我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Amazon Redshift 扩展读写工作负载
到目前为止,并发扩展仅支持读取查询的自动扩展;写入查询必须在主集群上运行。现在,我们正在扩展并发扩展以支持常见写入查询(包括复制、插入、更新和删除)的自动扩展。这在支持并发扩展的区域的
在这篇文章中,我们将讨论如何启用并发扩展,以便在减少排队时间的情况下为数据加载、ETL(提取、转换和加载)和数据处理等并发工作负载提供一致的 SLA。
并发扩展概述
通过并发扩展,Amazon Redshift 可自动弹性地扩展查询处理能力,为数百个并发查询提供持续的快速性能。随着并发性的增加,并发扩展资源会在几秒钟内透明地添加到您的 Amazon Redshift 集群中,从而在无需等待时间的情况下以快速性能处理突然激增的并发请求。当工作负载需求减弱时,Amazon Redshift 会自动关闭并发扩展资源以节省成本。
下图显示了并发扩展在高层次上的工作原理。
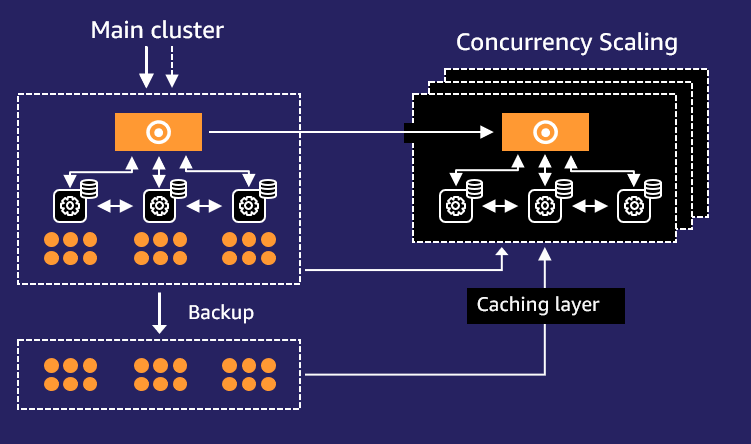
该工作流程包含以下步骤:
- 所有查询都转到主集群。
- 当指定工作负载管理 (WLM) 队列中的查询开始排队时,Amazon Redshift 会自动将符合条件的查询路由到新集群,从而实现并发扩展。
- Amazon Redshift 会自动启动新集群,处理等待的查询,并在不再需要时关闭并发扩展集群。
启用亚马逊 Redshift 并发扩展
