我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
扩展 DynamoDB:分区、快捷键和分割如何影响性能(第 1 部分:加载)
每次实验结束后,我们都会查看生成的性能图,解释我们所看到的模式,并通过反复的改进迭代向您展示 DynamoDB 内部基础知识和编写高性能应用程序的最佳实践。我们涵盖了表分区、分区键值、热分区、热分区、突发容量和表级吞吐量限制。
这个由三部分组成的系列文章首先介绍了我们将要探讨的问题,并探讨数据加载策略和 DynamoDB 在短时间运行期间的行为。
亚马逊云科技估计,我们即将探索的解决方案不仅可以大规模扩展,而且加载项目的成本约为0.18美元,每月持续存储0.05美元,并且在完全灵活的按需模式下,他们可以花费1美元进行800万次查询。我们将从缓慢的负载开始,到最后,我们将每秒处理数百万个请求,平均延迟低于 2 毫秒。
客户用例:IP 地址查询
这篇文章的灵感来自客户关于高基数分区键重要性的问题。许多 DynamoDB 用例都有自然而明显的高基数分区键(例如客户 ID 或资产 ID)。不是这种情况。埃森哲联邦服务联系了我们,表示他们想设计一个 IP 地址元数据查询服务。他们的数据集由数十万个 IP 地址范围组成,每个范围都有一个起始地址(例如 192.168.0.0)、一个结束地址(例如 192.168.10.255)和相关的元数据(例如所有者、国家/地区、适用的安全规则等)。他们的查询需要接受 IP 地址,找到包含该地址的范围,然后返回元数据。
埃森哲联邦服务想知道:
- DynamoDB 在这项查询服务上的表现如何。
- 哪种表格设计最有效。
- 就运行时间、成本和可扩展性而言,哪种设计最有效。
- 理论上每秒 DynamoDB 可以达到的最大查找次数是多少。
- 他们还担心他们的用例看起来不像经典的 DynamoDB 用例,因为没有明显的分区键。他们想知道这是否会限制性能。
在这篇文章中,我们将解决问题并回答这些问题。
查询算法
在进行任何表格设计之前,拥有基本算法很重要。它必须接受 IP 地址并有效地定位包含该地址的范围。
DynamoDB 表架构具有分区键和可选排序键。可能存在其他属性,但它们没有被索引(除非放在二级索引中)。
如果您还不熟悉分区键和排序键,则可能需要先学习
从 DynamoDB 提取数据的一种方法是执行
查询
操作。
查询
