我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 Glue 和亚马逊 Athena 处理和分析高度嵌套的大型 XML 文件
在当今的数字时代,数据是每个组织成功的核心。XML 是交换数据的最常用格式之一。分析 XML 文件至关重要,原因有很多。首先,XML 文件用于许多行业,包括金融、医疗保健和政府。分析 XML 文件可以帮助组织深入了解其数据,从而做出更好的决策并改善运营。分析 XML 文件还有助于数据集成,因为许多应用程序和系统使用 XML 作为标准数据格式。通过分析 XML 文件,组织可以轻松地集成来自不同来源的数据并确保其系统之间的一致性。但是,XML 文件包含半结构化、高度嵌套的数据,使得访问和分析信息变得困难,尤其是在文件很大、架构复杂、高度嵌套的情况下。
XML 文件非常适合应用程序,但它们可能不是分析引擎的最佳选择。为了提高查询性能并便于在下游分析引擎(例如
解决方案概述
我们探索了两种可以简化 XML 文件处理工作流程的不同技术:
- 技巧 1:使用 亚马逊云科技 Glue 爬虫和 亚马逊云科技 Glue 可视化编辑器 — 您可以将 亚马逊云科技 Glue 用户界面与爬虫结合使用,为 XML 文件定义表结构。这种方法提供了用户友好的界面,特别适合喜欢以图形方式管理数据的个人。
-
技巧 2:使用具有推断和固定架构的 亚马逊云科技 Glue DynamicFr
ames — 爬虫在处理大于 1 MB 的 XML 文件中的单行时存在局限性。 为了克服这一限制,我们使用 亚马逊云科技 Glue 笔记本来构建 亚马逊云科技 GlueDynamicFrames ,同时使用推断和固定架构。此方法可确保有效处理行大小超过 1 MB 的 XML 文件。
在这两种方法中,我们的最终目标是将 XML 文件转换为 Apache Parquet 格式,使它们易于使用 Athena 进行查询。使用这些技术,您可以提高 XML 数据的处理速度和可访问性,从而使您能够轻松获得有价值的见解。
先决条件
在开始本教程之前,请完成以下先决条件(这两种方法均适用):
-
下载 XML 文件
technique1.xml 和technique2.xml 。 -
将文件上传到
Amazon Simple Storage Servic e (Amazon S3) 存储桶。您可以将它们上传到不同文件夹中的同一 S3 存储桶或不同的 S3 存储桶。 -
按照为 A
WS Glue Stud io 设置 IAM 权限中的说明为您的 ETL 任务或笔记本创建 亚马逊云科技 身份和访问管理 (IAM ) 角色。 -
使用
iam: passRole 操作向您的角色添加内联策略:
- 向拥有您的 S3 存储桶访问权限的角色添加权限策略。
现在我们已经完成了先决条件,让我们继续实现第一种技术。
