我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Snapper 提供机器学习辅助标签,用于像素完美的图像物体检测
边界框注释是一项耗时而乏味的任务,需要注释者创建紧密贴合对象边界的注释。例如,边界框注释任务要求注释者确保注释对象的所有边缘都包含在注释中。实际上,创建精确且与对象边缘对齐的注释是一个费力的过程。
在这篇文章中,我们介绍了一款名为Snapper的新交互式工具,该工具由机器学习(ML)模型提供支持,可减少注释者所需的工作量。Snapper 工具会自动调整有噪点的注释,从而缩短了以高质量水平注释数据所需的时间。
Snapper 概述
Snapper 是一个交互式智能系统,可自动将对象注释 “捕捉” 到基于图像的对象。使用 Snapper,批注者通过绘制方框来放置边界框注释,然后看到对其边界框的即时自动调整,以更好地适应边界对象。
Snapper 系统由两个子系统组成。第一个子系统是前端 ReactJS 组件,它拦截与注释相关的鼠标事件并处理模型预测的渲染。我们将这个前端与
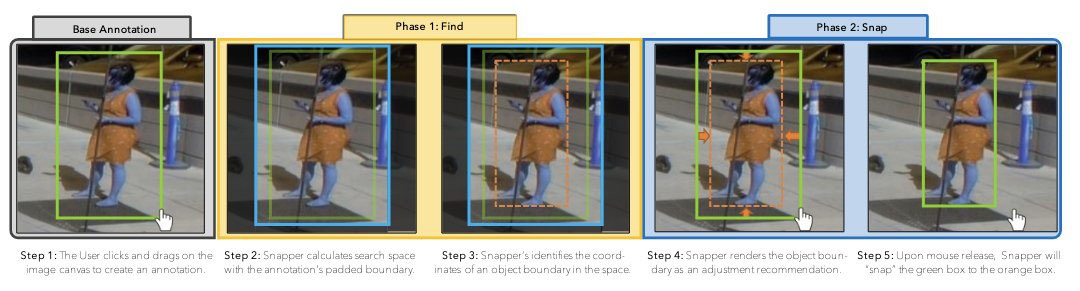
机器学习模型针对注释者进行了优化
近年来,计算机视觉界提出了大量的高性能物体检测模型。但是,这些最先进的模型通常针对无制导物体检测进行了优化。为了便于使用 Snapper 的 “捕捉” 功能来调整用户的注释,我们模型的输入是由注释器提供的初始边界框,它可以用作物体存在的标记。此外,由于系统没有旨在支持的预期对象类,因此 Snapper 的调整模型应不受对象限制,以便系统在一系列对象类上表现良好。
总的来说,这些要求与典型的机器学习对象检测模型的用例大相径庭。我们注意到,传统的物体检测问题被表述为 “检测物体中心,然后回归尺寸”。这是违反直觉的,因为对边界框边缘的准确预测关键在于首先找到准确的方框中心,然后尝试确定与边缘的标量距离。此外,它无法提供侧重于边缘位置不确定性的良好置信度估计值,因为只有分类器分数可供使用。
为了使我们的 Snapper 模型能够调整用户的注释,我们设计并实现了为边界框调整而定制的机器学习模型。作为输入,模型采用图像和相应的边界框注释。该模型使用卷积神经网络从图像中提取特征。特征提取后,将定向空间池化应用于每个维度,以聚合识别相应边缘位置所需的信息。
我们将边界框的位置预测制定为不同位置的分类问题。在观察整个物体时,作为分类任务,我们要求机器直接推断每个像素的位置是否存在边缘。这提高了准确性,因为每条边缘的推理都使用来自本地邻域的图像特征。此外,该方案将不同边缘之间的推理分离,从而防止明确的边缘位置受到不确定边缘位置的影响。此外,它还为我们提供了边缘直观的置信度估计值,因为我们的模型独立考虑物体的每条边缘(就像人类注释者一样),并为每条边缘的位置提供了可解释的分布(或不确定性估计值)。这使我们能够突出不太自信的边缘,从而实现更高效、更精确的人工审查。
对 Snapper 工具进行基准测试和评估
实际上,我们发现 Snapper 工具简化了边框注释任务,并且非常直观,便于用户上手。我们还对Snapper进行了定量分析,以客观地描述该工具的特征。我们使用一种对物体检测模型的评估标准来评估Snapper的调整模型,该模型使用两种衡量标准来检查有效性:联合线上的交点(IoU)以及边角偏差。IoU 通过将注释的重叠区域除以注释的联合区域来计算两个注释之间的对齐度,得出一个范围为 0—1 的指标。边缘偏差和角偏差是通过将偏离基本真实值的边和角的分数乘以像素值来计算的。
为了评估 Snapper,我们通过使用抖动随机调整

如上表所示,Snapper的调整模型显著改善了三个指标中两个噪声数据源。重点是高精度注解,我们观察到将 Snapper 应用于抖动的 MS COCO 数据集会使 IoU 超过 90% 的边界框的比例增加 40% 以上。
结论
在这篇文章中,我们介绍了一款名为Snapper的新型基于机器学习的注释工具。Snapper 由 SageMaker 模型后端以及我们集成到 Ground Truth 标签用户界面中的前端组件组成。我们使用模拟的噪声边界框注释对 Snapper 进行了评估,发现它可以成功优化不完美的边界框。在标签任务中使用 Snapper 可以显著降低成本并提高准确性。
要了解更多信息,请访问
作者简介
 乔纳森·巴克
(Jonathan Buck) 是亚马逊网络服务的软件工程师,从事机器学习和分布式系统的交叉工作。他的工作包括制作机器学习模型和开发由机器学习提供支持的新型软件应用程序,以将最新功能交到客户手中。
乔纳森·巴克
(Jonathan Buck) 是亚马逊网络服务的软件工程师,从事机器学习和分布式系统的交叉工作。他的工作包括制作机器学习模型和开发由机器学习提供支持的新型软件应用程序,以将最新功能交到客户手中。
 亚历克斯·威廉姆斯
