我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
OpenSearch 矢量引擎现已针对磁盘进行了优化,可实现低成本、准确的矢量搜索
OpenSearch 矢量引擎现在可以在 OpenSearch 2.17+ 域上以三分之一的成本运行矢量搜索。现在,您可以将 k-nn(矢量)索引配置为在磁盘模式下运行,针对内存受限的环境进行优化,并实现低成本、准确的矢量搜索,在数百毫秒内做出响应。当您不需要接近个位数的延迟时,磁盘模式是内存模式的一种经济的替代方案。
在这篇文章中,您将了解这项新功能的好处、底层机制、客户成功案例和入门。
矢量搜索和 OpenSearch 矢量引擎概述
矢量搜索是一种通过对已由机器学习 (ML) 模型编码为矢量(数字编码)的内容进行相似度匹配来提高搜索质量的技术。它支持语义搜索等用例,允许您考虑上下文和意图以及关键字,以提供更相关的搜索。
OpenSearch 矢量引擎通过为矢量化内容创建索引,支持超越数十亿个向量的实时矢量搜索。然后,您可以搜索索引中与给定查询向量最相似的前 K 个文档,这些向量可能是由同一 ML 模型编码的问题、关键字或内容(例如图像、音频片段或文本)。
调整 OpenSearch 矢量引擎
搜索应用程序在速度、质量和成本方面有不同的要求。例如,电子商务目录需要尽可能短的响应时间和高质量的搜索才能提供积极的购物体验。但是,为提高搜索质量和性能而进行优化通常会以增加内存和计算的形式产生成本。
速度、质量和成本的适当平衡取决于您的用例和客户的期望。OpenSearch 矢量引擎提供全面的调整选项,因此您可以做出明智的权衡,以获得根据您的独特要求量身定制的优秀结果。
您可以使用以下调整控件:
- 算法和参数 — 这包括以下内容:
- 分层可航行小世界 (HNSW) 算法和参数
ef_search,如、ef_construct和m - 反向文件索引 (IVF) 算法和参数,例如
nlist和nprobes - 精确 k 最近邻 (k-nn),也称为蛮力 k-nn (BFKNN) 算法
- 分层可航行小世界 (HNSW) 算法和参数
- 引擎 — Facebook 人工智能相似度搜索 (FAISS)、Lucene 和非度量空间库 (NMSLIB)。
- 压缩技术 — 标量(例如字节和半精度)、二进制和乘积量化
- 相似度(距离)指标 — 内积、余弦、L1、L2 和汉明
- 矢量嵌入类型 — 密集和稀疏且维度可变
- 排名和评分方法 — 矢量、混合(矢量和优秀匹配 25 (BM25) 分数的组合)和多阶段排名(例如交叉编码器和个性化工具)