技巧 1:使用 亚马逊云科技 Glue 爬虫和可视化编辑器
下图说明了可用于实现解决方案的简单架构。
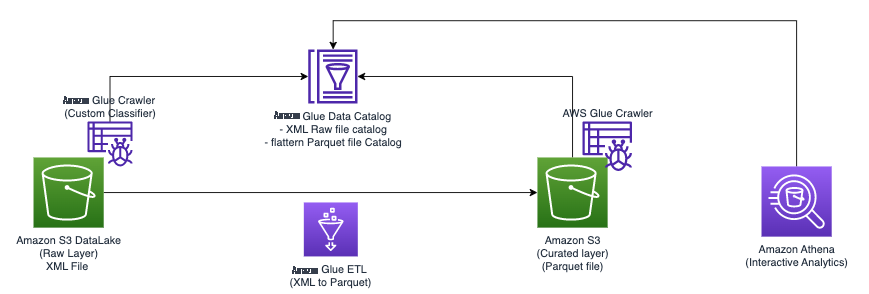
要使用 亚马逊云科技 Glue 和 Athena 分析存储在 Amazon S3 中的 XML 文件,我们完成了以下高级步骤:
- 创建 亚马逊云科技 Glue 爬虫来提取 XML 元数据并在 亚马逊云科技 Glue 数据目录中创建表。
- 使用 亚马逊云科技 Glue 提取、转换和加载 (ETL) 任务处理 XML 数据并将其转换为适合雅典娜的格式(如 Parquet)。
-
通过 亚马逊云科技 Glue 控制台或 亚马逊云科技
命令行接口 (AW S CLI) 设置和运行 亚马逊云科技 Glue 任务。 - 将处理过的数据(以 Parquet 格式)与 Athena 表一起使用,从而启用 SQL 查询。
- 使用 Athena 中的用户友好界面,通过对存储在 Amazon S3 中的数据进行 SQL 查询来分析 XML 数据。
该架构是一种可扩展、经济实惠的解决方案,用于使用 亚马逊云科技 Glue 和 Athena 分析 Amazon S3 上的 XML 数据。您无需复杂的基础设施管理即可分析大型数据集。
我们使用 亚马逊云科技 Glue 爬虫来提取 XML 文件元数据。您可以选择默认 亚马逊云科技 Glue 分类器进行通用 XML 分类。它会自动检测 XML 数据结构和架构,这对于常见格式很有用。
我们还在此解决方案中使用了自定义 XML 分类器。它专为特定的 XML 架构或格式而设计,允许精确的元数据提取。这对于非标准 XML 格式或需要对分类进行详细控制时非常理想。自定义分类器可确保仅提取必要的元数据,从而简化下游处理和分析任务。这种方法可以优化您的 XML 文件的使用。
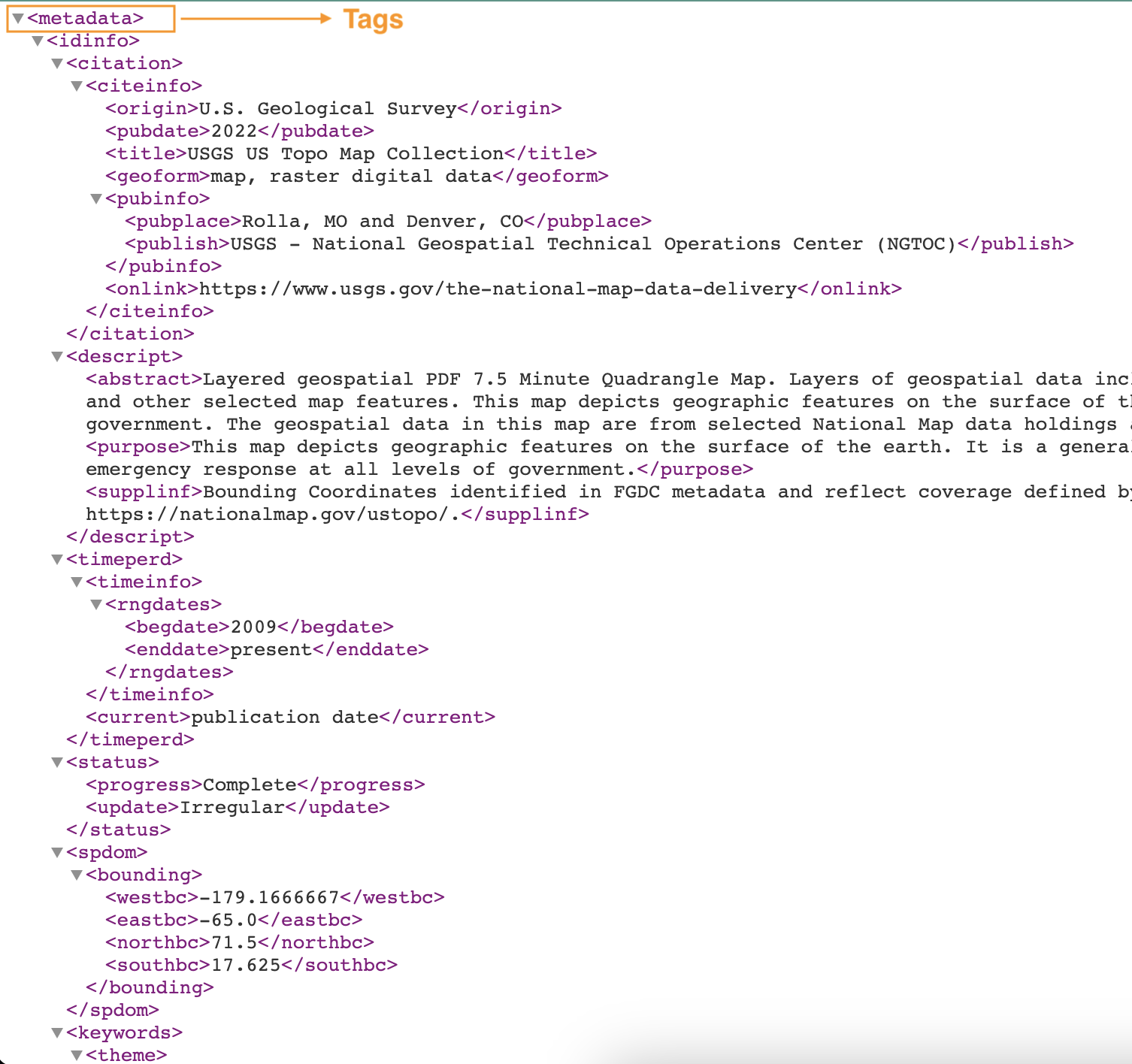
以下屏幕截图显示了带有标签的 XML 文件的示例。
创建自定义分类器
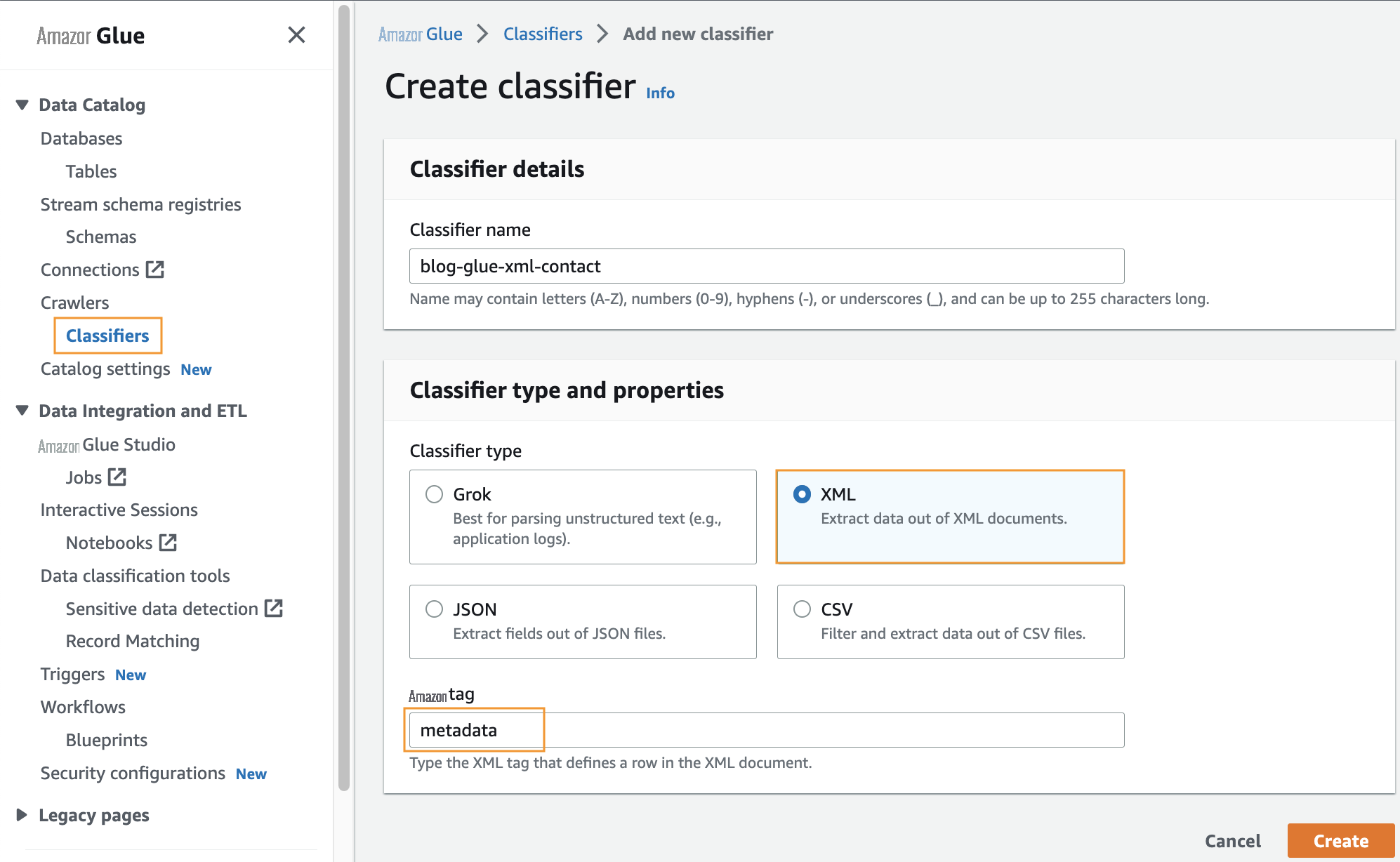
在此步骤中,您将创建自定义 亚马逊云科技 Glue 分类器以从 XML 文件中提取元数据。完成以下步骤:
- 在 亚马逊云科技 Glue 控制台的导航窗格 中的 爬虫 下,选择 分类器 。
- 选择 添加分类器 。
- 选择 XML 作为分类器类型。
-
输入分类器的名称,例如 blog-glue-xm
l-contact。 -
在 行标签 中 ,输入包含元数据(例如元数据 )的根标签的名称。 - 选择 “ 创建 ” 。
创建 亚马逊云科技 Glue Crawler 来抓取 xml 文件
在本节中,我们将创建一个 Glue Crawler,使用上一步中创建的客户分类器从 XML 文件中提取元数据。
创建数据库
-
前往