可以做很多事情,其中之一是检索精确指定分区键且排序键使用不等式(分区键等于 X,排序键不等于 Y)的项目。我们可以使用
查询
从 IP 范围中查找 IP,前提是数据符合以下两点:
- 数据集中的 IP 范围从不重叠。这本质上是正确的,否则数据集会模糊不清(因为同一个IP会有多个元数据条目)。
- IP 范围完整描述了所有 IP 地址,没有空白。这并不总是正确的,因为有些 IP 范围是专门保留的,没有元数据,但是合成范围可以通过有效负载来填补空白,表明没有可用的元数据,从而使这一假设成真。
每个 IP 范围都可以作为项目(行)存储在 DynamoDB 中。现在,让我们假设一个固定分区键值(所有项目都相同)和一个等于该范围的起始 IP 地址的排序键值。下面的图 1 显示了数据模型。(我们稍后会改进这个数据模型。)
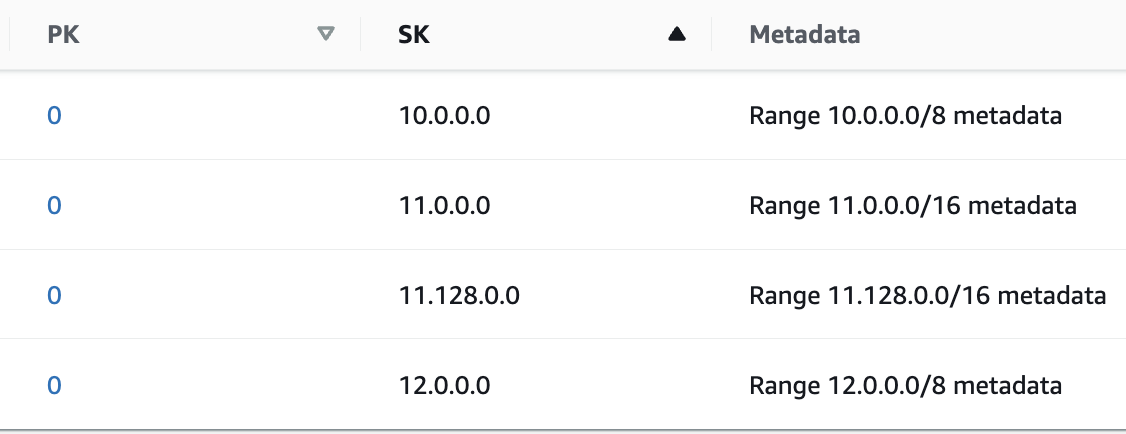
图 1:使用固定分区键的数据模型
然后,通过向后扫描并
如果你很难看出这个算法是如何工作的,那么将其可视化可能会有所帮助。想象一下乡下的围栏,许多栅栏柱是随机放置的。你想知道围栏的哪一段对应于你可能沿着栅栏行走的任何特定距离。要解决这个问题,你首先要走出那段距离,然后向后走,直到遇到栅栏柱。那篇围栏帖子上有关于该区段的所有元数据。每个围栏柱都描述了其后的部分。另一边的栅栏柱上存放着有关其后片段的元数据。如果围栏上有缝隙,则缝隙前的栅栏柱上会显示 这里的 间隙 。
但是等等,只有一个分区键值可以使查询变得简单,但直接违背了 DynamoDB
数据格式
要进行测试,我们必须首先考虑实际的数据格式。源数据位于 CSV 文件中,每行一个 IP 范围,没有间隙,没有重叠。每行都有起始和结束 IP 值以及元数据。以下是一个模拟示例,其中添加了空格以提高可读性:
使用起始 IP 字符串作为排序键很诱人,但是像对数字一样对字符串进行排序是危险的。你会发现 .100 介于 .1 和 .2 之间。一种解决方案是对值进行零填充,这样 1.0.32.0 就会变成 001.000.032.000。如果每个数字始终是三位数,则字符串和数字的排序方式相同。
还有更好的方法:将每个 IP 地址转换为其自然数字形式。IP 地址几乎总是以点分四进制格式编写,例如 1.0.32.0,但这只是一种人性化的序列化。从根本上讲,IP 地址(无论如何都是 IPv4)是一个单一的 32 位值。
