我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用全新的 Amazon Personalize 配方向您的用户推荐热门商品
Amazon Personalize 是一项完全托管的机器学习 (ML) 服务,开发者可以轻松地向其用户提供个性化体验。它使您能够通过在网站、应用程序和有针对性的营销活动中提供个性化的产品和内容推荐来提高客户参与度。您无需任何机器学习经验即可开始使用 API,只需点击几下即可轻松构建复杂的个性化功能。您的所有数据都经过加密,以确保私密性和安全性,并且仅用于为用户创建推荐。
用户兴趣可能会根据各种因素而变化,例如外部事件或其他用户的兴趣。网站和应用程序必须根据这些不断变化的兴趣量身定制推荐,以提高用户参与度。借助 Trending-Now,您可以显示目录中比其他商品更快的人气上升的商品,例如热门新闻、热门社交内容或新发行的电影。Amazon Personalize 会以比其他目录商品更快的速度寻找越来越受欢迎的商品,以帮助用户发现吸引同行的商品。Amazon Personalize 还允许您定义根据其独特业务环境计算趋势的时间段,根据用户的最新互动数据,可以选择每 30 分钟、1 小时、3 小时或 1 天计算一次。
在这篇文章中,我们将介绍如何使用这个新食谱向您的用户推荐热门商品。
解决方案概述
Trending-Now 通过计算每个项目在可配置的时间间隔内的互动量增加来识别热门项目。增长率最高的项目被视为热门商品。时间基于您的互动数据集中的时间戳数据。在创建解决方案时,您可以通过提供趋势发现频率来指定时间间隔。
Trending-Now 配方需要一个互动数据集,该数据集包含您的网站或应用程序上的个人用户和商品事件(例如点击、观看或购买)的记录以及事件时间戳。您可以使用 趋势发现频率 参数 来定义计算和刷新趋势的时间间隔。例如,如果您的网站流量大,且趋势变化迅速,则可以指定 30 分钟作为趋势发现频率。每隔 30 分钟,Amazon Personalize 就会查看成功引入的互动并刷新热门商品。此食谱还允许您捕获和显示过去 30 分钟内推出的任何新内容,这些内容比任何先前存在的目录项目更受用户群的兴趣。对于任何大于 2 小时的参数值,Amazon Personalize 会每 2 小时自动刷新一次热门商品推荐,以考虑新的互动和新商品。
由于交互数据稀疏或缺失,流量较低但使用 30 分钟值的数据集的推荐准确性可能较差。Trending-Now 配方要求您提供过去至少两个时间段的互动数据(该时间段是您所需的趋势发现频率)。如果在过去 2 个时间段内没有互动数据,Amazon Personalize 会将热门商品替换为热门商品,直到所需的最低数据可用为止。
