我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用新的大型工作人员类型 G.4X 和 G.8X 扩展适用于 Apache Spark 的 亚马逊云科技 Glue 任务
成千上万的客户使用无服务器数据集成服务
今天,我们很高兴地宣布,亚马逊云科技 Glue G.4X (4 DPU) 和 G.8X (8 DPU) 工作线程已正式上线,这是下一系列 亚马逊云科技 Glue 工作程序,用于最苛刻的数据集成工作负载。G.4X 和 G.8X 工作线程提供更高的计算、内存和存储空间,使您能够垂直扩展和运行密集型数据集成作业,例如内存密集型数据转换、倾斜聚合和涉及千兆字节数据的实体检测检查。较大的工作人员类型不仅有益于 Spark 执行者,而且在 Spark 驱动程序需要更大容量的情况下也会受益,例如,因为作业查询计划非常大。
这篇文章演示了 亚马逊云科技 Glue G.4X 和 G.8X 工作人员如何帮助你扩展 Apache Spark 的 Aws Glue 任务。
G.4X 和 G.8X 工作人员
亚马逊云科技 Glue G.4X 和 G.8X 工作人员为您提供更多的计算、内存和存储空间,以运行最苛刻的任务。G.4X 工作人员提供 4 个 DPU,每个节点有 16 个 vCPU、64 GB 内存和 256 GB 磁盘。G.8X 工作人员提供 8 个 DPU,每个节点有 32 个 vCPU、128 GB 内存和 512 GB 磁盘。您可以在 API、AW
下表显示了 亚马逊云科技 Glue 3.0 或更高版本中每种工作程序类型的计算、内存、磁盘和 Spark 配置。