序列化为二进制(但出于可读性考虑,保留句点)时 IP 地址 1.0.32.0 为 00000001.00000000.0000000,如果以单十进制形式传输,则为 16,785,408。这就是我们用于排序键的编号模型,因为它对不等式运算既简单又高效,而且
下面的图 2 显示了将 IP 地址转换为数值后该表的样子。
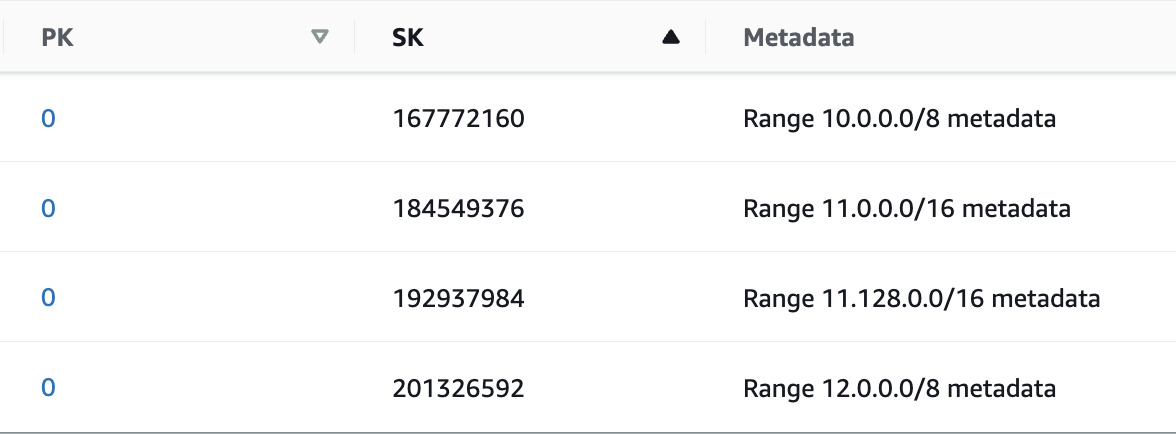
图 2:显示 IP 地址转换为数值的表格
正在加载
现在我们已经准备好开始测试,从负载性能开始。我们使用一个简单的循环单线程 Python 脚本加载 CSV 文件。请注意,所有测试结果均来自
美国东部
一号区域。
加载测试:按需表,顺序 CSV,使用单个分区键
作为第一个测试,让我们对新创建的按需表执行批量加载。我们从 CSV 文件中加载,让 Python 代码为所有项目分配相同的分区键,并将 IP 范围字符串转换为数字值。请注意,CSV 文件数据按 IP 范围排序,开头的 IP 较低。这种排序在 CSV 文件中很常见,这在实验的后面会很重要。下面的图 3 显示了结果。
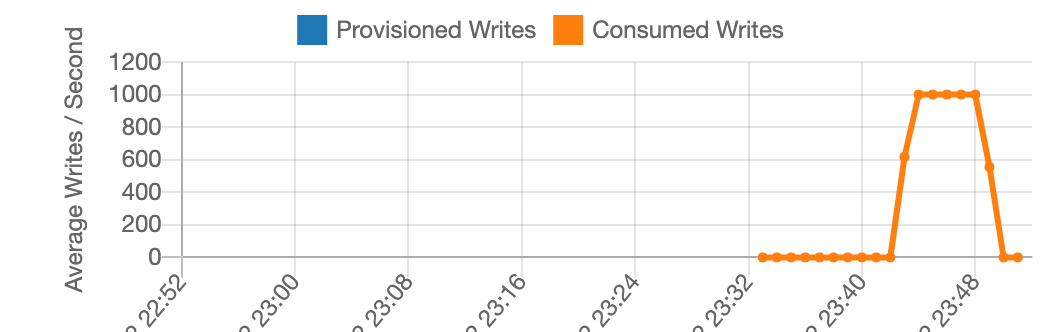
图 3:第一次负载测试的结果:按需表、顺序 CSV、单分区键
如图 3 所示,第一次负载测试以每秒 1,000 个写入单位的稳定速率执行。其余的写入请求受到限制。
以下是幕后发生的事情:每个 DynamoDB 表都分布在一定数量的物理分区中。每个物理分区每秒可以支持 3,000 个读取单元和每秒 1,000 个写入单元。仅使用一个分区键值,所有写入操作都将发送到一个分区,这就造成了瓶颈。
这并不意味着新的按需表仅分配一个分区。按需表会不断适应实时流量,新创建的按需表被记录为能够提供多达 4,000 个写入请求单元和 12,000 个读取请求单元。有关更多信息,请参阅
这些吞吐量能力与具有四个分区的表的功能完全一致。因此,即使有四个分区可用,因为我们使用的是单个分区键值,所有流量都会分配给其中一个分区,而其他三个分区处于非活动状态。
快速回顾一下如何将数据分配给分区:每个分区负责表键空间的子集,类似于非常大的数字行上的数字范围。分区键值经过哈希处理,将其转换为数字,其范围包含该数字的分区将对该分区键值进行读取或写入。如果分区键值始终相同,则同一分区通常会获得所有读取和写入。请注意,不同的分区键可以哈希到数字范围的相同常规区域,如果是,则将在处理该范围的分区中并置。分区可以拆分,将其项目移至两个新分区,并在数字范围上引入新的分割点。分区也可以在项目集合内拆分(分区键值相同的项目),在这种情况下,在计算分割点时会考虑排序键。
