我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用用于因果机器学习的开源 Python 库 doWhy 进行根本原因分析
找出复杂系统中观察到的变化的根本原因可能是一项艰巨的任务,既需要深入的领域知识,也需要数小时的手动工作。例如,我们可能想分析在线商店中销售的产品的利润意外下降,其中各种相互交织的因素可能会以微妙的方式影响产品的整体利润。
如果我们有自动化工具来简化和加速这项任务,那不是很好吗?一个可以通过几行代码自动识别观测到的效果的根本原因的库?
这就是
在本文中,我们将仔细研究这些算法。具体而言,我们想证明它们在复杂系统根本原因分析中的适用性。
将 DoWhy 的因果机器学习算法应用于此类问题可以显著缩短找到根本原因的时间。为了演示这一点,我们将深入研究一个基于随机生成的合成数据的示例场景,在该场景中,我们知道基本真相。
该场景
假设我们在一家在线商店出售一部零售价为999美元的智能手机。该产品的总体利润取决于多个因素,例如销售单位的数量、运营成本或广告支出。另一方面,例如,已售单位的数量取决于产品页面上的访问者数量、价格本身以及潜在的持续促销活动。假设我们在2021年观察到我们的产品稳步盈利,但是突然之间,2022年初的利润大幅下降。为什么?
在以下场景中,我们将使用doWhy来更好地了解影响利润的因素的因果影响,并确定利润下降的原因。要分析我们眼前的问题,我们首先需要定义我们对因果关系的信念。为此,我们收集影响利润的不同因素的 每日 记录。这些因素是:
- 购物活动? :表示是否发生了特殊购物活动的二进制值,例如黑色星期五或网络星期一的促销。
- 广告支 出 :广告活动支出。
- 页面浏览 量 :商品详情页面的访问次数。
- 单价 :设备价格,可能因临时折扣而有所不同。
- 已售单位 :已售手机的数量。
- 收入 :每日收入。
- 运营成本 :每日运营费用,包括制作成本、广告支出、管理费用等。
- 利润 :每日利润。
通过查看这些属性,我们可以利用我们的领域知识以有向无环图的形式描述因果关系,该图在下文中代表我们的因果图。该图如下所示:
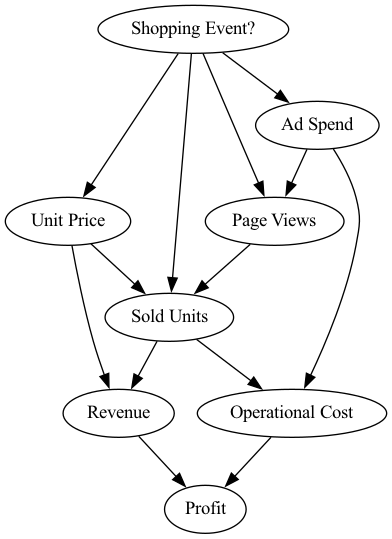
此图中从 X 到 Y、X → Y 的箭头描述了一种直接的因果关系,其中 X 是 Y 的原因。在这种情况下,我们知道以下几点:
购物活动?