Trending-Now 配方既适用于自定义数据集组,也适用于视频点播域数据集组。在这篇文章中,我们将演示如何使用这项针对带有自定义数据集组的媒体用例的全新 Trending-Now 功能,针对用户兴趣的快速变化趋势量身定制推荐。下图说明了解决方案的工作流程。
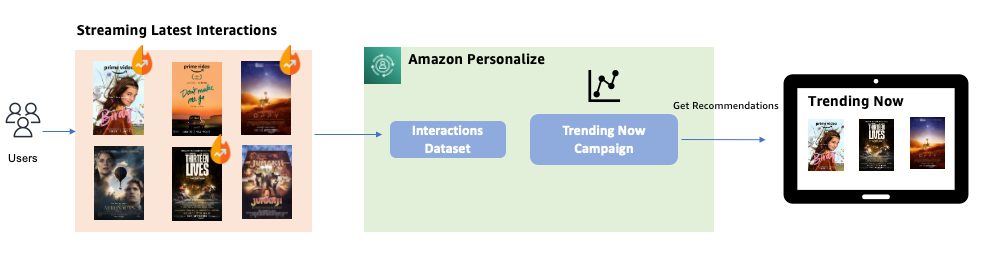
例如,在视频点播应用程序中,您可以使用此功能通过为趋势发现频率指定 1 小时来显示过去 1 小时内的热门电影。对于每 1 小时的数据,Amazon Personalize 就会识别出自上次评估以来互动增长率最高的商品。可用频率包括 30 分钟、1 小时、3 小时和 1 天。
先决条件
要使用 Trending-Now 配方,你首先需要在 Amazon Personalize 控制台上设置亚马逊个性化资源。创建数据集组、导入数据、训练解决方案版本并部署营销活动。有关完整说明,请参阅
在这篇文章中,我们采用了控制台的方法,使用新的 Trending-Now 配方来部署战役。或者,您可以使用提供的
准备数据集
完成以下步骤来准备数据集:
-
创建数据集组 。 -
使用以下
架构 创建互动数据集 : } -
将互动数据 从亚马逊 Simp le Storage Service ( Amazon S3) 导入到 Amazon Personalize。
对于互动数据,我们使用电影评论数据集MovieLens中的评分历史记录。
请使用以下 python 代码从 MovieLens 公共数据集中整理互动数据集。
MovieLens
数据集包含
user_id
、
评分
、
item_id
、用户和物品之间的互动以及这种互动发生的时间(时间戳,以 UNIX 纪元时间给出)。该数据集还包含电影标题信息,用于将电影 ID 映射到实际标题和类型。下表是数据集的示例。
| USER_ID | ITEM_ID | TIMESTAMP | TITLE | GENRES |
| 116927 | 1101 | 1105210919 | Top Gun (1986) | Action|Romance |
| 158267 | 719 | 974847063 | Multiplicity (1996) | Comedy |
| 55098 | 186871 | 1526204585 | Heal (2017) | Documentary |
| 159290 | 59315 | 1485663555 | Iron Man (2008) | Action|Adventure|Sci-Fi |
| 108844 | 34319 | 1428229516 | Island, The (2005) | Action|Sci-Fi|Thriller |
| 85390 | 2916 | 953264936 | Total Recall (1990) | Action|Adventure|Sci-Fi|Thriller |
