我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
简化将数据加载到 Amazon Redshift 中缓慢变化的维度的 2 类中
成千上万的客户依赖
在这篇文章中,我们将介绍如何在 Amazon Redshift 中简化将数据加载到缓慢变化的类型 2 维度中。
星型架构和缓慢变化的维度概述
星型架构是最简单的
虽然操作源系统仅包含最新版本
数据加载是维护数据仓库的关键方面之一。在星型架构数据模型中,中央事实表依赖于周围的维度表。这是以主键与外键关系的形式捕获的,其中维度表的主键由事实表中的外键引用。
SCD 人口挑战赛
在这篇文章中,我们演示了如何使用以下方法简化向维度表中加载数据:
-
使用
Amazon Simple Storage Servic e (Amazon S3) 托管源系统表中的初始和增量数据文件 -
使用
Amazon Redshift Spectrum 访问 S3 对象进行数据处理 以在 Amazon Redshift 中加载原生表 - 使用窗口函数创建视图以在 Amazon Redshift 中复制每个表的源系统版本
- 将源表视图连接到与维度表架构匹配的项目属性
- 将增量数据应用到维度表,使其与源端更改保持同步
解决方案概述
在现实场景中,源系统表中的记录会定期提取到 Amazon S3 位置,然后加载到 Amazon Redshift 的星型架构表中。
在本演示中,将来自两个源表(
客户_master 和customer_
ad
dress)的数据合并起来 ,填充目标维度表 dim_cu
stomer
,
即客户
维度表。
源表
customer_master
和 c
ustomer_
address 共享相同的主键 c
ustomer_id
,并将合并到同一个主键上,以获取每个 c
ustomer_
id 的一条记录以及两个表中的属性。
row_audit_ts
包含插入或上次更新特定源记录的最新时间戳。此列有助于识别自上次数据提取以来的变更记录。
rec_source_ stat
us 是一个可选列,用于指示相应的源记录是否已插入、更新或删除。这适用于源系统本身提供更改并适当地填充
rec_source_
status 的情况。
下图提供了源表和目标表的架构。
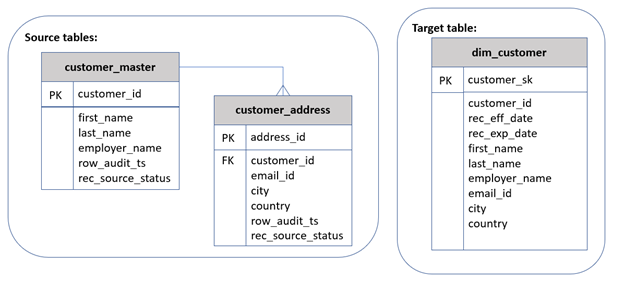
让我们仔细看看目标表 d
im_c
ustomer 的架构。它包含不同类别的列:
-
密钥
— 它包含两种类型的密钥:
-
customer_sk是此表的主键。它也被称为 代理密钥 ,具有单调递增的唯一值。 -
customer_id是源主键,提供对源系统记录的引用。
-
-
SCD2 元数据 — rec_eff_d
t 和 rec_exp_dt表示记录的状态。这两列共同定义了记录的有效性。对于当前活跃的记录,rec_exp_dt中的值 将设置为“9999-12-31”。 -
属性
-包括名字 、姓 氏、 雇主姓名、电子邮件ID、城市和国家。
将数据加载到 SCD 表中涉及首次批量数据加载,称为 初始数据 加载。 接下来是连续或定期的数据加载,称为 增量数据加载 ,以使记录与源表中的变化保持同步。
为了演示解决方案,我们完成了初始数据加载(1—7)和增量数据加载(8—12)的以下步骤:
- 将源数据文件放置在 Amazon S3 位置,每个源表使用一个子文件夹。