是 亚马逊云科技 AI 人机交互科学团队的应用科学家,他在人机交互 (HCI) 和机器学习的交叉点进行交互式系统研究。在加入亚马逊之前,他是田纳西大学电气工程和计算机科学系的教授,在那里他共同领导了人、代理、交互和系统 (PAIRS) 研究实验室。他还曾在微软研究院、Mozilla 研究中心和牛津大学担任研究职务。他经常在HCI的主要出版场所发表自己的作品,例如CHI、CSCW和UIST。他拥有滑铁卢大学的博士学位。
亚历克斯·威廉姆斯
是 亚马逊云科技 AI 人机交互科学团队的应用科学家,他在人机交互 (HCI) 和机器学习的交叉点进行交互式系统研究。在加入亚马逊之前,他是田纳西大学电气工程和计算机科学系的教授,在那里他共同领导了人、代理、交互和系统 (PAIRS) 研究实验室。他还曾在微软研究院、Mozilla 研究中心和牛津大学担任研究职务。他经常在HCI的主要出版场所发表自己的作品,例如CHI、CSCW和UIST。他拥有滑铁卢大学的博士学位。
 白敏
是 亚马逊云科技 的应用科学家,目前专攻二维/三维计算机视觉,专注于自动驾驶和用户友好型 AI 工具领域。不工作时,他喜欢探索大自然,尤其是在人迹罕至的地方。
白敏
是 亚马逊云科技 的应用科学家,目前专攻二维/三维计算机视觉,专注于自动驾驶和用户友好型 AI 工具领域。不工作时,他喜欢探索大自然,尤其是在人迹罕至的地方。
 库马尔·切拉皮拉
是亚马逊网络服务的总经理兼总监,领导机器学习/人工智能服务的开发,例如人机交互系统、人工智能 DevOps、地理空间机器学习和 ADAS/自动驾驶汽车开发。在加入 亚马逊云科技 之前,Kumar 曾担任 Uber ATG 和 Lyft Level 5 的工程总监,带领团队使用机器学习开发感知和测绘等自动驾驶功能。他还致力于应用机器学习技术来改进LinkedIn、Twitter、Bing和微软研究院的搜索、推荐和广告产品。
库马尔·切拉皮拉
是亚马逊网络服务的总经理兼总监,领导机器学习/人工智能服务的开发,例如人机交互系统、人工智能 DevOps、地理空间机器学习和 ADAS/自动驾驶汽车开发。在加入 亚马逊云科技 之前,Kumar 曾担任 Uber ATG 和 Lyft Level 5 的工程总监,带领团队使用机器学习开发感知和测绘等自动驾驶功能。他还致力于应用机器学习技术来改进LinkedIn、Twitter、Bing和微软研究院的搜索、推荐和广告产品。
 帕特里克·哈夫纳
是 亚马逊云科技 Sagemaker Ground Truth 团队的首席应用科学家。自 1995 年他应用 LeNet 卷积神经网络来检查识别以来,他一直致力于人机在环优化。他对将机器学习算法和标签用户界面结合起来以最大限度地降低标签成本的整体方法很感兴趣。
帕特里克·哈夫纳
是 亚马逊云科技 Sagemaker Ground Truth 团队的首席应用科学家。自 1995 年他应用 LeNet 卷积神经网络来检查识别以来,他一直致力于人机在环优化。他对将机器学习算法和标签用户界面结合起来以最大限度地降低标签成本的整体方法很感兴趣。
 Erran Li
是亚马逊 亚马逊云科技 AI 人类在环服务(亚马逊云科技 AI)的应用科学经理。他的研究兴趣是三维深度学习以及视觉和语言表现学习。此前,他是 Alexa AI 的资深科学家、Scale AI 的机器学习负责人和 Pony.ai 的首席科学家。在此之前,他曾在Uber ATG的感知团队和优步的机器学习平台团队工作,致力于自动驾驶、机器学习系统和人工智能战略计划的机器学习。他的职业生涯始于贝尔实验室,曾是哥伦比亚大学的兼职教授。他在ICML'17和ICCV'19上共同教授教程,并在Neurips、ICML、CVPR、ICCV共同组织了多个研讨会,内容涉及自动驾驶的机器学习、三维视觉和机器人、机器学习系统和对抗性机器学习。他在康奈尔大学拥有计算机科学博士学位。他是 ACM 研究员和 IEEE 研究员。
Erran Li
是亚马逊 亚马逊云科技 AI 人类在环服务(亚马逊云科技 AI)的应用科学经理。他的研究兴趣是三维深度学习以及视觉和语言表现学习。此前,他是 Alexa AI 的资深科学家、Scale AI 的机器学习负责人和 Pony.ai 的首席科学家。在此之前,他曾在Uber ATG的感知团队和优步的机器学习平台团队工作,致力于自动驾驶、机器学习系统和人工智能战略计划的机器学习。他的职业生涯始于贝尔实验室,曾是哥伦比亚大学的兼职教授。他在ICML'17和ICCV'19上共同教授教程,并在Neurips、ICML、CVPR、ICCV共同组织了多个研讨会,内容涉及自动驾驶的机器学习、三维视觉和机器人、机器学习系统和对抗性机器学习。他在康奈尔大学拥有计算机科学博士学位。他是 ACM 研究员和 IEEE 研究员。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。