰色波段不断调整以适应指标趋势的变化。在更有趣的情况下,数字警报中表示的一些有趣的事情会被触发(红色):
- 当指标达到极端峰值和极低值时,会触发警报(红色),分别表示故障率上升(目标系统)或某种网络问题。
- 当指标开始快速下降或上升时,警报已经触发。这样可以更早地检测到事件,从而使服务所有者能够更早地触发缓解措施并缩短缓解时间。
- 阈值带的宽度可以由单个参数控制——值越大,波段越厚,而值越小,波段越薄。与较小的波段相比,较大的阈值波段灵敏度较低。
使用 亚马逊云科技 云开发套件为 TCP_Target_Reset_Count 创建异常检测警报
以下是以下实现中需要注意的一些事项:
- 这假设 NLB ARN 是从相应的堆栈中导出的,如果您要在用于创建警报的同一 亚马逊云科技 CDK 包中创建 NLB,则无需这样做。
-
异常检测模型 的
标准差设置为8。应根据警报所需的灵敏度进行调整。增加它会使异常检测波段变大,因此警报对Tcp_target_Reset_Count 指标的微小变化变得不那么敏感。
异常检测警报类别
import {CfnAlarm, CfnAnomalyDetector, Metric, TreatMissingData} from "@aws-cdk/aws-cloudwatch";
import {Construct, Duration} from "@aws-cdk/core";
export interface AnomalyDetectionAlarmProps {
readonly alarmName: string;
readonly alarmDescription: string;
readonly metric: Metric;
readonly comparisonOperator: string;
readonly evaluationPeriods: number;
readonly period: Duration;
readonly standardDeviation: number;
readonly alarmActions?: string[];
readonly modelConfiguration?: CfnAnomalyDetector.ConfigurationProperty;
}
export class AnomalyDetectionAlarm extends Construct {
constructor(scope: Construct, id: string, props: AnomalyDetectionAlarmProps) {
super(scope, id);
const metricName = props.metric.metricName || "";
const anomalyDetectorMetricId = `anomalyDetectorMetricId`;
const anomalyDetectorId = `anomalyDetectorId`;
const metricStats = props.metric.toMetricConfig().metricStat;
const namespace = metricStats?.namespace || "";
const stats = metricStats?.statistic || "";
const dimensions = metricStats?.dimensions || undefined;
const alarmActions = props?.alarmActions || [];
new CfnAnomalyDetector(this, anomalyDetectorId, {
configuration: props.modelConfiguration,
namespace,
metricName,
stat: stats,
dimensions,
});
return new CfnAlarm(this, props.alarmName, {
alarmName: props.alarmName,
alarmDescription: props.alarmDescription,
comparisonOperator: props.comparisonOperator,
evaluationPeriods: props.evaluationPeriods,
thresholdMetricId: anomalyDetectorMetricId,
treatMissingData: TreatMissingData.MISSING,
metrics: [
{
expression: `ANOMALY_DETECTION_BAND(m1, ${props.standardDeviation})`,
id: anomalyDetectorMetricId,
},
{
id: "m1",
metricStat: {
metric: {
namespace,
metricName,
dimensions,
},
period: props.period.toSeconds(),
stat: stats,
},
},
],
alarmActions,
});
}
}
实例化警报
private createNLBAnomalyDetectionAlarm(alarmName: string) {
const nlbName = loadBalancerNameFromListenerArn(Fn.importValue("ServiceLoadBalancer"));
const metricName = "TCP_Target_Reset_Count";
const metric = new Metric({
statistic: "Sum",
label: nlbName,
metricName,
namespace: "AWS/NetworkELB",
period: Duration.minutes(5),
dimensions: {
LoadBalancer: nlbName,
},
});
new AnomalyDetectionAlarm(this, `${metricName}_Alarm`, {
alarmName,
alarmDescription: "TCP_Target_Reset_Count below the anomaly detector threshold",
metric,
comparisonOperator: "LessThanLowerThreshold",
evaluationPeriods: 3,
period: Duration.minutes(5),
standardDeviation: 8,
});
}
结论
我们概述了
这些警报可以与传统的 NLB 警报(例如不健康的主机数量)一起使用。
参考文献
-
使用 亚马逊云科技 控制台创建异常检测警报 -
使用 亚马逊云科技 CLI 创建异常检测警报

Varun Jewalikar
Varun Jewalikar 是 Prime Video 的软件工程师。他热衷于大规模分布式系统、混沌工程和开源。你可以通过 https://www.linkedin.com/in/vjewalikar/ 联系他
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。