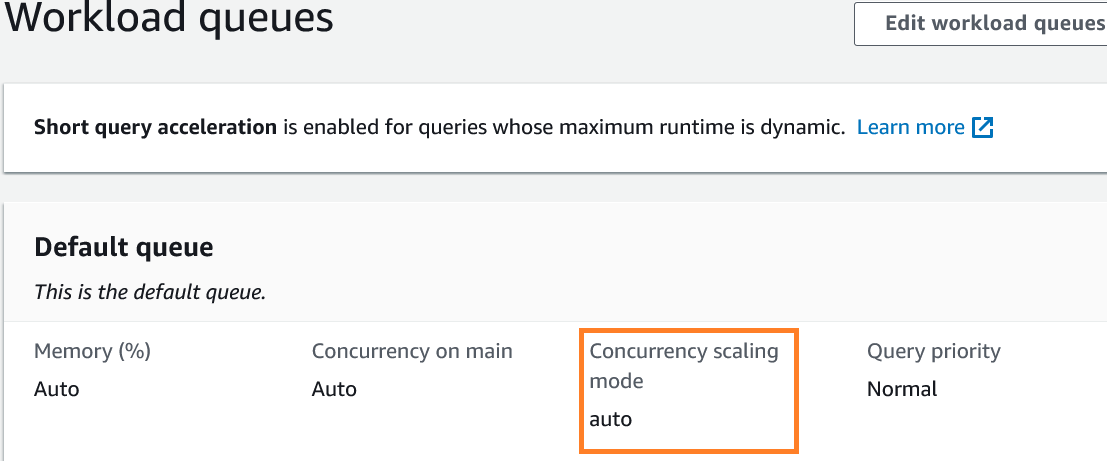
您可以在 WLM 队列级别管理并发扩展,在其中可以为特定队列设置并发扩展策略。为队列启用并发扩展后,符合条件的写入和读取查询将发送到并发扩展集群,而不必等待 Amazon Redshift 主集群上的资源腾出。Amazon Redshift 负责启动并发扩展集群、将查询路由到临时集群以及放弃并发集群。
您可以在
您首先需要确定您的集群是哪个参数组。为此,请完成以下步骤:
- 在 Amazon Redshift 控制台上, 在导航窗格中选择 集群 。
-
选择您的集群。
-
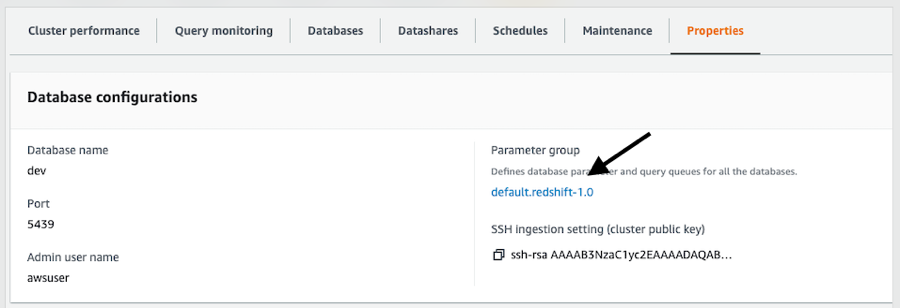
在
属性
选项卡上,记下与集群关联的参数组。
- 在导航窗格 中的 配置 下,选择 工作负载管理 。
-
选择与集群关联的参数组。如果您使用的是默认参数组 default.redshift-1.0,则需要创建自定义参数组并将其分配给集群。 默认参数组的每个参数都有预设值,并且无法修改。 -
在
参数
选项卡上,您可以在 1—10 个
max_concurrency_scaling_clusters 之间进行选择。 这是您可以同时运行的最大并发 Amazon Redshift 集群数量。十是软限制;可以通过提交带有支持案例的服务限制提高请求来提高此限制。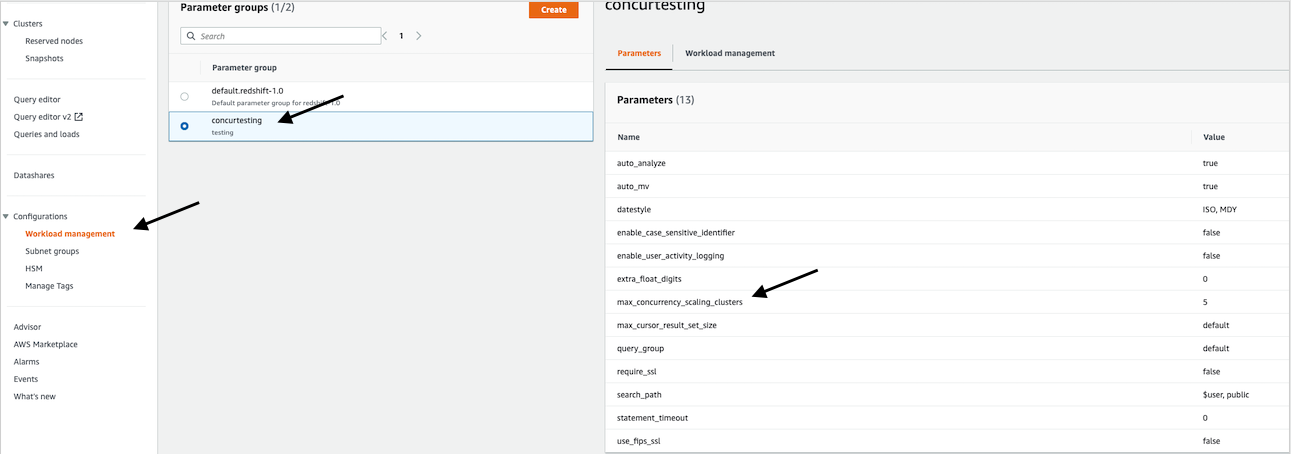
-
在
工作负载管理
选项卡上,为并发扩展集群选择
自动
模式。
用例示例
在本节中,我们使用三个用例来帮助您了解读写密集型工作负载的并发扩展如何无缝扩展以提高工作负载性能 SLA。