| 103930 | 18 | 839915700 | Four Rooms (1995) | Comedy |
| 104176 | 1735 | 985295513 | Great Expectations (1998) | Drama|Romance |
| 97523 | 1304 | 1158428003 | Butch Cassidy and the Sundance Kid (1969) | Action|Western |
| 87619 | 6365 | 1066077797 | Matrix Reloaded, The (2003) | Action|Adventure|Sci-Fi|Thriller|IMAX |
精选数据集包括用于
训练 Ama
。这些是使用 Trending-Now 配方训练模型的必填字段。下表是精选数据集的示例。
zon Personalize 模型的 USER _ID
、ITEM_
ID (电影 ID)和时间戳
| USER_ID | ITEM_ID | TIMESTAMP |
| 48953 | 529 | 841223587 |
| 23069 | 1748 | 1092352526 |
| 117521 | 26285 | 1231959564 |
| 18774 | 457 | 848840461 |
| 58018 | 179819 | 1515032190 |
| 9685 | 79132 | 1462582799 |
| 41304 | 6650 | 1516310539 |
| 152634 | 2560 | 1113843031 |
| 57332 | 3387 | 986506413 |
| 12857 | 6787 | 1356651687 |
训练模型
数据集导入任务完成后,您就可以训练模型了。
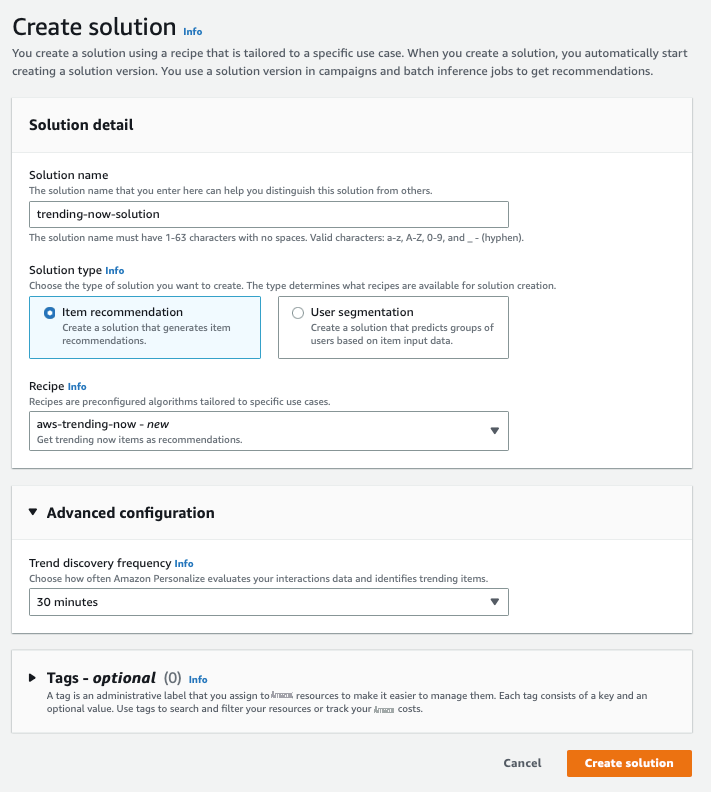
- 在 解决方案 选项卡上,选择 创建解决方案 。
-
选择
全新 aws-trending-now 配方。 - 在 高级配置 部分中,将 趋势发现频率 设置 为 30 分钟。
-
选择 “
创建解决方案
” 开始训练。
创建广告活动
在 Amazon Personalize 中,您使用广告系列为用户提供推荐。在此步骤中,您将使用上一步中创建的解决方案创建广告系列,并获得 Trending-Now 推荐:
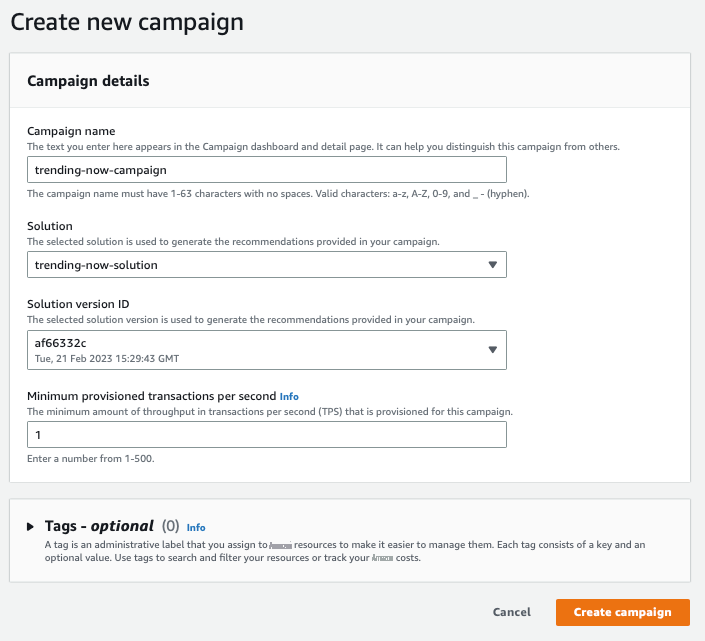
- 在 广告系列 选项卡上,选择 创建广告系列 。
- 在 活动名称 中 ,输入一个名称。
-
在 “
解决方案
” 中,选择 “立即走向
趋势” 的解决方案。 -
对于
解决方案版本 ID
,请选择使用
aws-trending-now 配方的解决方案版本。 - 对于 每秒 最低预配置交易量 ,将其保留为默认值。