| 亚马逊云科技 Glue Worker Type | DPU per Node | vCPU | Memory (GB) | Disk (GB) | Number of Spark Executors per Node | Number of Cores per Spark Executor |
| G.1X | 1 | 4 | 16 | 64 | 1 | 4 |
| G.2X | 2 | 8 | 32 | 128 | 1 | 8 |
| G.4X (new) | 4 | 16 | 64 | 256 | 1 | 16 |
| G.8X (new) | 8 | 32 | 128 | 512 | 1 | 32 |
要在 亚马逊云科技 Glue 任务中使用 G.4X 和 G.8X 工作人员,请将工作人员类型参数的设置更改为 G.4X 或 G.8X。在 亚马逊云科技 Glue Studio 中,您可以在 “ 工作人员 类型” 下选择 G 4X 或 G 8X 。
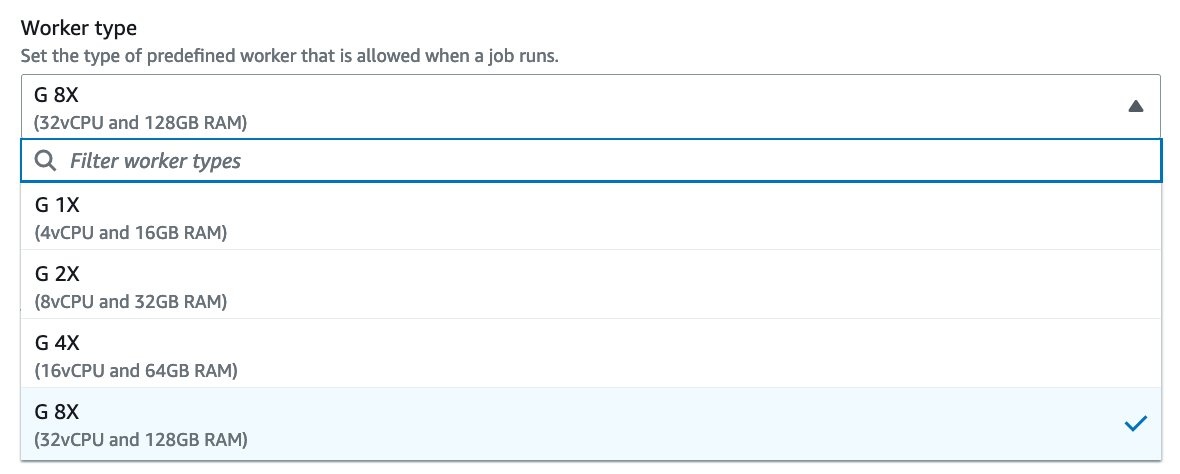
--worker- ty
pe 参数。
要在 AWS Glue Studio 笔记本或互动会话中使用 G.4X 和 G.8X,请在 %worker_type 魔法中设置 G.4X 或 G.8X:

使用 TPC-DS 基准测试的性能特征
在本节中,我们使用 TPC-DS 基准测试来展示新 G.4X 和 G.8X 工作人员类型的性能特征。我们使用了 亚马逊云科技 Glue 4.0 版任务。
在员工人数相同的情况下,G.2X、G.4X 和 G.8X 的结果
与 G.2X 工作人员类型相比,G.4X 工作线程拥有 2 倍的 DPU,G.8X 工作线程拥有 4 倍的 DPU。我们针对 3 TB 的 TPC-DS 数据集运行了 100 多次 TPC-DS 查询,这些数据集的工作人员数量相同,但工作人员类型不同。下表显示了基准测试的结果。