我们使用了 3 TB 的
以下场景展示了读取和写入的并发扩展如何无缝自动扩展并发繁重的混合工作负载:
- 所有查询均在关闭并发扩展的情况下同时触发
- 所有查询同时触发,并发扩展集群限制设置为 5 个集群
- 所有查询同时触发,并发扩展集群限制设置为 10 个集群
场景 1:在关闭并发扩展的情况下同时触发所有查询
在此基准测试中,所有查询均在 299 分钟内完成。以下是测试细节。
以下屏幕截图显示了 Amazon Redshift 自动 WLM 模式如何选择在排队其余查询时同时运行 16 个查询。由于并发扩展已关闭,因此不会启动其他集群,查询会继续等待正在运行的查询完成后才能进行处理。请注意,排队的查询数量在很长一段时间内一直保持在较高的数字,最终由于只有几个查询可以同时运行而降低。
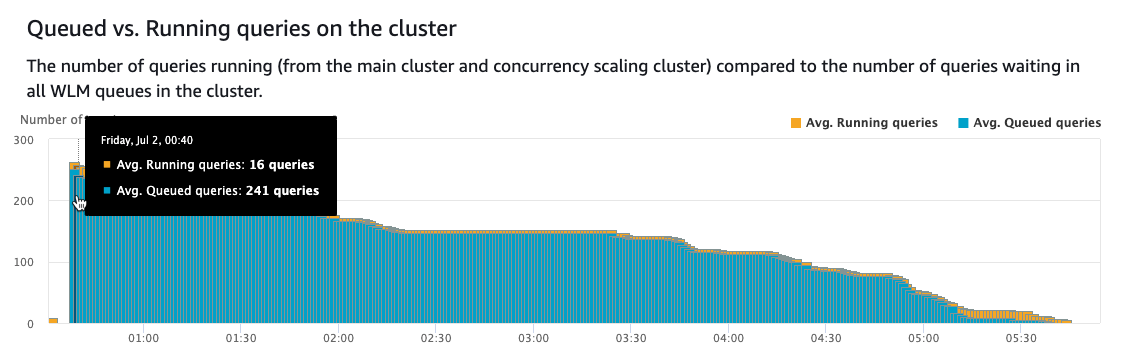
如以下屏幕截图所示,在工作负载窗口内没有其他并发集群启动,需要主集群处理所有查询。
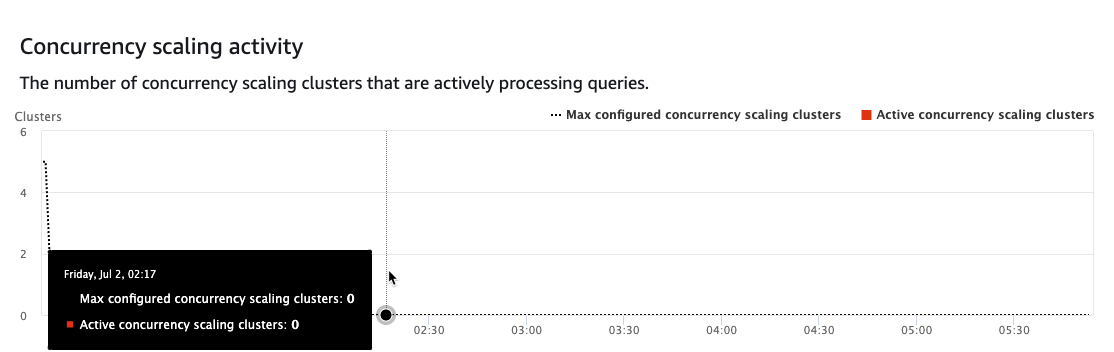
场景 2:所有查询同时触发,并发扩展集群的最大限制设置为 5 个集群
在此测试中,所有查询均在 49 分钟内完成。
以下屏幕截图描绘了大量排队。在几秒钟内,另外五个 Amazon Redshift 集群将启动到就绪状态,允许 53 个查询同时运行。此数字可能会根据查询类型在您的集群中发生变化。请注意,随着使用另外五个集群完成更多查询,排队的查询数量开始减少。