影响:
→
广告支出
:为了在特殊购物活动中推广产品,我们需要额外的广告支出。
→
页面浏览量
:由于折扣和各种优惠,购物活动通常会吸引大量访客光顾在线零售商。
→
单价
:通常,零售商在购物活动的日子会比通常的零售价提供一些折扣。
→
已售单位
:购物活动通常在圣诞节、父亲节等年度庆祝活动期间举行,人们购买的商品通常比平时多。
广告支出
影响:
→
页面
浏览量
:我们在广告上花费的越多,人们访问产品页面的可能性就越大。
→
运营成本
:广告支出是运营成本的一部分。
页面浏览
量 影响:
→
已售单位
:访问商品页面的人越多,商品被购买的可能性就越大。很明显,如果没有人访问该页面,就不会有任何销售。
单价
影响:
→
已售单位
:价格越高/越低,售出的单位越少/越多。
→
收入
:每日收入通常由已售单位数量和单价的乘积组成。
已售单位
的影响:
→
已售单位
:与以前的论点相同,已售单位的数量会严重影响收入。
→
运营成本
:我们生产和销售的每个单位都有制造成本。我们出售的单位越多,收入就越高,但制造成本也越高。
运营成本
影响:
→
利
润 :利润基于产生的收入减去运营成本。
收入
影响:
→
利润
:与运营成本的原因相同。
步骤 1:定义因果模型
现在,让我们使用 DoWhy 的图形因果关系模型 (GCM) 模块对这些因果关系进行建模。
在第一步中,我们需要定义一个所谓 的
为了对图形结构进行建模,我们使用了流行的开源 Python 图形库
import networkx as nx
causal_graph = nx.DiGraph([('Page Views', 'Sold Units'),
('Revenue', 'Profit'),
('Unit Price', 'Sold Units'),
('Unit Price', 'Revenue'),
('Shopping Event?', 'Page Views'),
('Shopping Event?', 'Sold Units'),
('Shopping Event?', 'Unit Price'),
('Shopping Event?', 'Ad Spend'),
('Ad Spend', 'Page Views'),
('Ad Spend', 'Operational Cost'),
('Sold Units', 'Revenue'),
('Sold Units', 'Operational Cost'),
('Operational Cost', 'Profit')])
接下来,我们来看看2021年的数据:
import pandas as pd
pd.options.display.float_format = '${:,.2f}'.format # Format dollar columns
data_2021 = pd.read_csv('2021 Data.csv', index_col='Date')
data_2021.head()
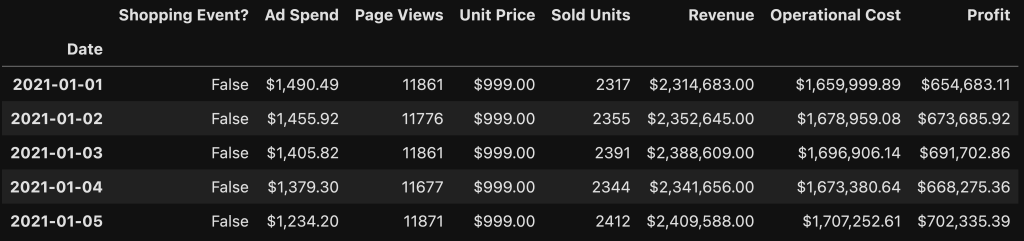
正如我们所见,我们在2021年每天都有一个样本,所有变量都在因果图中。请注意,在我们在这篇博客文章中考虑的合成数据中,购物活动也是随机生成的。
我们定义了因果图,但我们仍然需要为节点分配生成模型。使用 DoWhy,我们可以手动指定这些模型,并在需要时对其进行配置,也可以使用数据中的启发式方法自动推断 “合适的” 模型。我们将在这里利用后者:
from dowhy import gcm # Create the structural causal model object scm = gcm.StructuralCausalModel(causal_graph) # Automatically assign generative models to each node based on the given data gcm.auto.assign_causal_mechanisms(scm, data_2021)
只要有可能,我们建议根据先验知识来分配模型,因为这样模型将非常接近该领域的物理特性,而不是依赖数据的细微差别。但是,在这里我们要求DoWhy为我们做这件事。
步骤 2:将因果模型与数据拟合
为每个节点分配模型后,我们需要学习模型的参数:
gcm.fit(scm, data_2021)
拟
合
方法学习每个节点中生成模型的参数。合适的 SCM 现在可以用来回答不同类型的因果问题。
第 3 步:回答因果问题
影响利润差异的关键因素是什么?