-
使用 A
WS Glu e 爬虫解析数据文件并在 亚马逊云科技 Glue 数据目录中注册表。 - 在 Amazon Redshift 中创建外部架构以指向包含这些表的 亚马逊云科技 Glue 数据库。
-
在 Amazon Redshift 中,为每个源表创建一个视图,以获取每个主键 (c
ustomer_id) 值的最新版本的记录。 -
在 Amazon Redshift 中创建 d
im_customer 表,其中包含来自所有相关源表的属性。 - 在 Amazon Redshift 中创建一个视图,将步骤 4 中的源表视图连接起来,以投影维度表中建模的属性。
-
将步骤 6 中创建的视图中的初始数据填充到dim_customer 表中,生成 customer_sk。 - 将每个源表的增量数据文件放到相应的 Amazon S3 位置。
- 在 Amazon Redshift 中,创建一个临时表来容纳仅限更改的记录。
-
加入步骤 6 和
dim_customer 中的视图 ,识别比较属性的组合哈希值的变更记录。使用I、U或D指示器将变更记录填充到临时表 中。 -
在
dp_dt。im_customer 中更新临时表中所有xU和D记录 的 rec_e -
将记录插入到 d
im_customer 中 ,查询临时表中的所有I和U记录。
先决条件
在开始之前,请确保满足以下先决条件:
-
拥有 A
WS 账户 。 -
创建一个 S3 存储桶 ,用于 存储将加载到 Amazon Redshift 中的数据文件。 -
创建亚马逊 Redshift 集群或终端节点。有关说明,请参阅
亚马逊 Redshi ft 入门 。 -
当您的环境准备就绪后,打开
Amazon Redshift 查询编辑器 v2.0 (参见以下屏幕截图)并连接到您的 Amazon Redshift 集群或终端节点。

来自源表的土地数据
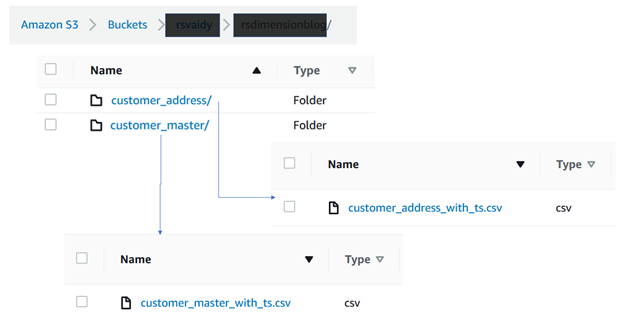
为 S3 存储桶中的每个源表创建单独的子文件夹,并将初始数据文件放在相应的子文件夹中。在下图中,客户_master 和
customer_address
的初始数据文件在
两个
不同的子文件夹中可用。要试用该解决方案,你可以使用
重要的是要包括一个审计时间戳 (
row_audit_ts
) 列,该列指示每条记录的插入时间或上次更新的时间。作为增量数据加载的一部分,具有相同主键值 (
customer_id
) 的行可以多次到达。
row_audit_ts
列有助于识别给定 c
ustomer_id
的此类记录的最新版本,用于进一步处理。
在 亚马逊云科技 Glue 数据目录中注册源表
我们使用 亚马逊云科技 Glue 爬虫从分隔的数据文件(例如本文中使用的 CSV 文件)中推断出元数据。有关开始使用 亚马逊云科技 Glue 爬虫的说明,请参阅
创建 亚马逊云科技 Glue 爬虫并将其指向包含源表子文件夹的 Amazon S3 位置,其中放置了相关的数据文件。在创建 亚马逊云科技 Glue 爬虫时,创建一个名为
r
s-dimension-blog 的新数据库。以下屏幕截图显示了为数据文件选择的 亚马逊云科技 Glue 爬虫配置。
请注意,在 “ 设置输出和调度 ” 部分,高级选项保持不变。
运行此爬虫应在
rs-dimension-
blog 数据库中创建以下表:
-
客户地址 -
客户主管