亚马逊云科技 Glue 控制台 , 在导航窗格中选择 数据库 。 - 单击 “ 添加数据库”。
-
提供一个名字,比如
blog_glue_xml - 选择 “ 创建 数据库 ”
创建爬虫
完成以下步骤来创建您的第一个爬虫:
- 在 亚马逊云科技 Glue 控制台上, 在导航窗格中选择 爬虫 。
- 选择 “ 创建爬虫 ”。
-
在 “
设置爬虫属性
” 页面上,提供新爬虫的名称(例如
blog-glue-parquet),然后选择 “下一步”。 - 在 “选择数据源和分类器 ” 页面上,在 “ 数据源配置 ” 下选择 “ 尚未确定 ”。
- 选择 “ 添加数据存储 ” 。
-
如需查看
S3 路径
,请浏览至
s3://${BUCKET_NAME}/input/geologicalsurvey/。
确保选择 XML 文件夹,而不是该文件夹内的文件。
- 将其余选项保留为默认值,然后选择 添加 S3 数据源 。
- 展开 自定义分类器——可选 ,选择 blog-glue-xml-contact,然后选择 “ 下一步 ”,将其余选项保留为 默认值。
-
选择您的 IAM 角色或选择
创建新的 IAM 角色
,添加后缀 glu
e-xml-contact (例如,og),然后选择下一步。awsGlueserviceNotebookRoleBl -
在 “
设置输出和调度
” 页面的 “
输出配置
” 下,为目标数据库选择
blog_glue_xml。 -
输入
console_作为添加到表中的前缀(可选),在 Crawler 计划 下 ,将频率设置为 按需。 - 选择 “ 下一步 ” 。
- 查看所有参数,然后选择 创建爬虫 。
运行 Crawler
创建爬虫后,请完成以下步骤来运行它:
- 在 亚马逊云科技 Glue 控制台上, 在导航窗格中选择 爬虫 。
- 打开您创建的爬虫并选择 “ 运行 ”。
爬虫需要 1-2 分钟才能完成。
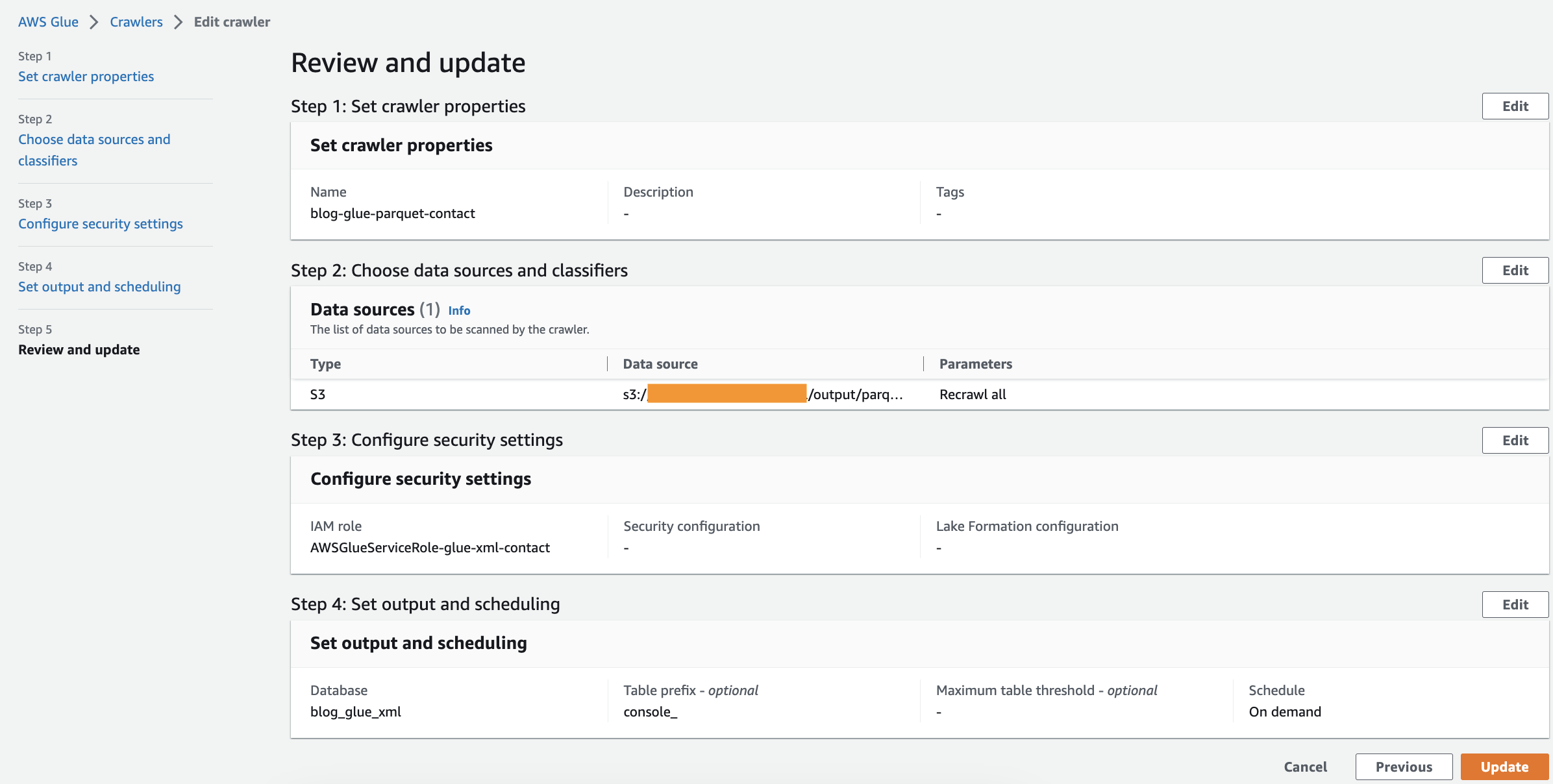
- 搜寻器完成后,在导航窗格 中选择 “ 数据库 ”。
- 选择您创建的数据库并选择表名以查看 Crawler 提取的架构。
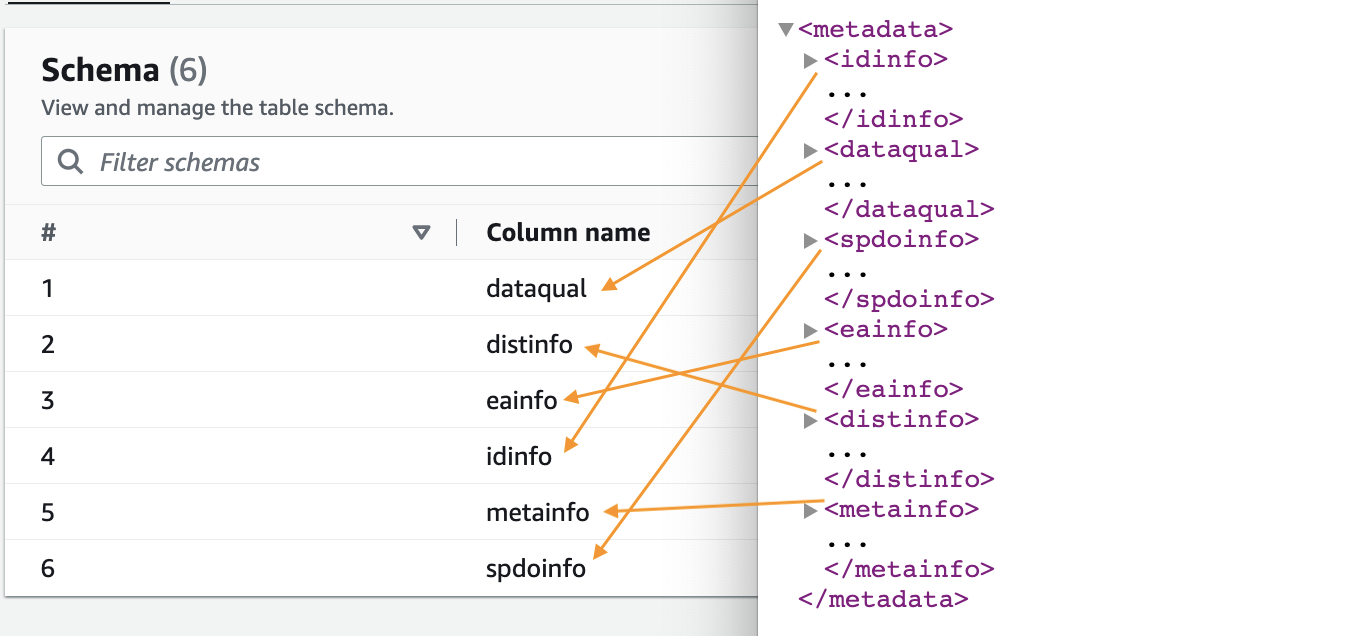
创建 亚马逊云科技 Glue 任务将 XML 转换为 Parquet 格式
在此步骤中,您将创建一个 亚马逊云科技 Glue Studio 任务,将 XML 文件转换为 Parquet 文件。完成以下步骤:
- 在 亚马逊云科技 Glue 控制台上,选择导航窗格 中的 任务 。
- 在 “ 创建作业 ” 下 ,选择 “ 带有空白画布 的可视化 ” 。
- 选择 “ 创建 ” 。
-
将任务重命名为 blog_
glue_xml_job。
现在你有一个空白的 亚马逊云科技 Glue Studio 可视化作业编辑器。编辑器的顶部是不同视图的选项卡。