此时,我们想了解哪些因素推动了利润的变化。让我们首先仔细看看一段时间内的利润。为此,我们使用
data_2021['Profit'].plot(ylabel='Profit in $', figsize=(15,5), rot=45)
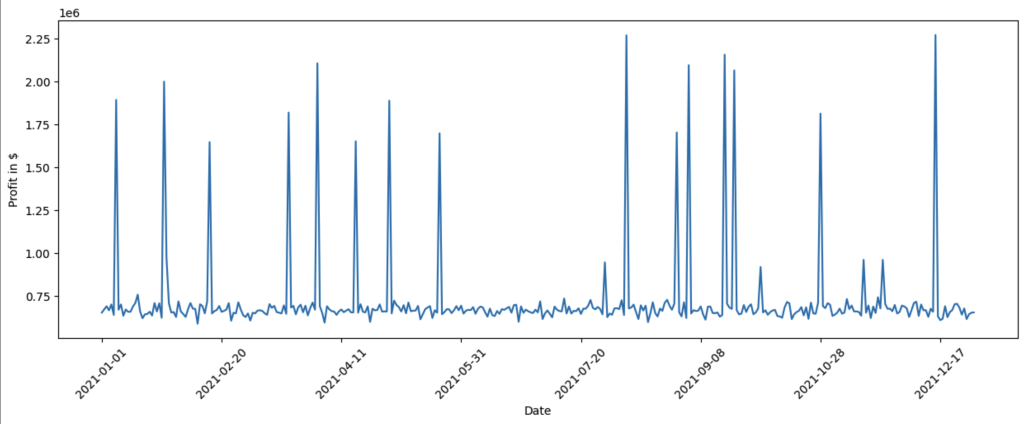
我们看到全年利润大幅增长。我们可以通过查看标准差来进一步量化这一点,我们可以使用 pandas 的
std ()
函数进行估计:
data_2021['Profit'].std()
259247.66010978
估计的标准差约为259247美元,相当可观。从因果图来看,我们发现收入和运营成本对利润有直接影响,但是其中哪一个对差异的影响最大?为了找出答案,我们可以使用
import numpy as np
def convert_to_percentage(value_dictionary):
total_absolute_sum = np.sum([abs(v) for v in value_dictionary.values()])
return {k: abs(v) / total_absolute_sum * 100 for k, v in value_dictionary.items()}
arrow_strengths = gcm.arrow_strength(scm, target_node='Profit')
gcm.util.plot(causal_graph,
causal_strengths=convert_to_percentage(arrow_strengths),
figure_size=[15, 10])
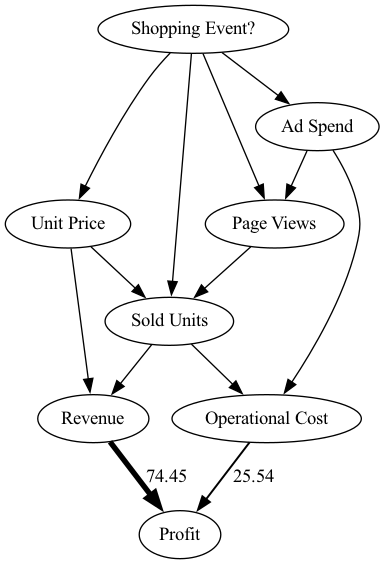
在此因果图中,我们可以看到每个节点对利润方差的贡献有多大。为简单起见,捐款被转换为百分比。由于利润本身只是收入和运营成本之间的差异,因此我们预计不会有其他因素影响差异。正如我们所见,收入贡献了74.45%,比运营成本的影响更大,后者占25.54%。这是有道理的,因为对已售单位数量的依赖性更强,收入的变化通常大于运营成本。请注意,doWhy 还支持其他类型的衡量标准,例如
