我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
利用亚马逊云科技本地区域进行边缘推理,缩短 AI 对话响应时间
生成式人工智能的最新进展导致了由基础模型 (FM) 提供支持的新一代对话式人工智能助手的激增。这些延迟敏感型应用程序支持实时文本和语音交互,自然地响应人际对话。它们的应用涵盖多个领域,包括客户服务、医疗保健、教育、个人和企业生产力等。
对话式 AI 助手通常直接部署在用户的设备上,例如智能手机、平板电脑或台式计算机,从而可以对语音或文本输入进行快速的本地处理。但是,为助手的自然语言理解和响应生成提供支持的 FM 通常是云端托管的,在强大的 GPU 上运行。当用户与 AI 助手互动时,他们的设备首先在本地处理输入,包括语音代理的语音转文本 (STT),然后编译提示。然后,该提示将通过网络安全地传输到基于云的 FM。FM 会分析提示并开始生成相应的响应,将其流式传输回用户的设备。在将响应呈现给用户之前,设备会进一步处理该响应,包括语音代理的文本到语音转换 (TTS)。这种高效的工作流程在基于云的 FM 的强大功能与本地设备交互的便利性和响应性之间取得了平衡,如下图所示。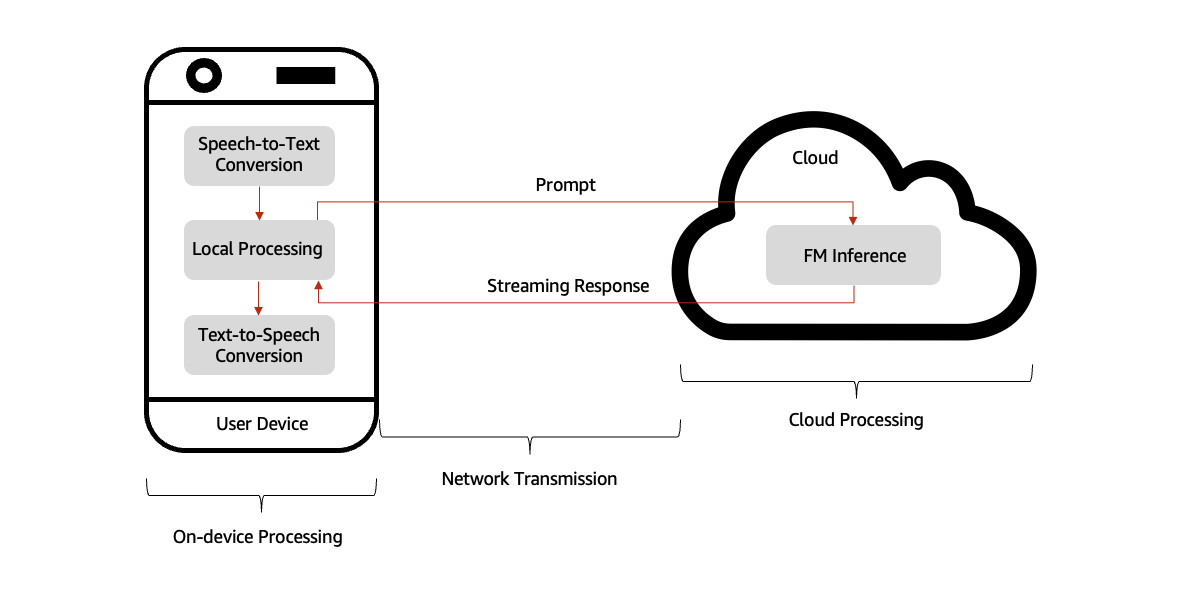
开发此类应用程序的一个关键挑战是减少响应延迟以实现实时、自然的交互。响应延迟是指从用户完成语音到开始听到 AI 助手的回应之间的时间。这种延迟通常包括两个主要组成部分:
- 设备端处理延迟 — 这包括本地处理所需的时间,包括 TTS 和 STT 操作。
- 第一个令牌时间 (TTFT) — 它衡量设备向云端发送提示与收到第一个响应令牌之间的间隔。TTFT 由两个组件组成。首先是网络延迟,即设备和云之间数据传输的往返时间。第二个是第一个令牌生成时间,即从 FM 收到完整提示到生成第一个输出令牌之间的时间。TTFT 对于使用响应流和 FM 的对话式 AI 界面的用户体验至关重要。使用响应流式传输,用户在响应仍在生成的时候就开始接收响应,从而显著改善了感知延迟。
一般认为,人际对话流程的理想响应延迟在 200—500 毫秒 (ms) 范围内,与人类对话中的自然停顿非常相似。考虑到额外的设备端处理延迟,实现该目标需要远低于 200 ms 的 TTFT。
尽管许多客户专注于通过模型优化、硬件加速和语义缓存等技术来优化 FM 推理端点背后的技术堆栈以降低 TTFT,但他们往往忽略了网络延迟的重大影响。由于用户和云服务之间的地理距离以及互联网连接质量的不同,这种延迟可能会有很大差异。
带有亚马逊云科技本地区域的混合架构
为了最大限度地减少网络延迟对用户无论身在何处 TTFT 的影响,可以通过将亚马逊云科技服务从商业区域扩展到更靠近最终用户的边缘站点来实施混合架构。这种方法包括在亚马逊云科技边缘服务上部署额外的推理终端节点,并使用 Amazon Route 53 来实施动态路由策略,例如地理位置路由、地理邻近路由或基于延迟的路由。这些策略在边缘站点和商业区域之间动态分配流量,根据实时网络状况和用户位置提供快速的响应时间。