-
选择 “
创建广告活动
” 以开始创建您的广告活动。
获取推荐
创建或更新广告系列后,您可以获得按从高到低排序的热门商品的推荐列表。
在广告活动(
即时关注广告
系列 )
个性化 API
选项卡上,选择获取推荐。
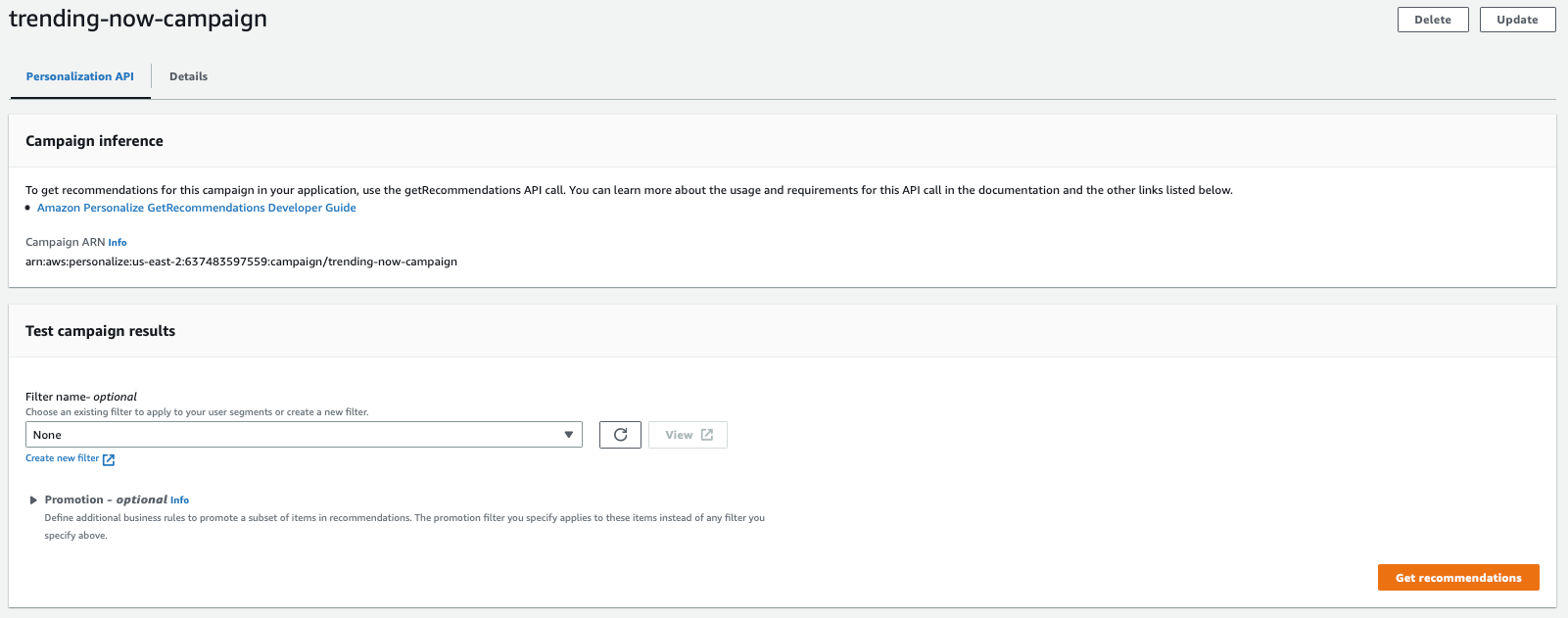
以下屏幕截图显示了活动详情页面,其中包含来自
GetRecommandation
s 调用的结果,其中包括推荐商品和推荐 ID。
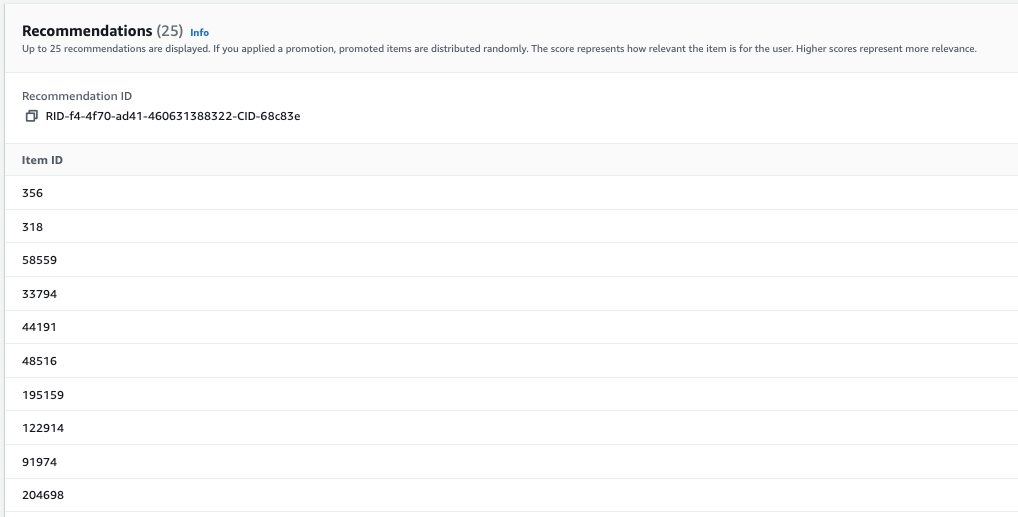
getRecommendations 调
用的结果包括推荐项目的 ID。下表是将 ID 映射到实际电影标题以提高可读性后的示例。执行映射的代码在随附的笔记本中提供。
| ITEM_ID | TITLE |
| 356 | Forrest Gump (1994) |
| 318 | Shawshank Redemption, The (1994) |
| 58559 | Dark Knight, The (2008) |
| 33794 | Batman Begins (2005) |
| 44191 | V for Vendetta (2006) |
| 48516 | Departed, The (2006) |
| 195159 | Spider-Man: Into the Spider-Verse (2018) |
| 122914 | Avengers: Infinity War – Part II (2019) |
| 91974 | Underworld: Awakening (2012) |
| 204698 | Joker (2019) |
获取热门推荐
在您使用
aws-trending-now 配方创建解决方案版本后,
Amazon Personalize 将通过计算每个项目在可配置的时间间隔内互动的增加量来识别最受欢迎的项目。增长率最高的项目被视为热门商品。时间基于互动数据集中的时间戳数据。
现在,让我们向 Amazon Personalize 提供最新的互动信息,以计算热门商品。我们可以通过创建
在这篇文章中,我们将以批量数据上传的形式提供最新的交互以及增量模式下的数据集导入任务。请使用以下 python 代码生成虚拟增量交互并使用数据集导入任务上传增量交互数据。
我们通过随机选择 USER_ID 和 ITEM
_ID 的几个值,并在这些用户
和带有最新时间
戳的物品
之间生成互动来合成这些交互作用。下表包含随机选择的
ITEM_ID
值,用于生成增量交互作用。
| ITEM_ID | TITLE |
| 153 | Batman Forever (1995) |
| 260 | Star Wars: Episode IV – A New Hope (1977) |