尽管直接影响有助于理解哪些直系父母对利润差异的影响最大,但这在很大程度上证实了我们先前的信念。但是,目前尚不清楚哪个因素是造成这种高方差的最终原因。收入本身仅基于已售单位和单价。尽管我们可以递归地将直接箭强度应用于所有节点,但我们无法正确地了解上游节点对方差的影响。
导致利润差异的重要因果因素是什么?为了找出答案,我们可以使用DoWhy的
import matplotlib.pyplot as plt
def bar_plot(value_dictionary, ylabel, uncertainty_attribs=None, figsize=(8, 5)):
value_dictionary = {k: value_dictionary[k] for k in sorted(value_dictionary)}
if uncertainty_attribs is None:
uncertainty_attribs = {node: [value_dictionary[node], value_dictionary[node]] for node in value_dictionary}
_, ax = plt.subplots(figsize=figsize)
ci_plus = [uncertainty_attribs[node][1] - value_dictionary[node] for node in value_dictionary.keys()]
ci_minus = [value_dictionary[node] - uncertainty_attribs[node][0] for node in value_dictionary.keys()]
yerr = np.array([ci_minus, ci_plus])
yerr[abs(yerr) < 10**-7] = 0
plt.bar(value_dictionary.keys(), value_dictionary.values(), yerr=yerr, ecolor='#1E88E5', color='#ff0d57', width=0.8)
plt.ylabel(ylabel)
plt.xticks(rotation=45)