亚马逊云科技本地区域是一种边缘基础设施部署,可将选定的亚马逊云科技服务置于人口众多和行业中心附近。它们支持需要极低延迟或使用熟悉的 API 和工具集进行本地数据处理的应用程序。每个本地区域都是相应的父亚马逊云科技区域的逻辑扩展,这意味着客户可以通过创建具有本地区域分配的新子网来扩展其亚马逊虚拟私有云 (Amazon VPC) 连接。
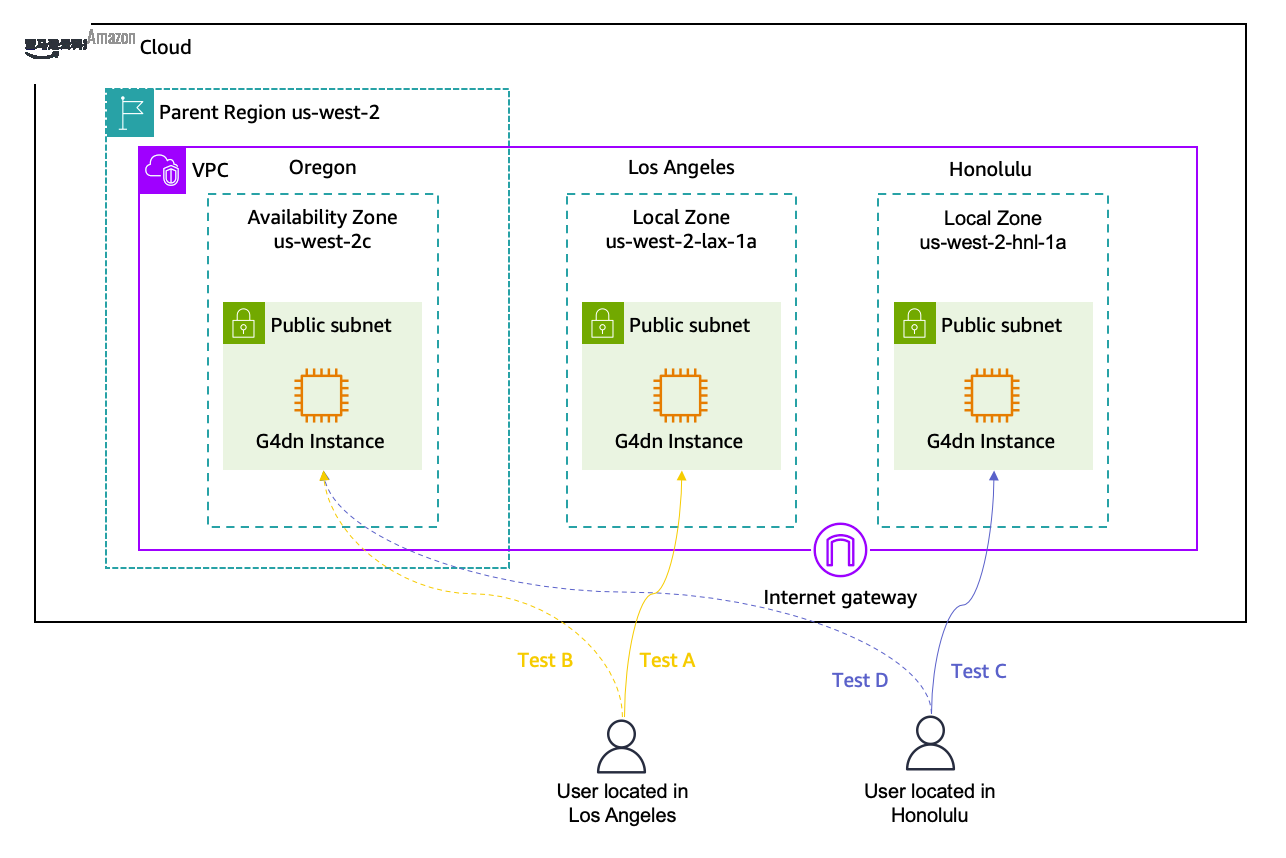
本指南演示如何在三个地点的 Amazon Elastic Compute Cloud(Amazon EC2)实例上部署 Hugging Face 的开源 FM:一个商用亚马逊云科技区域和两个亚马逊云科技本地区域。通过比较基准测试,我们说明在离最终用户更近的局域部署 FM 如何显著减少延迟,延迟是对话式人工智能助手等实时应用程序的关键因素。
先决条件
要运行此演示,请完成以下先决条件:
- 如果您还没有亚马逊云科技账户,请创建一个。
- 在父区域美国西部(俄勒冈)中启用洛杉矶和檀香山的本地区域。有关可用本地区域的完整列表,请参阅本地区域位置页面。接下来,在每个本地区域内创建一个子网。有关启用本地区域和在其中创建子网的详细说明,请参阅亚马逊云科技本地区域入门。
- 提交提高 Amazon EC2 服务配额的申请以访问 Amazon EC2 G4DN 实例。选择按需运行的 G 和 VT 实例作为配额类型,并选择至少 24 个 vCPU 作为配额大小。
- 从 huggingface.co/settings/tokens 创建 Hugging Face 读取令牌。
解决方案演练
本部分将引导您完成在洛杉矶本地区域启动 Amazon EC2 G4dn 实例和部署 FM 以进行推理的步骤。这些说明还适用于父区域、美国西部(俄勒冈)和檀香山本地区域的部署。
我们使用 Meta 的开源 Llama 3.2-3B 作为本次演示的 FM。这是一款来自 Llama 3.2 系列的轻量级 FM,由于其参数数量很少,被归类为小型语言模型 (SLM)。与大型语言模型 (LLM) 相比,SLM 的训练和部署效率更高,更具成本效益,在针对特定任务进行微调时表现出色,推理时间更短,资源要求更低。这些特性使得 SLM 特别适合在亚马逊云科技本地区域等边缘服务上部署。
要在洛杉矶本地区域子网中启动 EC2 实例,请执行以下步骤:
- 在 Amazon EC2 控制台控制面板的启动实例框中,选择启动实例。
- 在名称和标签下,输入实例的描述性名称(例如,la-local-zone-instance)。
- 在 "应用程序和操作系统映像(亚马逊机器映像)" 下,选择预先配置了 NVIDIA OSS 驱动程序和 PyTorch 的亚马逊云科技深度学习 AMI。在部署中,我们使用了深度学习 OSS Nvidia 驱动程序 AMI GPU PyTorch 2.3.1(亚马逊 Linux 2)。
- 在实例类型下,从实例类型列表中选择本地区域支持的实例的硬件配置。我们选择
