我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用无代码机器学习,使用 Amazon SageMaker Canvas 情感分析和文本分析模型从产品评论中获得见解
根据
SageMaker Canvas 专为业务分析师使用
在这篇文章中,我们演示了如何使用即用型情感分析模型和自定义文本分析模型从产品评论中得出见解。在这个用例中,我们有一组综合的产品评论,我们想要分析这些评论以了解情绪,并按产品类型对评论进行分类,以便轻松绘制模式和趋势,帮助业务利益相关者做出更明智的决策。首先,我们描述了使用即用型情感分析模型确定评论情绪的步骤。然后,我们将引导您完成训练文本分析模型以按产品类型对评论进行分类的过程。接下来,我们将解释如何审查经过训练的模型的性能。最后,我们将解释如何使用经过训练的模型进行预测。
情感分析是一种自然语言处理 (NLP) 即用型模型,用于分析文本中的情感。情绪分析可以用于单行预测或批量预测。每行文本的预测情绪要么是积极的,要么是负面的,要么是混合的,要么是中性的。
文本分析允许您使用自定义模型将文本分为两个或更多类别。在这篇文章中,我们想根据产品类型对产品评论进行分类。要训练文本分析自定义模型,您只需在 CSV 文件中提供由文本和关联类别组成的数据集即可。该数据集至少需要两个类别和每个类别的 125 行文本。训练模型后,您可以查看模型的性能并在需要时重新训练模型,然后再将其用于预测。