在 Amazon Redshift 中创建架构
首先,创建一个名为
rs-dim-blog-spectrum-
role 的 A
IAM 角色将 Amazon Redshift 作为可信实体,权限策略包括 Am
azons3ReadonlyAccess 和 awsGl ueConsoleFullAcces
s,因为 我们使用的是 AWS G
lue 数据目录。然后
相反,您也可以将
如果这样做,则在下面的
创建外部架构
命令中,将 iam_role 参数
作为 iam_role
默认值传递。
现在,打开 Amazon Redshift 查询编辑器 V2 并创建一个外部架构,传递新创建的 IAM 角色并将数据库指定为 rs-dimension-blog。
数据库名称
rs-dimension-blog
是在上一节配置爬虫时在数据目录中创建的名称。参见以下代码:
检查前一节中在数据目录中注册的表是否可以从 Amazon Redshift 中看到:
这些查询中的每一个都将从相应的数据目录表中返回 10 行。
在 Amazon Redshift 中创建另一个架构来托管表 dim_customer :
创建视图以从每个源表中获取最新记录
为
customer_master 表创建一个视图,将其 命名为 vw_cust_mst
r_latest:
前面的查询使用
row_num
ber 窗口函数根据 OVER 子句中的 ORDER BY 表达式确定一组行中当前行的序号,从 1 开始计算。通过将 PARTITION BY 子句
添加为 customer_id
,可以为每个
customer_id
值创建组, 并为每个组重置序号。
为
客户地址 表创建一个视图,将其命名为 vw_cust_
addr_latest :
这两个视图定义都使用 Amazon Redshift 的
行号 窗口函数,按行_
aud it_ts 列(审计时间戳列)的 降序对记录进行排序。
条件
rnum=1
获取每个 customer_id 值的最新记录。
在亚马逊 Redshift 中创建 dim_customer 表
在 r
维度表包括
s_dim_blog 架
构中,将 dim_customer 创建为亚马逊 Redshift 中的内部表。
customer_s
k列 ,该列充当代理键列,使我们能够捕获每条客户记录的时间敏感版本。每条记录的有效期由 rec_eff_dt 和
rec_exp_dt 列定义 ,分别代表记录生效
日期 和记录到期
日期。参见以下代码:
创建视图以整合最新版本的源记录
创建视图
vw_dim_customer_src
,它使用
左外联接
合并来自两个源表的最新记录,随时准备将其填充到 Amazon Redshift 维度表中。此视图从 “创建视图以从每个源表中获取最新记录” 部分中定义的最新视图中获取数据:
此时,此视图会获取初始数据以加载到我们即将创建的
dim_cu
stomer 表中。在您的用例中,使用类似的方法来创建和联接所需的源表视图,以填充目标维度表。
将初始数据填充到 dim_customer
通过查询视图 vw_dim_customer_src 将初始数据填充到
因为这是初始数据加载,所以运行
dim_custom
er 表中。
row_number 窗口函数生成的行号
足以在 c
ustomer_
sk 列中填充从 1 开始的唯一值:
在此查询中,我们已将
“2022-07-01” 指定 为 rec_e ff_dt