| Worker Type | Number of Workers | Number of DPUs | Duration (minutes) | Cost at $0.44/DPU-hour ($) |
| G.2X | 30 | 60 | 537.4 | $236.46 |
| G.4X | 30 | 120 | 264.6 | $232.85 |
| G.8X | 30 | 240 | 122.6 | $215.78 |
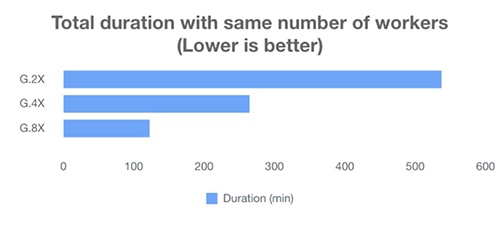
当使用相同数量的员工运行作业时,新的 G.4X 和 G.8x 工作人员实现了大致线性的垂直可扩展性。
使用相同数量的 DPU 时 G.2X、G.4X 和 G.8X 的结果
我们针对 10 TB 的 TPC-DS 数据集运行了 100 多次 TPC-DS 查询,这些数据集的 DPU 数量相同,但工作人员类型不同。下表显示了实验结果。
| Worker Type | Number of Workers | Number of DPUs | Duration (minutes) | Cost at $0.44/DPU-hour ($) |
| G.2X | 40 | 80 | 1323 | $776.16 |
| G.4X | 20 | 80 | 1191 | $698.72 |
| G.8X | 10 | 80 | 1190 | $698.13 |

当在总数相同的 DPU 上运行作业时,新的工作人员类型的工作性能基本保持不变。
示例:内存密集型转换
数据转换是将数据预处理和结构化为最佳形式的重要步骤。在某些转换中,例如聚合、联接、使用用户定义函数 (UDF) 的自定义逻辑等,会消耗更大的内存占用。新的 G.4X 和 G.8X 工作线程使您能够大规模运行更大规模的内存密集型转换。
以下示例从
roupBy