| 1792 | U.S. Marshals (1998) |
| 2363 | Godzilla (Gojira) (1954) |
| 2407 | Cocoon (1985) |
| 2459 | Texas Chainsaw Massacre, The (1974) |
| 3948 | Meet the Parents (2000) |
| 6539 | Pirates of the Caribbean: The Curse of the Bla… |
| 8961 | Incredibles, The (2004) |
| 61248 | Death Race (2008) |
通过选择 “
追加到当前数据集
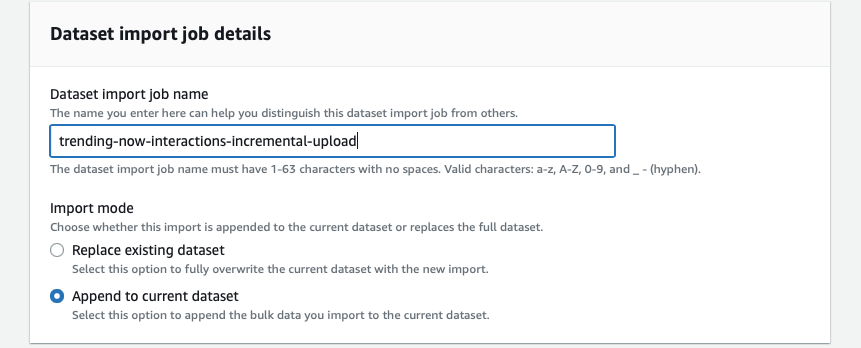
增量交互数据集的导入任务完成后,请等待您为新建议配置的趋势发现频率时间长度得到反映。
在广告活动 API 页面 上选择 获取 推荐,以获取最新的热门商品推荐列表。
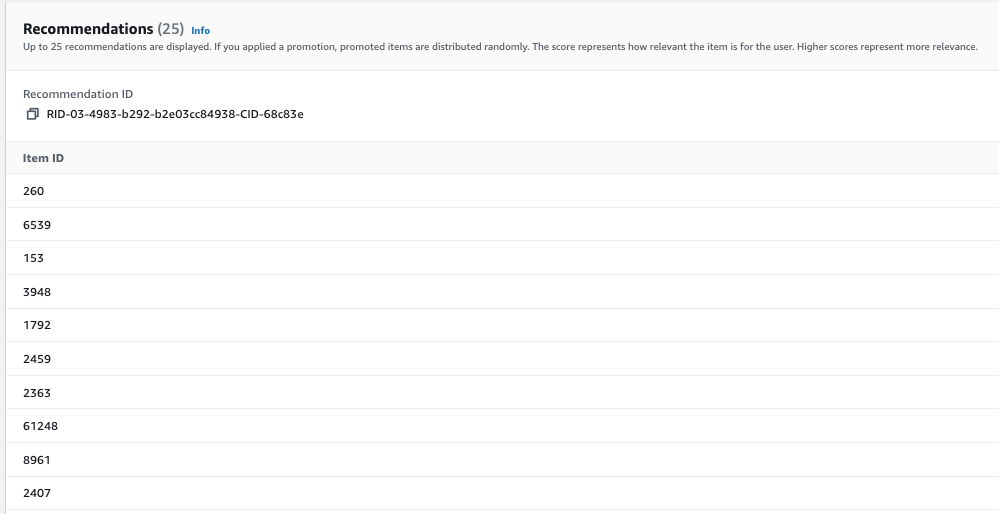
现在我们看到了最新的推荐物品清单。为了便于阅读,下表包含将 ID 映射到实际电影标题之后的数据。执行映射的代码在随附的笔记本中提供。
| ITEM_ID | TITLE |
| 260 | Star Wars: Episode IV – A New Hope (1977) |
| 6539 | Pirates of the Caribbean: The Curse of the Bla… |
| 153 | Batman Forever (1995) |
| 3948 | Meet the Parents (2000) |
| 1792 | U.S. Marshals (1998) |
| 2459 | Texas Chainsaw Massacre, The (1974) |
| 2363 | Godzilla (Gojira) (1954) |
| 61248 | Death Race (2008) |
| 8961 | Incredibles, The (2004) |
| 2407 | Cocoon (1985) |
前面的
getRecommandations 调用包括推荐
项目的 ID。现在我们看到推荐的
ITEM_ID
值来自我们提供给 Amazon Personalize 模型的增量互动数据集。这并不奇怪,因为这些是最近30分钟内从我们的合成数据集中获得交互的唯一项目。
现在,您已经成功训练了 Trending-Now 模型,以生成越来越受用户欢迎的商品推荐,并根据用户兴趣定制推荐。展望未来,你可以调整这段代码来创建其他推荐器。
您还可以将
清理
在执行本文中概述的步骤时,请务必清理在账户中创建的所有未使用资源。您可以通过
摘要
Ama zon Personalize 推