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
plt.show()
iccs = gcm.intrinsic_causal_influence(scm, target_node='Profit', num_samples_randomization=500)
bar_plot(convert_to_percentage(iccs), ylabel='Variance attribution in %')
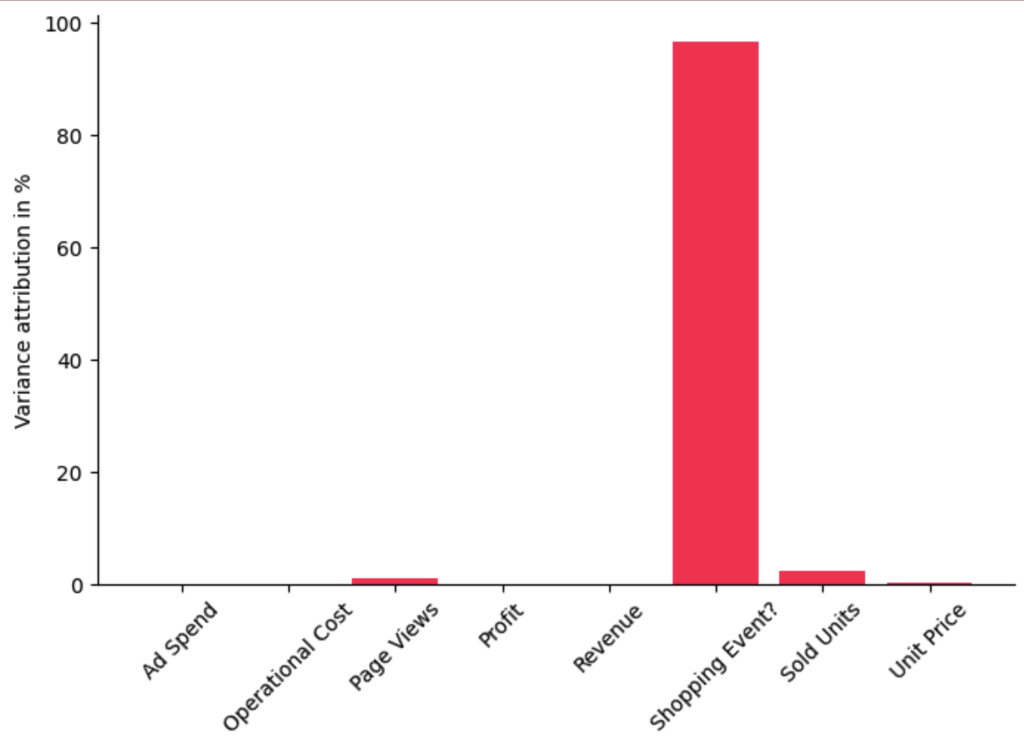
此条形图中显示的分数是百分比,表示每个节点为利润贡献了多少方差,但没有继承因果图中其父节点的方差。正如我们清楚地看到的那样,迄今为止,购物活动对我们利润差异的影响最大。这是有道理的,因为在黑色星期五或Prime Day等促销期间,销售受到严重影响,因此会影响整体利润。令人惊讶的是,我们还看到,诸如销售单位数量或页面浏览量之类的因素的影响相当小,也就是说,购物活动几乎可以完全解释利润的巨大差异。让我们通过标记我们举办购物活动的日子来直观地检查一下。为此,我们再次使用 pandas plot 函数,但另外在发生购物活动的地方用红色垂直条标记图中的所有点:
data_2021['Profit'].plot(ylabel='Profit in $', figsize=(15,5), rot=45) plt.vlines(np.arange(0, data_2021.shape[0])[data_2021['Shopping Event?']], data_2021['Profit'].min(), data_2021['Profit'].max(), linewidth=10, alpha=0.3, color='r')
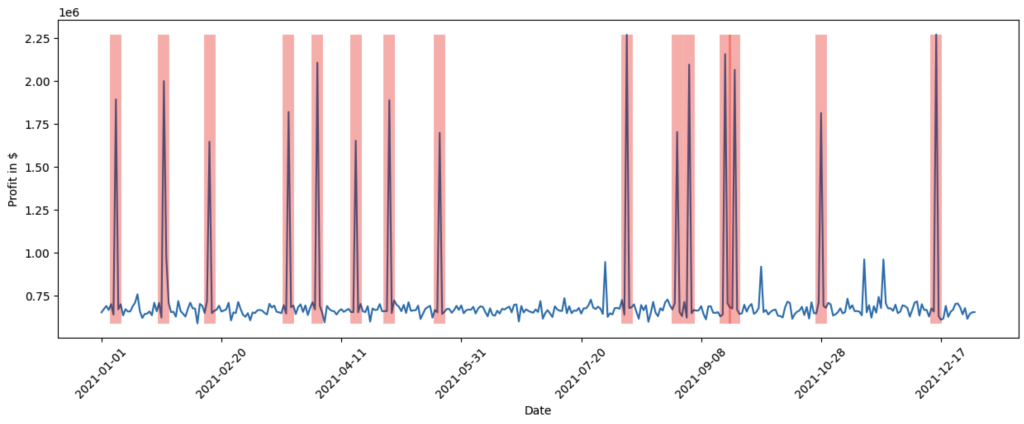
我们清楚地看到,购物活动恰逢利润的最高峰期。虽然我们可以通过查看各种不同的关系或使用领域知识来手动调查这个问题,但随着系统复杂性的增加,任务变得更加困难。通过几行代码,我们从 DoWhy 那里获得了这些见解。
解释特定日期利润下降的关键因素是什么?