, 使用 Pandas UDF 根据
有 G.2X 工作人员
当 亚马逊云科技 Glue 任务在 12 个 G.2X 工作线程(24 个 DPU)上运行时,由于设备上没有剩余空间错误,它失败了。在 Spark 用户界面上,失败 阶段 的 “阶段 ” 选项卡显示,由于该错误,亚马逊云科技 Glue 任务中有多个失败的任务。
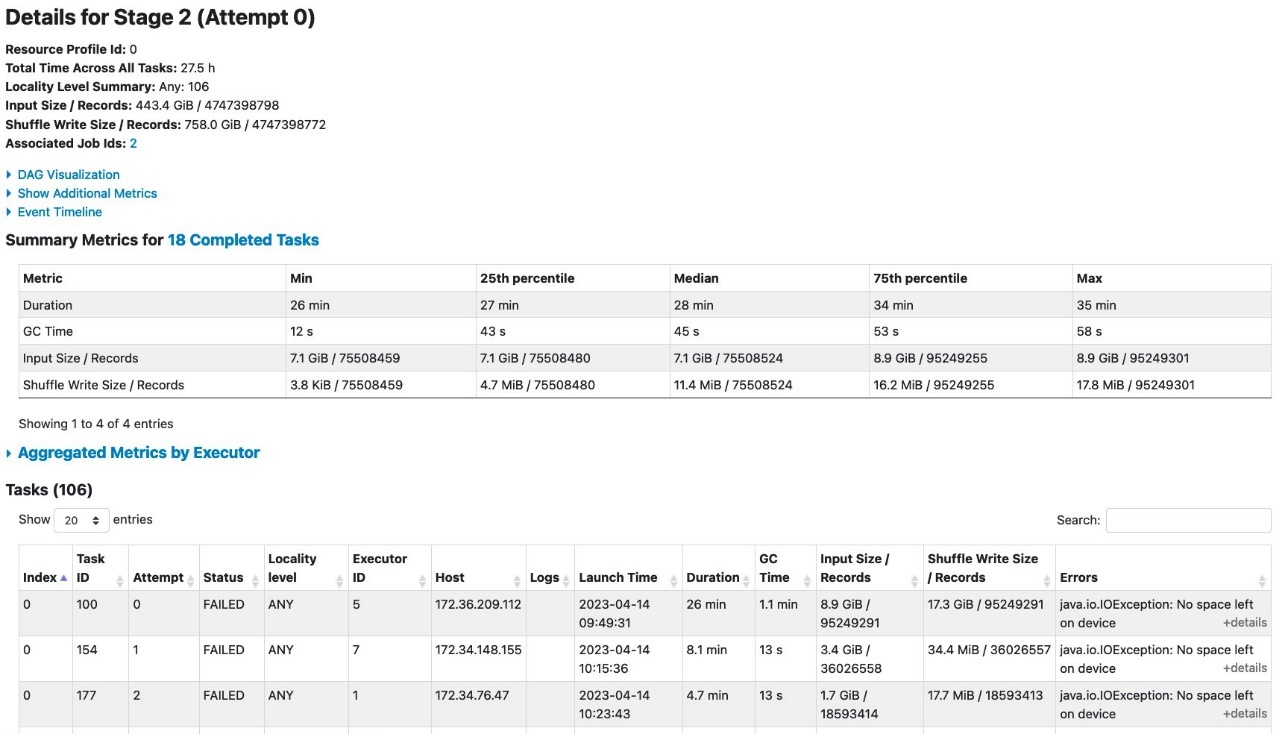
“ 执行器 ” 选项卡显示每个执行者的失败任务。
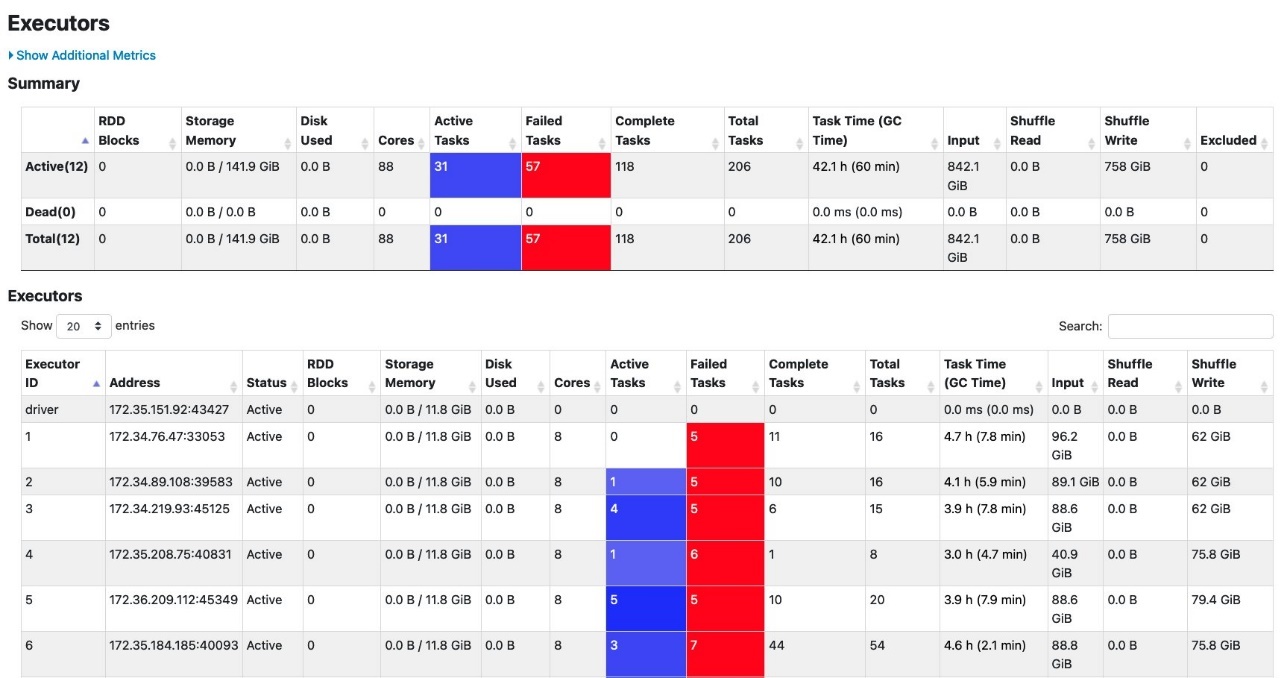
通常,G.2X 工作人员可以很好地处理内存密集型工作负载。这次,我们使用了一个特殊的 Pandas UDF,它消耗了大量内存,并且由于大量的洗牌写入而导致了故障。
有 G.8X 工作人员
当 亚马逊云科技 Glue 任务在 3 个 G.8X 工作线程(24 个 DPU)上运行时,它会成功运行而不会出现任何故障,如 Spark 用户界面的 “任务” 选项卡所示。
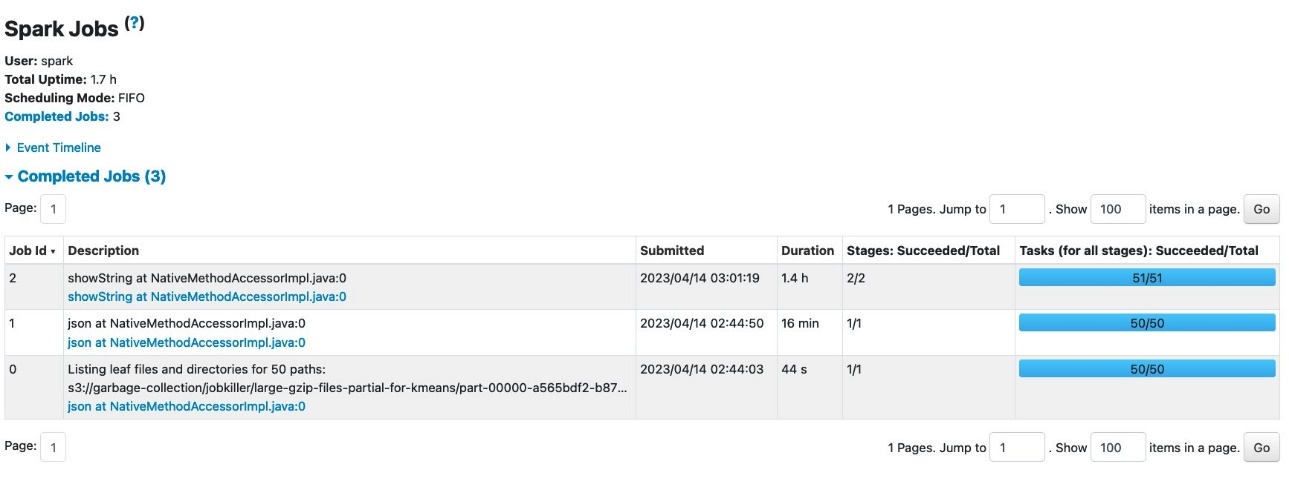
“ 执行者 ” 选项卡还说明没有失败的任务。
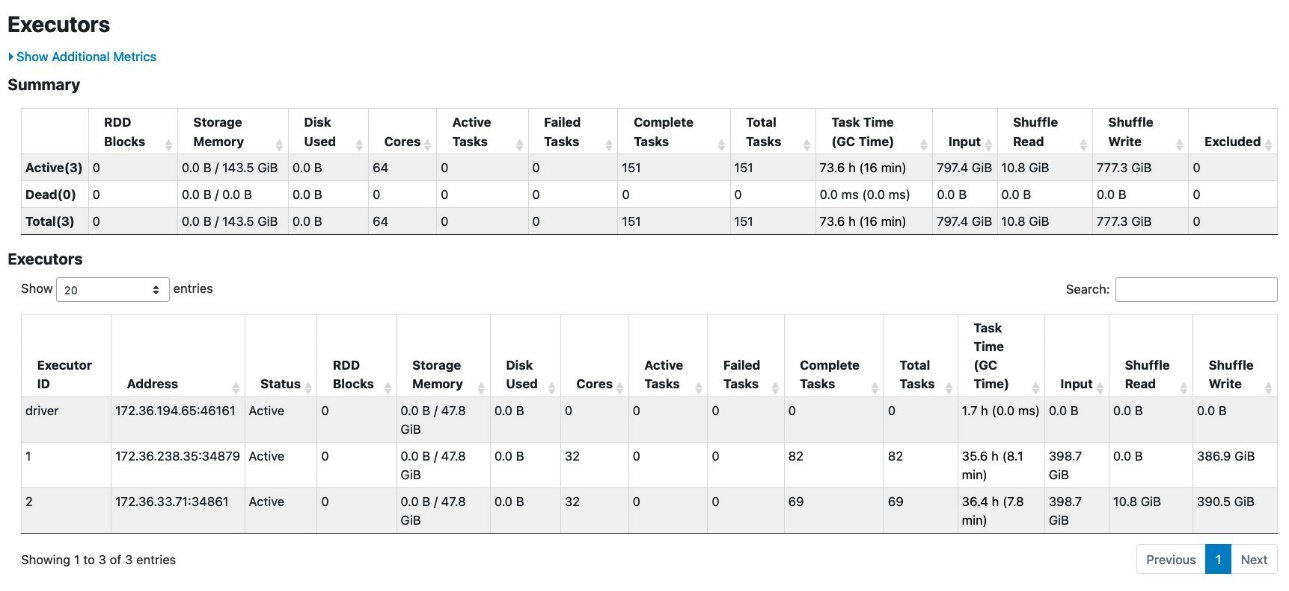
从这个结果中,我们观察到 G.8X 工作人员处理了相同的工作负载,没有出现故障。
结论
在这篇文章中,我们演示了 亚马逊云科技 Glue G.4X 和 G.8X 工作人员如何帮助你垂直扩展适用于 Apache Spark 的 亚马逊云科技 Glue 任务。G.4X 和 G.8X 工作人员目前可在美国东部(俄亥俄)、美国东部(弗吉尼亚北部)、美国西部(俄勒冈)、亚太地区(新加坡)、亚太地区(悉尼)、亚太地区(东京)、加拿大(中部)、欧洲(法兰克福)、欧洲(爱尔兰)和欧洲(斯德哥尔摩)工作。从今天起,您可以开始使用新的 G.4X 和 G.8X 工作人员类型来扩展工作量。要开始使用 亚马逊云科技 Glue,请访问