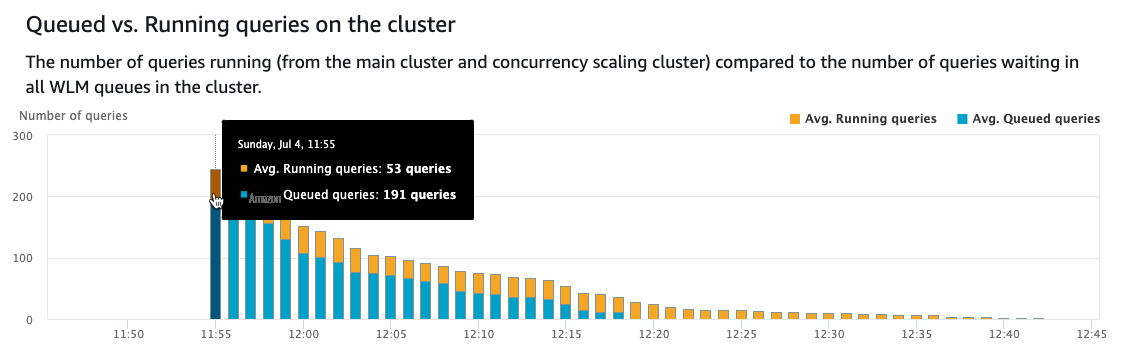
随着时间的推移,由于查询不再等待,并发扩展集群开始逐渐减少到 0。
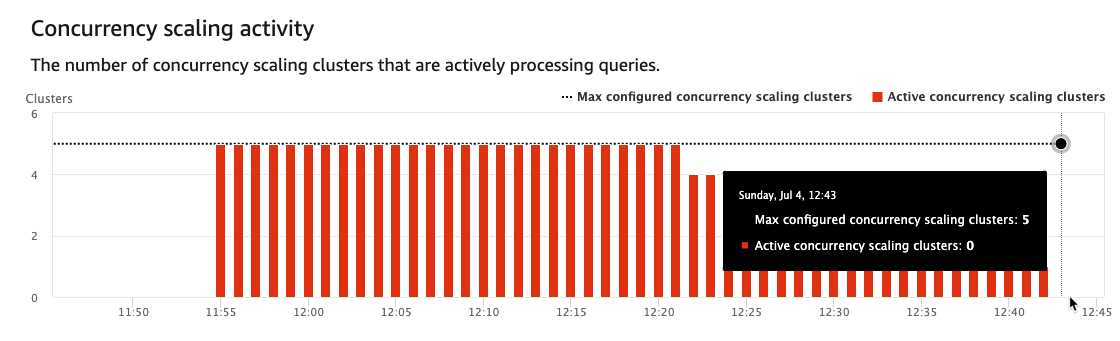
场景 3:所有查询同时触发,并发扩展集群限制设置为 10 个集群
在此测试中,所有查询均在 28 分钟内完成。
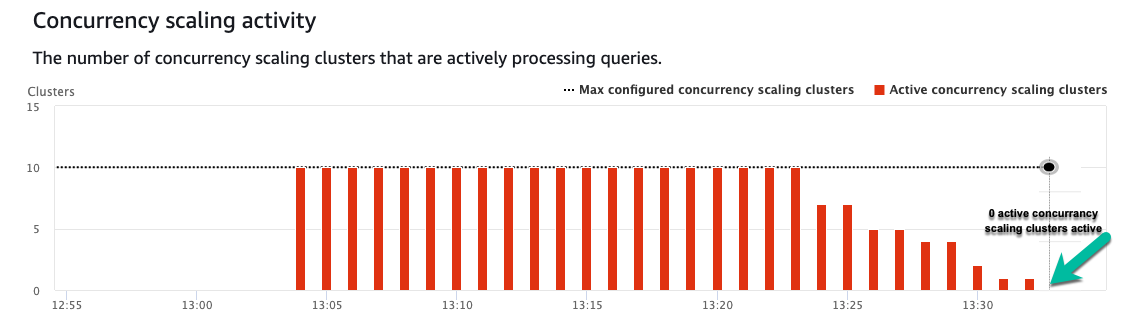
以下屏幕截图描绘了大量排队。在几秒钟内,另外 10 个 Amazon Redshift 集群将启动到就绪状态,允许多个查询同时运行。此数字可能会根据查询类型在您的集群中发生变化。请注意,随着使用另外五个集群完成更多查询,排队的查询数量开始减少。
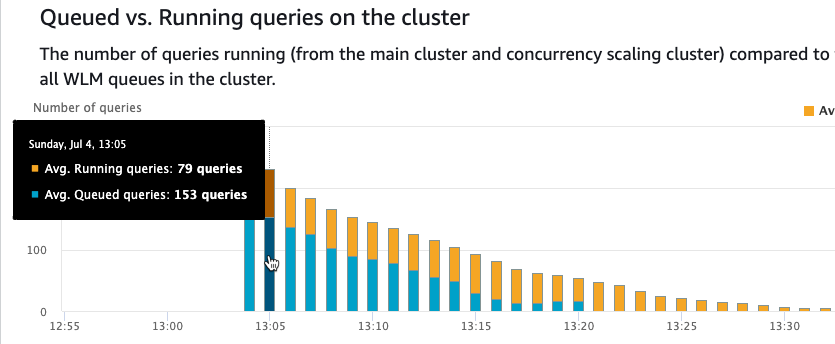
随着时间的推移,由于查询不再等待,并发扩展集群开始逐渐减少到 0。
测试结果审查
下表总结了我们的测试结果。
| . | Test Scenario 1 | Test Scenario 2 | Test Scenario 3 |
| Total Workload Completion Time | 299 Minutes | 49 Minutes | 28 Minutes |
测试结果揭示了读取和写入混合工作负载的并发扩展如何将总工作负载完成时间从 299 分钟缩短到 28 分钟,这是 SLA 改善的 10 倍以上,同时仅在需要扩展时才为额外的集群付费,从而具有成本效益。
监控并发扩展
监控并发扩展的一种方法是通过
urrency_sc