- 选择 “ 脚本 ” 选项卡,查看 亚马逊云科技 Glue ETL 脚本的空壳。
当我们在可视化编辑器中添加新步骤时,脚本将自动更新。
- 选择 作业详细信息 选项卡以查看所有作业配置。
-
对于
IAM 角色
,请选择
awsGluesServiceNotebookRoleBlog。 - 对于 Glue 版本 ,请选择 Glue 4.0 — 支持 Spark 3.3、Scala 2、Python 3 。
- 将 请求的工作人员人数 设置 为 2。
- 将 重试次 数 设置 为 0。
- 选择 “ 可视 ” 选项卡返回可视化编辑器。
- 在 来源 下拉菜单上,选择 亚马逊云科技 Glue 数据目录 。
-
在
数据源属性-数据目录
选项卡上,提供以下信息:
-
对于
数据库
,选择
blog_glue _xml。 -
对于 表 ,选择以爬虫创建的名称 console_ 开头的表(例如 console_geologicalsurvey)。
-
对于
数据库
,选择
-
在
节点属性
选项卡上,提供以下信息:将
-
名称
更改为
geologicals urvey 数据集。 - 选择 操作 和转换 更改架构(应用映射) 。
-
选择 “
节点属性
” ,然后将转换名称从 “更改架构(应用映射)” 更改为
ApplyMapping。 - 在 目标 菜单上,选择 S3 。
-
名称
更改为
-
在
数据源属性 — S3
选项卡上,提供以下信息:
- 对于 格式 ,选择 Par quet 。
- 对于 “ 压缩类型 ” ,选择 “ 未压缩 ”。
- 对于 S3 源类型 ,选择 S3 位置 。
-
对于
S3 网址
,请输入
s3://${BUCKET_NAME}/output/parquet/。 -
选择 “
节点属性
” ,然后将名称更改为 “
输出” 。
- 选择 “ 保存 ” 以保存作业。
- 选择 “ 运行 ” 来运行作业。
以下屏幕截图显示了可视化编辑器中的作业。
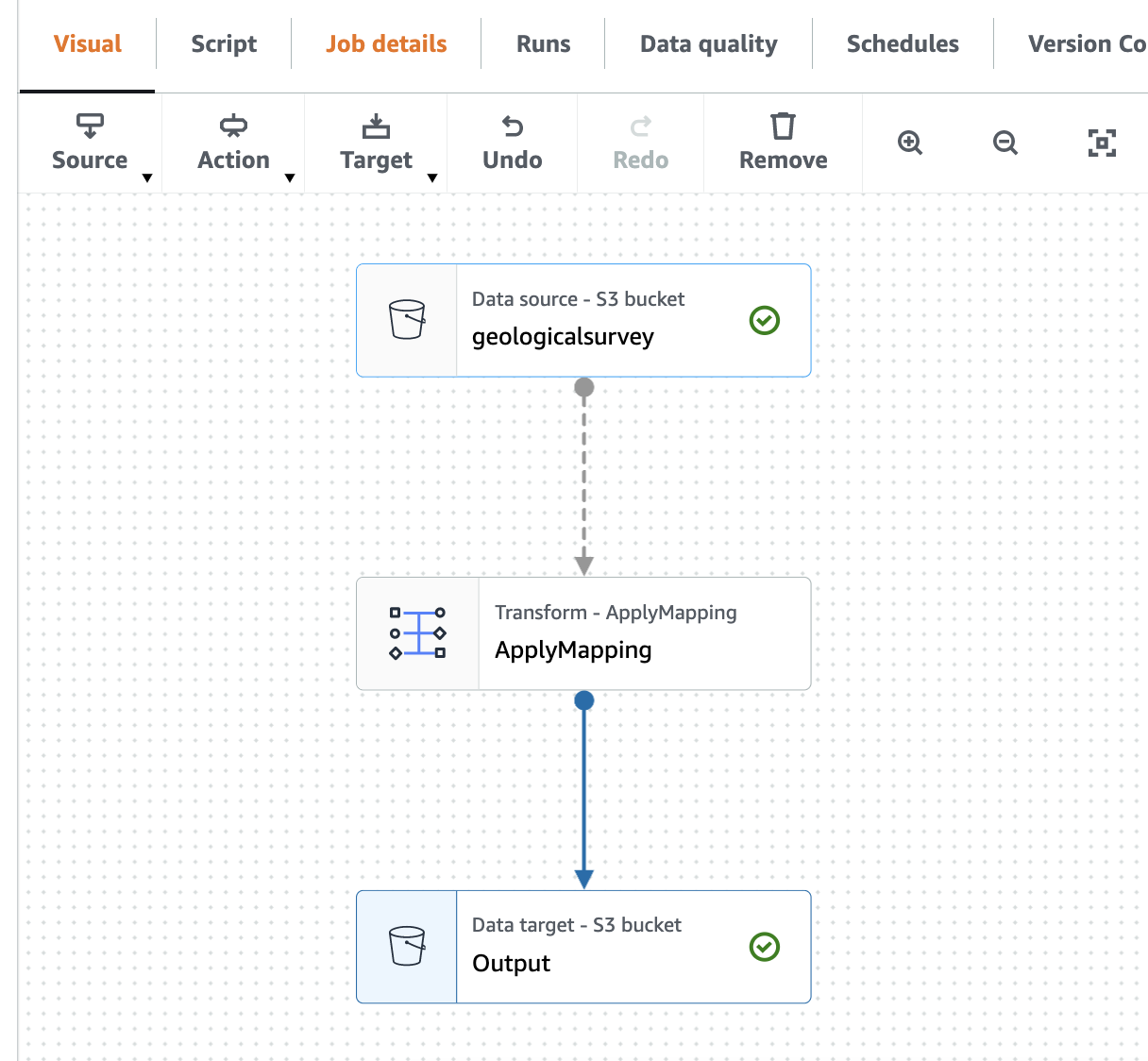
创建 亚马逊云科技 Gue Crawler 来抓取 Parquet 文件
在此步骤中,您将创建一个 亚马逊云科技 Glue 爬虫来从使用 亚马逊云科技 Glue Studio 任务创建的 Parquet 文件中提取元数据。这次,你使用默认的分类器。完成以下步骤:
- 在 亚马逊云科技 Glue 控制台上, 在导航窗格中选择 爬虫 。
- 选择 “ 创建爬虫 ”。
- 在 “ 设置爬虫属性 ” 页面上,提供新爬虫的名称,例如 bl og-glue-parquet-contact,然后选择 “下一步”。
- 在 “选择数据源和分类器 ” 页面上, 为 “ 数据源配置 ” 选择 “ 尚未 完成”。
- 选择 “ 添加数据存储 ” 。
-
如需查看
S3 路径
,请浏览至