先决条件
完成以下先决条件:
-
拥有 A
WS 账户 。 -
设置
SageMaker 画布 。 -
下载
产品评论数据集 示例: -
sample_product_reviews.csv— 包含 2,000 条综合产品评论,用于情感分析和文本分析预测。 -
sample_product_reviews_training.csv— 包含 600 条综合产品评论和三个产品类别,用于文本分析模型训练。
-
情绪分析
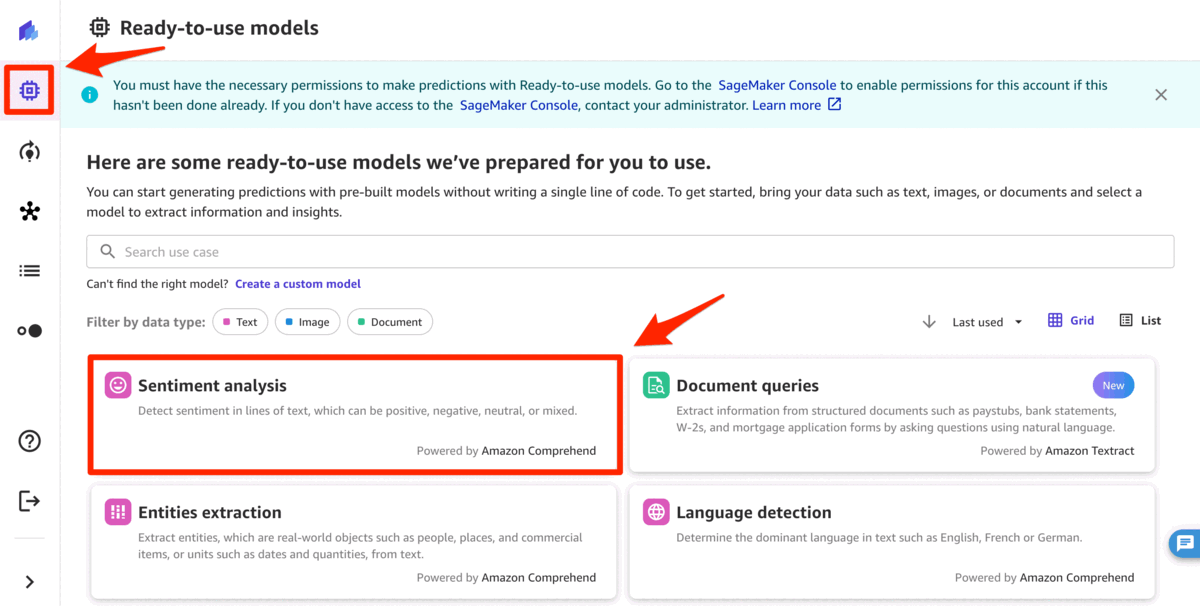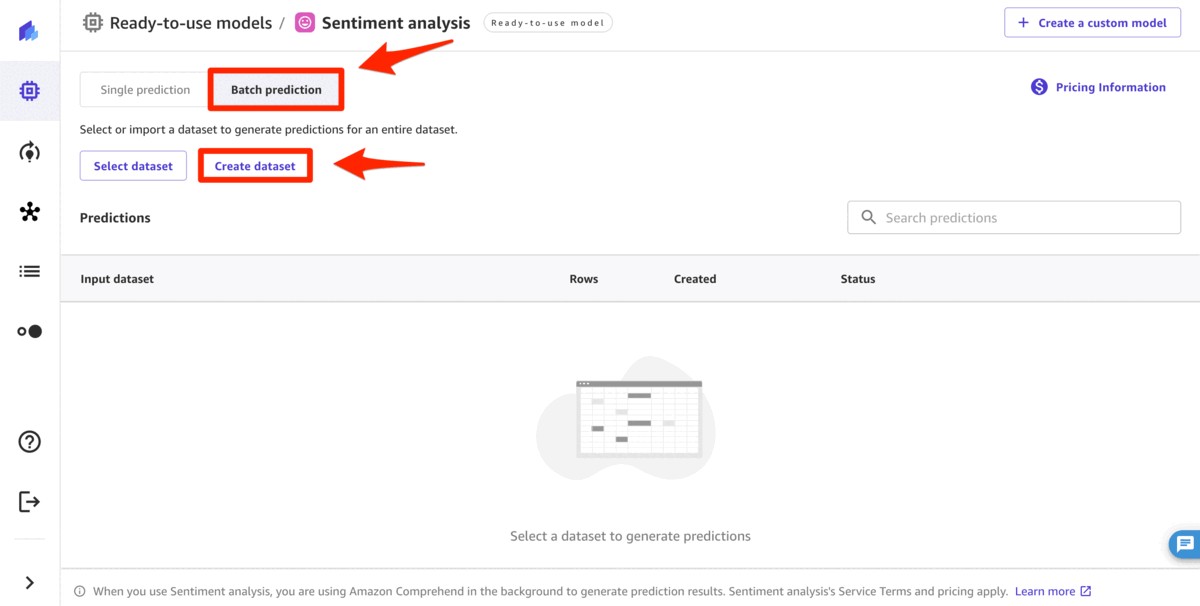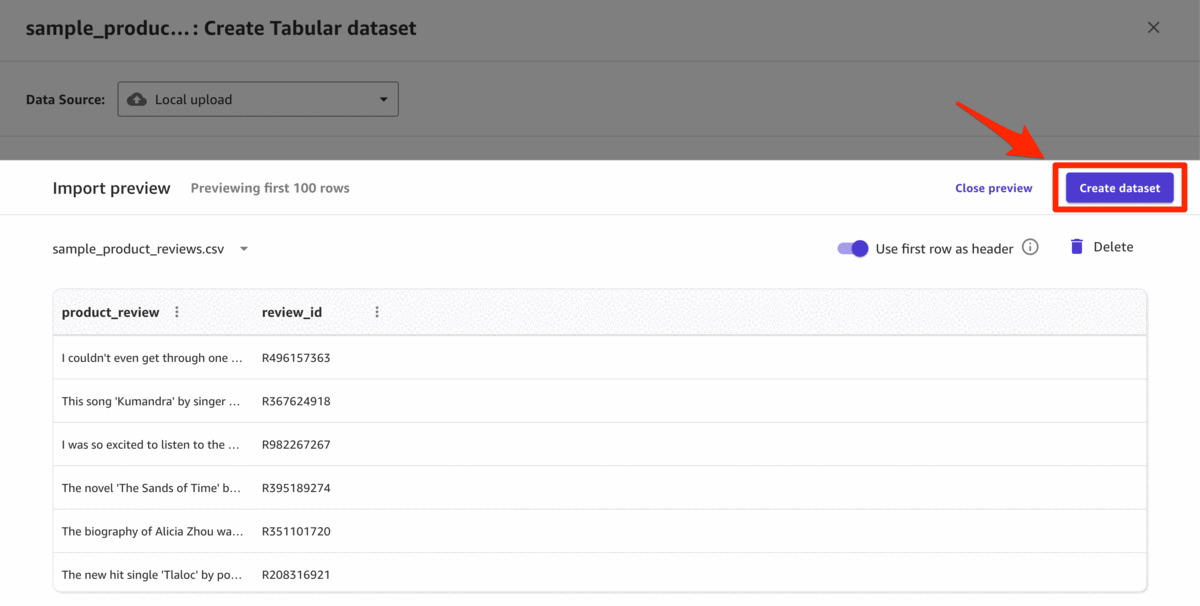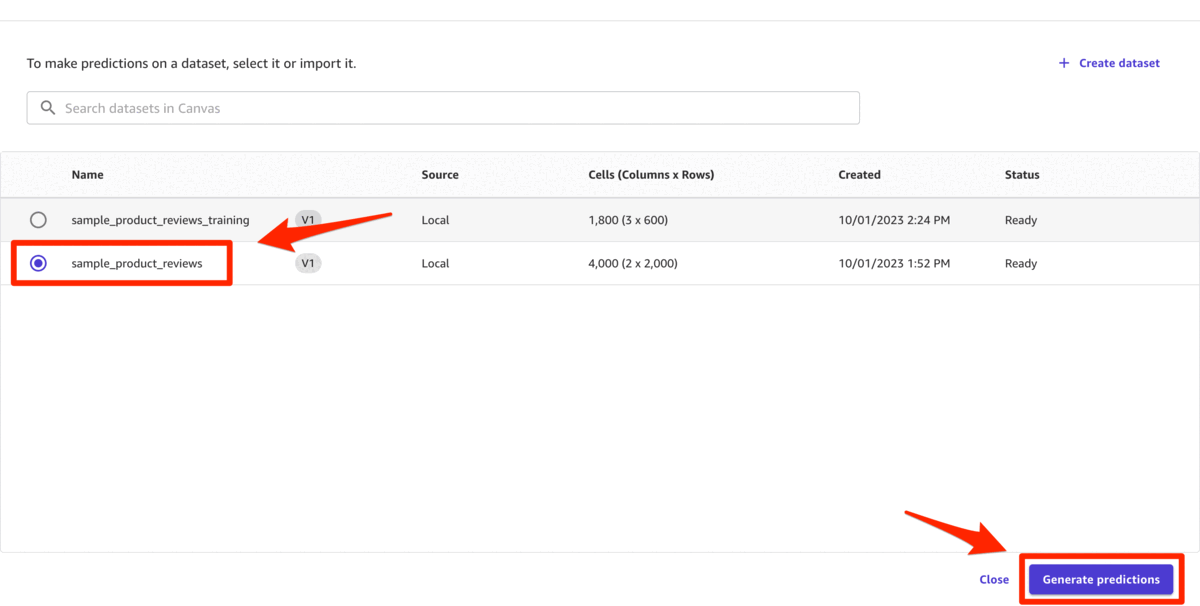
首先,您可以通过完成以下步骤使用情感分析来确定产品评论的观点。
-
在
SageMaker 控制台 上 ,单击导航窗格中的 “ 画布 ”,然后单击 “ 打开画布 ” 打开 SageMaker Canvas 应用程序。 - 在导航窗格 中单击 即用型模型 ,然后单击 情绪 分析。