我们很快就会看到这适用,但要点是,使用单个分区键值最初会将所有项目放到同一个分区中,这会极大地限制写入。
加载测试:按需表、顺序 CSV 和多个分区键
如果我们将数据分散到更多的分区键值上,我们可以加快加载速度。也许我们选择分区键值,即 IP 地址的第一部分。例如,192.168.0.0 获得的分区键为 192。这样可以将写入分区键值分散到 200 多个分区键值中,并且应该可以更均匀地将工作分散到各个分区中。
我们必须调整查询以根据要查找的 IP 范围指定正确的分区键,并调整加载器以确保没有范围跨越分区键边界,因为如果分区键边界跨越分区键边界,那么核心逻辑就会失效。新的表格设计如下图 4 所示。
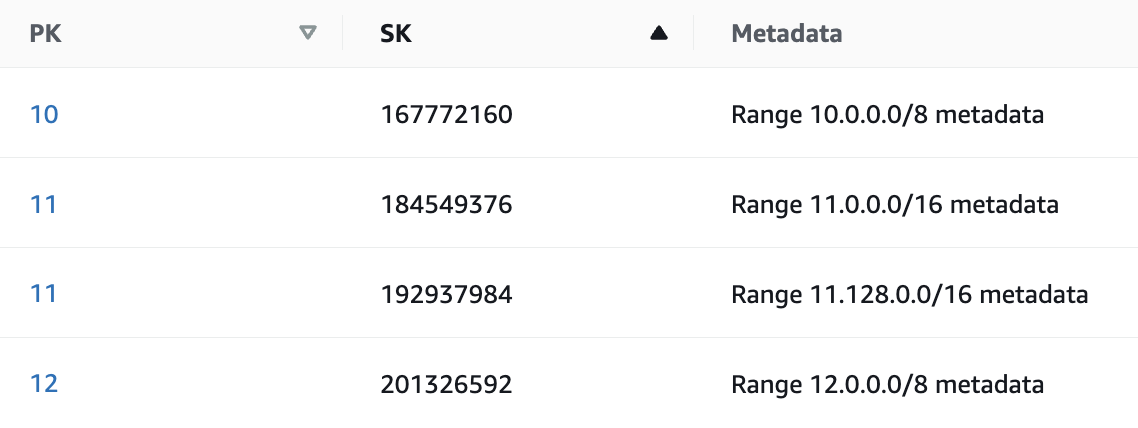
图 4:表格设计显示每个 /8 地址范围的不同分区键
下面的图 5 显示了加载过程中的性能。
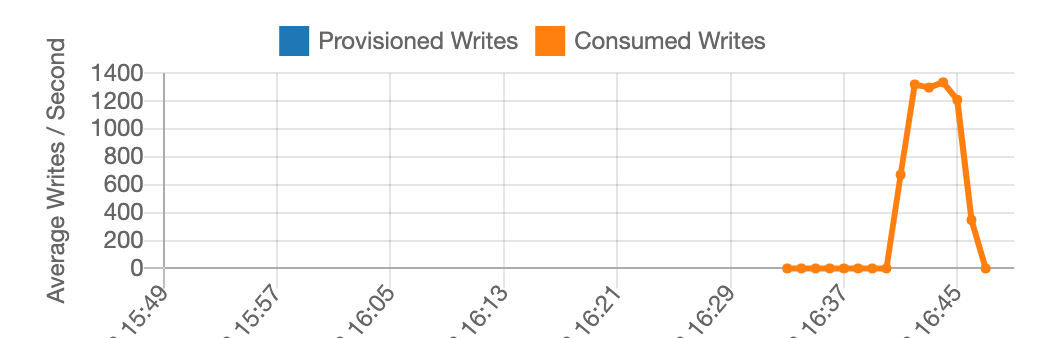
图 5:第二次负载测试的结果:现在有许多分区键
负载提高到每秒大约 1,250 次写入。为什么不更多?为什么工作不能更好地分配到各个分区?这是因为 CSV 文件是连续的。每个分区键值的所有数千个范围都依次进入。一个分区占用一段时间的所有流量,然后是另一个分区,然后是另一个分区。传播得不好。唯一的改进是分区键值切换,轮到新分区作为节流分区。
这里的结论是,顺序的 CSV 加载不能很好地分配流量。
加载测试:按需表、随机 CSV 和多个分区键
如果我们随机化 CSV 文件条目的顺序(通过调整文件或在 Python 加载器中进行洗牌作为内部任务),我们可以希望更均匀地分配负载并提高性能。下面的图 6 显示了我们的测试结果。
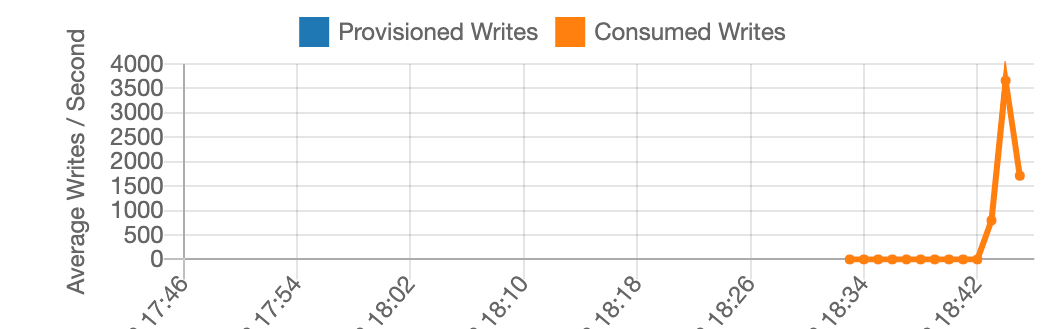
图 6:第三次负载测试的结果:现在使用的是行随机化 CSV 文件
此测试在不到 2 分钟的时间内完成。第一次和最后一次计时都是不完整的分钟,我们无法推断出每秒的速率。在完全测量的中心分钟内,它达到了每秒大约 3,600 次写入。这与四个分区得到充分利用的情况非常匹配。随机化数据写入顺序的简单操作极大地提高了写入吞吐量。
出于这些原因,每当 CSV 文件的行按分区键值排序(因此按分区键值分组)时,都应随机化 CSV 负载。
如果源数据来自另一个 DynamoDB 表的