中所有初始数据记录
的值。对于您的用例,您可以根据自己的情况修改此日期值。
前面的步骤完成了向
dim_c
ustomer 表中加载的初始数据。在接下来的步骤中,我们将继续填充增量数据。
在 Amazon S3 中保存持续变更数据文件
初始加载后,源系统会持续提供数据文件,要么仅包含新的和更改的记录,要么包含特定表的所有记录的完整提取。
您可以使用示例文件
如果您使用了
customer_master
的示例文件 ,则在添加增量文件后,以下查询会显示初始记录和增量记录:
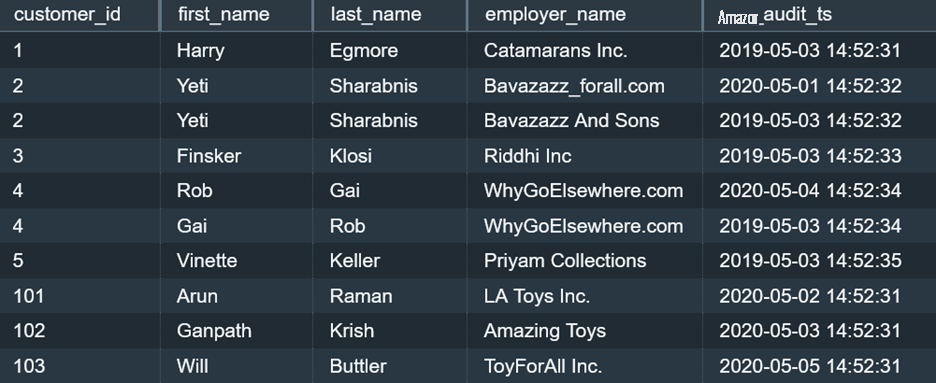
如果是完整的数据提取,我们可以通过比较以前和当前的版本并查找缺失的记录来识别源系统表中发生的删除。对于存在
rec_source_stat
us 列的仅限更改的数据提取,其值将帮助我们识别已删除的记录。无论哪种情况,都要将正在进行的变更数据文件放到相应的 Amazon S3 位置。
在此示例中,我们上传了客户_
master 和customer_
address 源表的增量数据,其中一些
c
ustomer_id
记录正在接收更新,并添加了一些新记录。
创建临时表来捕获变更记录
创建临时表
temp_dim_customer
来存储需要应用于目标 dim_customer 表的所有更改:
使用新的和更改的记录填充临时表
这是一个多步骤流程,可以组合成单个复杂的 SQL。完成以下步骤:
-
通过查询视图
vw_dim_customer_src 来获取所有客户属性的最新版本:
Amazon Redshift 提供哈希函数,例如
newver
(新版本)。
因为我们将正在进行的变更数据存放在与初始数据文件相同的位置,因此从前面的查询(
新
查询 )中检索到的记录包括所有记录,甚至包括未更改的记录。
但是由于视图
vw_dim_customer_src 的定义,每个客户
ID 只能获得一条记录 ,这是基于 row_audit_ts 的最新版本。
-
以类似的方式,从 d在这样做的同时,还要检索im_customer 检索所有客户记录的最新版本,这些记录由 rec_exp_dt=' 9999-12-31' 标识。dim_customer 中所有可用客户属性的sha2值:
该数据集将被称为
oldver
(旧版本或现有版本)。
-
从
dim_customer 表中识别当前的最大代理键值:
此值(
maxval
)将被添加到
row_num
ber 中, 然后再用作需要插入的变更记录的
customer_sk
值。
-
在 c
ustomer_id 列上对记录的旧版本(旧版本)和新版本(新版本)的记录执行完整的外部联接。然后比较 sha2函数生成的旧哈希值和新哈希值,以确定更改记录是插入、更新还是删除:
我们按如下方式标记记录:
-
如果旧 数据集中不存在customer_ id(oldver.customer_id 为空 ),则将其标记为插入内容('I')。 -
否则,如果新 数据集中不 存在客户 ID(newver.customer_id 为空 ),则将其标记为删除('D')。 -
否则,如果旧的
哈希值和新的哈希值不同,则这些记录表示更新('U')。 -
否则,它表示该记录未发生任何更改,因此可以忽略或标记为未处理 (
'N')。
如果源数据提取包含
rec_source_status 以识别已删除的记录