- 点击 批量预测 ,然后点击 创建数据集。
- 提供 数据集名称 并单击 “ 创建”。
-
单击
“从计算机中选择文件”
以导入
sample_product_reviews.csv数据集。 - 单击 “ 创建数据集 ” 并查看数据。第一列包含评论,用于情感分析。第二列包含评论 ID,仅供参考。
- 单击 “ 创建数据集 ” 以完成数据上传过程。
-
在
“选择用于预测的数据集”
视图中,选择
sample_product_reviews.csv, 然后单击 “ 生成预测”。 - 批量预测完成后,单击 “ 查看 ” 以查看预测。
情绪和信心列分别提供情绪和信心分数。置信度分数是介于 0 到 100% 之间的统计值,它显示了正确预测情绪的概率。
- 单击 “ 下载 CSV ” 将结果下载 到您的计算机。
文本分析
在本节中,我们将介绍使用自定义模型进行文本分析的步骤:导入数据、训练模型然后进行预测。
导入数据
首先导入训练数据集。完成以下步骤:
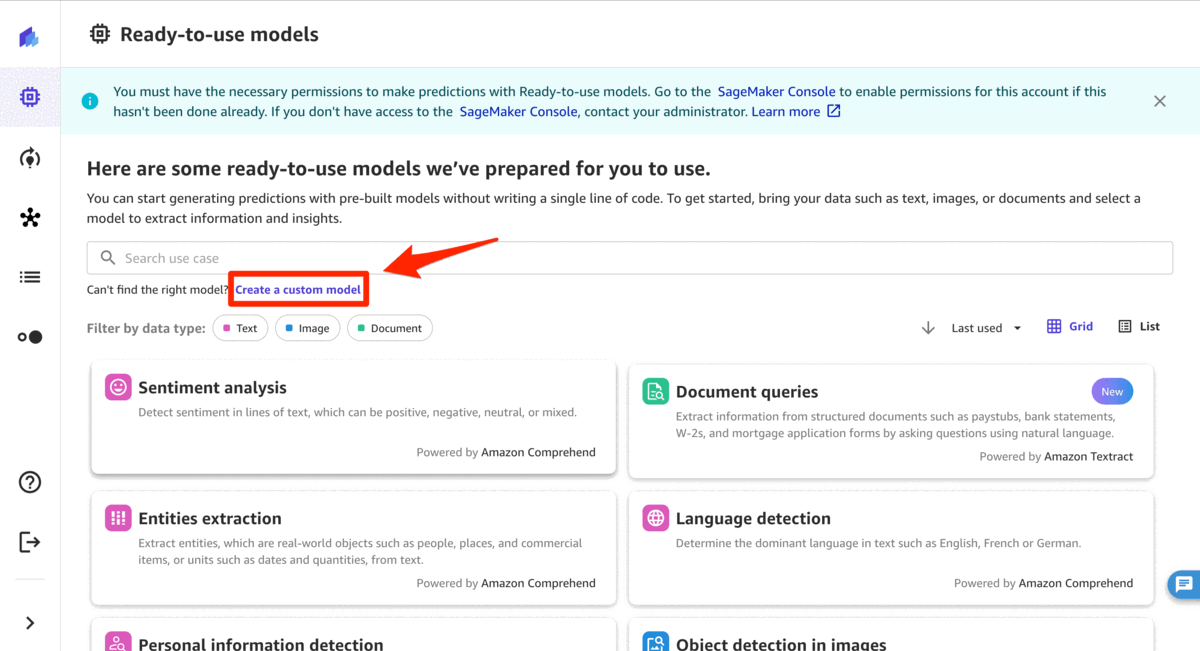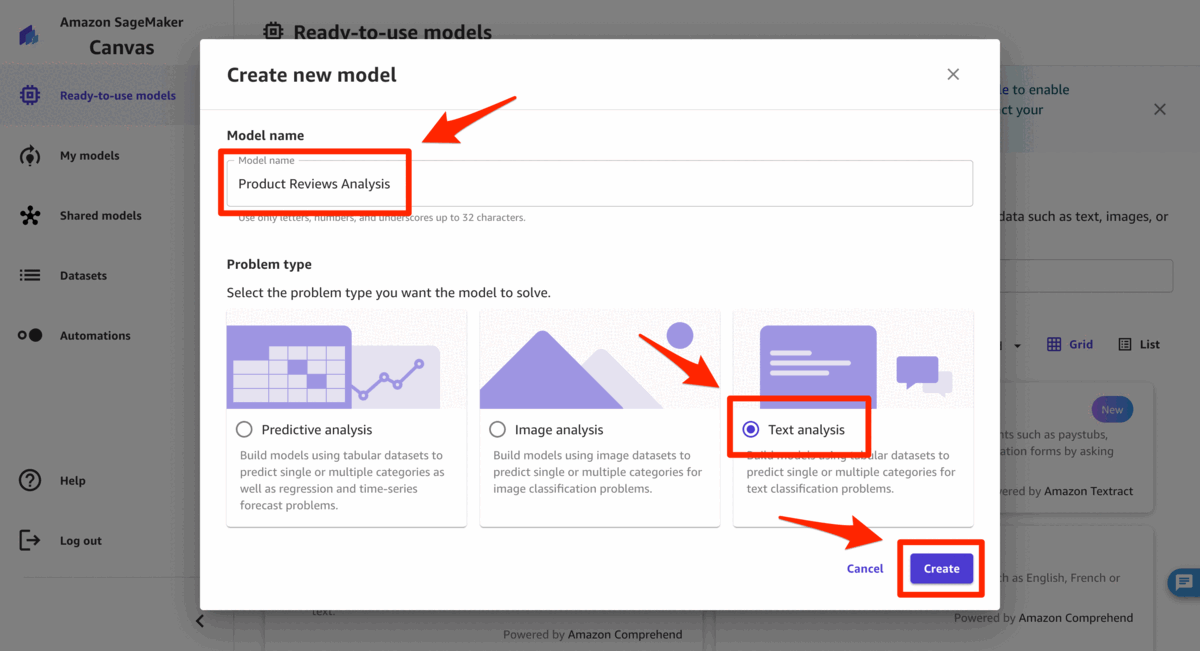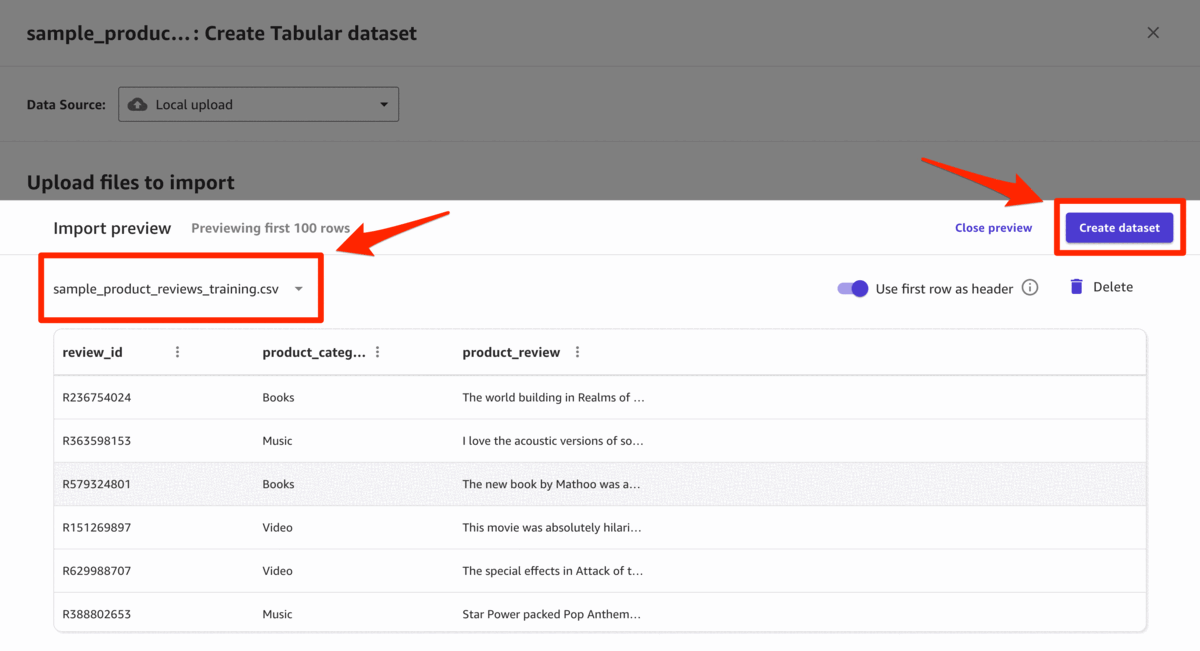