aling_status。
oncurrencyScalingActiveClusters 和 concurrencyScalingSec
onds 允许您设置对并发扩展使用情况
的监控。有关更多信息,请参阅
配置使用限制
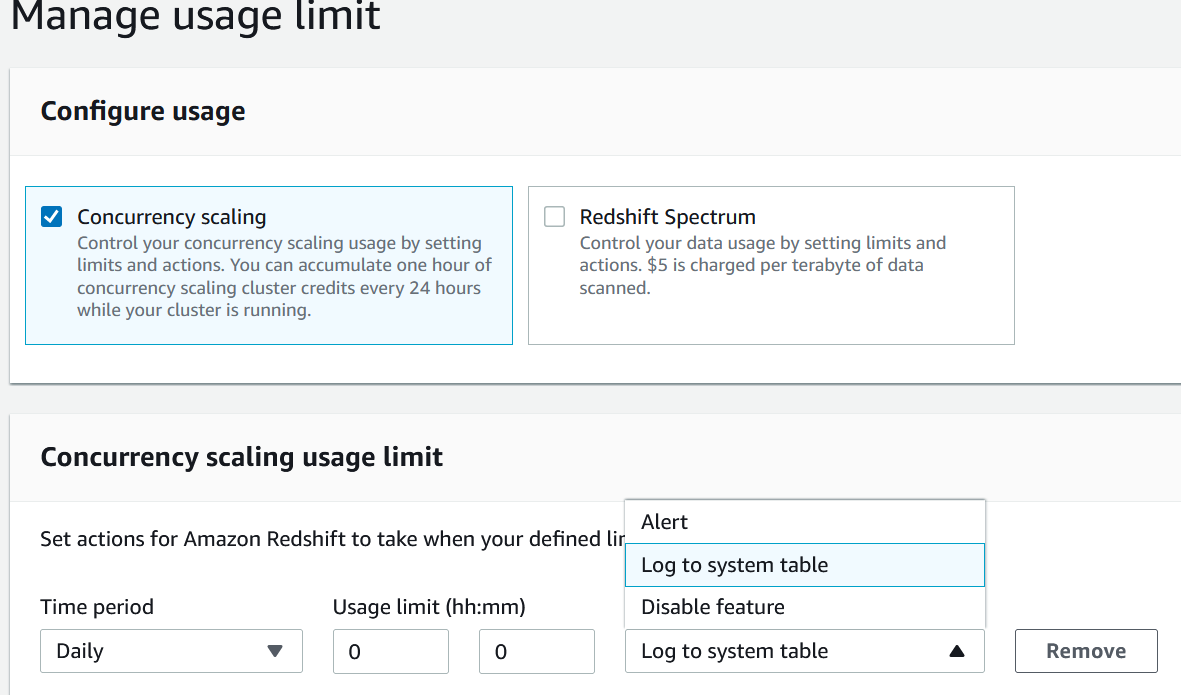
每使用 Amazon Redshift 主集群 24 小时,您将获得 1 小时的并发扩展积分。这笔免费积分可用于读取和写入查询。对于任何超过累计免费使用积分的使用量,将根据 Amazon Redshift 集群的按需费率按秒计费。您可以在集群级别应用成本控制以进行并发扩展。您可以选择为 ETL、仪表板和临时工作负载创建多个队列。有了这个,你可以选择为选择性队列启用并发扩展。
如以下屏幕截图所示,您可以选择时间段(每天、每周或每月)并指定所需的使用限制。然后,您可以选择操作选项(
警报
、
登录到系统表
或
禁用功能
)。有关如何为并发扩展设置成本控制的更多详细信息,请参阅使用
摘要
在这篇文章中,我们展示了如何通过无缝扩展到您配置的最大集群数量来启用并发扩展来帮助您满足读取和写入工作负载的 SLA,从而在控制成本的同时提高集群吞吐量。利用读取和写入功能进行并发扩展可以使您处理多种场景,例如数据管道中数据量的突然增加、回填操作、临时报告和月末处理。现在是时候将这些学习付诸实践并开始优化您的 Redshift 集群的读取和写入吞吐量了!
作者简介



*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。