扫描
,则在加载之前随机化源数据也很有用,因为
扫描
返回的项目自然 是按分区键哈希值分组的,因此在加载期间会形成稳定的热线。
加载测试:预置表、随机 CSV 和多个分区键
到目前为止,所有测试都是在新创建的按需表格上进行的。让我们测试一个配置为 10,000 个写入容量单位 (WCU) 的表(为了简单起见,我们不会开启自动扩展)。我们将继续使用随机化的 CSV 文件。下面的图 7 显示了我们观察到的情况。
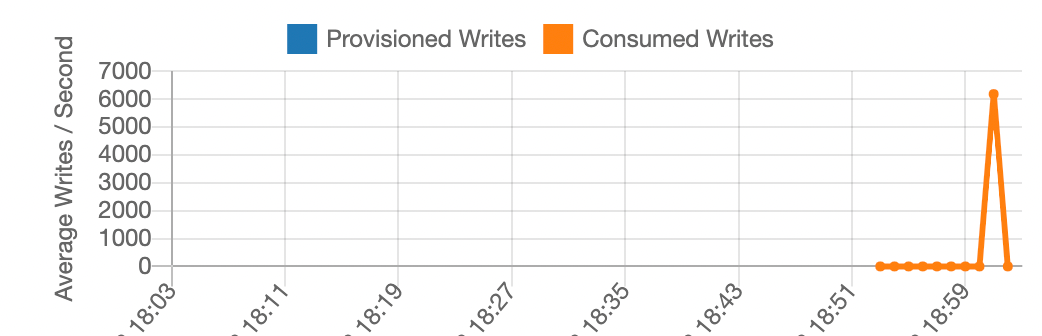
图 7:第四次负载测试的结果:现在使用配置为 10,000 个 WCU 的表
加载在不到一分钟的时间内完成。所有活动都收集在一个亚分钟的数据点中,平均每秒写入 6,000 次,这意味着那一分钟的峰值远高于该峰值。
新配置的包含 10,000 个 WCU 的表比新的按需表拥有更多的分区(它需要至少 10 个分区来处理写入负载),并且通过将大量分区键值分布在这些额外的分区上,我们得以提高性能。
这是否意味着预置比按需更好?不,因为
加载测试:摘要
最大负载速率取决于物理分区的数量、分区键值的数量以及负载跨分区并行处理工作的能力。拥有更多分区往往会提高加载率,但是如果有足够的分区键值将工作分散到各个分区上,并且加载逻辑也会将工作分散到分区键值上,则分区越多是最有益的。
在
结论
在这个由三部分组成的系列中,您通过回顾使用不同的分区键设计测试加载和查询性能的结果,了解了 DynamoDB 的内部结构。我们讨论了表分区、分区键值、热分区、热分区、突发容量和表级吞吐量限制。
与往常一样,欢迎您在评论中留下问题或反馈。
作者简介
 杰森·亨特
是加利福尼亚的首席解决方案架构师,专门研究 DynamoDB。自 2003 年以来,他一直在使用 NoSQL 数据库。他以对 Java、开源和 XML 的贡献而闻名。
杰森·亨特
是加利福尼亚的首席解决方案架构师,专门研究 DynamoDB。自 2003 年以来,他一直在使用 NoSQL 数据库。他以对 Java、开源和 XML 的贡献而闻名。
 Vivek Natarajan
是普渡大学主修计算机科学,也是 亚马逊云科技 的解决方案架构师实习生。
Vivek Natarajan
是普渡大学主修计算机科学,也是 亚马逊云科技 的解决方案架构师实习生。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。