在利润方面取得成功的一年之后,新技术进入市场,因此,我们希望通过销售更多设备来保持利润并摆脱多余的库存。因此,为了增加需求,我们在2022年初将零售价格降低了10%。根据先前的分析,我们知道价格下跌10%将大致使需求增加13.75%,略有盈余。根据
first_day_2022 = pd.read_csv('2022 First Day.csv', index_col='Date')
(first_day_2022['Sold Units'][0] / data_2021['Sold Units'][0] - 1) * 100
18.946914113077252
令人惊讶的是,我们的售出单位数量仅增加了约19%。鉴于收入远低于预期,这肯定会影响利润。让我们同时将其与上一年进行比较:
(1 - first_day_2022['Profit'][0] / data_2021['Profit'][0]) * 100
8.57891513840979
事实上,利润下降了约8.5%。既然价格下跌我们预计需求会大大增加,为什么会出现这种情况?让我们调查一下这里发生了什么。
为了弄清楚是什么原因导致了利润下降,我们可以利用 DoWhy 的
attributions = gcm.attribute_anomalies(scm, target_node='Profit', anomaly_samples=first_day_2022)
bar_plot({k: v[0] for k, v in attributions.items()}, ylabel='Anomaly attribution score')
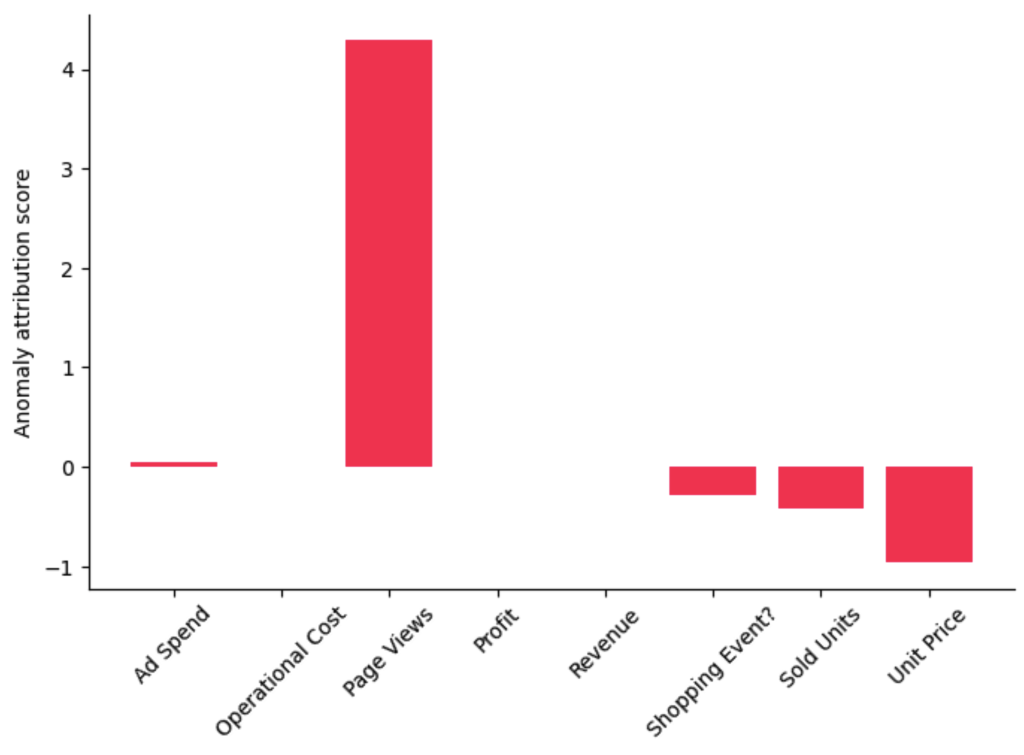
正的归因分数意味着相应的节点促成了观测到的异常,在我们的例子中就是利润的下降。节点的负分表示该节点的观测值实际上降低了出现异常的可能性(例如,由于价格下跌而导致的需求增加应该会增加利润)。有关分数解释的更多详细信息可以在我们的
虽然这种方法可以让我们对所学的特定模型和参数的属性进行点估计,但我们也可以使用 DoWhy 的 置信区间 功能,该功能包含了拟合模型参数和算法近似值的不确定性:
median_attributions, confidence_intervals, = gcm.confidence_intervals(
gcm.fit_and_compute(gcm.attribute_anomalies,
scm,
bootstrap_training_data=data_2021,
target_node='Profit',
anomaly_samples=first_day_2022),
num_bootstrap_resamples=10)
bar_plot(median_attributions, 'Anomaly attribution score', confidence_intervals)
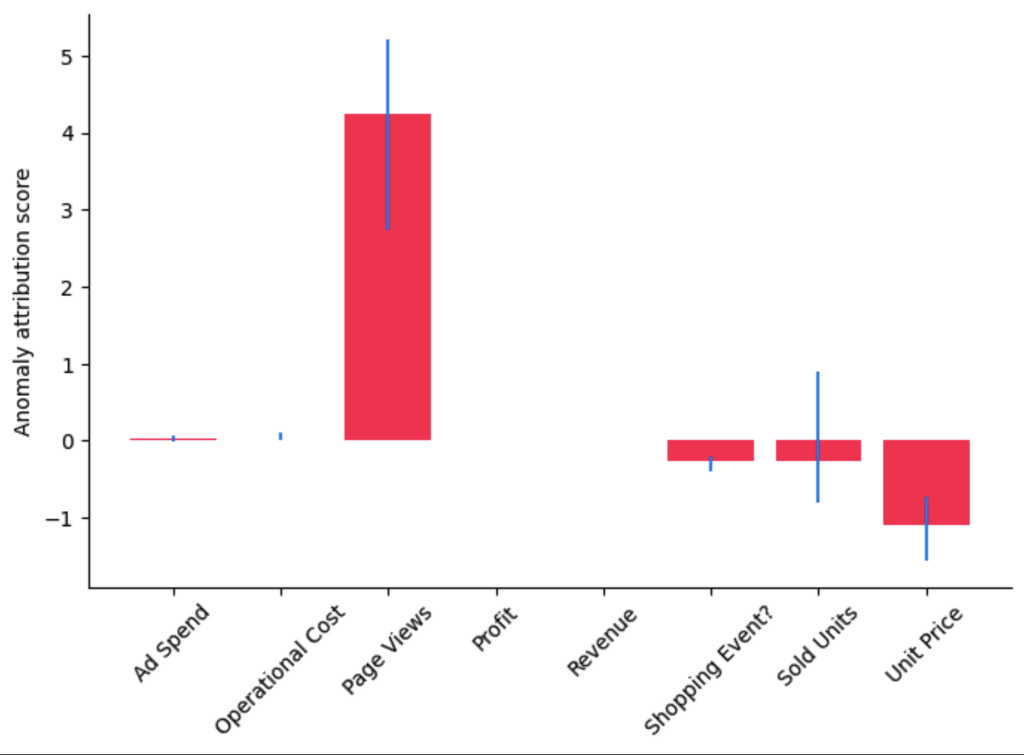
注意,在此条形图中,我们可以看到在较小的数据集上进行多次运行的中位数归因,其中每次运行都会重新拟合模型并重新评估属性。我们得到的画面与以前类似,但已售单位归因的置信区间也为零,这意味着其贡献微不足道。但是仍然存在一些重要问题:这仅仅是巧合吗?如果不是,我们系统的哪一部分发生了变化?为了找出答案,我们需要收集更多的数据。
是什么导致了2022年第一季度的利润下降?
虽然先前的分析基于单一观察,但让我们看看这是否只是巧合,还是这是一个持续存在的问题。在准备季度业务报告时,我们还有前三个月的更多数据可用。我们首先检查2022年第一季度的利润是否与2021年相比平均有所下降。与以前类似,我们可以通过计算2022年和2021年第一季度平均利润之间的分数来做到这一点:
data_first_quarter_2021 = data_2021[data_2021.index <= '2021-03-31']
data_first_quarter_2022 = pd.read_csv("2022 First Quarter.csv", index_col='Date')
(1 - data_first_quarter_2022['Profit'].mean() / data_first_quarter_2021['Profit'].mean()) * 100