s3://${BUCKET_NAME}/output/parquet/。
确保选择
镶木地板
文件 夹,而不是文件夹内的文件。
-
选择您在先决条件部分创建的 IAM 角色,或者选择
创建新的 IAM 角色
(例如,
awsGlueserviceNotebookRoleBlog),然后选择下一步。 -
在 “
设置输出和调度
” 页面的 “
输出配置
” 下,为数据库选择
blog_glue_xml。 -
输入
parquet_作为添加到表格的前缀(可选),在 Crawler 计划 下 ,将频率设置为 按需。 - 选择 “ 下一步 ” 。
- 查看所有参数,然后选择 创建爬虫 。
现在你可以运行爬虫了,这需要 1-2 分钟才能完成。

您可以在 亚马逊云科技 Glue 数据目录中预览新创建的 Parquet 文件架构,该架构与 XML 文件的架构类似。
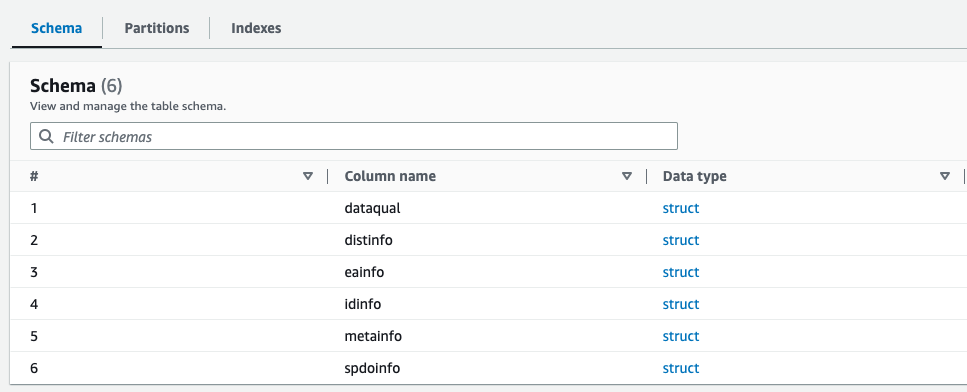
我们现在拥有适合用于 Athena 的数据。在下一节中,我们将使用 Athena 执行数据查询。
使用 Athena 查询 Parquet 文件
Athena 不支持查询
以下示例代码使用点表示法查询嵌套数据:
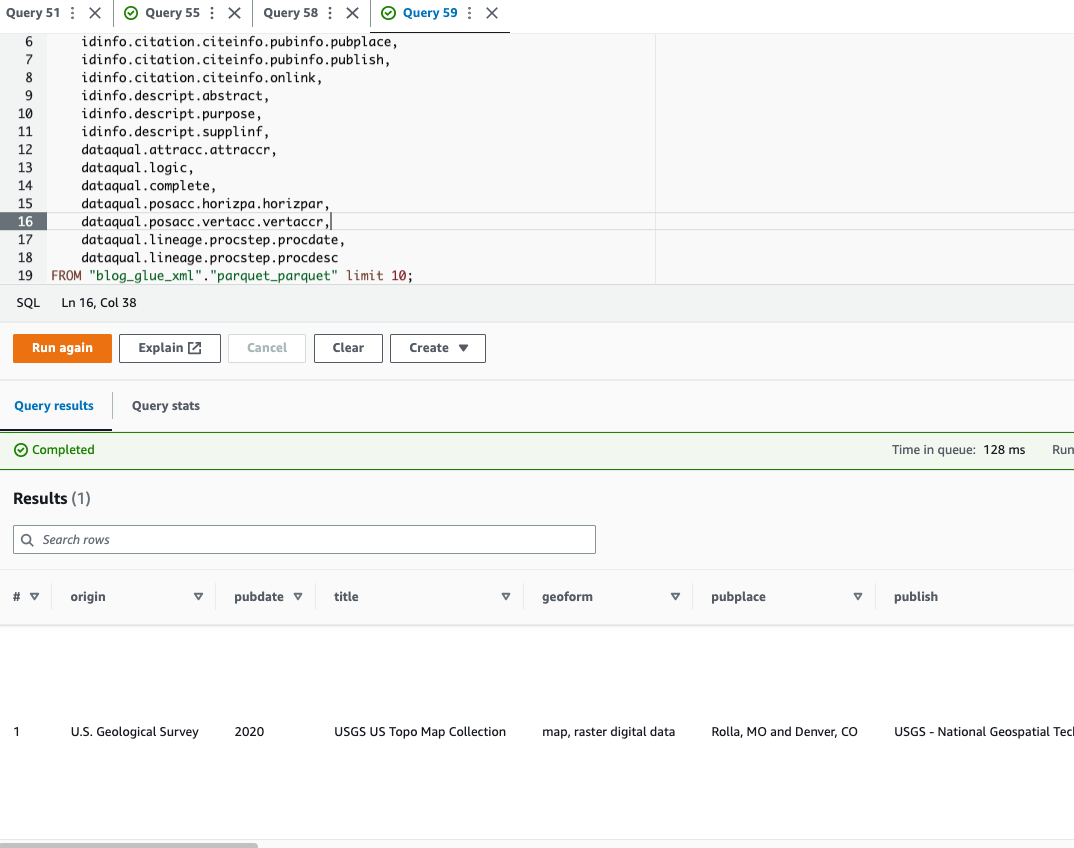
现在我们已经完成了技巧 1,让我们继续学习技巧 2。
技巧 2:使用具有推断和固定架构的 亚马逊云科技 Glue DynamicFrames
在上一节中,我们介绍了使用 亚马逊云科技 Glue 爬虫生成表格的处理小型 XML 文件的过程、将文件转换为 Parquet 格式的 亚马逊云科技 Glue 任务以及访问 Parquet 数据的过程。但是,在处理
我们的方法包括使用推断和固定架构,通过 亚马逊云科技 Glue
要实施此解决方案,您需要完成以下高级步骤:
- 创建 亚马逊云科技 Glue 笔记本来读取和分析 XML 文件。
-
使用 带有
InferSchema 的文件。DynamicFrames 来读取 XML - 使用关系化函数取消嵌套任何数组。
- 将数据转换为 Parquet 格式。
- 使用雅典娜查询 Parquet 数据。
-
重复前面的步骤,但这次是将架构传递给DynamicFrames, 而不是使用 InferSchema。
电动汽车人口数据 XML 文件在其根级别上有一个
响应
标签。该标签包含嵌套在其中的
行
标签数组。行标签是一个包含一组其他行标签的数组,这些行标签提供有关车辆的信息,包括其品牌、型号和其他相关细节。以下屏幕截图显示了一个示例。

创建 亚马逊云科技 Glue 笔记本
要创建 亚马逊云科技 Glue 笔记本,请完成以下步骤:
-
打开
亚马逊云科技 Glu e Studio 控制台, 在导航窗格中选择 任务 。 - 选择 Jupyter 笔记本 并选择 “创建”。