- 在 即用型模型 页面上,单击 创建自定义 模型
-
在
型号名称
中 ,输入名称(例如,
产品评论分析)。单击 “ 文本分析”, 然后单击 “ 创建”。 -
在
选择
选项卡上,单击
创建数据集
以导入
sample_product_reviews_training.csv数据集。 - 提供 数据集名称 并单击 “ 创建”。
- 单击 “ 创建数据集 ” 并查看数据。训练数据集包含描述产品类别的第三列,目标列由三种产品组成:书籍、视频和音乐。
- 单击 “ 创建数据集 ” 以完成数据上传过程。
-
在
选择数据集
页面上,选择
sample_product_reviews_training.csv, 然后单击 选择数据集 。
训练模型
接下来,您将配置模型以开始训练过程。
-
在 “
构建
” 选项卡上的 “
目标” 列
下拉菜单上,单击
product_category 作为训练目标。 -
单击
product_review作为来源。 - 单击 “ 快速构建 ” 开始模型训练。
有关快速构建和标准编译之间差异的更多信息,请参阅
模型训练完成后,您可以先查看模型的性能,然后再将其用于预测。
- 在 分析 选项卡上,将显示模型的置信度分数。置信度分数表示模型有多确定其预测是正确的。在 “ 概览 ” 选项卡上,查看每个类别的绩效。