出的全新 aws-trending
-now 配方可帮助您识别迅速受到用户欢迎的商品,并针对用户兴趣的快速变化趋势量身定制推荐。
有关 Amazon Personalize 的更多信息,请参阅
作者简介
 Vamshi Krishna Enabothal
a 是 亚马逊云科技 的高级应用人工智能专家架构师。他与来自不同领域的客户合作,以加快高影响力的数据、分析和机器学习计划。他热衷于人工智能和机器学习中的推荐系统、自然语言处理和计算机视觉领域。工作之余,Vamshi 是一名遥控爱好者,负责制造遥控设备(飞机、汽车和无人机),还喜欢园艺。
Vamshi Krishna Enabothal
a 是 亚马逊云科技 的高级应用人工智能专家架构师。他与来自不同领域的客户合作,以加快高影响力的数据、分析和机器学习计划。他热衷于人工智能和机器学习中的推荐系统、自然语言处理和计算机视觉领域。工作之余,Vamshi 是一名遥控爱好者,负责制造遥控设备(飞机、汽车和无人机),还喜欢园艺。
 Anchit Gupta 是 Amazon P
ersonalize 的高级产品经理。她专注于提供可以更轻松地构建机器学习解决方案的产品。在业余时间,她喜欢做饭、玩棋盘/纸牌游戏和阅读。
Anchit Gupta 是 Amazon P
ersonalize 的高级产品经理。她专注于提供可以更轻松地构建机器学习解决方案的产品。在业余时间,她喜欢做饭、玩棋盘/纸牌游戏和阅读。
 Abhishek Mangal
是Amazon Personalize的软件工程师,致力于设计软件系统以大规模为客户提供服务。在业余时间,他喜欢看动画,并认为《海贼王》是近代历史上最伟大的叙事作品。
Abhishek Mangal
是Amazon Personalize的软件工程师,致力于设计软件系统以大规模为客户提供服务。在业余时间,他喜欢看动画,并认为《海贼王》是近代历史上最伟大的叙事作品。
 丁浩
是 亚马逊云科技 人工智能实验室的应用科学家,正在为 亚马逊云科技 Personalize 开发下一代推荐系统。他的研究兴趣在于推荐系统、贝叶斯深度学习和大型语言模型 (LLM)。
丁浩
是 亚马逊云科技 人工智能实验室的应用科学家,正在为 亚马逊云科技 Personalize 开发下一代推荐系统。他的研究兴趣在于推荐系统、贝叶斯深度学习和大型语言模型 (LLM)。
 刘天敏
是一名高级软件工程师,在亚马逊个性化部工作。他专注于使用各种机器学习算法大规模开发推荐系统。在业余时间,他喜欢玩电子游戏、看体育赛事和弹钢琴。
刘天敏
是一名高级软件工程师,在亚马逊个性化部工作。他专注于使用各种机器学习算法大规模开发推荐系统。在业余时间,他喜欢玩电子游戏、看体育赛事和弹钢琴。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。