您可以调整调整控件的组合,以实现速度、质量和成本的不同平衡,并根据您的需求进行优化。下图提供了示例配置的粗略性能分析。
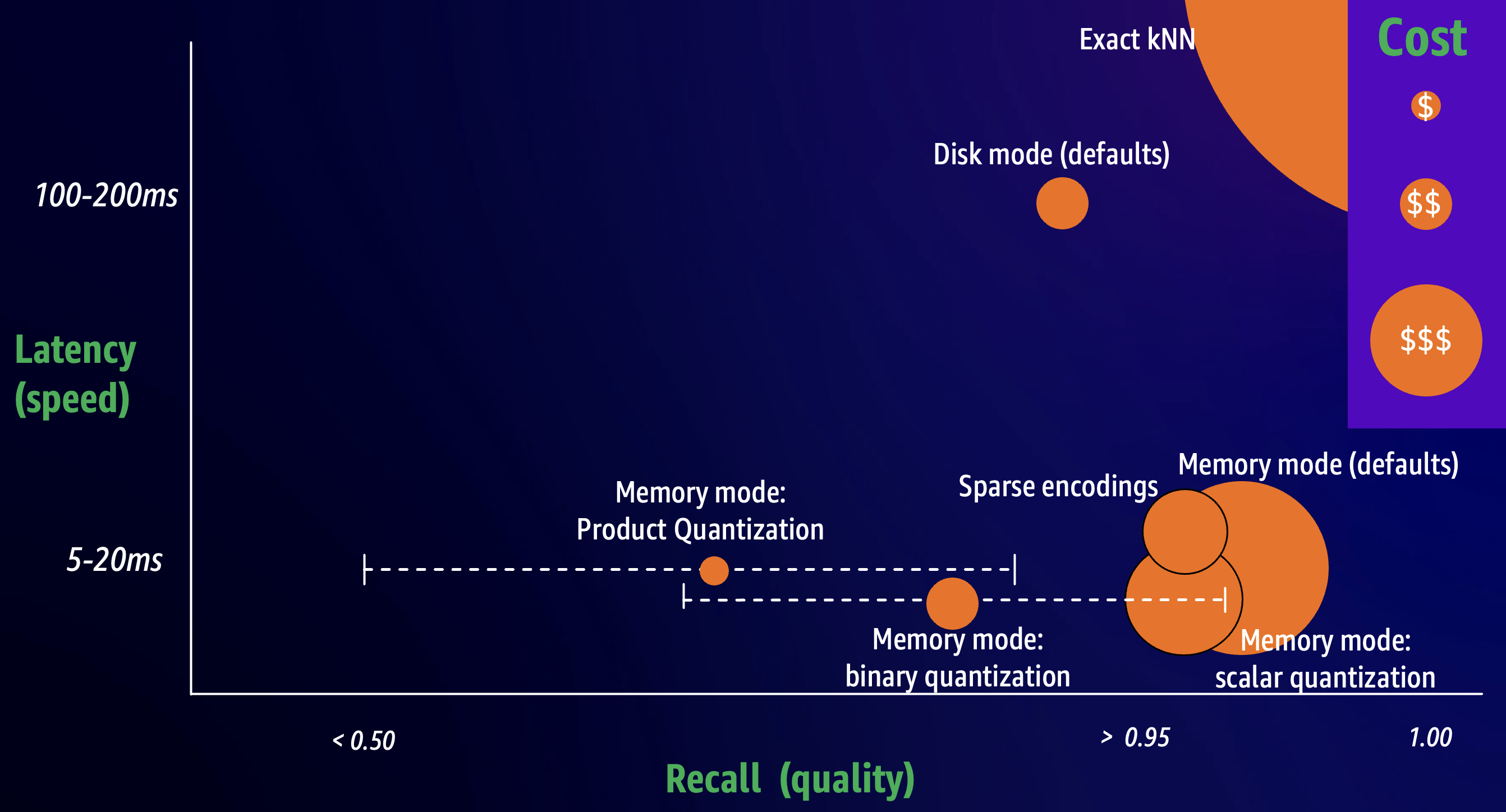
调整磁盘优化
在 OpenSearch 2.17+ 中,您可以通过用内存性能换取更高的延迟,将 k-nn 索引配置为在磁盘模式下运行,以实现高质量、低成本的矢量搜索。如果您的用例对 100 到 200 毫秒范围内的第 90 个百分位数 (P90) 延迟感到满意,那么磁盘模式是您在保持高搜索质量的同时节省成本的绝佳选择。下图说明了替代引擎配置中磁盘模式的性能概况。
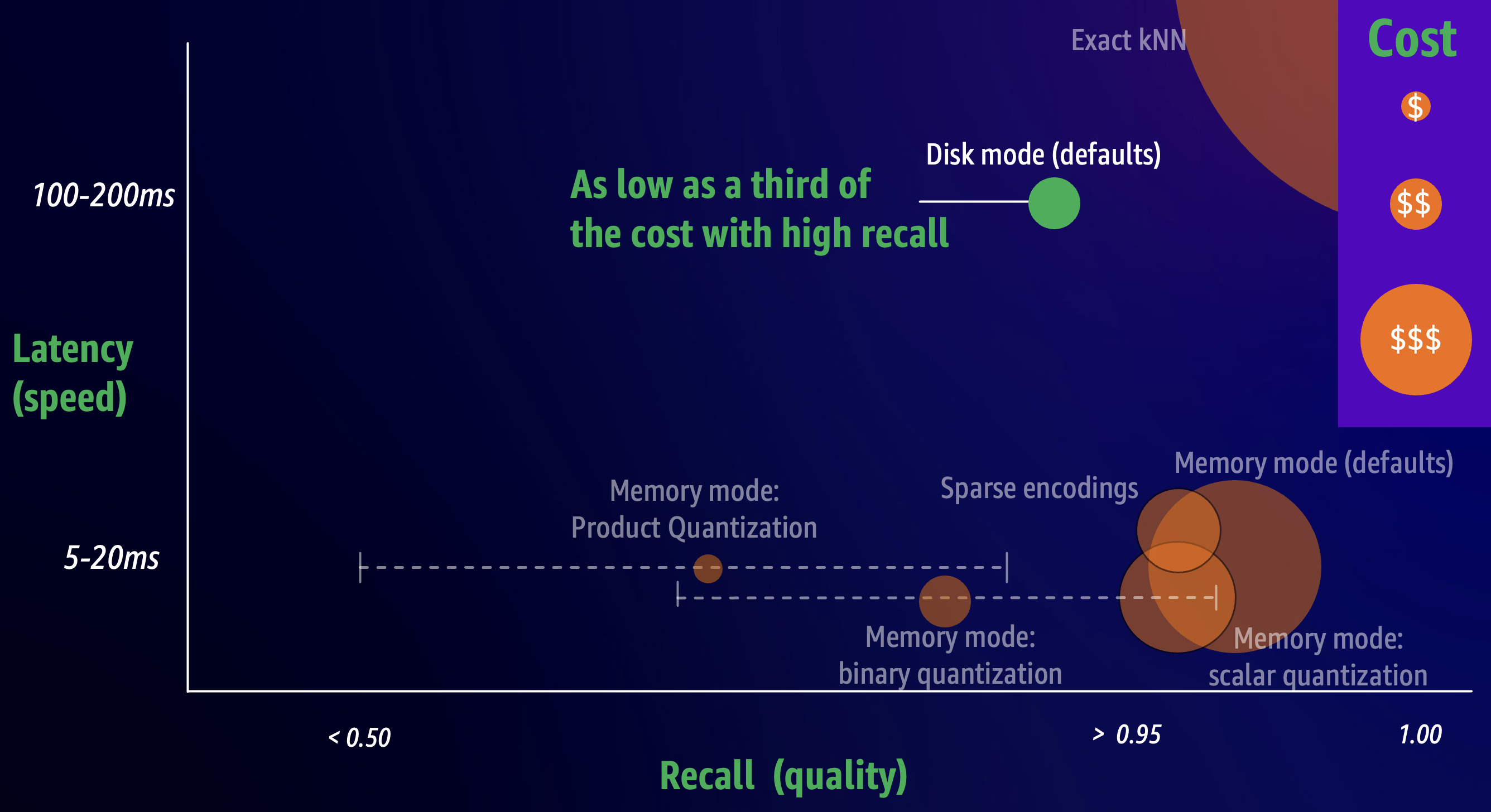
磁盘模式旨在开箱即用,与内存模式相比,您的内存需求减少了 97%,同时提供了很高的搜索质量。但是,您可以调整压缩率和采样率以调整速度、质量和成本。
下表显示了磁盘模式默认设置的性能基准。OpenSearch 基准测试(OSB)用于运行前三次测试,后两次使用 VectordBBench(VDBB)进行测试。应用了性能调整优秀实践来实现优秀结果。低规模测试(Tasb-1M 和 Marco-1M)是在具有一个副本的单个 r7gd.large 数据节点上运行的。其他测试是在两个带有一个副本的 r7gd.2xlarge 数据节点上运行的。成本削减百分比指标是通过将等效的、规模合适的内存部署与默认设置进行比较来计算的。
| 数据集 | 召回 @100(搜索质量) | p90 延迟 (ms) | 尺寸 | 向量数(百万) | 成本降低百分比 | 模型 | 来源 |
| Cohere TREC-RAG | 0.94 | 104 | 1024 | 113 | 67% | Cohere 嵌入 V3 | 预处理 |
| Tasb-1M | 0.96 | 7 | 768 | 1 | 83% | msmacro-distilbert-base-tas-b | 未处理 |
| Marco-1M | 0.99 | 7 | 768 | 1 | 67% | msmarco-distilbert | 未处理 |
| OpenAI 5M | 0.98 | 62 | 1536 | 5 | 67% | 文本嵌入-ada-002 | 生成的 |
| 莱昂 100M | 0.93 | 169 | 768 | 100 | 67% | 夹 | 生成的 |
这些测试旨在证明磁盘模式可以在各种数据集和模型上以 32 倍的压缩率提供高搜索质量,同时保持我们的目标延迟(低于 P90 200 毫秒)。这些基准不是为评估机器学习模型而设计的。模型对搜索质量的影响因多种因素而异,包括数据集。
磁盘模式的幕后优化