- 单击 “ 评分 ” 查看模型精度见解。
-
单击 “
高级指标
” 可查看
混淆矩阵和 F1 分数 。
做出预测
要使用自定义模型进行预测,请完成以下步骤:
- 在 “ 预测 ” 选项卡上,单击 “ 批量预测 ” ,然后单击 “ 手动 ” 。
-
单击您之前用于情感分析的相同数据集
sample_product_reviews.csv,然后单击 “ 生成预测”。 - 批量预测完成后,单击 “ 查看 ” 以查看预测。
对于自定义模型预测,SageMaker Canvas 需要一些时间来部署模型以供初始使用。如果模型闲置 15 分钟,SageMaker Canvas 会自动取消配置模型,以节省成本。
预测
(类别)和
置信
度 列分别提供预测的产品类别和置信度分数。
- 突出显示已完成的作业,选择三个点,然后单击 “ 下载 ” 将结果下载到您的计算机。
清理
在导航窗格 中单击 “
注销
” 以注销 SageMaker Canvas 应用程序,以停止消耗
结论
在这篇文章中,我们演示了如何在没有机器学习专业知识的情况下使用
作者简介
 Gavin Satur
是亚马逊网络服务的首席解决方案架构师。他与企业客户合作构建战略性、架构精良的解决方案,并对自动化充满热情。工作之余,他喜欢与家人共度时光、打网球、烹饪和旅行。