作者简介
 关山 则隆
是 亚马逊云科技 Glue 团队的首席大数据架构师。他在日本东京工作。他负责构建软件工件以帮助客户。在业余时间,他喜欢骑公路自行车骑自行车。
关山 则隆
是 亚马逊云科技 Glue 团队的首席大数据架构师。他在日本东京工作。他负责构建软件工件以帮助客户。在业余时间,他喜欢骑公路自行车骑自行车。
 田中智宏 是 A
WS Support 团队的高级云支持工程师。他热衷于帮助客户使用 ETL 工作负载构建数据湖。在空闲时间,他喜欢和同事一起喝咖啡,也喜欢在家煮咖啡。
田中智宏 是 A
WS Support 团队的高级云支持工程师。他热衷于帮助客户使用 ETL 工作负载构建数据湖。在空闲时间,他喜欢和同事一起喝咖啡,也喜欢在家煮咖啡。
 刘楚涵
是 亚马逊云科技 Glue 团队的软件开发工程师。他热衷于为大数据处理、分析和管理构建可扩展的分布式系统。在业余时间,他喜欢打网球。
刘楚涵
是 亚马逊云科技 Glue 团队的软件开发工程师。他热衷于为大数据处理、分析和管理构建可扩展的分布式系统。在业余时间,他喜欢打网球。
 Matt Su
是 亚马逊云科技 Glue 团队的高级产品经理。他喜欢通过 亚马逊云科技 Analytic 服务使用他们的数据帮助客户发现见解并做出更好的决策。在业余时间,他喜欢滑雪和园艺。
Matt Su
是 亚马逊云科技 Glue 团队的高级产品经理。他喜欢通过 亚马逊云科技 Analytic 服务使用他们的数据帮助客户发现见解并做出更好的决策。在业余时间,他喜欢滑雪和园艺。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。