当您将 k-nn 索引配置为在磁盘模式下运行时,OpenSearch 会自动应用量化技术,在加载矢量时对其进行压缩以生成压缩索引。默认情况下,磁盘模式将每个全精度向量(数百到数千个维度的序列,每个维度存储为 32 位数字)转换为二进制矢量,二进制矢量将每个维度表示为一个单位。这种转换可产生 32 倍的压缩率,使引擎能够生成比由全精度矢量组成的索引小 97% 的索引。大小合适的群集会将此压缩索引保存在内存中。
压缩通过减少矢量引擎所需的内存来降低成本,但作为回报,压缩会牺牲精度。磁盘模式使用两步搜索过程可以恢复准确性,从而恢复搜索质量。查询执行的第一阶段首先是高效地遍历内存中的压缩索引以查找候选匹配项。第二阶段使用这些候选向量对相应的全精度向量进行过采样。这些全精度矢量以旨在减少 I/O 和优化磁盘检索速度和效率的格式存储在磁盘上。然后,使用全精度矢量样本对第一阶段的匹配进行增强和重新评分(使用精确的 k-nn),从而恢复因压缩而造成的搜索质量损失。磁盘模式相对于内存模式的更高延迟归因于这种重新评分过程,这需要磁盘访问和额外的计算。
早期客户成功案例
客户已经在磁盘模式下运行矢量引擎。在本节中,我们将分享早期采用者的感言。
Asana 通过 OpenSearch 的矢量引擎逐步引入语义搜索功能,正在提高客户在工作管理平台上的搜索质量。他们最初通过使用产品量化将索引压缩 16 倍来优化部署。通过切换到磁盘优化配置,他们有可能将成本再降低 33%,同时保持搜索质量和延迟目标。这些经济学使 Asana 可以扩展到数十亿个向量,并在其整个平台上实现语义搜索的民主化。
DevRev 通过直接将面向客户的团队与开发人员联系起来,弥合了软件公司的根本差距。作为一个以人工智能为中心的平台,它创建了从客户反馈到产品开发的直接途径,通过准确的搜索、快速分析和可定制的工作流程,帮助 1,000 多家公司加速增长。DevRev 建立在大型语言模型 (LLM) 和在 OpenSearch 的矢量引擎上运行的检索增强生成 (RAG) 流程之上,可实现智能对话体验。
"借助 OpenSearch 的磁盘优化矢量引擎,我们以 16 倍的压缩率实现了搜索质量和延迟目标。OpenSearch 为我们数十亿的矢量搜索之旅提供了可扩展的经济效益。"
— 安舒·阿维纳什,DevRev 的人工智能和搜索主管
在 OpenSearch 矢量引擎上开始使用磁盘模式
首先,您需要确定托管索引所需的资源。首先,使用以下公式估算支持磁盘优化 k-nn 索引(默认压缩率为 32 倍)所需的内存:
Required memory (bytes) = 1.1 x ((vector dimension count)/8 + 8 x m) x (vector count)