G4dn.2xlarge了这个解决方案。该实例配备了一个 NVIDIA T4 Tensor Core GPU 和 16 GB 的 GPU 内存,这使其非常适合在边缘对 SLM 进行高性能和具有成本效益的推断。每个本地区域的可用实例类型可在亚马逊云科技本地区域功能中找到。查看您的 FM 的硬件要求以选择相应的实例。 - 在 "密钥对(登录)" 下,选择现有密钥对或创建新的密钥对。
- 在 "网络设置" 旁边,选择 "编辑",然后:
- 选择您的 VPC。
- 选择您的本地区域子网。
- 创建安全组或选择现有安全组。将安全组的入站规则配置为仅允许端口 8080 上来自客户端 IP 地址的流量。
- 您可以保留实例其他配置设置的默认选择。要确定支持的存储类型,请参阅亚马逊云科技本地区域功能中的计算和存储部分。
- 在摘要面板中查看您的实例配置摘要,准备就绪后,选择启动实例。
- 确认页面让您知道您的实例正在启动。选择 "查看所有实例" 以关闭确认页面并返回控制台。
接下来,完成以下步骤,使用 Hugging Face 文本生成推断 (TGI) 作为模型服务器部署 Llama 3.2-3B:
- 使用安全外壳 (SSH) 连接到实例
- 使用以下命令启动 docker 服务。它预装了我们选择的 AMI。
- 运行以下命令下载并运行 TGI 服务器和 Llama 3.2-3B 模型的 Docker 镜像。在我们的部署中,我们使用了 Docker 镜像版本 2.4.0,但结果可能会因您选择的版本而异。TGI 支持的型号的完整列表可在 Hugging Face 支持的型号中找到。有关 TGI 部署和优化的更多详细信息,请参阅此文本生成推理 GitHub 页面。
- TGI 容器运行后,您可以通过从本地环境运行以下命令来测试您的终端节点:
 Nima Seifi 是亚马逊云科技的解决方案架构师,总部位于南加州,专门研究 SaaS 和 LLMOps。他担任基于亚马逊云科技的初创公司的技术顾问。在加入亚马逊云科技之前,他在电子商务行业担任 DevOps 架构师超过 5 年,此前他在移动互联网技术领域进行了十年的研发工作。Nima 撰写了 20 多份技术出版物,拥有 7 项美国专利。工作之余,他喜欢阅读、看纪录片和在海滩散步。
Nima Seifi 是亚马逊云科技的解决方案架构师,总部位于南加州,专门研究 SaaS 和 LLMOps。他担任基于亚马逊云科技的初创公司的技术顾问。在加入亚马逊云科技之前,他在电子商务行业担任 DevOps 架构师超过 5 年,此前他在移动互联网技术领域进行了十年的研发工作。Nima 撰写了 20 多份技术出版物,拥有 7 项美国专利。工作之余,他喜欢阅读、看纪录片和在海滩散步。 Nelson Ong 是亚马逊云科技的解决方案架构师。他与各行各业的早期初创公司合作,以加快他们的云采用。
Nelson Ong 是亚马逊云科技的解决方案架构师。他与各行各业的早期初创公司合作,以加快他们的云采用。*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。