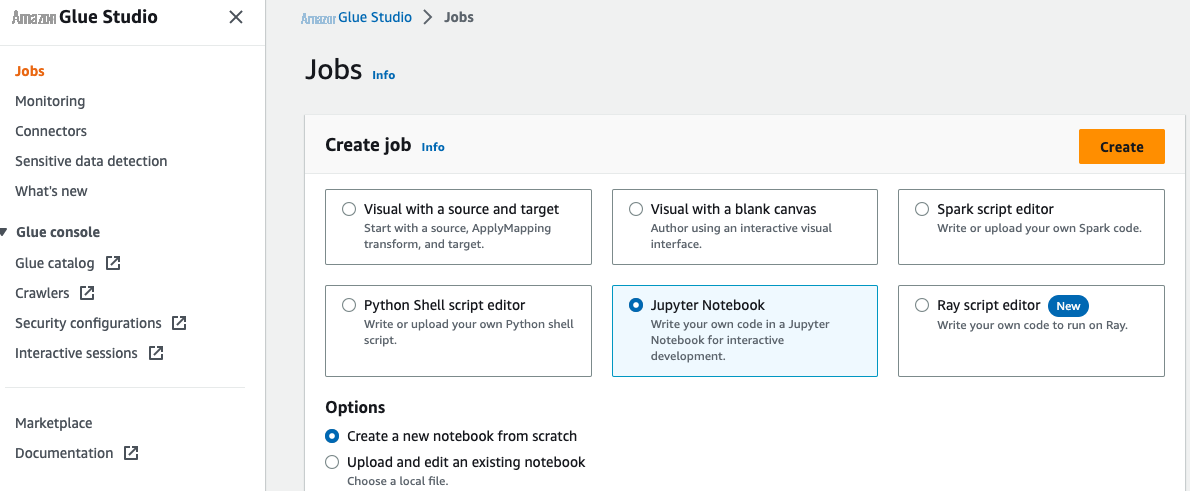
-
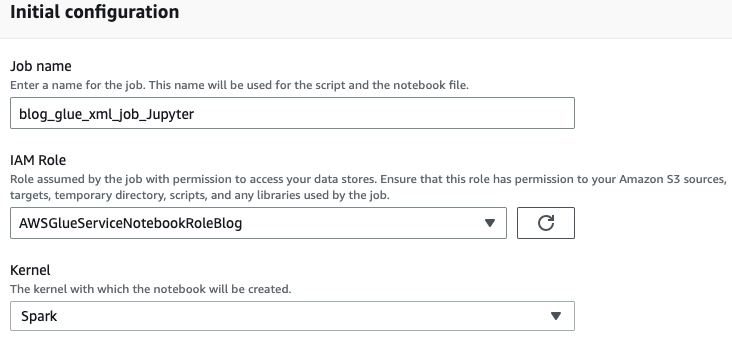
输入你的 亚马逊云科技 Glue 任务的名称,例如 blog_
Glue_xml_job_Jupyter。 -
选择您在先决条件(
awsGlueserviceNotebookRoleBlog)中创建的角色。
亚马逊云科技 Glue 笔记本附带了一个预先存在的示例,该示例演示了如何查询数据库并将输出写入 Amazon S3。
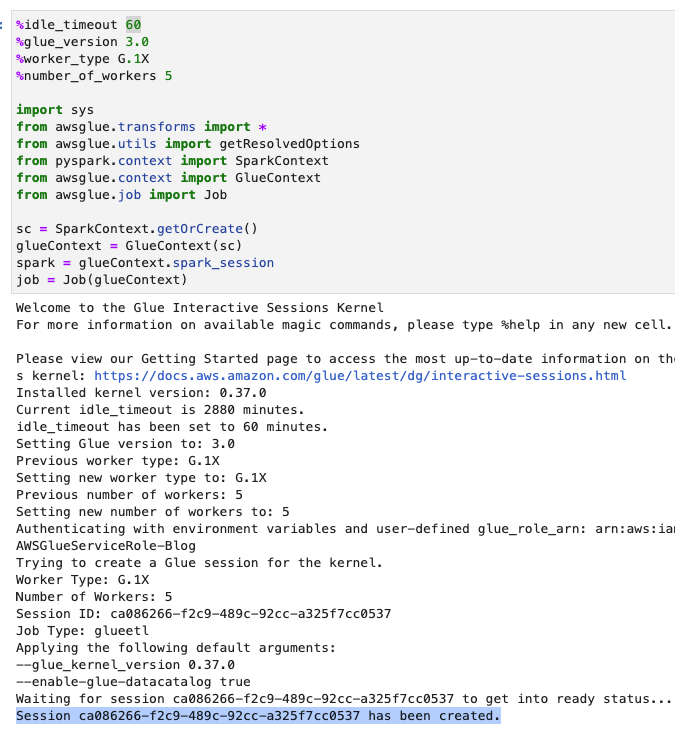
- 调整超时时间(以分钟为单位),如以下屏幕截图所示,然后运行单元创建 亚马逊云科技 Glue 交互式会话。
创建基本变量
创建交互式会话后,在笔记本的末尾创建一个包含以下变量的新单元格(提供您自己的存储桶名称):
读取 XML 文件以推断架构
如果你没有将架构传递给
DynamicFrame
,它会推断出文件的架构。要使用动态帧读取数据,可以使用以下命令:
打印 dynamicFrame 架构
使用以下代码打印架构:
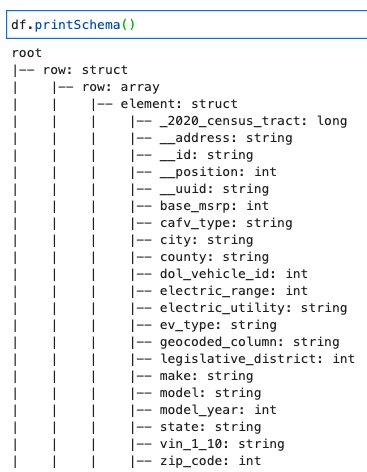
该架构显示了一个嵌套结构,其
行
数组包含多个元素。要将此结构拆分为几行,可以使用 亚马逊云科技 Glue
我们只对行数组中包含的信息感兴趣,我们可以使用以下命令查看架构:
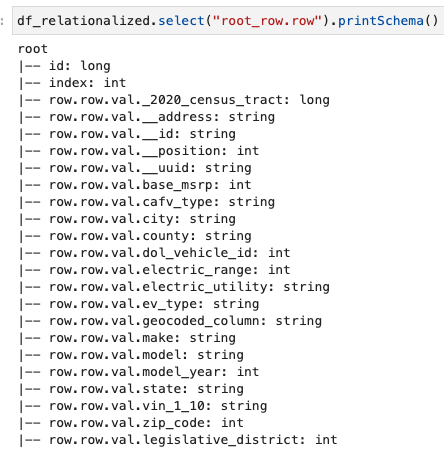
列名包含
row.row
,它对应于数据集中的数组结构和数组列。我们不重命名这篇文章中的列;有关重命名的说明,请参阅
亚马逊云科技 Glue
DynamicFr
ame 提供了一些功能,您可以在 ETL 脚本中使用这些功能在数据目录中创建和更新架构。我们使用
updateBe
havior 参数直接在数据目录中创建表。通过这种方法,我们无需在 亚马逊云科技 Glue 任务完成后运行 亚马逊云科技 Glue 爬虫。

通过设置架构读取 XML 文件
读取文件的另一种方法是预定义架构。为此,请完成以下步骤:
- 导入 亚马逊云科技 Glue 数据类型: etypes 导入*
- 为 XML 文件创建架构:架 ]))))])
- 读取 XML 文件时传递架构: )
- 像以前一样取消嵌套数据集: )
- 将数据集转换为 Parquet 并创建 亚马逊云科技 Glue 表: row.row”))
使用 Athena 查询表
现在我们已经创建了两个表,我们可以使用 Athena 查询这些表。例如,我们可以使用以下查询:
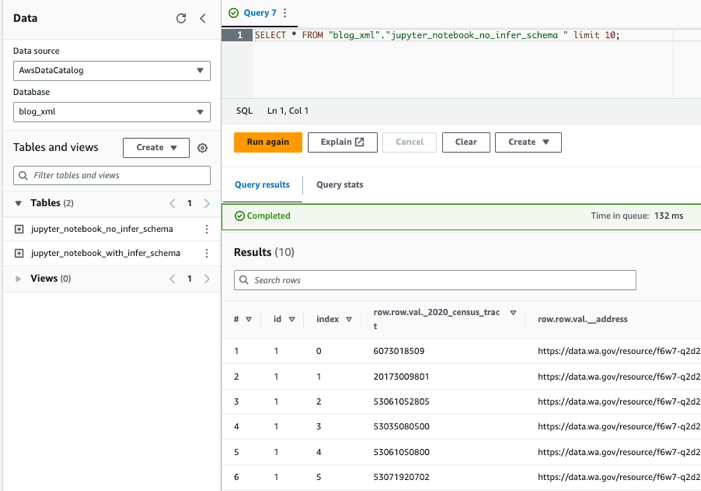
清理
在这篇文章中,我们创建了一个 IAM 角色、一个 亚马逊云科技 Glue Jupyter 笔记本和 亚马逊云科技 Glue 数据目录中的两个表。我们还将一些文件上传到 S3 存储桶。要清理这些对象,请完成以下步骤:
- 在 IAM 控制台上,删除您创建的角色。
- 在 亚马逊云科技 Glue Studio 控制台上,删除自定义分类器、爬虫、ETL 任务和 Jupyter 笔记本。
- 导航到 亚马逊云科技 Glue 数据目录并删除您创建的表。
-
在 Amazon S3 控制台上,导航到您创建的存储桶并删除名为temp、infer_schema 和 no_infer_schema的文件夹。
关键要点
在 AWS Glue 中,AWS Glue DynamicFrames 中有一个名为
它会根据其包含的数据自动计算出数据框的结构。相比之下,定义架构意味着在加载数据之前明确说明数据框的结构。
InferSchema
的功能。
XML 是一种基于文本的格式,不限制其列的数据类型。这可能会导致 InferSchema 函数出现问题。例如,在第一次运行中,列 A 的值为 2 的文件会生成一个以 A 列为整数的 Parquet 文件。在第二次运行中,新文件的 A 列值为 C,导向一个 Parquet 文件,其中 A 列为字符串。现在 S3 上有两个文件,每个文件都有一个不同数据类型的 A 列,这可能会在下游造成问题。
嵌套结构或数组等复杂数据类型也会发生同样的情况。例如,如果文件有一个名为 transact
ion
的标签条目 ,则将其推断为结构。但是,如果另一个文件具有相同的标签,则将其推断为数组
尽管存在这些数据类型问题,但当你不知道
架构或手动定义架构不切实际时,Infer
Schema 还是很有用的。但是,对于大型或不断变化的数据集,它并不理想。定义架构更精确,尤其是对于复杂的数据类型,但也有其自身的问题,例如需要手动操作以及对数据更改不灵活。
InferSchema
存在局限性,例如数据类型推断不正确以及处理空值时出现问题。定义架构也有局限性,例如手动操作和潜在错误。
在推断和定义架构之间进行选择取决于项目的需求。InferSchema 非常适合快速浏览小型数据集,而对于需要准确性和一致性的更大、复杂的数据集,定义架构更好。考虑每种方法的利弊和限制,以选择最适合您的项目的方法。
结论
在这篇文章中,我们探讨了两种使用 亚马逊云科技 Glue 管理 XML 数据的技术,每种技术都是针对您可能遇到的特定需求和挑战量身定制的。
技术 1 为喜欢图形界面的人提供了一条用户友好的路径。您可以使用 亚马逊云科技 Glue 爬虫和可视化编辑器轻松定义您的 XML 文件的表结构。这种方法简化了数据管理流程,对于那些寻求直接处理数据的方法的人来说尤其有吸引力。
但是,我们认识到,爬虫有其局限性,特别是在处理行数大于 1 MB 的 XML 文件时。这就是技术 2 的用武之地。通过利用 具有推断和固定
架构的 AWS Glue DynamicFr