Gavin Satur
是亚马逊网络服务的首席解决方案架构师。他与企业客户合作构建战略性、架构精良的解决方案,并对自动化充满热情。工作之余,他喜欢与家人共度时光、打网球、烹饪和旅行。
 Les Chan
是总部位于加利福尼亚州尔湾的亚马逊网络服务的高级解决方案架构师。Les 热衷于与企业客户合作,采用和实施技术解决方案,唯一的重点是推动客户业务成果。他的专长涵盖应用程序架构、DevOps、无服务器和机器学习。
Les Chan
是总部位于加利福尼亚州尔湾的亚马逊网络服务的高级解决方案架构师。Les 热衷于与企业客户合作,采用和实施技术解决方案,唯一的重点是推动客户业务成果。他的专长涵盖应用程序架构、DevOps、无服务器和机器学习。
 Aaqib Bickiya
是总部位于南加州的亚马逊网络服务的解决方案架构师。他帮助零售领域的企业客户加速项目和实施新技术。Aaqib 的重点领域包括机器学习、无服务器、分析和通信服务
Aaqib Bickiya
是总部位于南加州的亚马逊网络服务的解决方案架构师。他帮助零售领域的企业客户加速项目和实施新技术。Aaqib 的重点领域包括机器学习、无服务器、分析和通信服务
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。