例如,如果您使用 Amazon Titan Text V2 的默认值,则您的矢量维度数为 1024。磁盘模式使用 HNSW 算法来构建索引,因此 "m" 是算法参数之一,默认为 16。如果您为由 Amazon Titan Text 编码的 10 亿个矢量语料库构建索引,则您的内存要求为 282 GB。
如果您的工作负载吞吐量大,则需要确保您的域名也有足够的 IOPS 和 CPU。如果您遵循部署优秀实践,则可以使用实例存储和存储性能优化的实例类型,这通常会为您提供足够的 IOPS。您应始终对高吞吐量工作负载进行负载测试,并调整原始估计值以适应更高的 IOPS 和 CPU 要求。
现在,您可以部署一个大小适合您需求的 OpenSearch 2.17+ 域名。将模式参数设置为 on_disk 创建 k-nn 索引,然后提取数据。如果您已经在默认in_memory模式下运行了 k-nn 索引,则可以通过将模式切换到on_disk然后执行重新索引任务来对其进行转换。重建索引后,您可以相应地缩小域名。
结论
在这篇文章中,我们讨论了如何在磁盘模式下运行 OpenSearch 矢量引擎中获益,分享了客户成功案例,并提供了入门技巧。现在,您可以以低至三分之一的成本运行 OpenSearch 矢量引擎。
要了解更多信息,请参阅文档。
作者简介
 Dylan Tong 是亚马逊云科技的高级产品经理。他领导 OpenSearch 的人工智能和机器学习(ML)产品计划,包括 OpenSearch 的矢量数据库功能。Dylan 拥有数十年的直接与客户合作以及在数据库、分析和 AI/ML 领域创建产品和解决方案的经验。Dylan 拥有康奈尔大学计算机科学学士学位和工程硕士学位。
Dylan Tong 是亚马逊云科技的高级产品经理。他领导 OpenSearch 的人工智能和机器学习(ML)产品计划,包括 OpenSearch 的矢量数据库功能。Dylan 拥有数十年的直接与客户合作以及在数据库、分析和 AI/ML 领域创建产品和解决方案的经验。Dylan 拥有康奈尔大学计算机科学学士学位和工程硕士学位。
 Vamshi Vijay Nakkirtha 是一名软件工程经理,从事 OpenSearch 项目和 Amazon OpenSearch 服务。他的主要兴趣包括分布式系统。
Vamshi Vijay Nakkirtha 是一名软件工程经理,从事 OpenSearch 项目和 Amazon OpenSearch 服务。他的主要兴趣包括分布式系统。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。