13.0494881794224
事实上,利润下降在2022年第一季度持续存在。现在,其根本原因是什么?让我们应用 DoWhy 的
median_attributions, confidence_intervals = gcm.confidence_intervals(
lambda: gcm.distribution_change(scm,
data_first_quarter_2021,
data_first_quarter_2022,
target_node='Profit',
# Here, we are intersted in explaining the differences in the mean.
difference_estimation_func=lambda x, y: np.mean(y) - np.mean(x))
)
bar_plot(median_attributions, 'Profit change attribution in $', confidence_intervals)
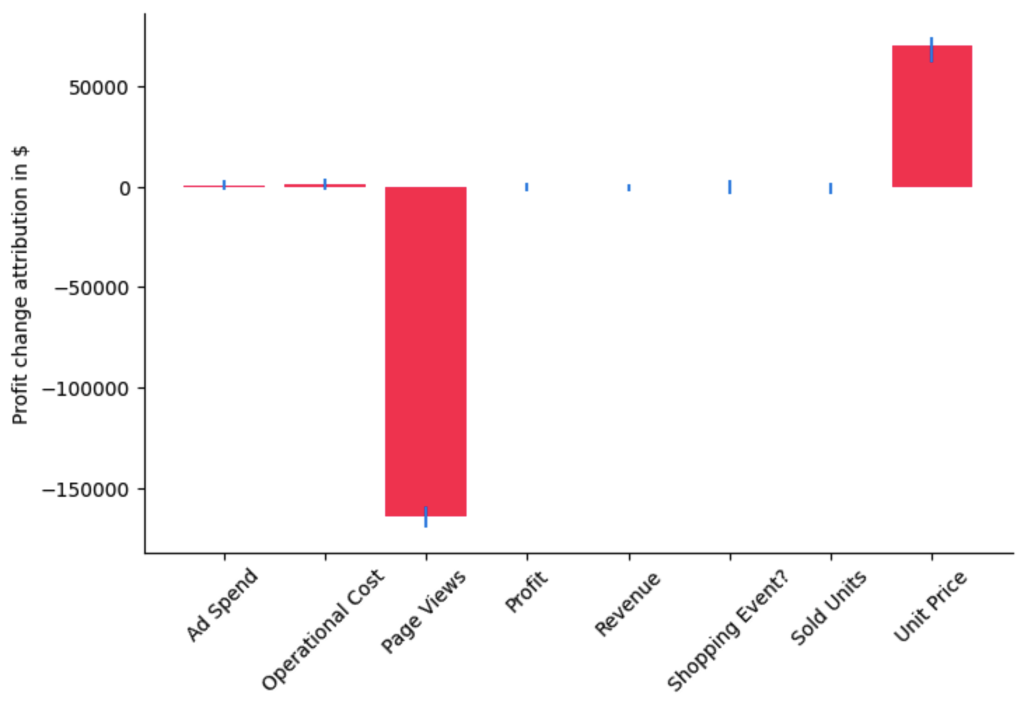
在本例中,分布变化法解释了利润均值的变化,即负值表示节点对均值的增加做出了贡献,正值表示平均值的增加。使用条形图,我们现在可以非常清楚地看到,由于已售单位的增加,单价的变化实际上对预期利润的贡献略为正数,但问题似乎出在页面浏览量为负值。尽管我们已经将其理解为2022年初下降的主要驱动力,但我们现在已经发现并确认页面浏览量也有所变化。让我们比较一下平均页面浏览量与上一年的平均页面浏览量。
(1 - data_first_quarter_2022['Page Views'].mean() / data_first_quarter_2021['Page Views'].mean()) * 100
14.347627108364
实际上,页面浏览量下降了约14%。由于我们消除了所有其他潜在因素,因此我们现在可以更深入地研究页面浏览量,看看那里发生了什么。这是一个假设情景,但我们可以想象,这可能是由于搜索算法的变化导致该产品在结果中的排名较低,因此吸引了较少的客户访问产品页面。知道了这一点,我们现在可以开始缓解这个问题了。
在DoWhy的图形因果关系模型新功能的帮助下,我们只需要几行代码就能自动查明特定异常值的主要驱动因素,尤其是能够识别导致分布变化的主要因素。
结论
在本文中,我们展示了DoWhy如何帮助分析示例在线商店利润下降的根本原因。为此,我们研究了 DoWhy 特征,例如箭头优势、内在因果影响、异常归因和分布变化归因。但是你知道吗,doWhy还可用于估计平均治疗效果、因果结构学习、因果结构诊断、干预措施和反事实?如果您对此感兴趣,我们邀请您访问我们的
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。