ames,并使用 亚马逊云科技 Glue 笔记本,您可以高效地处理任何大小的 XML 文件。此方法提供了一种强大的解决方案,即使对于行数超过 1 MB 限制的 XML 文件,也能确保无缝处理。
在您浏览数据管理世界时,在工具包中使用这些技术可以使您根据项目的特定要求做出明智的决策。无论您喜欢技术 1 的简单性还是技术 2 的可扩展性,亚马逊云科技 Glue 都能为您提供有效处理 XML 数据所需的灵活性。
作者简介
 Navnit Shukl a
是一名 亚马逊云科技 专业解决方案架构师,专注于分析。他热衷于帮助客户从他们的数据中发现有价值的见解。通过他的专业知识,他构建了创新的解决方案,使企业能够做出明智的、以数据为导向的选择。值得注意的是,纳夫尼特·舒克拉是名为《亚马逊云科技 上的数据整理》一书的杰出作者。
Navnit Shukl a
是一名 亚马逊云科技 专业解决方案架构师,专注于分析。他热衷于帮助客户从他们的数据中发现有价值的见解。通过他的专业知识,他构建了创新的解决方案,使企业能够做出明智的、以数据为导向的选择。值得注意的是,纳夫尼特·舒克拉是名为《亚马逊云科技 上的数据整理》一书的杰出作者。
 帕特里克·穆勒
在 亚马逊云科技 担任高级数据实验室架构师。他的主要职责是帮助客户将他们的想法转化为可用于生产的数据产品。在空闲时间,Patrick 喜欢踢足球、看电影和旅行。
帕特里克·穆勒
在 亚马逊云科技 担任高级数据实验室架构师。他的主要职责是帮助客户将他们的想法转化为可用于生产的数据产品。在空闲时间,Patrick 喜欢踢足球、看电影和旅行。
 Amogh Gaikwad
是亚马逊网络服务的高级解决方案开发人员。他帮助全球客户在 亚马逊云科技 上构建和部署 AI/ML 解决方案。他的工作主要集中在计算机视觉和自然语言处理上,并帮助客户优化其人工智能/机器学习工作负载以实现可持续性。Amogh 获得了计算机科学硕士学位,专攻机器学习。
Amogh Gaikwad
是亚马逊网络服务的高级解决方案开发人员。他帮助全球客户在 亚马逊云科技 上构建和部署 AI/ML 解决方案。他的工作主要集中在计算机视觉和自然语言处理上,并帮助客户优化其人工智能/机器学习工作负载以实现可持续性。Amogh 获得了计算机科学硕士学位,专攻机器学习。
 Sheela Sonone
是 亚马逊云科技 的高级驻地架构师。她帮助 亚马逊云科技 客户在加速数据、分析和 AI/ML 工作负载和实施方面做出明智的选择和权衡。在业余时间,她喜欢与家人共度时光——通常是在网球场上。
Sheela Sonone
是 亚马逊云科技 的高级驻地架构师。她帮助 亚马逊云科技 客户在加速数据、分析和 AI/ML 工作负载和实施方面做出明智的选择和权衡。在业余时间,她喜欢与家人共度时光——通常是在网球场上。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。