,请务必修改前面的逻辑 。
尽管
sha2
输出将可能无限的输入字符串映射到一组有限的输出字符串,但原始行值的哈希值与更改的行值发生冲突的可能性很小。我们没有单独比较前后的每列值,而是比较 s
ha2
生成的哈希值, 以得出客户记录的任何属性是否发生了变化。对于您的用例,我们建议您在进行充分测试后选择适用于您的数据条件的
- 结合前面步骤的输出,让我们创建 INSERT 语句,该语句仅捕获变更记录以填充临时表:
使更新的客户记录过期
由于
temp_dim_custom
er 表现在仅包含变更记录(
“I” 、“
U ” 或 “
) ,因此同样的内容可以应用于目标 dim_customer 表。
D ”
让我们首先获取
iud_
op 列 中值为 “
U ”
或 “D”
的所有记录。这些记录已在源系统中被删除或更新。由于
dim_c
ustomer 是一个缓慢变化的维度,因此它需要反映每条客户记录的有效期。在这种情况下,我们会过期已更新或删除的当前有效记录。
我们从昨天(通过设置
rec_exp_dt=current_dt=current_date-1)在 customer_
id 列中匹配的记录到期:
插入新的和更改的记录
最后一步,我们需要插入更新记录的更新版本以及所有首次插入的记录。
在 temp_dim_c
ust
omer 表
的
和 “I” 表示:
iud_op
列中,它们分别由 “U”
根据 SQL 客户端的设置,您可能需要运行
提交事务;
命令来验证之前的更改是否成功保留在 Amazon Redshift 中。
检查最终输出
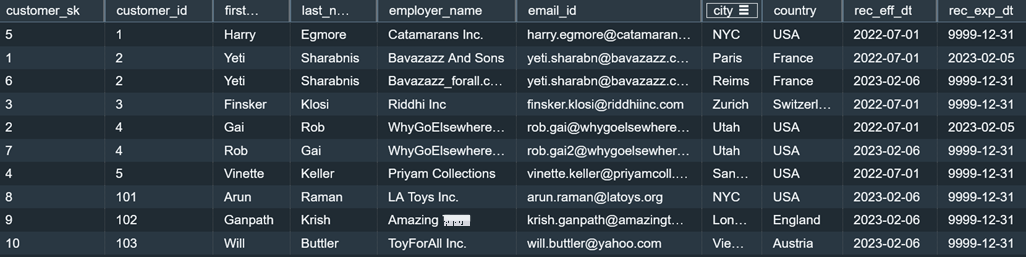
您可以运行以下查询,看到
dim_custom
er 表现在包含初始数据记录和增量数据记录,从而捕获在增量数据加载过程中更改的
customer_id
值的多个版本。输出还表明,每条记录都已在 rec_eff_dt 和
rec_exp_dt 中填充了与记录有效
期相对
应的相应值。
对于本文中提供的示例数据文件,前面的查询返回以下记录。如果你使用的是这篇文章中提供的示例数据文件,请注意
customer_sk
中的值 可能与下表中显示的值不匹配。
在这篇文章中,我们只展示重要的 SQL 语句;完整的 SQL 代码可在
清理
如果您不再需要创建的资源,则可以将其删除以防止产生额外费用。
结论
在这篇文章中,您学习了如何在 Amazon Redshift 中简化数据加载到 Type-2 SCD 表中,包括初始数据加载和增量数据加载。该方法处理填充目标维度表的多个源表,在每次运行时捕获最新版本的源记录。
有关更多材料和其他
作者简介
 Vaidy Kalpath
y 是 亚马逊云科技 的高级数据实验室解决方案架构师,他帮助客户实现数据平台现代化并定义端到端数据策略,包括数据提取、转换、安全、可视化。他热衷于从商业用例向后研究,创建可扩展和可定制的架构,以帮助客户使用 亚马逊云科技 上的数据分析服务进行创新。
Vaidy Kalpath
y 是 亚马逊云科技 的高级数据实验室解决方案架构师,他帮助客户实现数据平台现代化并定义端到端数据策略,包括数据提取、转换、安全、可视化。他热衷于从商业用例向后研究,创建可扩展和可定制的架构,以帮助客户使用 亚马逊云科技 上的数据分析服务进行创新。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。